
yolov7源码:(https://github.com/WongKinYiu/yolov7)
1.数据集预处理(VOC格式)
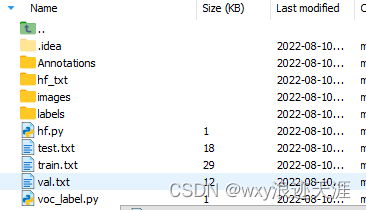
创建一个新的文件夹(名字随意)用于放自己的数据集,我这里命为mydata,如果怕麻烦严格按照我这里的格式,后面的脚本就不需要怎么改,直接复制黏贴,其中Annotation放自己的标注文件xml文件,hf_txt 存放验证集训练集测试集的数据名;images存放自己的数据集图片。

首先划分数据集,划分数据集脚本hf.py如下:
# -*- coding: utf-8 -*-
import os
import random
trainval_percent = 0.7#数据集比例
train_percent = 0.7
xmlfilepath = 'Annotations'
txtsavepath = 'images'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('hf_txt/trainval.txt', 'w')
ftest = open('hf_txt/test.txt', 'w')
ftrain = open('hf_txt/train.txt', 'w')
fval = open('hf_txt/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
将该脚本放置mydata目录下
cd ./mydata
python hf.py
运行成功将得到hf_txt四个文件,里面存放划分好的训练集验证集等不带后缀的数据图片名

将标注文件xml文件转换为yolo格式的txt文件,转换脚本voc_label.py,如下
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
from os import getcwd
sets = ['train', 'val', 'test']
classes = ["yu"] #改成你自己数据集标注类别,双引号单引号都可以,注意中英文输入,不然会报错
abs_path = os.getcwd()
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
in_file = open('Annotations/%s.xml' % (image_id),encoding='utf-8')
out_file = open('labels/%s.txt' % (image_id), 'w',encoding='utf-8')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for image_set in sets:
if not os.path.exists('labels/'):
os.makedirs('labels/')
image_ids = open('hf_txt/%s.txt' % (image_set)).read().strip().split()
list_file = open('%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write(abs_path + '/images/%s.png\n' % (image_id))#注意自己图片的后缀,jpg就改成jpg,我这里是训练png图片
convert_annotation(image_id)
list_file.close()
进入到mydata目录下执行这个脚本
cd ./mydata
python voc_label.py
执行成功后将会得到三个txt文件,以及labels文件夹,txt里面存放对应数据集图片的训练路径,labels下存放对应图片的坐标信息,五个小于的数,第一个类别代表数,猫框中心坐标(x,y)长和宽(H,w),都经过了归一化处理
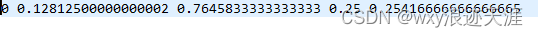
到此数据集处理完毕斜体样式
2 增加数据集索引
增加数据集索引,在源码下的data目录下,新建一个yaml文件,写入以下信息
train: mydata/train.txt #数据集的相对路劲
val: mydata/val.txt
# number of classes
nc: 1#数据集类别数量
# class names
names: ['yu']和voc_label.py中的类别一致顺序也是
到此数据集索引处理结束
3 修改配置文件cfg
修改配置文件cfg,在源码下yolov7-main/cfg/training/,选择你要训练的cfg文件,打开,只需修改nc,数据集类别数量,改为自己类别数量如:

下载预训练权重,点对应model,即可下载
4修改训练文件train.py
可以照这个我这里修改,主要修改default=‘yolov7.pt’;default=‘cfg/training/yolov7.yaml’;default=‘data/person.yaml’;
default=20;default=8;这里相对路径,如果显卡不错,batch可以调大点。

**
5配置yolov7虚拟环境
**
我这里使用的硬件
ubuntu 20.04
cuda-10.2
cudnn-7.6.5
注:cuda版本很重要,必须知道
查看cuda版本命令
nvcc -V

输出即可查看cuda版本,如果查不到,自行百度安装相应的可兼容cuda版本
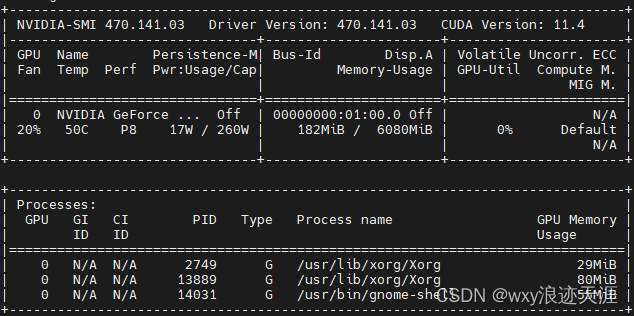
查看自己ubuntu系统可兼容的最高版本cuda,输入一下命令
nvidia-smi
输入看到,cuda可安装<=11.4,不可高于这个版本,否则安装不了
其次,必须装anaconda,anaconda版本尽量装python高版本如3.9,不然虚拟环境配置的python必须小于等于该版本,否则报错。
上述准备完毕,开始建立虚拟环境yo7
conda create -n 环境名(随意,英文即可) python =3.8
conda create -n yo7 python =3.8 //(我的)
激活环境
conda activate yo7
进入源码根目录
cd ./yolov7-main
pip install -r requirements.txt
如果下载很慢可以用国内源,尝试以下命令;
pip install -i https://pypi.douban.com/simple -r requirements.txt
成功安装没有报错,就可以训练啦,奥利给
python train.py
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。