
本文只是记录个人阅读论文的感想与思考!难免存在错误!如若理解有误还请各位大佬指出!感谢!
目录
论文一:3D MRI brain tumor segmentation using autoencoder regularization
本文将介绍两篇在经典的U-Net的解码器分支中添加了一个额外的分支(变分自编码器分支)的论文,添加这个额外的分支的目的是为了给编码器提供额外的正则化,并重构图像从而缓解在医学图像领域带标注的数据不足的问题!
首先介绍一下自编码器和变分自编码器的相关概念!!
相关概念
自编码器(AE)
一般来说我们把自编码器理解为一种降维的工具。自编码器一般分为两个部分,其一是编码器,由多层网络构成,将输入的数据压缩成一个低维度向量,这个低维度向量称之为bottleneck(瓶颈)。其二是解码器部分,将bottleneck作为其输入,最终得到输出。我们称之为数据重构。其结构如下图所示
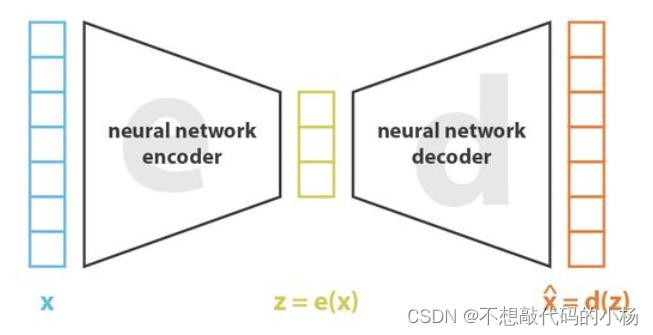
在图中编码器由z=e(x)表示,解码器由y=d(z)表示,因此自编码器的前向传播过程可以用y=d(e(x))来表示 。我们的目的是要让重构数据尽可能的很原始数据保持一致!从而达到压缩还原的作用。因此对应的损失就是尽可能的使x和y尽可能一样,因此损失函数可以定义为:
loss=||x-d(e(x))||^2
可以参考视频讲解:自编码器原理讲解
自编码器存在的问题
自编码器用于生成新内容时具有其局限性。在自编码器中虽然既有编码器又有解码器,但是其数据重构过程没有办法产生任何新内容。我们可能会认为,如果隐空间足够规则(在训练过程中被编码器很好地“组织”了),我们可以从该隐空间中随机取一个点并将其解码以获得新的内容,就像生成对抗网络中的生成器一样。
但自编码器的隐空间的规则性是一个难点,它取决于初始空间中数据的分布、隐空间的大小和编码器的结构。可以说自编码器的不规则的隐空间是使其在生成新内容时具有局限性。自编码器仅仅以最小化损失的目标进行训练,而不管隐空间的规则性,如何组织,这不利于新内容的生成,也非常容易造成模型的过拟合!!
变分自编码器(VAE)
基于编码器存在的问题,为了将自编码器的解码器用于生成新内容的目的,我们必须确保隐空间足够规则。获得这种规则的隐空间的一种方法是在训练过程中加入一种显式的正则化。变分自编码器可以定义为一种自编码器,其训练经过正规化以避免过度拟合,并确保隐空间具有能够进行数据生成过程的良好属性。
同自编码器一样,VAE也同样具有编码器和解码器结构。经过训练以使编码解码后的数据与初始数据之间的重构误差最小。但是,为了引入隐空间的某些正则化,我们对编码-解码过程进行了一些修改:我们不是将输入编码为隐空间中的单个点,而是将其编码为隐空间中的概率分布
VAE的训练过程为以下4步:1)将输入编码为在隐空间上的分布 2)从该分布中采样隐空间中的一个点 3)对采样点进行解码并计算出重建误差4)最后,重建误差通过网络反向传播
在实践中,通常选择正态分布来作为编码的分布。将输入编码为具有一定方差而不是单个点的分布的原因是这样可以非常自然地表达隐空间规则化:编码器返回的分布被强制接近标准正态分布。
因此,在训练VAE时最小化的损失函数由一个“重构项”(在最后一层)组成,“重构项”倾向于使编码解码方案尽可能地具有高性能,而一个“正则化项”(在隐层)通过使编码器返回的分布接近标准正态分布,来规范隐空间的组织。其结构如下图

其损失函数如下
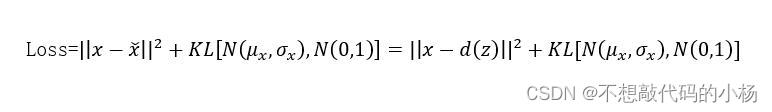
损失函数由一个重构项和正则化项组成,重构项目标是确保输入和重构数据尽可能的一致,而正则化项是为了使隐空间规则化,从而使得VAE适合于生成新内容的任务!!
关于正则化的直观解释
为了使自编码器生成新内容称为可能,我们期望隐空间具有规则性。通过两个主要属性来表示:连续性(即隐空间中的两个相邻的点解码以后不应呈现出完全不同的内容)和完整性(即针对给定的分布,从隐空间采样的点在解码后应提供有意义的内容)
具体如下图

左图为不规则的隐空间;右图为规则的隐空间。在不规则的隐空间中临近的点解码后不相似如左图中两个相邻的点解码后一个变为三角形一个位正方形。此外还有的点无法解码出有意义的数据如紫色图形。
为了避免这些影响,我们必须同时对协方差矩阵和编码器返回的分布均值进行正则化。实际上,通过强制分布接近标准正态分布(集中和简化)来完成此正则化!!通过使用这个正则化项,我们可以防止模型在编码器中的编码相互远离,并鼓励尽可能多的返回分布发生“重叠”。从而满足预期的连续性和完整性条件,使得隐空间具有规则。
论文一:3D MRI brain tumor segmentation using autoencoder regularization
Introduction
网络的结构是一个编码器与解码器的结构。
由于带标注的医学影像数据有限。添加了一个变分自编码器分支来重构输入图像本身(缓解了带标注数据不足的问题),起到规范共享解码器并对其层施加额外的约束作用。
此外变分自编码器分支只在训练期间使用,使用变分自编码器的动机是为编码器添加额外的指导和正则化。
方法(Method)
网络结构如下图所示

编码器部分:
编码器部分使用ResNet块,其中每一个块由两个带有组归一化和Relu激活函数的卷积组成。在编码器部分逐渐将图像的分辨率缩小,通道数增加。提取深层语义信息。此外为了避免在下采样过程中丢失过多的空间信息。在图像分辨率缩小为原来的1/8后不再进行缩小!
解码器部分:
每个解码器都会放大特征图,通道数减少为原来的1/2,然后与等效空间级别的编码器输出相加。在解码器的末端与原始图像具有相同的空间分辨率。然后使用1*1*1卷积成3个通道,再通过Sigmod激活函数得到最终的分割结果
VAE-变分自编码器部分:
从编码器端点的输出开始,将其减少到256的低维空间(给定均值和标准差分别为128和128)从具有给定的标准差和均值高斯分布的隐空间中抽取一个样本,并且以解码器相同的方式重构为输入图像尺寸。只是在这个分支中不再使用来自编码器的层间跳跃连接
Loss损失函数:
损失由三部分组成如下:

在这个损失函数中
第一项是输出预测和Groud Truth之间的Dice Loss。
第二项是变分自编码器的重构损失,其目的是为了使重构的图像和原始输入图像尽可能保持一致。
第三项是变分自编码器的正则化项,是估计正态分布和先验分布之间的KL散度。其目的是为了使使变分自编码器具有规则性的隐空间,这要更利于与变分自编码器重构出新的内容,从而缓解标注数据不足问题。
论文二:A Two-Stage Cascade Model with Variational
Autoencoders and Attention Gates for MRI
Brain Tumor Segmentation
Introduction
本文提出的网络框架基于两阶段的编码器-解码器分割结构,在网络结构的两个阶段都使用变分自编码器来重构原始输入数据来防止发生过拟合。
在第二阶段的网络结构中,网络在解码器分支中使用了注意力门,避免了解码器在等效空间级别的连接中得到冗余的不必要的信息。并且使用由第一阶段输出形成的扩展数据集进行额外的训练。
Method(方法)
方法概括
输入数据首先经过第一阶段网络进行处理,以获得一个相对粗略的分割结果。第二阶段网络使用来自第一阶段的初步分割图和原始MRI图像的串联作为其输入。第二阶段网络旨在改进NCR/NET(坏死和非增强肿瘤)和ET(增强肿瘤)子区域的预测。此外应用了AGs注意力门来进一步抑制不相关的背景区域。网络结构如下图

第一阶段网络:具有VAE分支的非对称U-Net
编码器部分:编码器由四个空间级别的ResNet块组成,块的数量分别为(1,2,2,4),每个ResNet块中都有两个带有组归一化和Relu的卷积,使用步长为2的3*3*3卷积进行下采样。
解码器部分:解码器具有和编码器对称的结构,每块的块数是1,使用三线性上采样恢复特征图尺寸,并且通过跳跃连接将其与同级别的编码器输出连接。使用1*1*1卷积将特征通道数从32减少到3.使用sigmod将其转换为分割概率图。
VAE分支:这个分支从编码器的输出重构原始图像,一开始使用全连接层将编码器端点输出降低到256维的低维空间,256代表高斯分布的128个均值和128个标准差。从中抽取大小128的样本,按照与解码器相同的策略重构输入图像。另外编码器和VAE之间没有跳跃连接
第二阶段网络:具有VAE分支注意力门控非对称U-Net
第二阶段网络的编码器与第一阶段的网络结构相同,只是在解码器分支上添加了AG(注意门控),来自于每个空间级别的较粗尺度的门控信号被传递到注意力门来确定注意力系数。
AG的输出是来自编码器的输入特征和注意系数的乘积,然后通过逐元素求和将每个级别的AG的输出与来自较粗尺度的2倍上采样特征相加。注意力门的内部结构示意图如下:

如图所示:较粗尺度的门控信号
![]()
![]()
![]()
![]()
![]()

损失函数
网络的损失函数和论文一的损失函数一样,也是由预测结果和GroundTruth的DiceLoss;VAE的重构损失;VAE的正则项三部分加权组成。
参考:编码器与自编码器概念理解
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。