
文章目录
一、HDFS概述
1.1 HDFS 产出背景及定义
(1)HDFS 产生背景
随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统。HDFS 只是分布式文件管理系统中的一种。
(2)HDFS 定义
HDFS(Hadoop Distributed File System),它是一个文件系统,用于存储文件,通过目录树来定位文件;其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。
HDFS 的使用场景:适合一次写入,多次读出的场景。一个文件经过创建、写入和关闭之后就不需要改变。
1.2 HDFS 优缺点
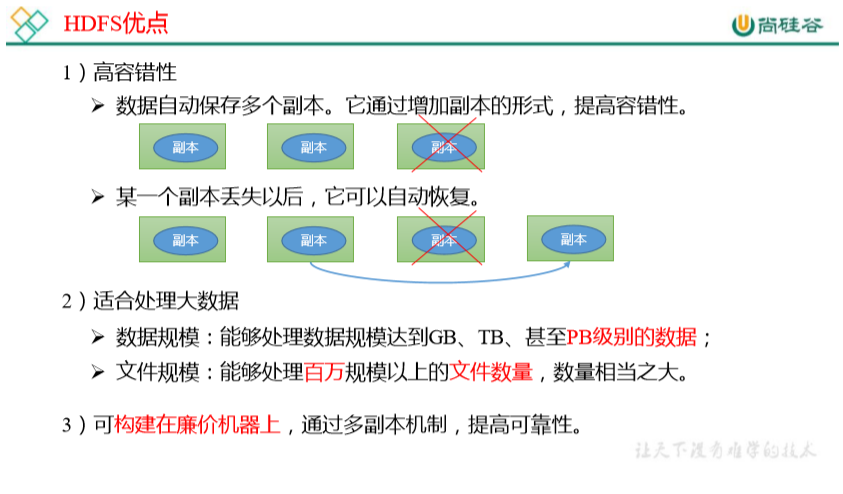

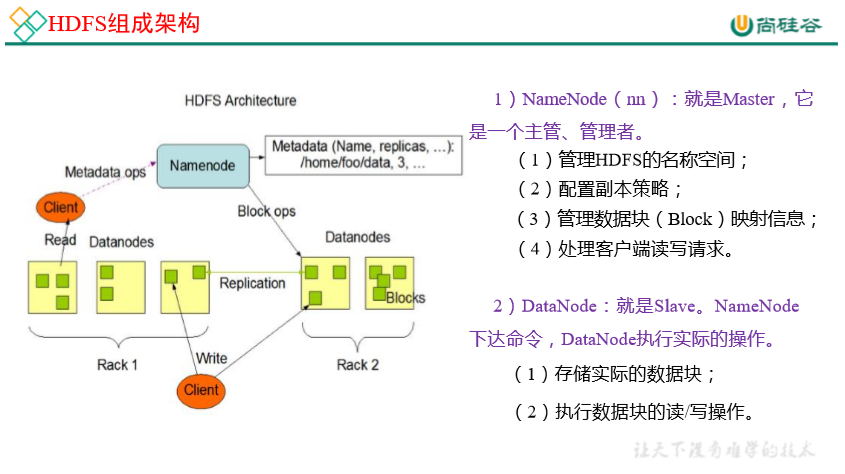
1.3 HDFS 组成架构

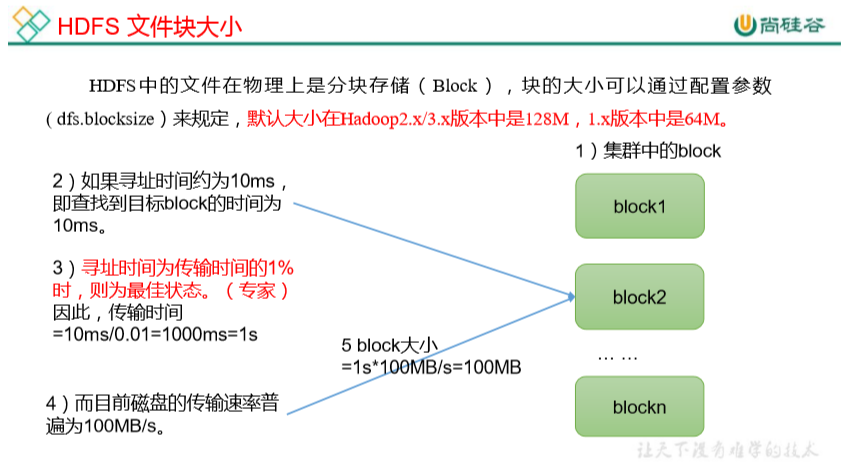
1.4 HDFS 文件块大小(面试重点)

二、HDFS的Shell相关操作
2.1 基本语法
2.2 命令大全
2.3 常用命令操作
2.3.1 准备工作
2.3.2 上传
2.3.3 下载
2.4 HDFS 直接操作
三、HDFS的API操作
3.1 客户端环境准备
package com.xxxx.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.Test;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
/**
* 客户端代码常用套路:
* 1、获取一个客户端对象
* 2、执行相关的操作命令
* 3、关闭资源
*/
public class HdfsClient {
@Test
public void testMkdirs() throws IOException, URISyntaxException, InterruptedException {
//创建一个配置文件
Configuration configuration = new Configuration();
//获取文件系统,url:连接的集群nn地址
//FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"), configuration);
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"), configuration,"lln");
//创建目录
fs.mkdirs(new Path("/xiyou/huaguoshan/"));
//关闭资源
fs.close();
}
}
优化
package com.xxxx.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
/**
* 客户端代码常用套路:
* 1、获取一个客户端对象
* 2、执行相关的操作命令
* 3、关闭资源
*/
public class HdfsClient {
private FileSystem fs;
//初始化
@Before
public void init() throws URISyntaxException, IOException, InterruptedException {
//创建一个配置文件
Configuration configuration = new Configuration();
//获取文件系统,url:连接的集群nn地址
fs = FileSystem.get(new URI("hdfs://hadoop102:8020"), configuration,"lln");
}
//关闭资源
@After
public void close() throws IOException {
fs.close();
}
@Test
public void testMkdirs() throws IOException {
//创建目录
fs.mkdirs(new Path("/xiyou/huaguoshan1/"));
}
}
3.2 HDFS 的API案例实操
3.2.1 HDFS 文件上传
API参数的优先级
@Test
public void testCopyFromLocalFile() throws IOException, InterruptedException, URISyntaxException {
// 1 获取文件系统
Configuration configuration = new Configuration();
configuration.set("dfs.replication", "2");
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"), configuration, "lln");
// 2 上传文件
fs.copyFromLocalFile(new Path("d:/sunwukong.txt"), new Path("/xiyou/huaguoshan"));
// 3 关闭资源
fs.close();
}
(3)参数优先级
参数优先级排序:
- 客户端代码中设置的值
- ClassPath 下的用户自定义配置文件
- 然后是服务器的自定义配置(xxx-site.xml)
- 服务器的默认配置(xxx-default.xml)
3.2.2 HDFS 文件下载
@Test
public void testCopyToLocalFile() throws IOException{
//参数解读:参数一:是否删除源数据,参数二:源文件路径,参数三:目标地址路径win,参数四:是否开启文件校验
fs.copyToLocalFile(false,new Path("hdfs://hadoop102/xiyou/huaguoshan"),new Path("D:\\"),true);
}
3.2.3 HDFS 删除文件和目录
@Test
public void testDelete() throws IOException{
//参数解读:参数一:要删除的路径,参数二:是否递归删除
//删除文件
//fs.delete(new Path("/jdk-8u212-linux-x64.tar.gz"),false);
//删除空目录
//fs.delete(new Path("/sanguo"),false);
//删除非空目录
fs.delete(new Path("/xiyou"),true);
}
3.2.4 HDFS 文件更名和移动
@Test
public void testMv() throws IOException {
//对文件名称的修改
//参数解读:参数一:源文件路径,参数二:目标文件路径
//fs.rename(new Path("/input/word.txt"),new Path("/input/lln.txt"));
//文件个更名和修改
//fs.rename(new Path("/input/lln.txt"),new Path("/word.txt"));
//目录的更名
fs.rename(new Path("/input"),new Path("/output"));
}
3.2.5 HDFS 查看文件详情
@Test
public void testDetail() throws IOException {
//获取所有文件信息
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true);
//遍历文件
while (listFiles.hasNext()) {
LocatedFileStatus fileStatus = listFiles.next();
System.out.println("========" + fileStatus.getPath() + "=========");
System.out.println(fileStatus.getPermission());
System.out.println(fileStatus.getOwner());
System.out.println(fileStatus.getGroup());
System.out.println(fileStatus.getLen());
System.out.println(fileStatus.getModificationTime());
System.out.println(fileStatus.getReplication());
System.out.println(fileStatus.getBlockSize());
System.out.println(fileStatus.getPath().getName());
// 获取块信息
BlockLocation[] blockLocations = fileStatus.getBlockLocations();
System.out.println(Arrays.toString(blockLocations));
}
}
3.2.6 HDFS 文件和文件夹判断
@Test
public void testListStatus() throws IOException {
//判断是文件还是文件夹
FileStatus[] listStatus = fs.listStatus(new Path("/"));
for(FileStatus fileStatus :listStatus){
// 如果是文件
if (fileStatus.isFile()) {
System.out.println("f:"+fileStatus.getPath().getName());
}else {
System.out.println("d:"+fileStatus.getPath().getName());
}
}
}
四、HDFS的读写流程
4.1 HDFS 写数据流程
4.1 剖析文件写入
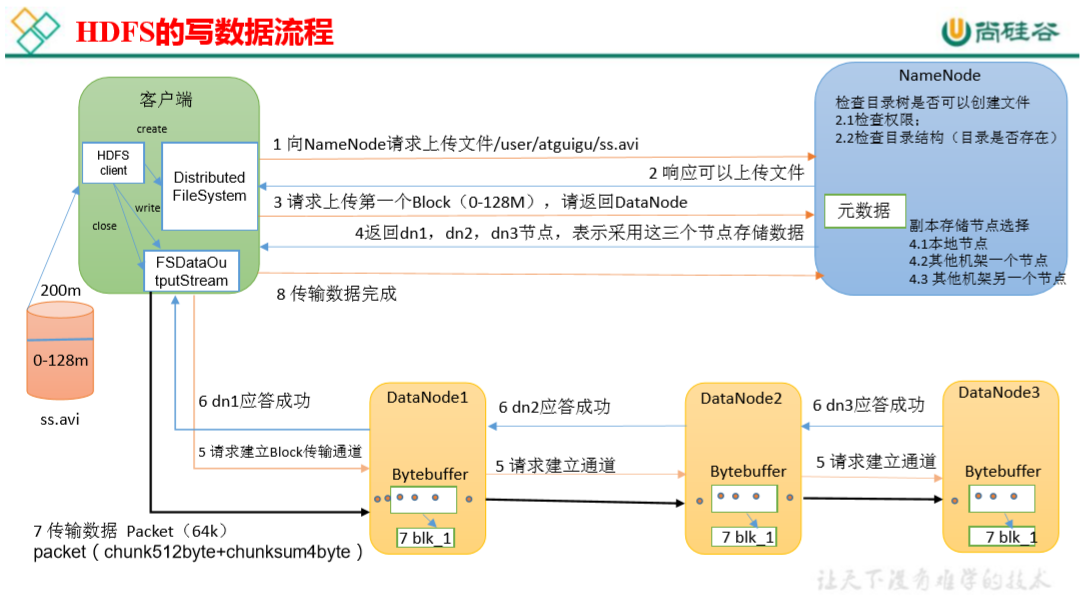
(1)客户端通过 Distributed FileSystem 模块向 NameNode 请求上传文件,NameNode 检查目标文件是否已存在,父目录是否存在。
(2)NameNode 返回是否可以上传。
(3)客户端请求第一个 Block 上传到哪几个 DataNode 服务器上。
(4)NameNode 返回 3 个 DataNode 节点,分别为 dn1、dn2、dn3。
(5)客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。
(6)dn1、dn2、dn3 逐级应答客户端。
(7)客户端开始往 dn1 上传第一个 Block(先从磁盘读取数据放到一个本地内存缓存),以 Packet 为单位,dn1 收到一个 Packet 就会传给 dn2,dn2 传给 dn3;dn1 每传一个 packet会放入一个应答队列等待应答。
(8)当一个 Block 传输完成之后,客户端再次请求 NameNode 上传第二个 Block 的服务器。(重复执行 3-7 步)。
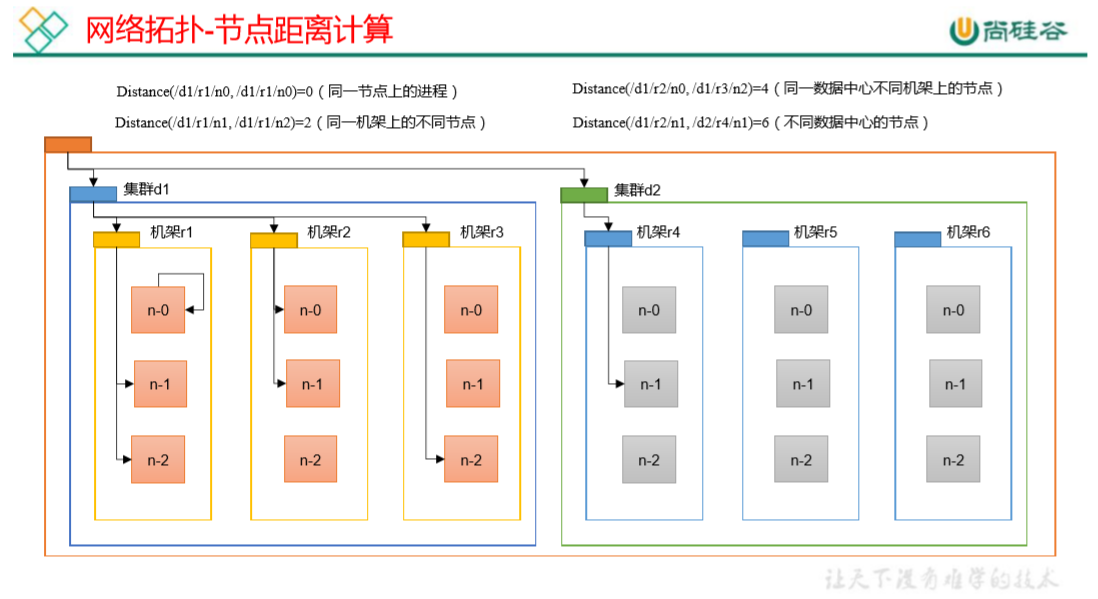
4.2 网络拓扑-节点距离计算
在 HDFS 写数据的过程中,NameNode 会选择距离待上传数据最近距离的 DataNode 接
收数据。那么这个最近距离怎么计算呢?
节点距离:两个节点到达最近的共同祖先的距离总和。
五、NameNode 和 SecondaryNameNode
六、DataNode工作机制
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。