
在前文我们介绍过基于价值算法和基于策略算法的区别:
在基于价值算法中,是根据值函数对策略进行改进,对比基于策略的方法,他的决策更为肯定就是选择价值最高的;而基于策略方法,是直接对策略进行迭代让累计回报最大。
在上文也介绍了基于策略算法的一个实例。
本文介绍一个结合了基于值和基于策略优势的方案:Actor-Critic。
Actor-Critic介绍
首先我们回顾下PolicyGradient算法,R(\tau)作为一个Loss幅值计算,它需要在一次探索完成后进行学习,学习过程比较慢,而且由于是要考虑多个step过程,累计多步的回报,计算的R值方差会比较大。如果我们将R的形式进行调整,使用td_error来作为R,优点是方差小,但是因为用到逼近方法,计算的策略梯度存在偏差。如果结合基于值的策略方案,这种不用累计一次探索再进行学习,而可以单步学习,提升学习效率。这里td_error需要的V值用一个近似估计采用一个网络来预测,可以将这个网络叫做Critic,因为他的作用就是用来评价每一步的动作选取的好坏。这样就是在PolicyGradient算法上引入了基于值算法的网络。也就是Actor-Critic的主要思路。
优化过程如下图:
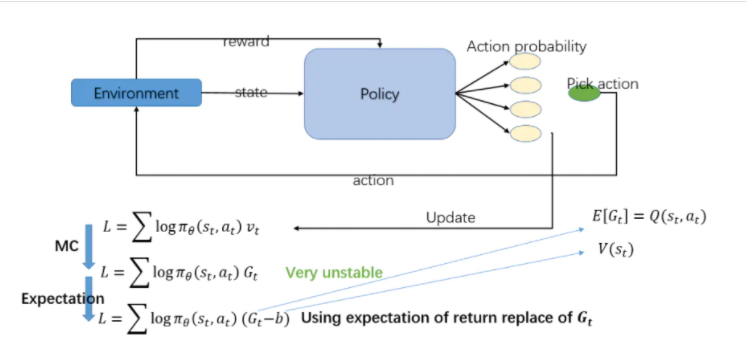
总结一下,Actor网络是基于PolicyGradient,是一个基于策略的学习。Critic是基于Q-learning,基于值的学习。在PolicyGradient学习中我们已经了解了他是需要一次探索结束后才能进行学习,而Q-learning是可以单步更新。
根据字面意思,Actorc是演员,Critic是评论家,Actor的作用就是决策出下一动作是什么,而Critic网络就是指出执行的动作是好还是坏。
Actor的目标是最大化期望reward,Critic的目标是更新现实和估计的误差(TD error)。基于PG的方法我们创建一个Actor网络,然后再创建Critic网络来计算Q函数值(希望Actor策略下的估计和现实Q值误差小),就是Actor-Critci方法。
所以我们可以认为actor预测动作的概率,critic根据actor的动作评价动作的得分,Actor根据Critic的评分调整选择动作的概率学习方向。
AC方法的优点:可以进行单步更新,不需要等待一次探索结束再计算长期效益
AC方法的缺点:需要更新两个网络,Actor的更新取决Critic的评价,训练过程中难收敛。
Actor-Critic实例一
下面我们还是通过代码来更深刻的理解AC方法,还是解决cartpole问题。其中R(\tau)我们使用td_error时序差分的微分思想。
这里学习过程和PolicyGradient不同,不用等待一次探索,而是每个step进入learn。
探索过程:
# 开始探索训练
for i_episode in range(MAX_EPISODE):
s = env.reset()
t = 0
track_r = []
while True:
if RENDER: env.render()
# 使用actor网络选取动作
a = actor.choose_action(s)
# 得到每步动作后新的状态值和即刻回报r
s_, r, done, info = env.step(a)
# 探索结束(杆倒),设置r为负数
if done:
r = -20
track_r.append(r)
# 每个step,critic进行一次学习,得到td_error。
# gradient = grad[r + gamma * V(s_) - V(s)]
td_error = critic.learn(s, r, s_)
# 每个step,actor进行一次学习,同时critic会指导学习方向
# actor的目标:true_gradient = grad[logPi(s,a) * td_error]
actor.learn(s, a, td_error)Cricit网络和loss计算,其中loss使用td_error,最小化td_error的平方作为目标优化参数,目的是用近似的值函数接近真实的值函数。
class Critic(object):
def __init__(self, sess, n_features, lr=0.01):
self.sess = sess
# 状态
self.s = tf.placeholder(tf.float32, [1, n_features], "state")
# 执行actor的状态值函数
self.v_ = tf.placeholder(tf.float32, [1, 1], "v_next")
# 即刻回报
self.r = tf.placeholder(tf.float32, None, 'r')
# 两层全链接,预测
with tf.variable_scope('Critic'):
# 两层全连接层,预测状态值函数
l1 = tf.layers.dense(
inputs=self.s,
units=20, # number of hidden units
activation=tf.nn.relu, # None
# have to be linear to make sure the convergence of actor.
# But linear approximator seems hardly learns the correct Q.
kernel_initializer=tf.random_normal_initializer(0., .1), # weights
bias_initializer=tf.constant_initializer(0.1), # biases
name='l1'
)
self.v = tf.layers.dense(
inputs=l1,
units=1, # output units
activation=None,
kernel_initializer=tf.random_normal_initializer(0., .1), # weights
bias_initializer=tf.constant_initializer(0.1), # biases
name='V'
)
with tf.variable_scope('squared_TD_error'):
# TD_error = (r+gamma*V_next) - V_eval
self.td_error = self.r + GAMMA * self.v_ - self.v
self.loss = tf.square(self.td_error)
with tf.variable_scope('train'):
self.train_op = tf.train.AdamOptimizer(lr).minimize(self.loss)
def learn(self, s, r, s_):
# 学习 状态的价值 (state value), 不是行为的价值 (action value),
# 计算 TD_error = (r + v_) - v,
# 用 TD_error 评判这一步的行为有没有带来比平时更好的结果,
# return # 学习时产生的 TD_error
s, s_ = s[np.newaxis, :], s_[np.newaxis, :]
v_ = self.sess.run(self.v, {self.s: s_})
td_error, _ = self.sess.run([self.td_error, self.train_op],
{self.s: s, self.v_: v_, self.r: r})
return td_error再来看看Actor网络和loss计算,其中目标是最大化log_prob * self.td_error。
对于这里的loss之前有个疑问,critic目的是让td_error越来越小,那在actor网络里如何指导的呢?
我们可以假设如果达到了最佳状态,采取的动作反馈到环境中的值函数和估计的值函数一致了,也说明策略收敛了。
在收敛之前,如果r+V(t+1)-V(t)大说明选取的动作好,我们要向这个方向继续学习;
反之,如果r+V(t+1)-V(t)小,说明选择的动作小于状态值期望,我们向这个方向学习幅度就要 小点。
# 创建Actor网络
class Actor(object):
def __init__(self, sess, n_features, n_actions, lr=0.001):
self.sess = sess
# 状态值
self.s = tf.placeholder(tf.float32, [1, n_features], "state")
# 动作值
self.a = tf.placeholder(tf.int32, None, "act")
# critic学习得到的td_error
self.td_error = tf.placeholder(tf.float32, None, "td_error")
with tf.variable_scope('Actor'):
# 两层全链接层,得到动作概率
l1 = tf.layers.dense(
inputs=self.s,
units=20, # number of hidden units
activation=tf.nn.relu,
kernel_initializer=tf.random_normal_initializer(0., .1),
bias_initializer=tf.constant_initializer(0.1),
name='l1'
)
self.acts_prob = tf.layers.dense(
inputs=l1,
units=n_actions,
activation=tf.nn.softmax,
kernel_initializer=tf.random_normal_initializer(0., .1),
bias_initializer=tf.constant_initializer(0.1),
name='acts_prob'
)
with tf.variable_scope('exp_v'):
# 只计算采取动作的概率
log_prob = tf.log(self.acts_prob[0, self.a])
# td_error = (r+gamma*V_next) - V_eval
self.exp_v = tf.reduce_mean(log_prob * self.td_error)
with tf.variable_scope('train'):
# 和PG一样,为了最大化self.exp_v,所以最小化-self.exp_v
self.train_op = tf.train.AdamOptimizer(lr).minimize(-self.exp_v)
def learn(self, s, a, td):
""" Actor进行学习
:param s: 状态
:param a: 动作
:param td: 来自critic,指导Actor对不对
:return:
"""
s = s[np.newaxis, :]
feed_dict = {self.s: s, self.a: a, self.td_error: td}
_, exp_v = self.sess.run([self.train_op, self.exp_v], feed_dict)
return exp_v
def choose_action(self, s):
""" 根据actor网络选择动作
:param s: 状态
:return: 根据概率选择动作
"""
s = s[np.newaxis, :]
probs = self.sess.run(self.acts_prob, {self.s: s})
# 根据action得到的概率选取动作(不使用max,增加一点探索性)
return np.random.choice(np.arange(probs.shape[1]), p=probs.ravel())以上就是使用Actor-Critic算法的一个示例,其中Critic网络中使用了TD-error,而根据上面的分析td-error有个特点是低方差但是高偏差,我们在使用r+\gamma*V(t+1)作为值函数的V(t)的估计量近似过程中是一直存在误差的。下一章我们介绍使用优势函数替换td-error的方案来优化这种偏差。
参考:
https://www.jianshu.com/p/9632f10bc590
https://mofanpy.com/tutorials/machine-learning/reinforcement-learning/actor-critic/
https://www.jianshu.com/p/9632f10bc590
原文地址:https://cloud.tencent.com/developer/article/1948578
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。