
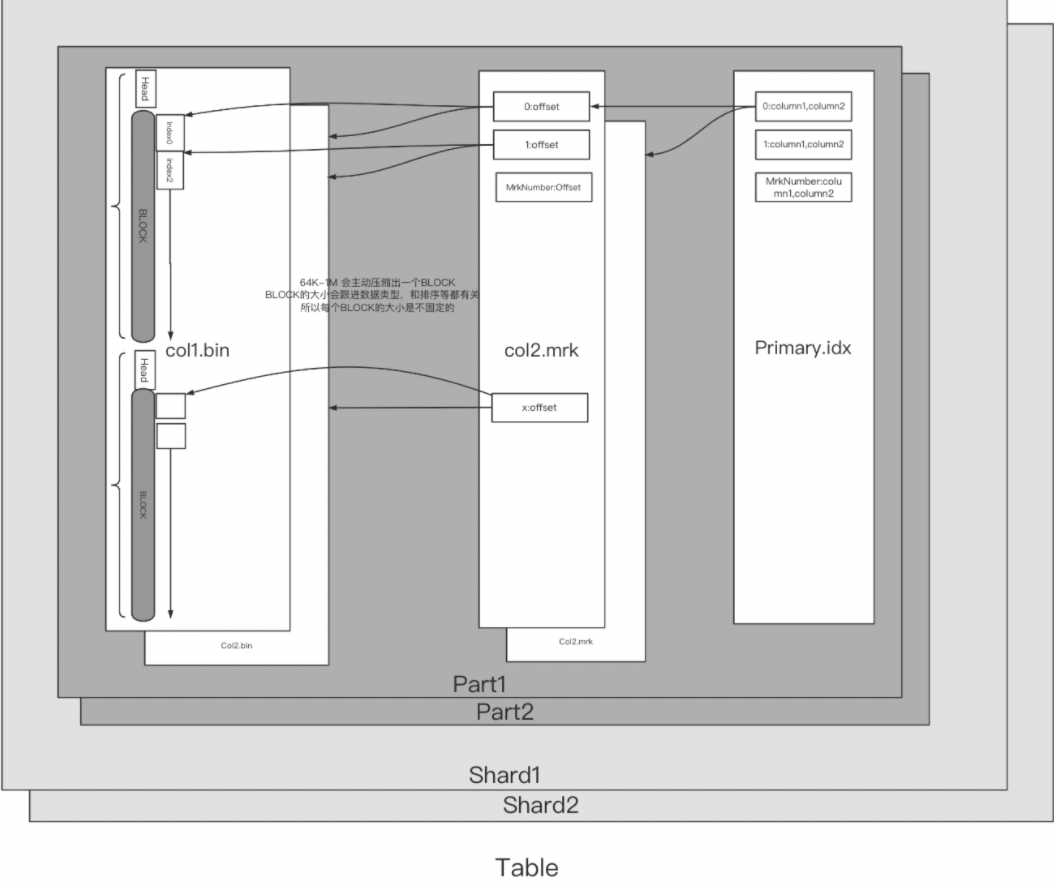
1 ClickHouse稀疏索引
个人理解(就是目录,就是每页的关键字 + 加关键字所在位置
index(第n个索引,关键字) ,
mrk(偏移,偏移对应的位置offset)
index->mrk->bin)
2 二级索引
关键字 |
说明 |
|---|---|
index name |
索引别名 |
Index expression |
索引源字段 |
Type |
minmax, set, bloom filter,map |
GRANULARITY |
索引粒度 ,如ClickHouse 默认稀疏索引默认是8192 ,我理解 8192*GRANULARITY就是 skip_index.mrk 的block 大小 |
skpidx{index_name}.idx |
which contains the ordered expression values) |
skpidx{index_name}.mrk2 |
which contains the corresponding offsets into the associated data column files. |
3 表索引设置
- use_skip_indexes (0 or 1, default 1). 默认过滤所有index
- force_data_skipping_indexes 强制使用哪个index
4 管理索引
-
ALTER TABLE [db].table_name [ON CLUSTER cluster] ADD INDEX name expression TYPE type GRANULARITY value [FIRST|AFTER name]- Adds index description to tables metadata. -
ALTER TABLE [db].table_name [ON CLUSTER cluster] DROP INDEX name- Removes index description from tables metadata and deletes index files from disk. -
ALTER TABLE [db.]table_name [ON CLUSTER cluster] MATERIALIZE INDEX name [IN PARTITION partition_name]- Rebuilds the secondary indexnamefor the specifiedpartition_name. Implemented as a mutation. IfIN PARTITIONpart is omitted then it rebuilds the index for the whole table data.
5 Example
CREATE TABLE table_name
(
u64 UInt64,
i32 Int32,
s String,
...
INDEX a (u64 * i32, s) TYPE minmax GRANULARITY 3,
INDEX b (u64 * length(s)) TYPE set(1000) GRANULARITY 4
) ENGINE = MergeTree()
SELECT count() FROM table WHERE s < 'z'
SELECT count() FROM table WHERE u64 * i32 == 10 AND u64 * length(s) >= 1234
CREATE TABLE data
(
key Int,
d1 Int,
d1_null Nullable(Int),
INDEX d1_idx d1 TYPE minmax GRANULARITY 1,
INDEX d1_null_idx assumeNotNull(d1_null) TYPE minmax GRANULARITY 1
)
Engine=MergeTree()
ORDER BY key;
SELECT * FROM data_01515;
SELECT * FROM data_01515 SETTINGS force_data_skipping_indices=''; -- query will produce CANNOT_PARSE_TEXT error.
SELECT * FROM data_01515 SETTINGS force_data_skipping_indices='d1_idx'; -- query will produce INDEX_NOT_USED error.
SELECT * FROM data_01515 WHERE d1 = 0 SETTINGS force_data_skipping_indices='d1_idx'; -- Ok.
SELECT * FROM data_01515 WHERE d1 = 0 SETTINGS force_data_skipping_indices='`d1_idx`'; -- Ok (example of full featured parser).
SELECT * FROM data_01515 WHERE d1 = 0 SETTINGS force_data_skipping_indices='`d1_idx`, d1_null_idx'; -- query will produce INDEX_NOT_USED error, since d1_null_idx is not used.
SELECT * FROM data_01515 WHERE d1 = 0 AND assumeNotNull(d1_null) = 0 SETTINGS force_data_skipping_indices='`d1_idx`, d1_null_idx'; -- Ok.6 索引类型

7 支持哪些函数
Function (operator) / Index |
primary key |
minmax |
ngrambf_v1 |
tokenbf_v1 |
bloom_filter |
|---|---|---|---|---|---|
equals (=, ==) |
✔ |
✔ |
✔ |
✔ |
✔ |
notEquals(!=, <>) |
✔ |
✔ |
✔ |
✔ |
✔ |
like |
✔ |
✔ |
✔ |
✔ |
✗ |
notLike |
✔ |
✔ |
✔ |
✔ |
✗ |
startsWith |
✔ |
✔ |
✔ |
✔ |
✗ |
endsWith |
✗ |
✗ |
✔ |
✔ |
✗ |
multiSearchAny |
✗ |
✗ |
✔ |
✗ |
✗ |
in |
✔ |
✔ |
✔ |
✔ |
✔ |
notIn |
✔ |
✔ |
✔ |
✔ |
✔ |
less (<) |
✔ |
✔ |
✗ |
✗ |
✗ |
greater (>) |
✔ |
✔ |
✗ |
✗ |
✗ |
lessOrEquals (<=) |
✔ |
✔ |
✗ |
✗ |
✗ |
greaterOrEquals (>=) |
✔ |
✔ |
✗ |
✗ |
✗ |
empty |
✔ |
✔ |
✗ |
✗ |
✗ |
notEmpty |
✔ |
✔ |
✗ |
✗ |
✗ |
hasToken |
✗ |
✗ |
✗ |
✔ |
✗ |
8 Demo
https://clickhouse.com/docs/en/guides/improving-query-performance/skipping-indexes#skip-best-practices
1 创建 默认 8192 的稀疏索引
CREATE TABLE skip_table
(
my_key UInt64,
my_value UInt64
)
ENGINE MergeTree primary key my_key
SETTINGS index_granularity=8192;
INSERT INTO skip_table SELECT number, intDiv(number,4096) FROM numbers(100000000);
SELECT * FROM skip_table WHERE my_value IN (125, 700)
┌─my_key─┬─my_value─┐
│ 512000 │ 125 │
│ 512001 │ 125 │
│ ... | ... |
└────────┴──────────┘2 创建 8192 * 2 的二级索引
ALTER TABLE skip_table ADD INDEX vix my_value TYPE set(100) GRANULARITY 2;
/*ALTER TABLE xx ADD INDEX game_id_index game_id TYPE bloom_filter(0.01) GRANULARITY 1;*/3 生效历史数据
ALTER TABLE skip_table MATERIALIZE INDEX vix;4 验证
SELECT * FROM skip_table WHERE my_value IN (125, 700)
┌─my_key─┬─my_value─┐
│ 512000 │ 125 │
│ 512001 │ 125 │
│ ... | ... |
└────────┴──────────┘
8192 rows in set. Elapsed: 0.051 sec. Processed 32.77 thousand rows, 360.45 KB (643.75 thousand rows/s., 7.08 MB/s.)
see detail
SET send_logs_level='trace';
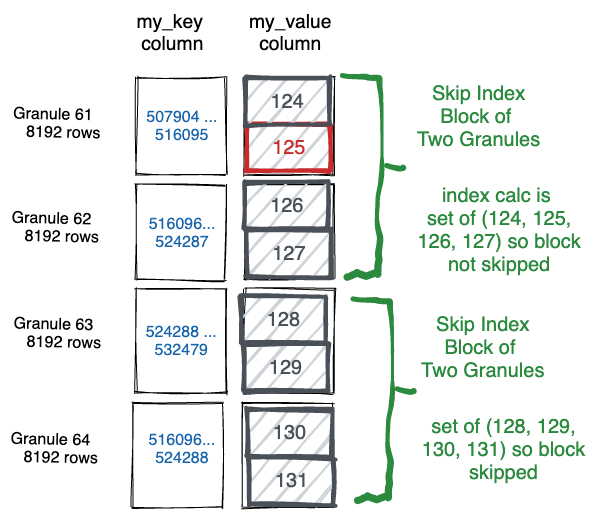
<Debug> default.skip_table (933d4b2c-8cea-4bf9-8c93-c56e900eefd1) (SelectExecutor): Index `vix` has dropped 6102/6104 granules.下方为图形解释,每个稀疏索引为 8192*2 ,索引每2两个Granule为一个Skip Index ,1 Block
原文地址:https://cloud.tencent.com/developer/article/2066560
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。