
- paper: Don't stop Pretraining: Adapt Language Models to Domains and Tasks
- GitHub: https://github.com/allenai/dont-stop-pretraining
论文针对预训练语料和领域分布,以及任务分布之间的差异,提出了DAPT领域适应预训练(domain-adaptive pretraining)和TAPT任务适应预训练(task-adaptive pretraining)两种继续预训练方案,并在医学论文,计算机论文,新闻和商品评价4个领域上进行了测试。想法很简单就是在垂直领域上使用领域语料做继续预训练,不过算是开启了新的训练范式,从之前的pretrain+fintune,到pretrain+continue pretrain+finetune
核心要点主要有以下4个
- 和预训练差异越大的领域,领域适应继续预训练的效果提升越显著
- 任务适应预训练轻量好使,效果也不差
- 领域预训练+任务预训练效果最好,不过成本较高
- 通过KNN扩展任务语料,能逼近领域预训练的效果

DAPT
首先作者通过每个领域内的Top10K高频词的重合度,来衡量领域之间,以及领域和预训练语料的文本相似度,相似度News>Reviews>Bio>CS。我们预期DAPT的效果会和相似度相关,理论上在相似度低的领域,继续预训练应该带来更大的提升。

训练部分作者复用了Roberta的预训练方案。为了保证4个领域可比,作者通过样本采样,以及不同的batch size保证了4个领域的step相同。为了防止灾难遗忘,作者只在领域数据上继续训练了1个epoch(12.5K steps)。除了News领域,其他领域的继续预训练都带来了MLM Loss的下降。
在下游分类任务微调中,继续训练的模型效果都显著优于原始Roberta,和预训练语料差异更大的领域CS,Bio整体的效果提升更显著,如下

为了剔除更多的训练样本可能带来的效果提升,作者按以上的语料相关性,每个领域都选择了相关性最低的另一个领域的继续预训练模型(¬DAPT),对比在下游微调中的效果,部分场景有提升部分有下降,但是都显著低于对应领域的继续预训练模型,从而进一步证明继续预训练的收益来自对应领域信息的补充。
TAPT
TAPT是使用任务样本直接进行继续训练。Task Adaptive和Domain Adaptive的主要区别是,Task对应的数据集更小训练成本更低,不过因为直接使用任务数据,所以和任务的相关度更高。对应以上DAPT训练1个epoch(12.5K steps), TAPT训练100个epoch,每个epochs使用15%的Random Delete来进行样本增强。
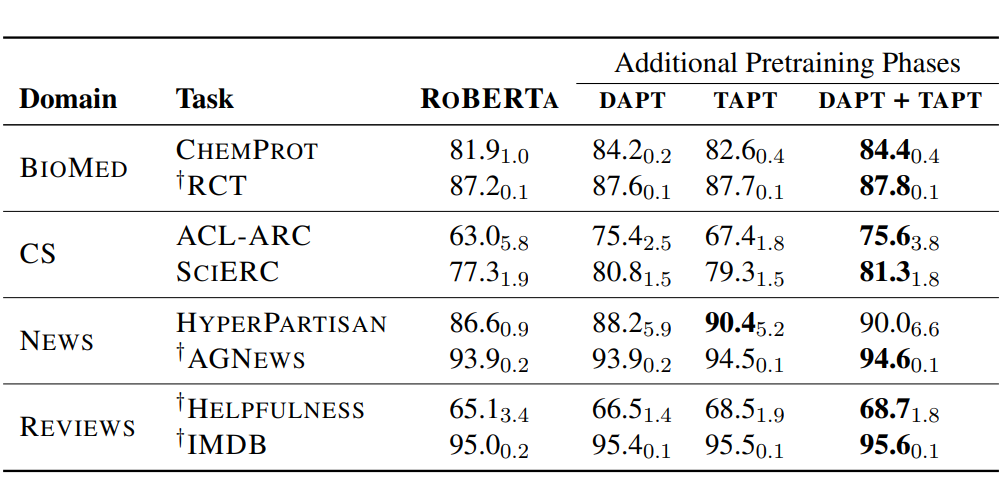
作者对比了只使用DAPT,TAPT以及先使用DAPT+TAPT的效果:整体上DAPT+TAPT的继续预训练效果最好。其中针对更加垂直(和预训练语料相关性更小)的领域DAPT更好。感觉主要是因为领域垂直,TAPT受限于样本量能提供的领域信息不足,容易过拟和。而和预训练语料更相似的新闻领域和评论领域,TAPT的效果甚至超过DAPT,如下
作者进一步尝试了Cross Task Transfer,就是使用相同领域中任务1做继续预训练,然后在任务2上进行微调。效果显著低于使用相同任务的语料做T继续训练,这进一步说明了相同领域不同任务间的语料分布也是存在差异的,所以在部分任务上TAPT的效果要优于DAPT。
那能否在保留当前任务分布的前提下,拓展任务相关语料,解决TAPT样本量不足的问题呢?比较直观的方案就是使用文本Embedding,从相同领域的样本中,使用KNN抽取任务对应的K个相似样本来扩充任务样本。作者使用的是词袋模型VAMPIRE来计算文本表征,对比了不同参数K的效果,500KNN已经逼近DAPT。如果你有耐心>_<的话,KNN配合TAPT确实算是更优的方案,它的预训练成本显著低于DAPT,但又比TAPT的效果以及泛化性要显著更好

领域差异
说了半天继续预训练可以提高下游任务的效果,不过究竟继续预训练干了啥??这部分在作者也没有很详细的证明,所以我们只能借助相关paper来猜想一哈~
- 领域词汇/实体/ngram差异: 垂直领域和通用领域的主要差异在专属实体和短语,也就是领域知识信息。继续预训练可以提供这部分的补充信息。不过这其实也challenge了论文复用Roberta的预训练方案并一定是最优方案,可能SpanBert或者ERNIE,甚至K-Bert对应的知识增强,实体掩码方案更合适
- 整体语料差异: 除知识之外,常规的文本表达和上下文语境也存在整体差异,可以通过继续与训练来进行调整。
- 优化空间分布,提高线性可分性:在之前探测Bert Finetune对向量空间的影响中我们讨论过,微调其实是对预训练文本表征的空间分布进行了调整,使得在下游任务中空间分布更简单更加线性可分,这里猜测继续预训练其实也起到了类似的效果。
- 提高模型泛化:在下游任务微调中,模型往往只更新/依赖任务相关的局部信息,而继续预训练目标的设置使得模型能更全面的学习领域/任务相关的上下文知识,一定程度上提高模型的泛化能力,起到更优的bayesian prior的作用
案例
总结下,针对单任务模型,直接使用TAPT成本最低实用性最高,针对领域底层大模型,使用DAPT效果更好。不过使用起来具体使用哪种预训练方案,以及如何避免灾难遗忘,感觉还是要case by case的来看。一些相关的案例有
- 金融负面主体识别比赛:Rank3的方案就尝试了在任务语料上继续预训练,并且配合实体掩码相关的预训练方案来提升模型效果。
- 疫情期间民情识别比赛: 作者用比赛数据提供的任务样本,以及任务样本相关的未标注样本进行做curated tapt,平均准确率有1个点左右的提升
- 淘宝UGC情感分类:评论底层大模型,使用评论领域语料来继续预训练,用于上层的子任务
最近在复现一些比赛方案时,尝试了下在金融负面主体这个任务中引入TAPT,因为是实体相关的情感分类问题,因此在TAPT上使用了Whole Word和Entity粒度结合的MLM作为预训练目标。在使用多任务的基础上,使用TAPT进一步训练后F1进一步有0.2%个点的提升,不过这个提升只有当预训练使用全部语料的时候才显著,如果和下游微调一样保留部分数据用于测试,则不会有显著的效果提升,这里的效果对比更支持上面的提高模型泛化能力这个假设~具体实现详见ClassicSolution/fin_neg_entity
原文地址:https://cloud.tencent.com/developer/article/2129633
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。