
文章目录
基操:准备数据,准备模型,查看属性
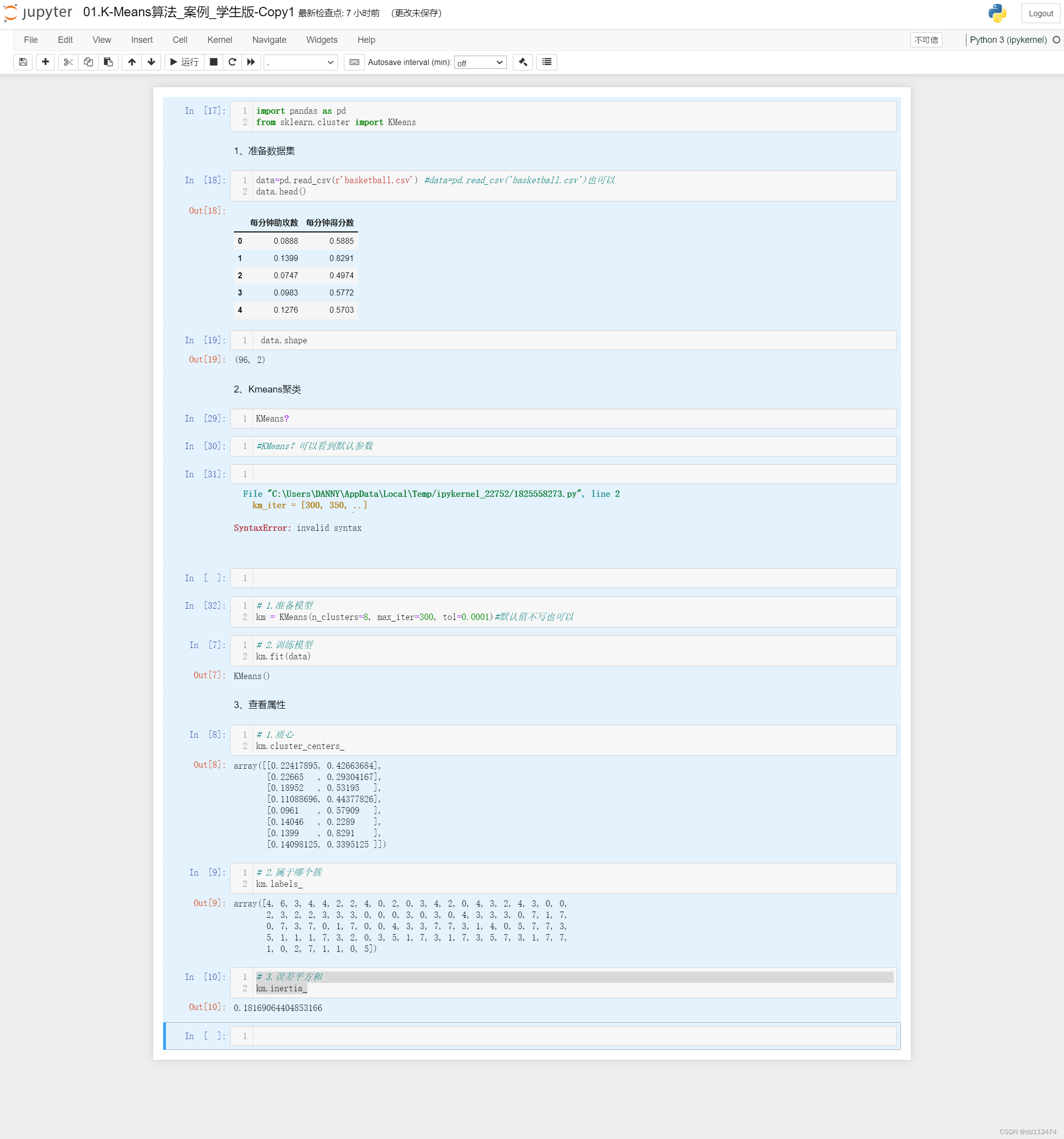
import pandas as pd
from sklearn.cluster import KMeans
1、准备数据集
data=pd.read_csv(r'basketball.csv') #data=pd.read_csv('basketball.csv')也可以
data.head()
data.shape
2、Kmeans聚类
KMeans?
#KMeans?可以看到默认参数
# 1.准备模型
km = KMeans(n_clusters=8, max_iter=300, tol=0.0001)#默认值不写也可以
# 2.训练模型
km.fit(data)
3、查看属性
# 1.质心
km.cluster_centers_
# 2.属于哪个簇
km.labels_
# 3.误差平方和
km.inertia_
最优参数模型(画出迭代的Dataframe)
import pandas as pd
from sklearn.cluster import KMeans
1、准备数据集
data=pd.read_csv(r'basketball.csv') #data=pd.read_csv('basketball.csv')也可以
data.head()
data.shape
2、Kmeans聚类
KMeans?
#KMeans?可以看到默认参数
df=pd.DataFrame(columns=["i","j","tol","差平方和"])
df.loc[0,:]=(1,2,3,4)
df
cluster = [2, 3, 4]
km_iter = [300, 350, ..]
tol?
for i in cluster:
for j in km_iter:
for m in tol:
km = KMeans(n_clusters=i, max_iter=j, tol=m)
km.fit(data)
km.inertia_
# 1.准备模型
km = KMeans(n_clusters=8, max_iter=300, tol=0.0001)#默认值不写也可以
# 2.训练模型
km.fit(data)
3、查看属性
# 1.质心
km.cluster_centers_
# 2.属于哪个簇
km.labels_
# 3.误差平方和
km.inertia_
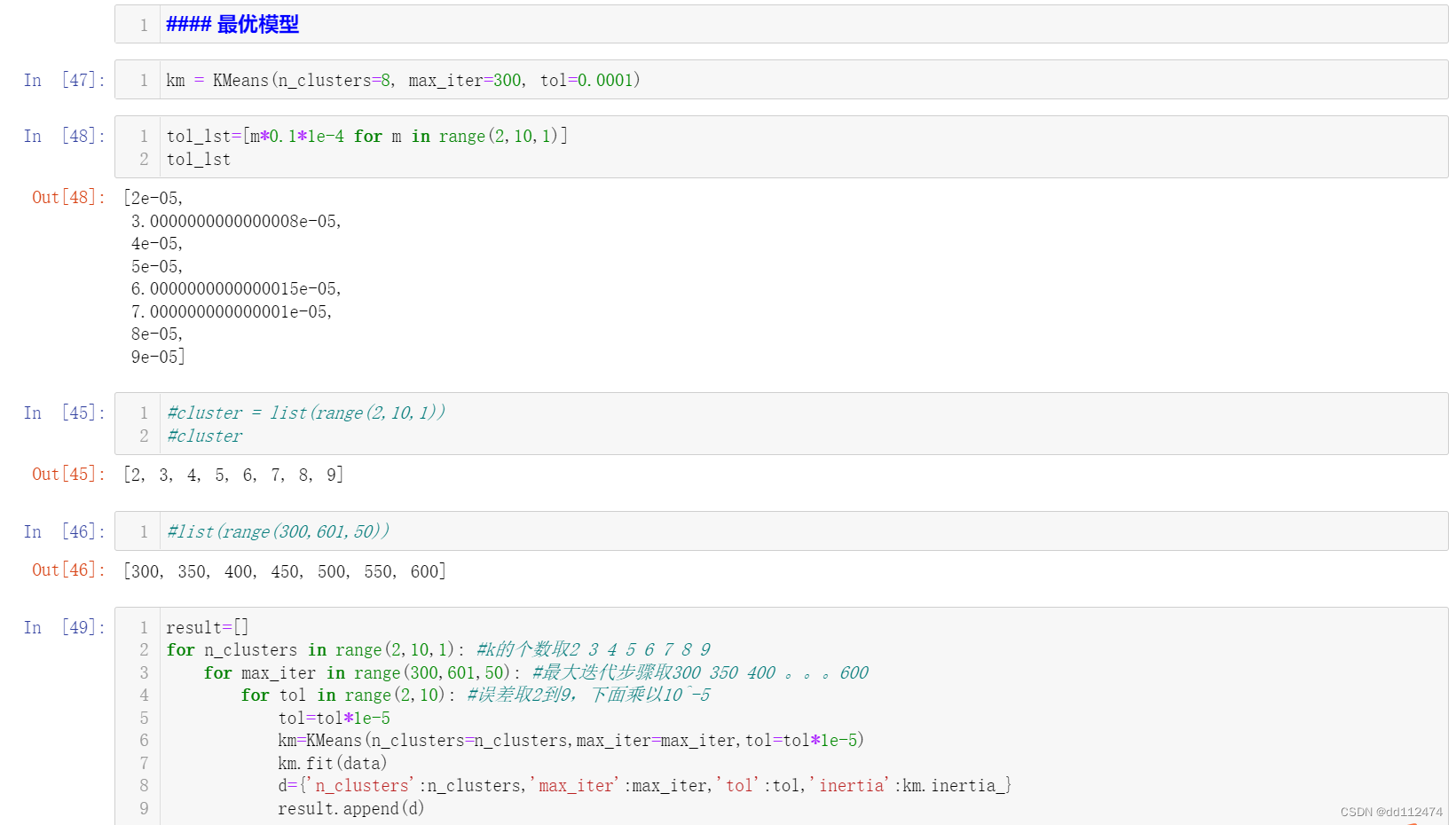
#### 最优模型
km = KMeans(n_clusters=8, max_iter=300, tol=0.0001)
tol_lst=[m*0.1*1e-4 for m in range(2,10,1)]
tol_lst
#cluster = list(range(2,10,1))
#cluster
#list(range(300,601,50))
result=[]
for n_clusters in range(2,10,1): #k的个数取2 3 4 5 6 7 8 9
for max_iter in range(300,601,50): #最大迭代步骤取300 350 400 。。。600
for tol in range(2,10): #误差取2到9,下面乘以10^-5
tol=tol*1e-5
km=KMeans(n_clusters=n_clusters,max_iter=max_iter,tol=tol*1e-5)
km.fit(data)
d={'n_clusters':n_clusters,'max_iter':max_iter,'tol':tol,'inertia':km.inertia_}
result.append(d)
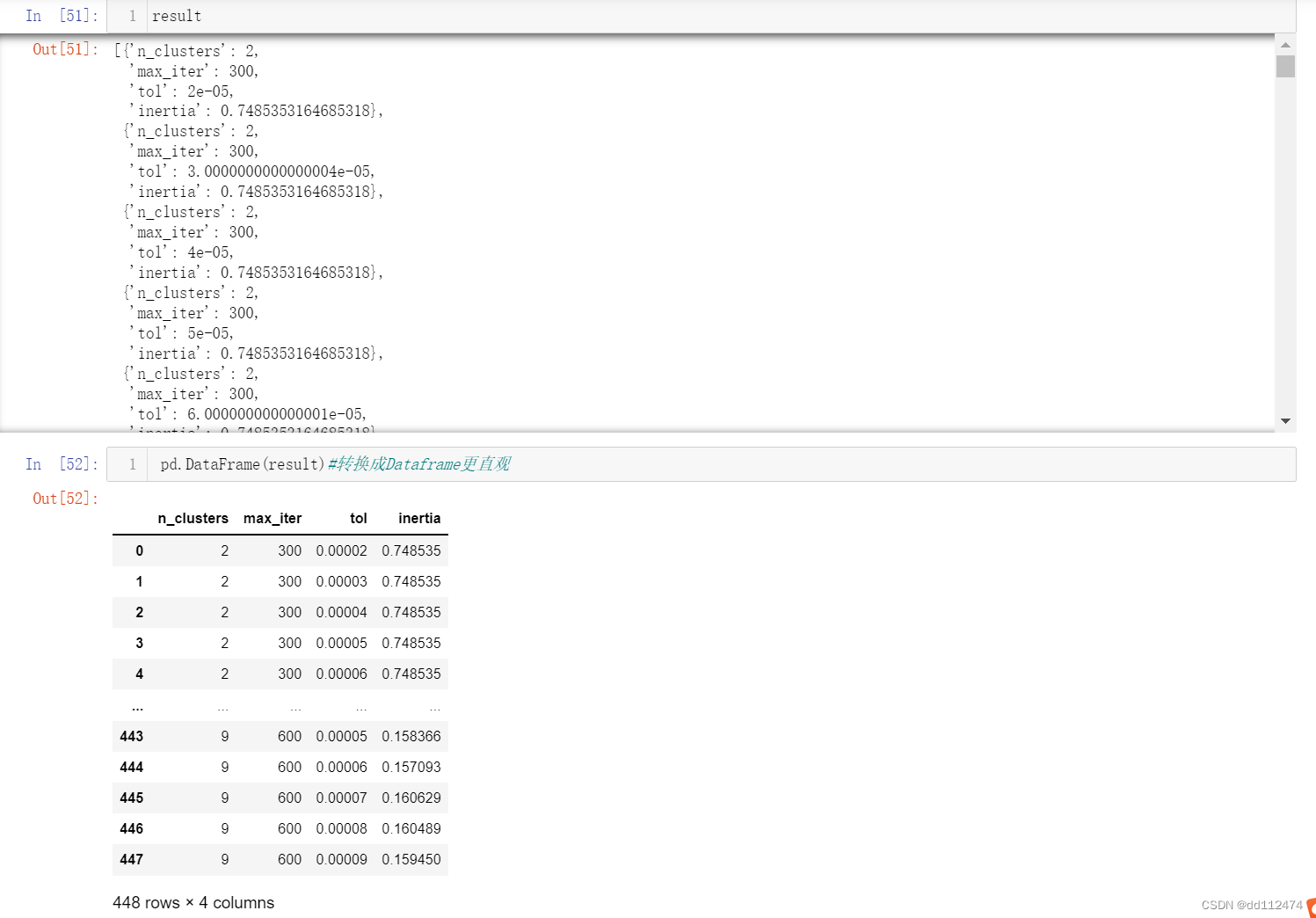
result
pd.DataFrame(result)#转换成Dataframe更直观
在Dataframe里面找到最优的tol(误差平方和),以及该行的其他参数(innertia,n_clusters,max_iter)
1,找到Dataframe里inertia这一列中的最小值:argmin()
result_df('inertia').argmin()
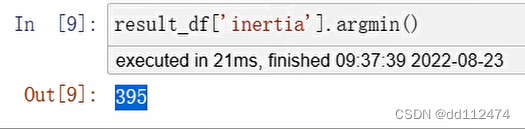
返回395,也就是说第395行(索引标号)的inertia最小
2,用.iloc[ , ]根据索引标号找出所需的那一行(,前面是行索引,后面是列索引,不要列用:表示)
result_df.iloc[result_df('inertia').argmin(),:]
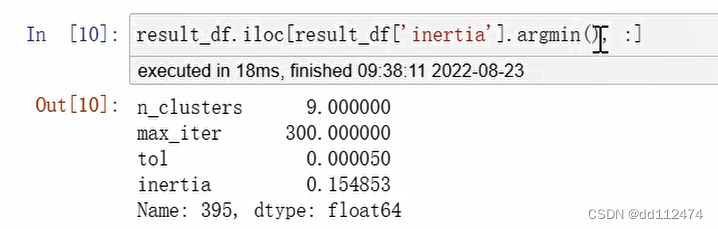
3,一行数据就是一个series,可以使用type()查看数据类型
r = result_df.iloc[result_df('inertia').argmin(),:]
type(r)
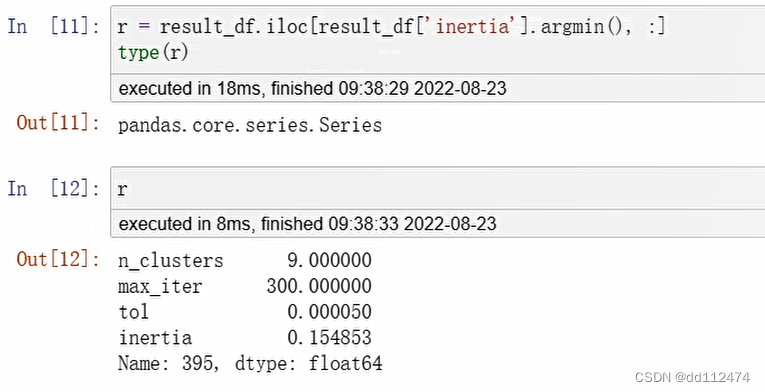
4,返回值的代码
n_clusters = r['n_clusters']
n_clusters
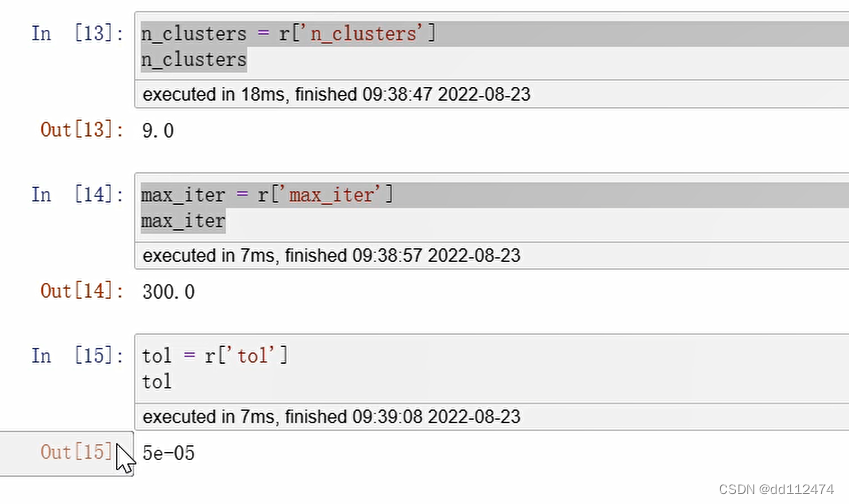
画出折线图
1,保存n_clusters、误差平方和,先建立两个列表
x = []#放k值n_cluster
y = []#放误差平方和inertia
2,循环打印出k=[2,20), 用for XXX in range( , ):
(注:5000条数据以下一般不超过10个簇,5000以上不超过20个)
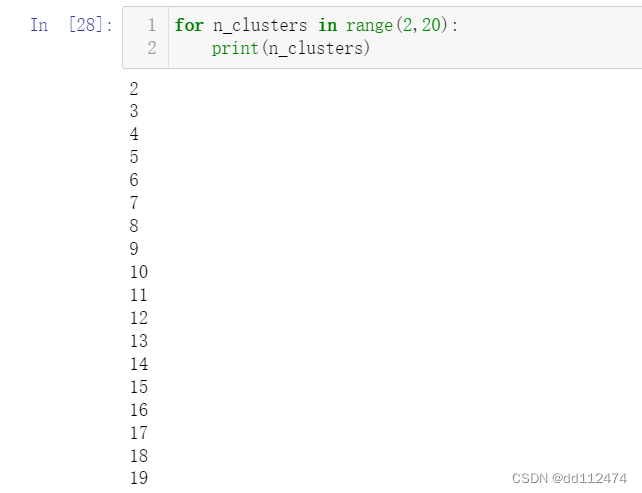
for n_clusters in range(2,20):
print(n_clusters)
3,准备模型(公式)
km=KMeans(三个参数n_clusters,max_iter,tol)
km.fit(数据集)
km=KMeans(n_clusters=n_clusters,max_iter=max_iter,tol=tol)
km.fit(data)
4,保存生成的数据,inertia(簇内误差平方和)和k个数(n_clusters)
用.appen()
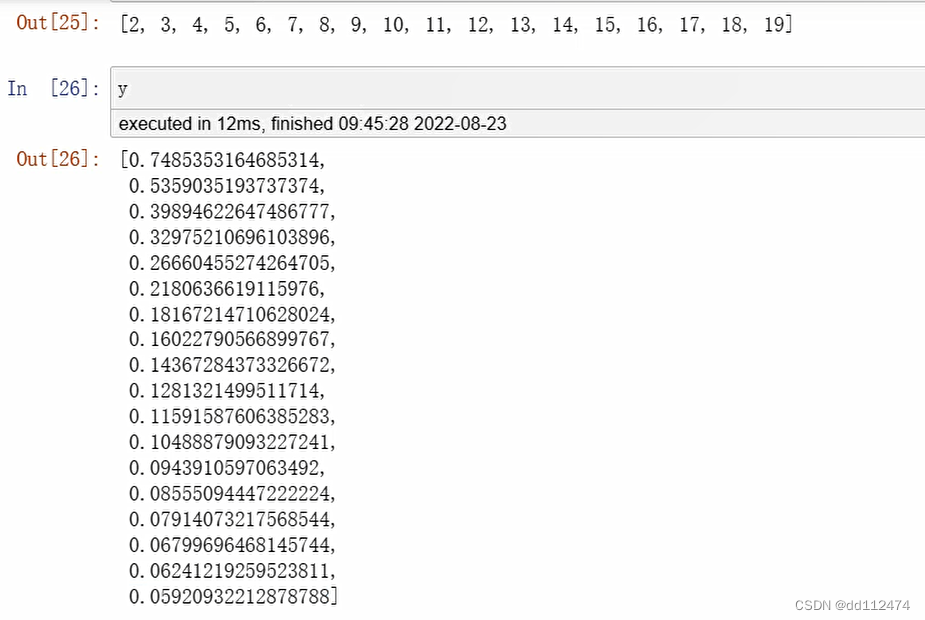
x.append(n_clusters)
y.append(km.inertia_)#inertia是属性,要写成km.inertia_

5,运行报错,调整字符类型 float–>int

max_inter是float类型,而kmeans要求是int,所以在前面强制转换max_inter
max_iter = int(r['max_iter'])
max_iter

成功运行,打印出x,y
6,需要作图,在第一行添加
from matplotlib import pyplot as plt
创建一张画布
plt.figure(figsize(20,8),dpi=100)
创建x,y轴、标签以及题目
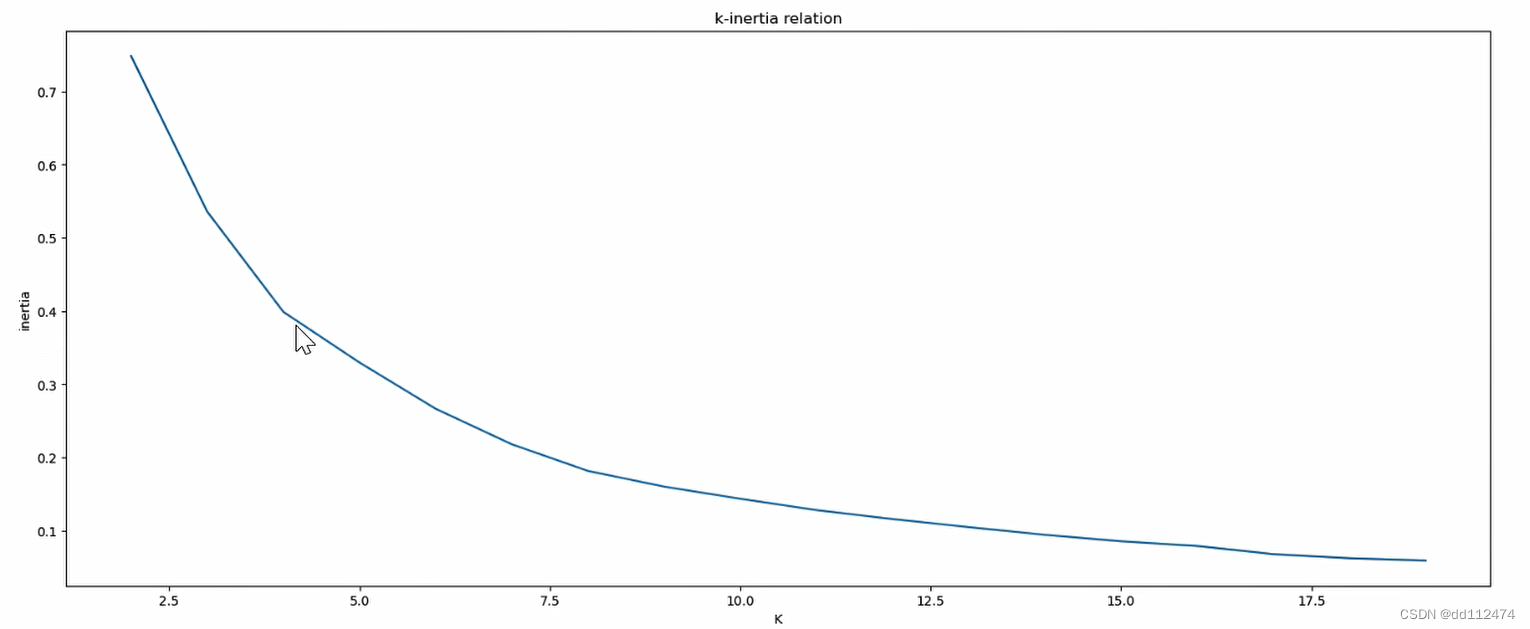
plt.plot(x,y)
plt.xlabel('k')
plt.ylabel('inertia')
plt.title('k-inertia relation')
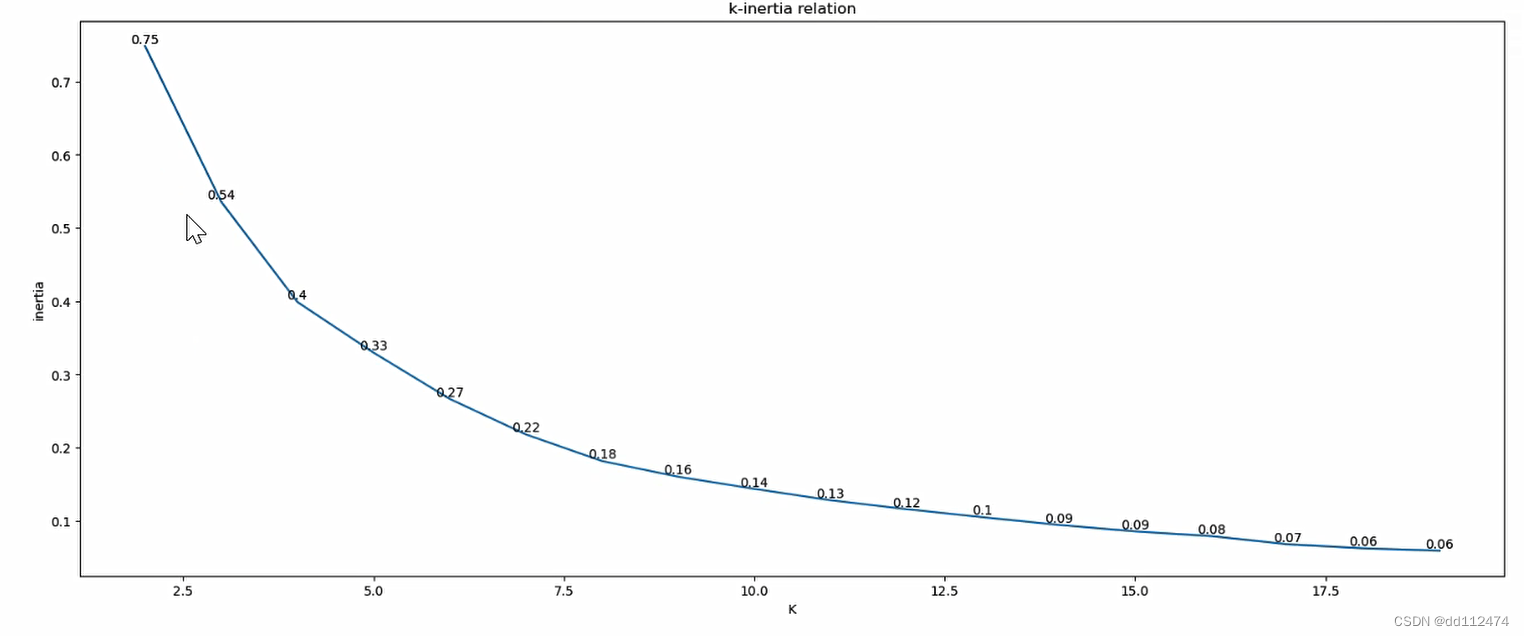
效果
在图上标注点和数据 :用zip( ,)把x,y值组合成坐标(x,y)
调整坐标文本显示位置:round(b,2)是保留两位小数,ha和va控制水平垂直
for a,b in zip(x,y):
plt.text(a,b,round(b,2),ha='center',va='bottom')

全文代码
import pandas as pd
from sklearn.cluster import KMeans
from matplotlib import pyplot as plt
1、准备数据集
data = pd.read_csv(r'basketball.csv')
data.head()
data.shape
2、Kmeans聚类
# 1.准备模型
km = KMeans(n_clusters=8, max_iter=300, tol=0.0001)
# 2.训练模型
km.fit(data)
3、查看属性
# 1.质心
km.cluster_centers_
# 2.属于哪个簇
km.labels_
data
# 3.误差平方和
km.inertia_
4、最优模型
result = []
for n_clusters in range(2,10):
for max_iter in range(300,601,50):
for tol in range(2,10):
tol=tol*1e-5
km = KMeans(n_clusters=n_clusters, max_iter=max_iter, tol=tol)
km.fit(data)
d = {'n_clusters':n_clusters, 'max_iter':max_iter, 'tol':tol, 'inertia': km.inertia_}
result.append(d)
result
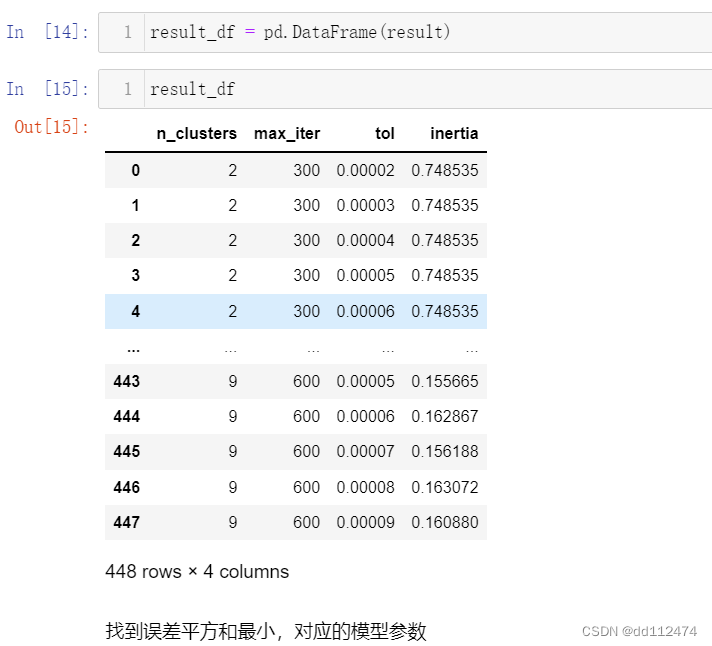
result_df = pd.DataFrame(result)
result_df
找到误差平方和最小,对应的模型参数
r = result_df.iloc[result_df['inertia'].argmin(), :]
type(r)
#iloc[]是利用索引切片只留下想要的行和列 参考:https://www.py.cn/faq/python/18973.html
#argmin()是找到当前行或列的最小值 此时最小为0.160880下标为447,就转换为r = result_df.iloc[[447], :]
r
n_clusters = r['n_clusters']
n_clusters
max_iter = int(r['max_iter'])
max_iter
tol = r['tol']
tol
选择合适的K值
data.head()
data.shape
x = []
y = []
for n_clusters in range(2,20):
print(n_clusters)
km = KMeans(n_clusters=n_clusters, max_iter=max_iter, tol=tol)
km.fit(data)
# 保存n_clusters、误差平方和
x.append(n_clusters)
y.append(km.inertia_)
x
y
用n_clusters(k)作为横坐标,误差平方和作为中坐标---折线图(最优k)
plt.figure(figsize=(20, 8), dpi=100)
plt.plot(x, y)
plt.xlabel('K')
plt.ylabel('inertia')
plt.title('k-inertia relation')
# 将数字标注到折线图中
for a, b in zip(x, y):
plt.text(a, b, round(b, 2), ha='center', va='bottom')
手写笔记

版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。