
记录一个pytorch训练机器学习模型的代码,代码内容包括:数据库建立、数据预处理、特征分析与提取、神经模型定义、模型训练与验证、模型拟合结果输出等部分,模拟效果见下图。

一、数据介绍
数据长度为116列2699行,记录了美国各州与新冠相关的一些特征。前一部分为各州编码,后一部分为5天的特征数据。


二、构建数据库与数据预处理
为了方便后续数据调用,因此在数据库构建的同时将数据处理成需要的格式。数据预处理十分重要,预处理的方式与模型结构有关。
为了能更直观地看到模型验证结果,选择最后100行数据作为验证数据集,其他数据作为训练数据集。
数据格式为csv文件,因此用csv.reader函数可以很方便地读取数据。读取后,删掉无关地数据,精简数据。
在模型训练时,将最后一列作为标签,用前面列的特征数据来对最后一列进行预测。但是特征数据有115个,因此必然需要筛选出哪些是与标签数据有关的数据。本文采用SelectKBest方法筛选特征数据。
数据库构建代码如下:
class MyDatasets(Dataset):
def __init__(self, path, feature_num, method):
with open(path, 'r') as f:
csv_data = list(csv.reader(f))
csv_title = csv_data[0][1:]
csv_data = np.array(csv_data[1:])[:, 1:].astype(float) # 删除数据第一行(title)和第一列(id)
feature_list = feature_get(feature_num)
b = np.zeros((2699, len(feature_list) + 1))
for idx in range(len(feature_list)):
b[:, idx] = csv_data[:, feature_list[idx]]
b[:, -1] = csv_data[:, -1]
csv_data = b
self.csv_title = csv_title
if method == 'train':
self.csv_data = csv_data[:-100]
elif method == 'test':
self.csv_data = csv_data[-100:]
def __getitem__(self, idx):
data_cov = self.csv_data[idx][:-1]
title_cov = self.csv_data[idx][-1]
return data_cov, title_cov
def __len__(self):
return len(self.csv_data)
特征数据筛选代码如下:
import csv
import numpy as np
from sklearn.feature_selection import SelectKBest, chi2
def feature_get(k): # k:需要筛选出的特征数量
with open('covid.train_new.csv', 'r') as f:
csv_data = list(csv.reader(f))
csv_title = csv_data[0][1:]
csv_data = np.array(csv_data[1:])[:, 1:].astype(float)
# 生成数据
labels_list = []
data_list = []
for i in csv_data:
labels_list.append(i[-1])
data_list = np.append(data_list, i[:-1])
data_list = data_list.reshape(2699, -1)
labels_list = np.array(labels_list)
model = SelectKBest(chi2, k=k)
x_new = model.fit_transform(data_list, labels_list.astype('int32'))
data_list = data_list.transpose()
x_new = x_new.transpose()
feature_list = []
for i in x_new:
for j in range(len(data_list) - 1):
if i[10] == data_list[j][10]:
feature_list.append(j)
return feature_list
数据库建立后,在导入模型前还需要进行归一化操作
scaler = MinMaxScaler(feature_range=(-1, 1))
train_dataset.csv_data = scaler.fit_transform(train_dataset.csv_data)
test_dataset.csv_data = scaler.transform(test_dataset.csv_data)
三、模型定义
模型由三层全链接层构成
class MyNet(nn.Module):
def __init__(self, input_dim):
super(MyNet, self).__init__()
# 一个简单的三层全链接层的神经网络模型
self.layers = nn.Sequential(
nn.Linear(input_dim, 16), # 全连接层
nn.ReLU(), # 激活函数
nn.Linear(16, 8),
nn.ReLU(),
nn.Linear(8, 1)
)
def forward(self, x):
x = self.layers(x)
x = x.squeeze(1) # (B, 1) -> (B)
return x
四、模型训练与验证
模型训练与验证过程较简单,只需注意输入维度、输出维度、数据格式等方面。这里的输入维度(input_dim)为输入的特征数据个数。
mod = MyNet(input_dim)
loss_fn = nn.MSELoss()
learning_rate = 1e-1
optimizer = torch.optim.SGD(mod.parameters(), lr=learning_rate)
loss_list = []
total_train_step = 0
epoch = 200
mod.train()
total_loss = 0
for i in range(epoch):
print('第{}轮训练开始'.format(i + 1))
for data in train_dataloader:
cov_data, target = data
output = mod(cov_data.to(torch.float32))
loss = loss_fn(output, target.to(torch.float32))
total_loss += loss.item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step = total_train_step + 1
print('训练次数:{},loss:{}'.format(total_train_step, total_loss))
loss_list.append(total_loss)
total_loss = 0
# torch.save(mod, 'mod2.pth')
print('*' * 25 + '训练完成' + '*' * 25)
mod.eval()
output_list = []
total_test_loss = 0
with torch.no_grad():
for data in test_dataloader:
cov_data, target = data
output = mod(cov_data.to(torch.float32))
output_list = np.append(output_list, output)
loss = loss_fn(output, target.to(torch.float32))
total_test_loss = total_test_loss + loss.item()
print('整体测试集loss:{}'.format(total_test_loss))
五、模型结果输出
在输出绘图时,需要对输出数据进行逆归一化,还原数据。在进行逆归一化前,需要将数据大小还原成归一化以前的大小。逆归一化完成后,需要将数据拉伸为一维数据,与标签数据的大小保持一致,方便绘图。
output_list = scaler.inverse_transform(output_list.reshape(-1, feature_num + 1))
output_list = output_list.reshape(1, -1)[0]
模型超参数数据与绘图代码详见完整代码部分。
六、完整代码
import csv
import numpy as np
import torch
from matplotlib import pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from torch.utils.data import Dataset, DataLoader
from MyFeature import feature_get
import torch.nn as nn
import time
class MyDatasets(Dataset):
def __init__(self, path, feature_num, method):
with open(path, 'r') as f:
csv_data = list(csv.reader(f))
csv_title = csv_data[0][1:]
csv_data = np.array(csv_data[1:])[:, 1:].astype(float) # 删除数据第一行(title)和第一列(id)
feature_list = feature_get(feature_num)
b = np.zeros((2699, len(feature_list) + 1))
for idx in range(len(feature_list)):
b[:, idx] = csv_data[:, feature_list[idx]]
b[:, -1] = csv_data[:, -1]
csv_data = b
self.csv_title = csv_title
if method == 'train':
self.csv_data = csv_data[:-100]
elif method == 'test':
self.csv_data = csv_data[-100:]
def __getitem__(self, idx):
data_cov = self.csv_data[idx][:-1]
title_cov = self.csv_data[idx][-1]
return data_cov, title_cov
def __len__(self):
return len(self.csv_data)
class MyNet(nn.Module):
def __init__(self, input_dim):
super(MyNet, self).__init__()
# 一个简单的三层全链接层的神经网络模型
self.layers = nn.Sequential(
nn.Linear(input_dim, 16), # 全连接层
nn.ReLU(), # 激活函数
nn.Linear(16, 8),
nn.ReLU(),
nn.Linear(8, 1)
)
def forward(self, x):
x = self.layers(x)
x = x.squeeze(1) # (B, 1) -> (B)
return x
start_time = time.time()
feature_num = 4
train_dataset = MyDatasets('covid.train_new.csv', feature_num, 'train')
test_dataset = MyDatasets('covid.train_new.csv', feature_num, 'test')
labels_list = []
for i in test_dataset.csv_data:
labels_list.append(i[-1])
scaler = MinMaxScaler(feature_range=(-1, 1))
train_dataset.csv_data = scaler.fit_transform(train_dataset.csv_data)
test_dataset.csv_data = scaler.transform(test_dataset.csv_data)
batch_size = 16
train_dataloader = DataLoader(train_dataset, batch_size, drop_last=False)
test_dataloader = DataLoader(test_dataset, batch_size, drop_last=False)
test_data_size = len(test_dataset.csv_data)
# input_dim = len(train_dataset.csv_data[0])-1
input_dim = feature_num
mod = MyNet(input_dim)
loss_fn = nn.MSELoss()
learning_rate = 1e-1
optimizer = torch.optim.SGD(mod.parameters(), lr=learning_rate)
loss_list = []
total_train_step = 0
epoch = 200
mod.train()
total_loss = 0
for i in range(epoch):
print('第{}轮训练开始'.format(i + 1))
for data in train_dataloader:
cov_data, target = data
output = mod(cov_data.to(torch.float32))
loss = loss_fn(output, target.to(torch.float32))
total_loss += loss.item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step = total_train_step + 1
print('训练次数:{},loss:{}'.format(total_train_step, total_loss))
loss_list.append(total_loss)
total_loss = 0
# torch.save(mod, 'mod2.pth')
print('*' * 25 + '训练完成' + '*' * 25)
mod.eval()
output_list = []
total_test_loss = 0
with torch.no_grad():
for data in test_dataloader:
cov_data, target = data
output = mod(cov_data.to(torch.float32))
output_list = np.append(output_list, output)
loss = loss_fn(output, target.to(torch.float32))
total_test_loss = total_test_loss + loss.item()
print('整体测试集loss:{}'.format(total_test_loss))
# 输出结果
output_list = scaler.inverse_transform(output_list.reshape(-1, feature_num + 1)) # 对output进行维度转换
output_list = output_list.reshape(1, -1)[0] # 将矩阵变成一维,和label_list保持一致
cor = np.corrcoef(np.vstack((labels_list, output_list)))[1, 0] # 数组合成,求相关系数
cor = round(cor, 4) # 保留两位小数
total_test_loss = round(total_test_loss, 4)
end_time = round((time.time() - start_time), 4)
print('训练次数{},学习率{},批尺寸{},耗时{}秒,'.format(epoch, learning_rate, batch_size, end_time))
print('相关系数{},测试集损失{}'.format(cor, total_test_loss))
with open('模型训练情况.txt', 'a', encoding='utf-8') as f:
f.write('训练次数' + str(epoch) + ' ')
f.write('学习率' + str(learning_rate) + ' ')
f.write('批尺寸' + str(batch_size) + ' ')
f.write('相关系数' + str(cor) + ' ')
f.write('测试集损失' + str(total_test_loss) + ' ')
f.write('特征数量' + str(feature_num) + ' ')
f.write('耗时' + str(end_time) + ' ')
f.write('\n')
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# plt.figure(1)
# plt.title('loss变化', fontsize=16)
# plt.plot(loss_list)
# plt.figure(2)
plt.title('模拟情况 ' + '相关系数:' + str(cor), fontsize=16)
plt.plot(output_list, label='模拟')
plt.plot(labels_list, label='实测')
plt.legend()
plt.show()
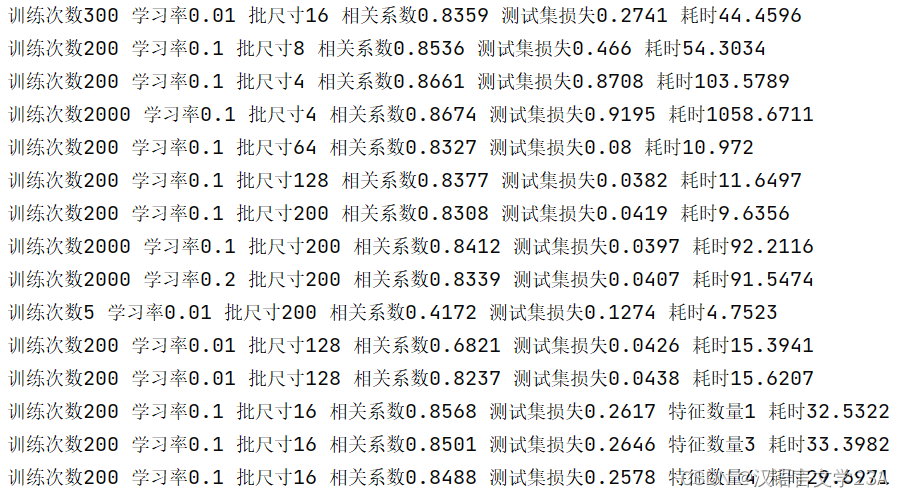
七、部分运行结果展示
八、参考资料
【李宏毅《机器学习》2022】作业1:COVID 19 Cases Prediction (Regression)
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。