
二、数据清洗、转换
此实验使用S3作为数据源
ETL:
E extract 输入
T transform 转换
L load 输出
大纲
简易架构图
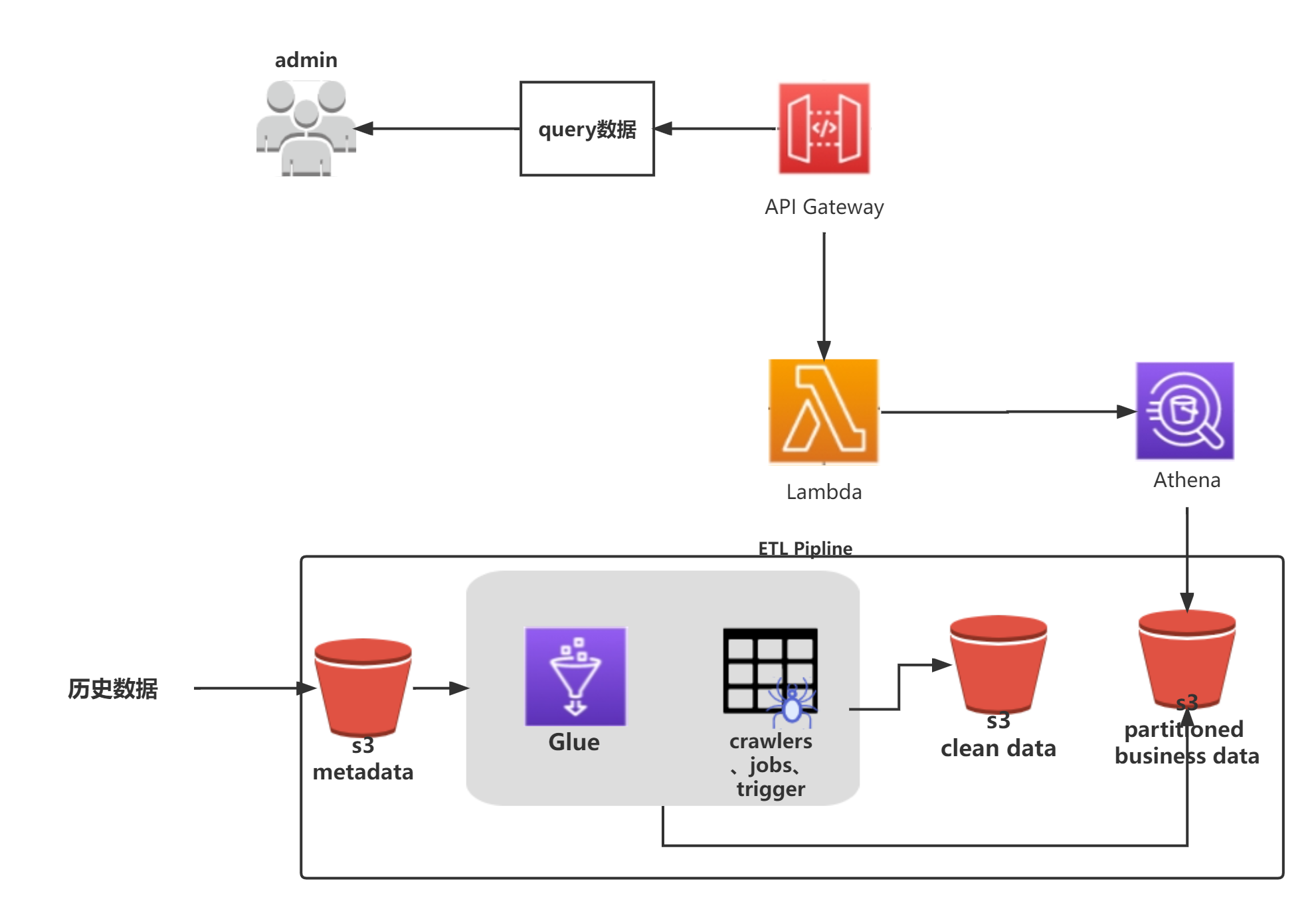
2.1、数据清洗
此步会将S3中的原始数据清洗成我们想要的自定义结构的数据。之后,我们可通过APIGateway+Lambda+Athena来实现一个无服务器的数据分析服务。
| 步骤 | 图例 |
|---|---|
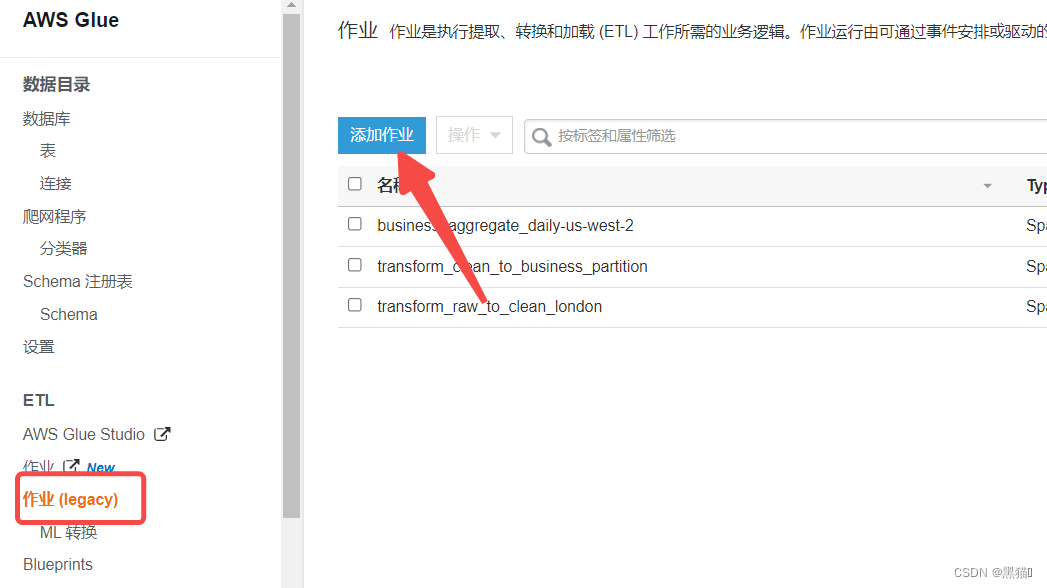
| 1、入口 |
|
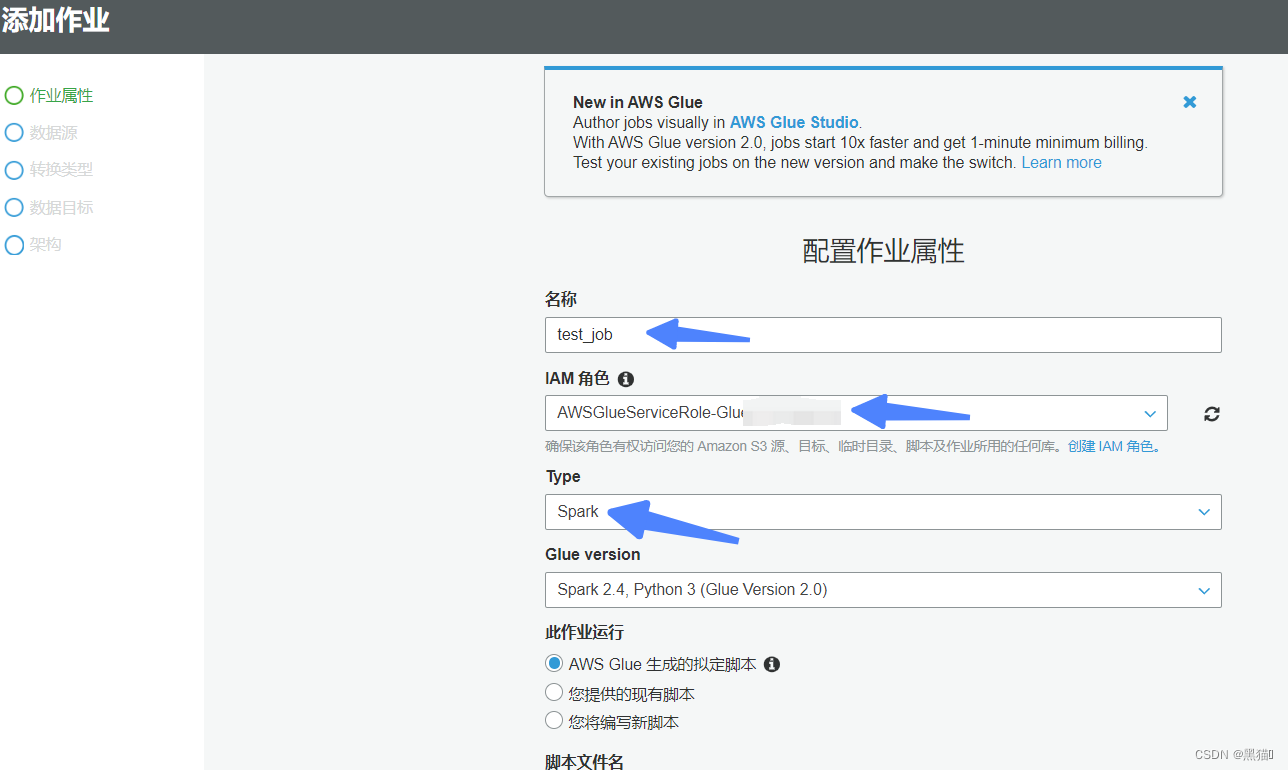
| 2、创建Job(s3作为数据源,则Type选择Spark,若为Kinesis等,选择Stream Spark) |
|
| 3、IAM角色需要有s3与Glue的权限 |
|
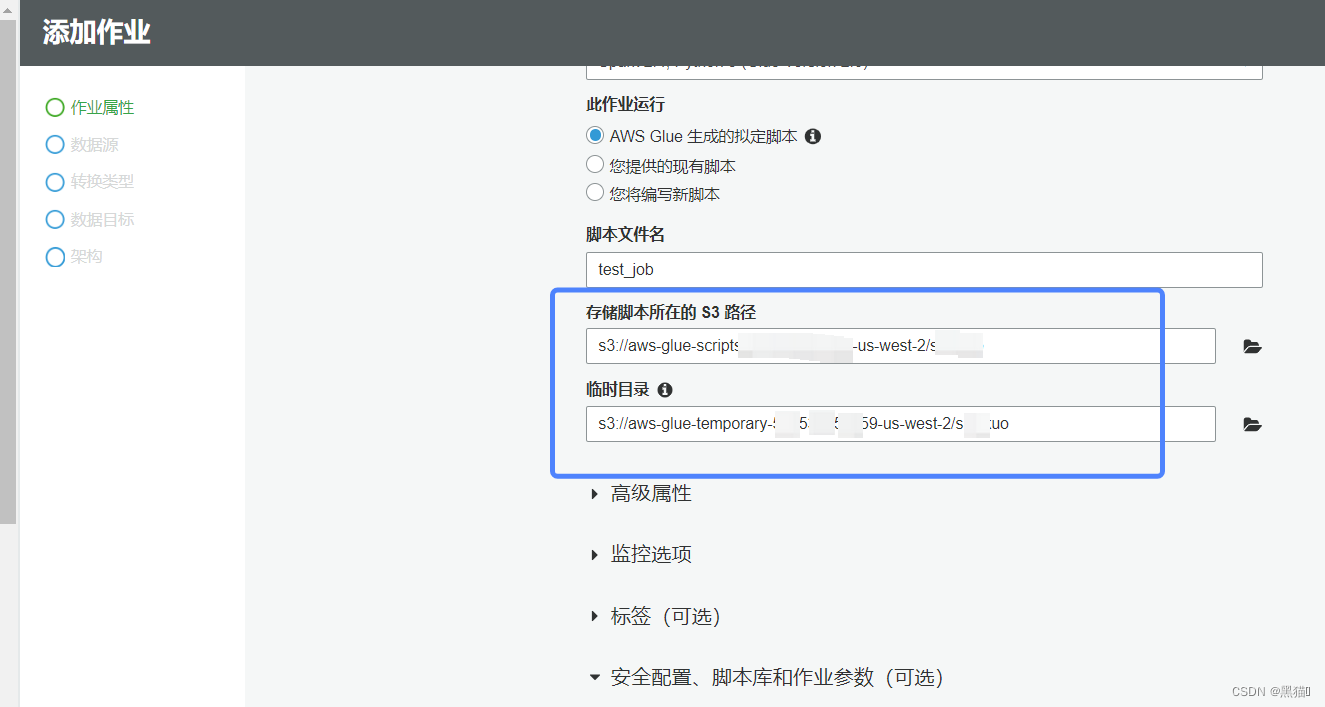
| 4、选择s3脚本位置,若已经完成脚本的编写工作,则可以选择第二项或第三项,若无则Glue会提供默认脚本 |
|
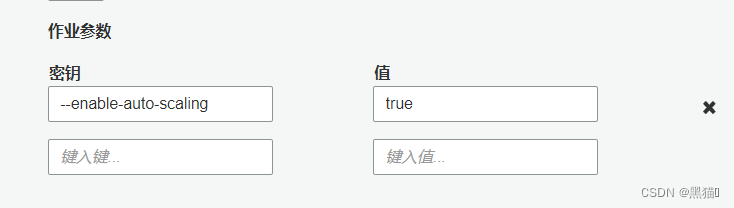
| 5、安全配置参数 |
|
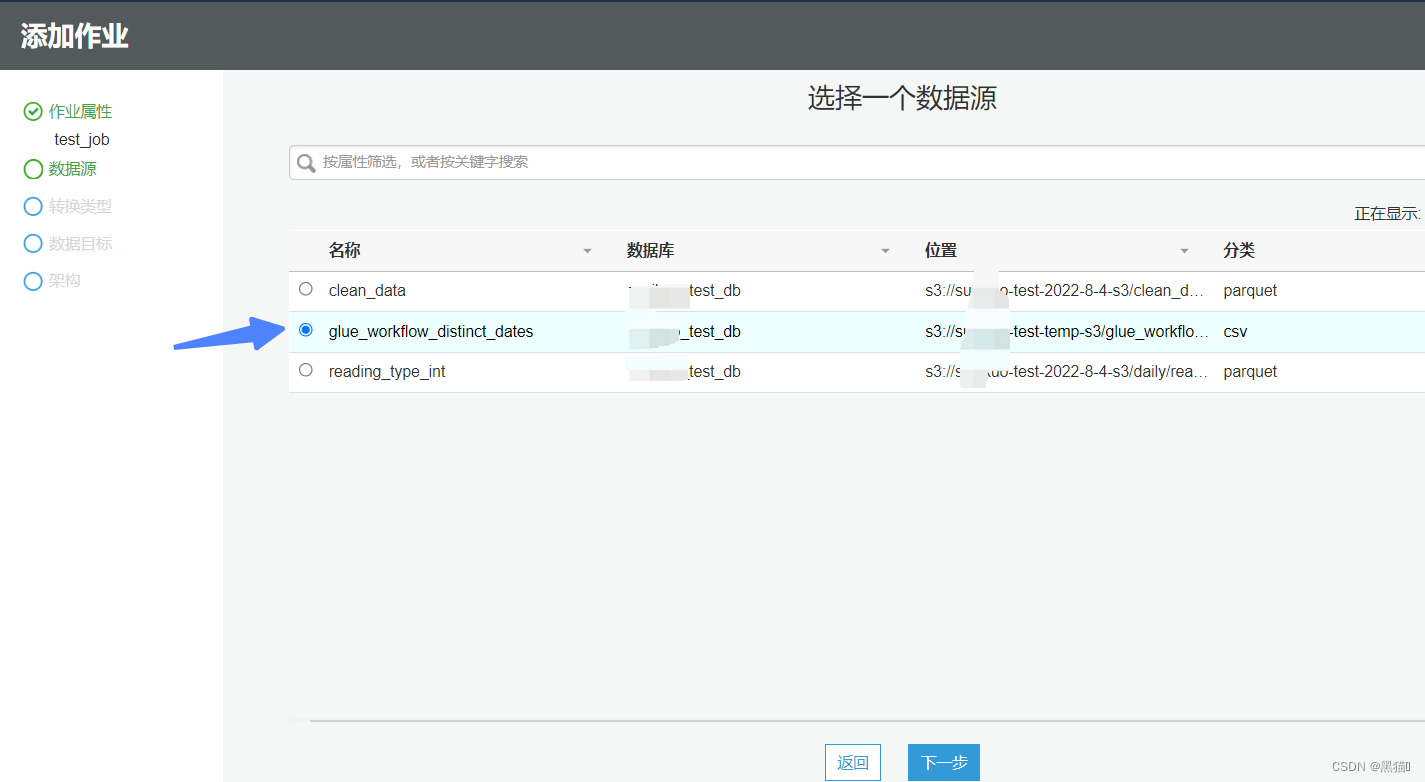
| 6、数据源() |
|
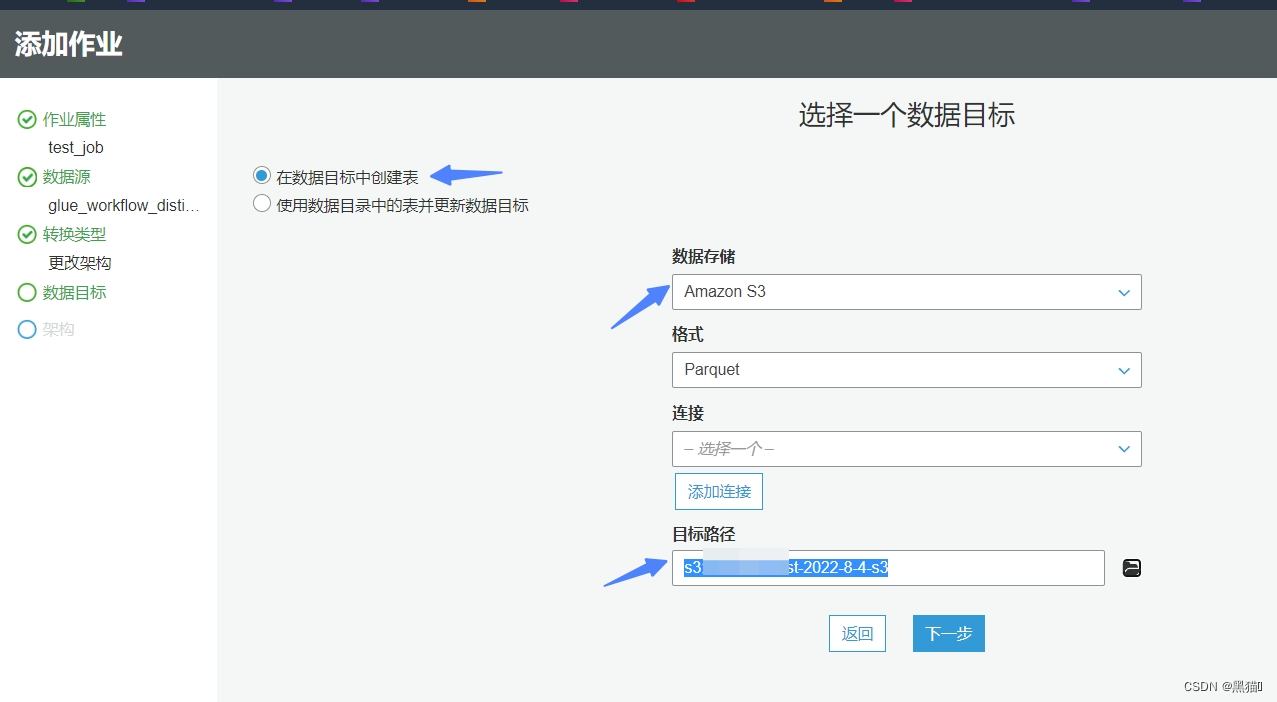
| 7、数据目标(我们会将清洗后的数据存储到新的s3桶) |
|
| 8、设计架构(在本案例中,我们会自定义脚本。所以不再在此处设计架构)(此处设计后,脚本会自动生成相关代码) |
|
| 9、保存 |
|
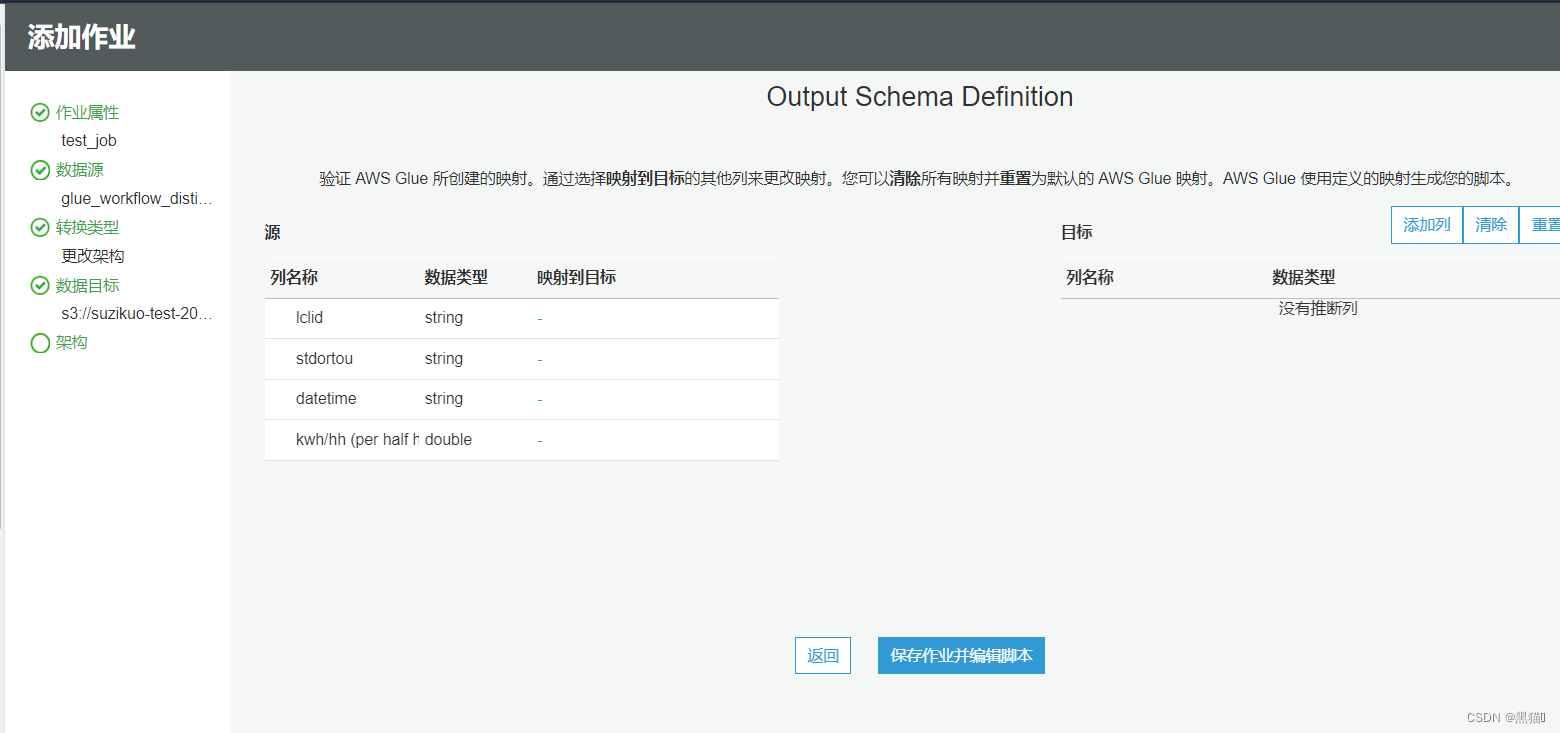
2.2、编辑脚本
脚本中的args参数的键值需要从Job的安全配置参数中定义
2.2.1、连接数据源(s3)
#数据源
datasource = glueContext.create_dynamic_frame.from_catalog(database = args['db_name'], table_name = tableName, transformation_ctx = "datasource")
2.2.2. 数据结构转换
mapped_readings = ApplyMapping.apply(frame = datasource, mappings = [("lclid", "string", "meter_id", "string"), \
("datetime", "string", "reading_time", "string"), \
("KWH/hh (per half hour)", "double", "reading_value", "double")], \
transformation_ctx = "mapped_readings")
2.2.3、数据结构拆分、定义
mapped_readings_df = DynamicFrame.toDF(mapped_readings)
mapped_readings_df = mapped_readings_df.withColumn("obis_code", lit(""))
mapped_readings_df = mapped_readings_df.withColumn("reading_type", lit("INT"))
reading_time = to_timestamp(col("reading_time"), "yyyy-MM-dd HH:mm:ss")
mapped_readings_df = mapped_readings_df \
.withColumn("week_of_year", weekofyear(reading_time)) \
.withColumn("date_str", regexp_replace(col("reading_time").substr(1,10), "-", "")) \
.withColumn("day_of_month", dayofmonth(reading_time)) \
.withColumn("month", month(reading_time)) \
.withColumn("year", year(reading_time)) \
.withColumn("hour", hour(reading_time)) \
.withColumn("minute", minute(reading_time)) \
.withColumn("reading_date_time", reading_time) \
.drop("reading_time")
2.2.4、清洗后的数据写入新s3
# write data to S3
filteredMeterReads = DynamicFrame.fromDF(mapped_readings_df, glueContext, "filteredMeterReads")
s3_clean_path = "s3://" + args['clean_data_bucket']
glueContext.write_dynamic_frame.from_options(
frame = filteredMeterReads,
connection_type = "s3",
connection_options = {"path": s3_clean_path},
format = "parquet",
transformation_ctx = "s3CleanDatasink")
2.2.5、运行作业
执行成功后,状态将变为"SUCCESS",失败将会给出失败信息,可在CloudWatch 中查看详情
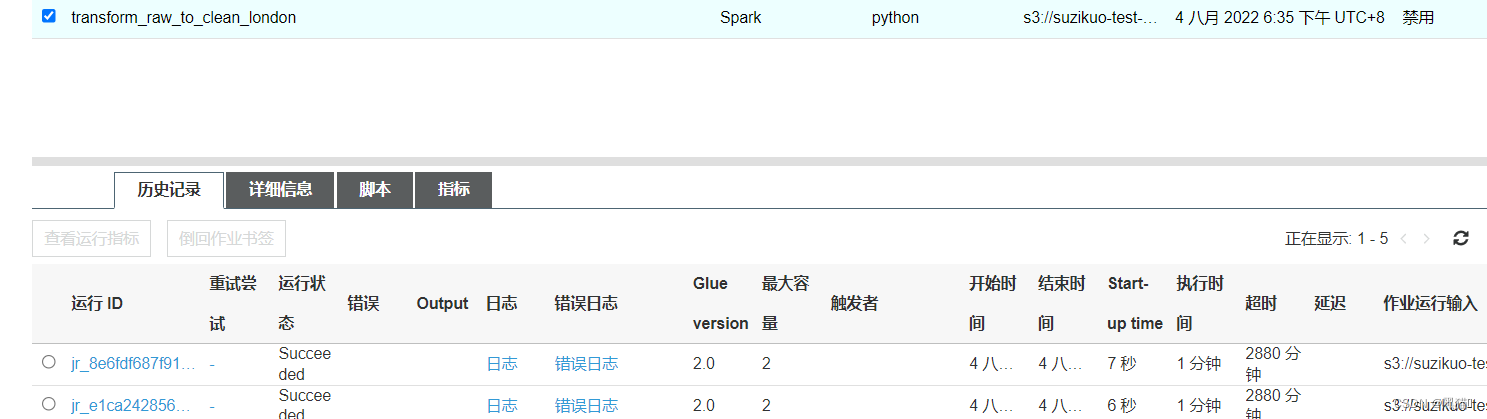
清洗后的数据保存到了s3
数据清洗完毕后,可通过上一篇中的爬网程序步骤,将清洗后的数据的结构创建表到数据目录中,
此时我们可以使用Athena对清洗后的数据进行分析。
2.3、数据分区
接下来我们对数据进行分区处理(此处只提供了按天分区)
重新进行数据清洗中的创建Job操作后,重写脚本
2.3.1、编辑脚本
连接数据源。表为上一步最后重新爬取生成的新表。
cleanedMeterDataSource = glueContext.create_dynamic_frame.from_catalog(database = args['db_name'], table_name = tableName, transformation_ctx = "cleanedMeterDataSource")
根据type与data_str分区
business_zone_bucket_path_daily = "s3://{}/daily".format(args['business_zone_bucket'])
businessZone = glueContext.write_dynamic_frame.from_options(frame = cleanedMeterDataSource, \
connection_type = "s3", \
connection_options = {"path": business_zone_bucket_path_daily, "partitionKeys": ["reading_type", "date_str"]},\
format = "parquet", \
transformation_ctx = "businessZone")
2.3.2、运行脚本
分区后的数据结果:
再次创建、运行爬网程序,将会在数据目录中生成新的分区表。
2.4、总结
到这一步,我们已经使用Glue ETL对s3桶中的数据进行了清洗、分区操作。在进行上篇中的Athena操作后,我们已经可以通过Athena直接查询到清洗、分区后的数据集了。
接下来,我们会通过使用APIGateway+Lambda+Athena来构建一个无服务器的数据查询分析服务。
作者
Zikuo Su
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。