
模块概述
在NLP处理中,分词的目标就是是把输入的文本流,切分成一个个子串,每个子串相对有完整的语义,便于学习embedding表达和后续模型的使用。有三种粒度,分别是word、subword、char。
word/词,词,是最自然的语言单元。对于英文等自然语言来说,存在着天然的分隔符,如空格或一些标点符号等,对词的切分相对容易。但是对于一些东亚文字包括中文来说,就需要某种分词算法才行。顺便说一下,Tokenizers库中,基于规则切分部分,采用了spaCy和Moses两个库。如果基于词来做词汇表,由于长尾现象的存在,这个词汇表可能会超大。像Transformer XL库就用到了一个26.7万个单词的词汇表。这需要极大的embedding matrix才能存得下。embedding matrix是用于查找取用token的embedding vector的。这对于内存或者显存都是极大的挑战。常规的词汇表,一般大小不超过5万。
char/字符,即最基本的字符,如英语中的’a’,‘b’,‘c’或中文中的’你’,‘我’,'他’等。而一般来讲,字符的数量是少量有限的。这样做的问题是,由于字符数量太小,我们在为每个字符学习嵌入向量的时候,每个向量就容纳了太多的语义在内,学习起来非常困难。
subword/子词级,它介于字符和单词之间。比如说’Transformers’可能会被分成’Transform’和’ers’两个部分。这个方案平衡了词汇量和语义独立性,是相对较优的方案。它的处理原则是,常用词应该保持原状,生僻词应该拆分成子词以共享token压缩空间。
models模块实现许多分词算法,比如基于word-level的算法类WordLevel、基于subword-level的算法类BPE、Unigram、WordPiece,这些类都是Model的子类或者实现类,因为Model类是不能被实例化的。
对于Model类官方文档中的解释如下,意思是说Model主要用于处理所有sub-token的发现和生成,这是可训练且真正依赖于您的输入数据的部分:
Model: Handles all the sub-token discovery and generation, this is the part that is trainable and really dependent of your input data.
模块使用
1、WordLevel
tokenizers.models.WordLevel(vocab, unk_token)
实现了WordLevel算法。也就是将一个单词映射为一个id。
tokenizer = Tokenizer(WordLevel(unk_token = unk_token))
trainer = WordLevelTrainer(special_tokens = spl_tokens)
2、BPE
tokenizers.models.BPE(vocab = None, merges = None, cache_capacity = None, dropout = None, unk_token = None, continuing_subword_prefix = None, end_of_word_suffix = None, fuse_unk = None )
实现了BPE(Byte-Pair Encoding,字节对编码)算法。其核心思想在于将最常出现的子词对合并,直到词汇表达到预定的大小时停止。 BPE算法如下:
首先,它依赖于一种预分词器pretokenizer来完成初步的切分。pretokenizer可以是简单基于空格的,也可以是基于规则的;
分词之后,统计每个词出现的频次,供后续计算使用。例如,我们统计到了5个词的词频:
("hug", 10), ("pug", 5), ("pun", 12), ("bun", 4), ("hugs", 5)
然后建立基础词汇表,包括所有的字符,即:
["b", "g", "h", "n", "p", "s", "u"]
根据规则,我们分别考察2-gram,3-gram的基本字符组合,把高频的ngram组合依次加入到词汇表中,直到词汇表达到预定大小停止。比如,我们计算出ug/un/hug三种组合出现频次分别为20,16和15,加入到词汇表中。
最终词汇表的大小= 基础字符词汇表大小 + 合并串的数量,比如像GPT,它的词汇表大小 40478 = 478(基础字符) + 40000(merges)。如果遇到未知的单词,用unk来表示。添加完后,我们词汇表变成:
["b", "g", "h", "n", "p", "s", "u", "ug", "un", "hug"]
Byte-level BPE
BPE的一个问题是,如果遇到了unicode,基本字符集可能会很大。一种处理方法是我们以一个字节为一种“字符”,不管实际字符集用了几个字节来表示一个字符。这样的话,基础字符集的大小就锁定在了256。
tokenizer = Tokenizer(BPE(unk_token = unk_token))
trainer = BpeTrainer(special_tokens = spl_tokens)
BPE算法的实现:
import re, collections
def get_stats(vocab):
pairs = collections.defaultdict(int)
for word, freq in vocab.items():
symbols = word.split()
for i in range(len(symbols)-1):
pairs[symbols[i],symbols[i+1]] += freq
return pairs
def merge_vocab(pair, v_in):
v_out = {}
bigram = re.escape(' '.join(pair))
p = re.compile(r'(?<!\S)' + bigram + r'(?!\S)')
for word in v_in:
w_out = p.sub(''.join(pair), word)
v_out[w_out] = v_in[word]
return v_out
vocab = {'l o w </w>': 5, 'l o w e r </w>': 2, 'n e w e s t </w>': 6, 'w i d e s t </w>': 3}
num_merges = 1000
for i in range(num_merges):
pairs = get_stats(vocab)
if not pairs:
break
best = max(pairs, key=pairs.get)
vocab = merge_vocab(best, vocab)
print(best)
3、WordPiece
tokenizers.models.WordPiece(vocab, unk_token, max_input_chars_per_word )
实现了WordPiece算法。它的原理非常接近BPE,不同之处在于它做合并时,并不是直接找最高频的组合,而是基于概率生成新的subword。即它每次合并的两个字符串A和B,应该具有最大的值 P ( A B ) / P ( A ) P ( B ) P(AB)/P(A)P(B) P(AB)/P(A)P(B)。合并AB之后,所有原来切成A+B两个tokens的就只保留AB一个token,整个训练集上最大似然变化量与 P ( A B ) / P ( A ) P ( B ) P(AB)/P(A)P(B) P(AB)/P(A)P(B)成正比。
tokenizer = Tokenizer(WordPiece(unk_token = unk_token))
trainer = WordPieceTrainer(special_tokens = spl_tokens)
4、Unigram
tokenizers.models.Unigram(vocab)
实现了Unigram算法。与BPE或者WordPiece不同,Unigram的算法思想是从一个巨大的词汇表出发,再逐渐删除trim down其中的词汇,直到size满足预定义。Unigram算法如下:
初始的词汇表可以采用所有预分词器分出来的词,再加上所有高频的子串。每次从词汇表中删除词汇的原则是使预定义的损失最小。训练时,计算loss的公式为:
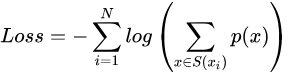
假设训练文档中的所有词分别为 x 1 , x 2 , . . . , x N x_1,x_2,...,x_N x1,x2,...,xN ,而每个词tokenize的方法是一个集合 S ( x i ) S(x_i) S(xi)。当一个词汇表确定时,每个词tokenize的方法集合 S ( x i ) S(x_i) S(xi)就是确定的,而每种方法对应着一个概率 p ( x ) p(x) p(x)。如果从词汇表中删除部分词,则某些词的tokenize的种类集合就会变少,log(*)中的求和项就会减少,从而增加整体loss。
Unigram算法每次会从词汇表中挑出使得loss增长最小的10%~20%的词汇来删除。一般Unigram算法会与SentencePiece算法连用。
到目前为止描述的所有标记化算法都有相同的问题:假设输入文本使用空格来分隔单词。但是,并非所有语言都使用空格来分隔单词,例如中文、日文和泰文。
SentencePiece,顾名思义,它是把一个句子看作一个整体,再拆成片段,而没有保留天然的词语的概念。一般地,它把空格space也当作一种特殊字符来处理,再用BPE或者Unigram算法来构造词汇表。SentencePiece 是对子词单元的重新实现,也是一种subword-level算法。SentencePiece 支持两种分割算法,byte-pair-encoding (BPE)和Unigram语言模型。
tokenizer = Tokenizer(Unigram())
trainer = UnigramTrainer(unk_token= unk_token, special_tokens = spl_tokens)
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。