
一、读取文件:Unicode解码错误:“utf-8”编解码器无法解码位置238中的字节0xd3:继续字节无效
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x87 in position 11: invalid start byte
解决方法一:
首先把csv文件以记事本的格式打开,默认保存是ANSI编码,我们应该手动修改成utf-8 ===>(如果记事本打开后是乱码,我们可以把csv数据粘贴到记事本上后保存)
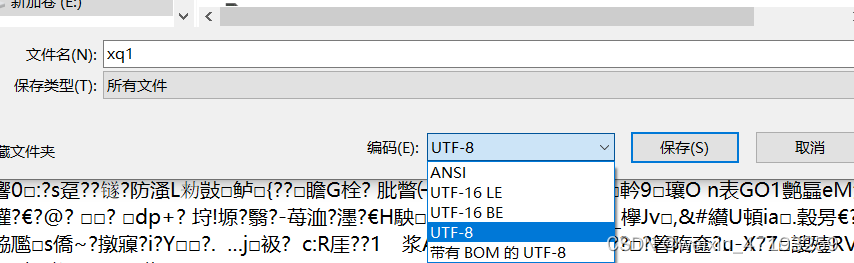
解决方法二:
将文件在python的IDE中打开,在最上边,加注一行代码即可!
# -*- coding: utf-8 -*-
二、解析器错误:标记数据的错误。C错误:在第49行中预期有一个字段,见2
pandas.errors.ParserError: Error tokenizing data. C error: Expected 2 fields in line 11, saw 5
(1)检查自己的数据集相应行是不是格式产生了错误,比如某行多敲了一个逗号等等.大多数此类报错的问题都是出在这里了.
(2)查看文件的扩展名,是xlsx的就用read_excel,如果是csv文件就用read_csv。如果明明是表格,你非要用csv读,就会出现这种报错。(注意:有时文件扩展名会文件类型不一致)
三、获取某一栏数据出错:KeyError: ‘price’

检查读取文件数据:可以看到文件价格这一栏不是price,而是参考价格,所以才会出现keyerror。
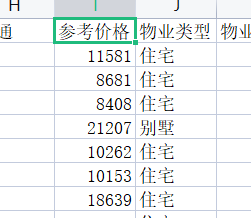
解决方法:

版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。