
这篇文章全称叫做《Learning to Quantize Deep Networks by Optimizing Quantization Intervals with Task Loss》,由1Samsung Advanced Institute of Technology公开发表。
摘要
降低权重和activation(在这篇文章中可理解为上层激活层的输出,即当前层的输入)的bit-width 会让网络计算效率更高,但是通常会降低网络精度。为了最大程度的保持精度,文章提出了一种方法用于量化权重和activation, 降低他们的bitwidth, 同时不会带来较多的精度损失。这个方法是应用于模型训练中的,当推理时,只需要使用量化时的结果即可。
方法论
本文提出的方法基本思想:在网络训练过程中,量化器会学习到最佳的数据范围,此范围内的数据会被量化,以外的数据将会被clamp,这种量化是在训练过程中逐渐学习到的,与task loss 相关,因此能最大程度的减少量化的损失,提升网络精度。
本文的量化器分为两部分,转化器(transformer)和离散器(discretizer)。
转化器主要是将权重或是activation进行归一化,范围为(0,1)或(-1, 1),转化器最简单的方法就是除以权重或者activation的最大值,另一种方法是使用函数tanh 或者clip, 但文中并未使用两种方法。
离散器会将归一化的值转变为离散值。
在文中,参数化了量化器的转化器,使其可训练,这样可以与网络权重联合优化。首先来看转化器的表达式:
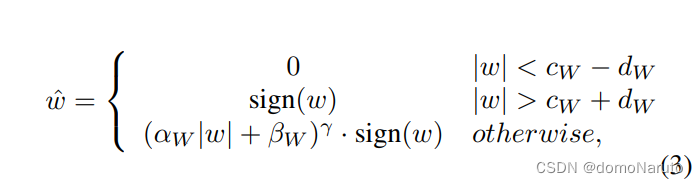
其中 w 代表原始权重值,表示w的绝对值,
, 其中
表示可量化数据范围的中心,
表示量化范围边界与中心点的距离。由公式可以看出,转化器会学习到一个合适的数据中心点
, 范围大小为
, 范围外的数据将会被clamp成0 或1 或-1。细心计算可以知道,最后一个公式就是将 w 进行了归一化,正数范围为(0, 1) , 负数范围为(-1, 0),总结来看,所有的数据将会归一化到(-1,1)。
也是一个可学习的参数,用于拟合不同的数据分布引入的。
针对activation的量化,文中进行了简化处理,这样处理有利于整体网络在训练时的效率。具体公式如下:
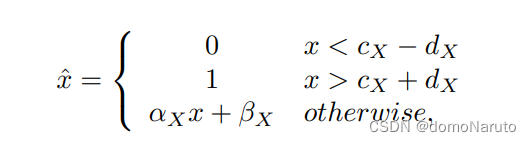
实验
实验证明了此文章的方法不会显著降低网络模型的精度,基于resnet 和 alexnet的结果如下:
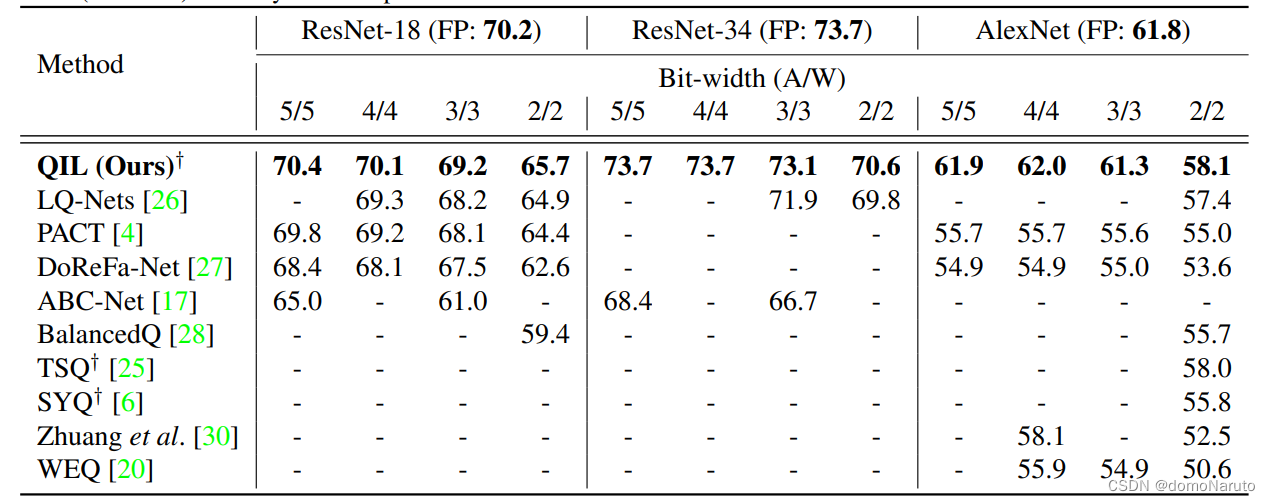
文章中做了联合训练和直接量化的对比,显示在低bit-width 的量化情形下,文章提出的方法更能保持精度,效果很明显很好。为了证明权重转化器的重要性及有效性,在保持activation 精度不变的情况下,作者做了对比实验,将权重量化的bitwidth 逐步缩小(即通常会引入较大误差),实验结果如下:
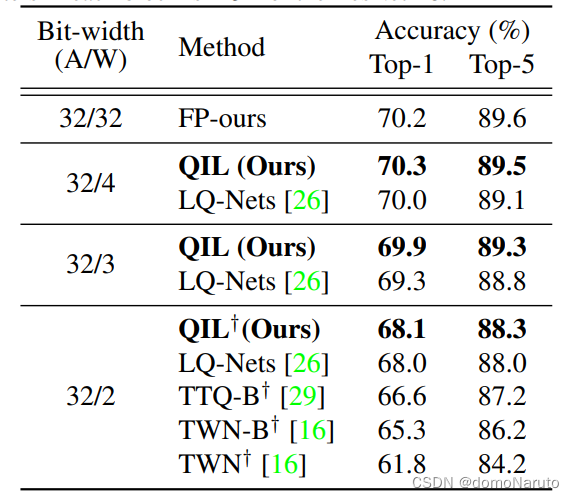
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。