
1.什么是Elasticsearch
Elasticsearch 是位于 Elastic Stack 核心的分布式搜索和分析引擎。Logstash 和 Beats 有助于收集、聚合和丰富您的数据并将其存储在 Elasticsearch 中。Kibana 使您能够以交互方式探索、可视化和分享对数据的见解,并管理和监控堆栈。Elasticsearch 是索引、搜索和分析魔法发生的地方。
2.数据库作为搜索的弊端
1.站内搜索(垂直搜索):
数据量小,简单搜索,可以使用数据库。
这样会出现什么样的问题呢?
1.存储问题。电商网站商品上亿条时,涉及到单表数据过大必须拆分表,
数据库磁盘占用过大必须分库( mycat )。
2.性能问题:解决上面问题后,查询 “ 笔记本电脑 ” 等关键词时,上亿条数据
的商品名字段逐行扫描,性能跟不上。
3.不能分词。如搜索 “ 笔记本电脑 ” ,只能搜索完全和关键词一样的数据,那
么数据量小时,搜索 “ 笔记电脑 ” , “ 电脑 ” 数据要不要给用户。
2. 互联网搜索,肯定不会使用数据库搜索。数据量太大。 PB 级。
我们可以使用搜索引擎来解决数据库搜索的问题 :
搜索也是一款数据库,搜索可以进行分词搜索 --- 搜索速度非常快
3.常见的搜索引擎
ElasticSearch和Solr
3.1二者的区别
1. Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引;也可以通过Http Get操作提出查找请求,并得到XML格式的返回结果,【特点】是一个高性能,采用Java开发,Solr基于Lucene的全文搜索服务器。同时对其进行了扩展,提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面,是一款非常优秀的全文搜索引擎。
2.ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。ElasticSearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。官方客户端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。根据DB-Engines的排名显示,Elasticsearch是最受欢迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene。
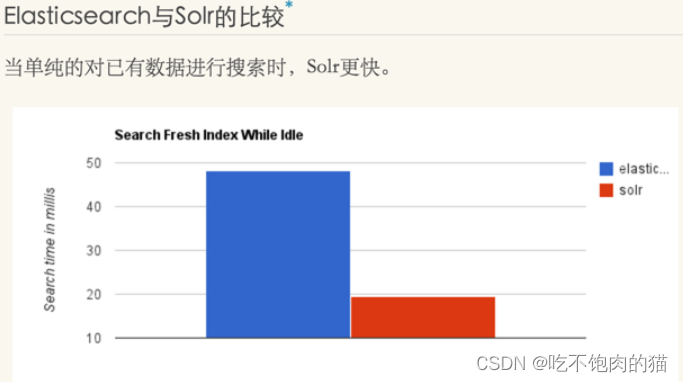
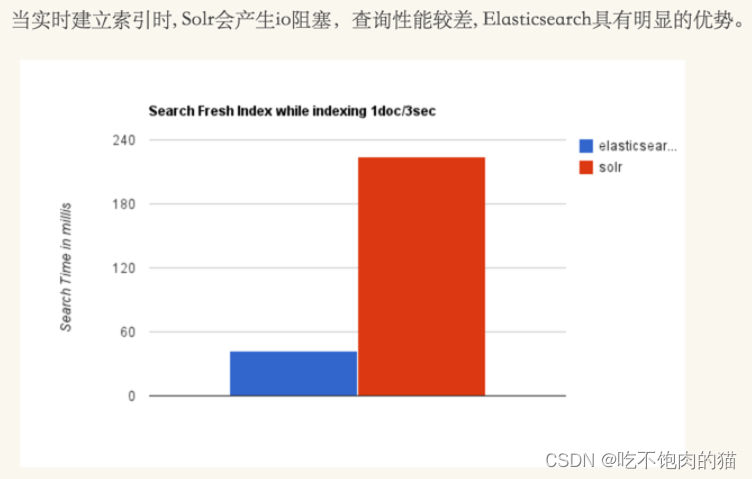
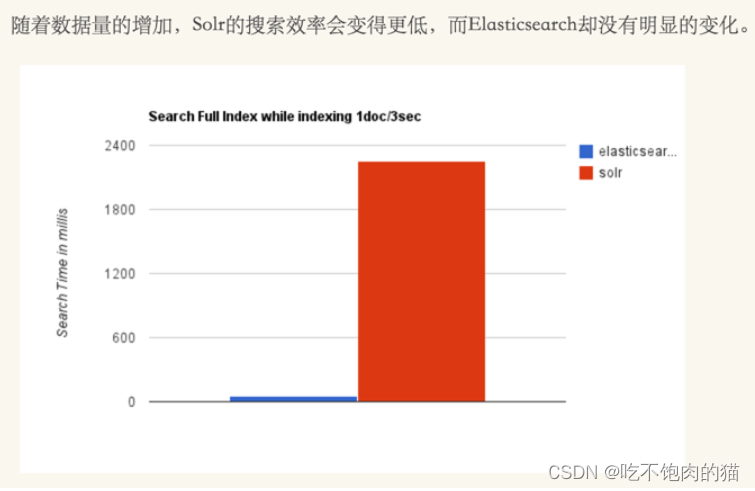
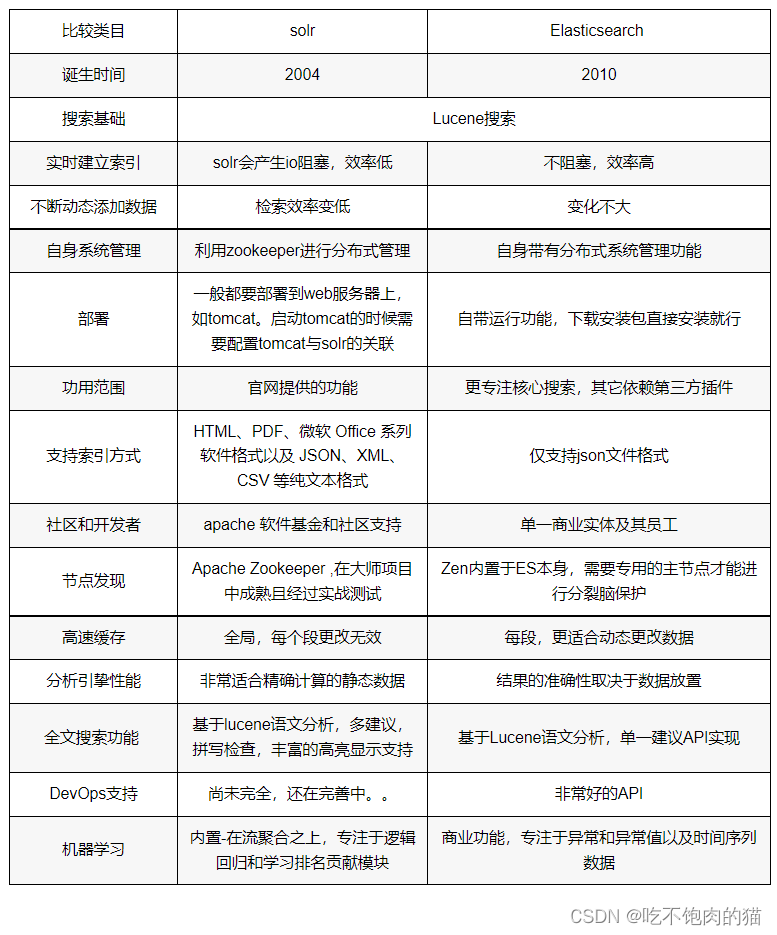
3.2性能的对比
4. Kibana
Kibana 是一种数据可视化和挖掘工具,可以用于日志和时间序列分析、应用程序监控和运营智能使用案例。它提供了强大且易用的功能,例如直方图、线形图、饼图、热图和内置的地理空间支持。此外,它还提供了与 Elasticsearch 的紧密集成,后者是一款流行的分析和搜索引擎,这使得 Kibana 成为了可视化 Elasticsearch 中存储数据的默认之选。
4.1使用Kibana
开启kibana
5.命令
5.1创建索引,并在里面填上数据,自动创建id
PUT /king/student/3{
"name" : "摩托哥",
"age" : 35
}
5.2创建索引,添加上数据,随机创建id
POST /king/student/{
"name" : "马闹鸡",
"age" : 28
}
5.3创建索引,不添加数据
PUT /lin
{
"mappings":{
"properties":{
"name":{
"type":"text"
},
"age":{
"type":"integer"
}
}
}
}
5.4删除索引
DELETE /lin
5.5查询都有什么索引
GET /_cat/indices?v
5.6查看索引下类型的数据
GET /king/student/2
5.7修改部分文档
POST /user/doc/1/update
{
"doc":{
"name":"旅游博主林先生"
}
}
5.8修改---这种修改必须指定所有列,如果只指定一部分列,那么它原来的其他列就会消失。
PUT /king/student/2
{
"name":"灰姑娘",
"age":"16"
}
5.9查询所有数据
GET /king/student/_search
5.10根据条件查询数据
GET /king/student/_search?q=name:"林"
5.11查询的条件封装到json中,默认都是doc,查询部分列用"_source":[],from是根据下标指定第几页,size是指定一页中有几条数据
PUT /user/_doc/1
{
"name":"林先生",
"age":20,
"desc":["沉着","冷静","缜密"]
}PUT /user/_doc/2
{
"name":"摩托哥",
"age":20,
"desc":["坚持","努力"]
}PUT /user/_doc/3
{
"name":"阿瑟",
"age":18,
"desc":["细心","肯吃苦"]
}GET /user/_search
{
"query":{
"match":{
"age":"20"
}
},
"_source": ["name","age","desc"],
"from":1,
"size":1
}
5.12range范围,lt是小于 gt是大于 sort是排序desc是降序,asc是升序
GET /user/_search
{
"query":{
"range":{
"age":{
"gt":3
}
}
},
"_source": ["name","age","desc"],
"from":0,
"size":10,
"sort": [
{
"age": {
"order": "desc"
}
}
]
}
5.13must相当于and,should相当于or
GET /user/_search
{
"query":{
"bool": {
"must_not": [
{
"match": {
"age": "20"
}
}
]
}
}
}
5.14高亮查询highlight,fields领域,pre_tags前置标签,post_tags后置标签
GET /user/_search
{
"query":{
"match": {
"name": "林"
}
},
"highlight": {
"pre_tags": "<span style='color:red'>",
"post_tags": "</span>",
"fields": {
"name": {}
}
}
}
5.15match匹配查询,会对匹配的关键字进行拆字操作,term精准查询,不会对关键字进行拆词操作
GET /user/_search
{
"query": {
"term": {
"name": "先"
}
}
}
5.16分词keyword是不分词的,分词standard是分词的
GET _analyze
{
"analyzer": "keyword",
"text":["测试是否分词"]
}GET _analyze
{
"analyzer": "standard",
"text":["测试是否分词"]
}
5.17类型是文本的时候会分词,是keyword的时候是不分词的
PUT /test
{
"mappings":{
"properties":{
"name":{
"type":"text"
},
"address":{
"type": "keyword"
}
}
}
}PUT /test/_doc/1
{
"name":"测试keyword和text哪种是分词的",
"address":"测试keyword和text哪种是分词的"
}
5.18查询的时候因为address的类型是keyword所以没有办法分词,是一个整体,所以就无法使用address查询
GET /test/_search
{
"query": {
"match": {
"name": "测试"
}
}
}
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。