

本文将分享发表在2018年的NAACL上,outstanding paper。论文链接ELMo。该论文旨在提出一种新的词表征方法,并且超越以往的方法,例如word2vec、glove等。
论文贡献点
- 能捕捉到更复杂的语法、语义信息。
- 能更好的结合上下文内容,对多义词做更好的表征。(以往的词表征方法,例如word2vec等可能无法很好的解决这个问题)
- 能非常容易的将这种词表征方法整合进现有的模型中,在多种NLP任务中,都极大了提高了state of the art。
Embedding from Language Models(ELMo)
论文中所提出的词表征方法是基于语言模型的。
双向语言模型
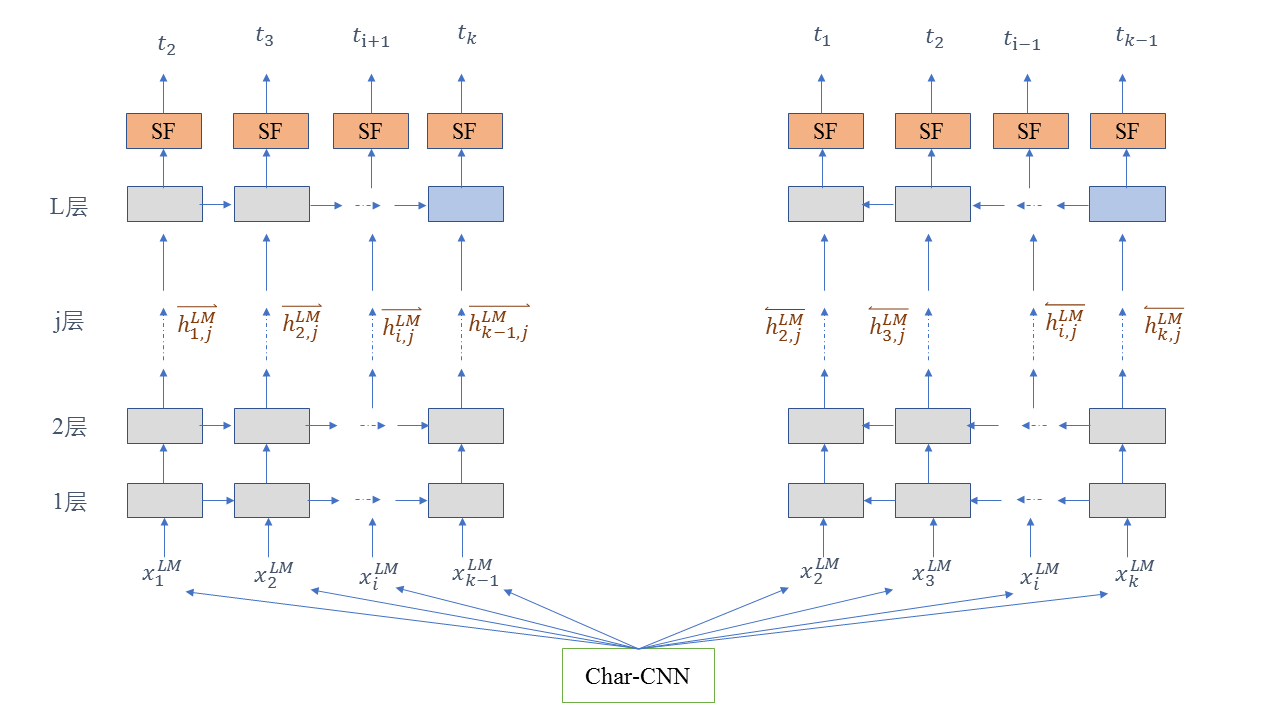
如上图所示,左侧是正向的L层的语言模型,右边是L层的反向网络。SF表示Softmax 结构。
其中xiLM 表示词ti 经过charCNN 后的向量,hi,jLM、hi,jLM分别表示正向反向LSTM 的第j 层的第i 个LSTMCell 的隐藏层状态。
其中正向语言模型(从前往后预测):
p(t1,t2,..,tn)=k=1∏np(tk∣t1,t2,...,tk−1)
反向语言模型(从后往前预测):
p(t1,t2,..,tn)=k=1∏np(kk∣tk+1,tk+2,...,tn)
需要注意的是,正向反向语言模型会共享部分参数。,两者并不是完全独立的。
优化目标,联合正反向网络:
obj=MAX(k=1∑n(log p(tk∣t1,t2,...,tk−1:θx,θLSTM,θs)+log p(tk∣tk+1,tk+2,...,tn:θx,θLSTM,θs)))
其中θx 表示词表征参数, θs 表示softmax 参数,θLSTM表示LSTM 网络参数。
显然模型采用的损失函数就是MLE,这样我们就可以训练这个网络。
ELMO
对于训练好的L 层的双向语言模型,每个token,例如第k 个词tk 都可以用2L+1 个向量集合表示,如下:
Rk={xkLM,hk,jLM,hk,jLM∣j=1,..,L}
为了下游的模型能更好的使用上面得出的词表征,我们需要将2L+1 向量集合压缩成一个向量表示。
ELMok=E(Rk;θe)
例如,我们可以仅仅使用双向语言模型的最后一层的输出:
E(Rk)=hk,LLM
其中hk,LLM=[hk,jLM:hk,jLM]
更普遍的做法是:
ELMoktask=E(Rk;θtask)=γtaskj=0∑Lsjtaskhk,jLM
sjtask 表示按特定任务对权重做softmax−normalized, γ是需要根据经验调试的超参数。
将ELMo应用到有监督学习
- 将ELMo 词向量直接与普通的词向量(例如本文中经过Char−CNN得到的词向量)拼接,即:[xk:ELMoktask]。
- 将ELMo 词向量直接与双向的语言模型的隐层状态hk 拼接,即:[hk:ELMoktask] 拼接,论文中说这种拼接操作,在效果上更好。论文中有提到,对于网络中不同层能表示出词的不同含义。比如:High-level LSTM可以捕捉词语上下文独立的语义信息,适合做监督的词义消歧任务;Lower-level的可以捕捉句法信息,适合做词性标注。那么这里与不同层的状态拼接操作,就相当于Ensemble的操作,所以效果会比较好?
- 对ELMo 做正则操作,也就是对双向的LSTM 中权重做正则处理。即对模型loss 函数加上λ∣∣w∣∣22。
实验分析
论文的实验部分验证了加入MLMo 的词向量在各个NLP任务上都得到了很好的表现。这里面举一些个人觉得比较有亮点的部分分析下。
使用所有层信息、使用最后一层信息、以及正则的实验效果
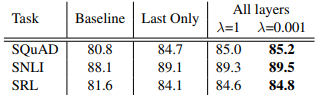
Baseline 是没有使用ELMo 的词向量,last only 是仅仅使用双向语言模型的最后一层的词向量,All layers 使用了双向语言模型所有层的词向量集成,显然我们可以看出当正则λ=0.001 并且使用了所有层的词向量集成,效果答复提升。说明这种集成的做法是比较有效的。
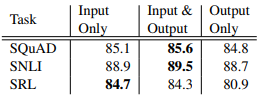
将ELMo词向量用在模型的输入处和输出处的效果对比
关键代码
构建带残差的双向语言模型
with tf.variable_scope("elmo_rnn_cell"):
self.forward_cell = tf.nn.rnn_cell.LSTMCell(self.hidden_size, reuse=tf.AUTO_REUSE)
self.backward_cell = tf.nn.rnn_cell.LSTMCell(self.hidden_size, reuse=tf.AUTO_REUSE)
if config.get("use_skip_connection"):## 残差连接
self.forward_cell = tf.nn.rnn_cell.ResidualWrapper(self.forward_cell)
self.backward_cell = tf.nn.rnn_cell.ResidualWrapper(self.backward_cell)
with tf.variable_scope("elmo_softmax"):## 下面的forward_softmax_w 就是上面所讲的$s^{task}_j$
softmax_weight_shape = [config["word_vocab_size"], config["elmo_hidden"]]
self.forward_softmax_w = tf.get_variable("forward_softmax_w", softmax_weight_shape, dtype=tf.float32)
self.backward_softmax_w = tf.get_variable("backward_softmax_w", softmax_weight_shape, dtype=tf.float32)
self.forward_softmax_b = tf.get_variable("forward_softmax_b", [config["word_vocab_size"]])
self.backward_softmax_b = tf.get_variable("backward_softmax_b", [config["word_vocab_size"]])
embedding_output = self.embedding.forward(data)## 将data经过char-cnn得到普通词向量
with tf.variable_scope("elmo_rnn_forward"):
forward_outputs, forward_states = tf.nn.dynamic_rnn(self.forward_cell,
inputs=embedding_output,
sequence_length=data["input_len"],
dtype=tf.float32)
with tf.variable_scope("elmo_rnn_backward"):
backward_outputs, backward_states = tf.nn.dynamic_rnn(self.backward_cell,
inputs=embedding_output,
sequence_length=data["input_len"],
dtype=tf.float32)
# #将正反向模型链接起来
forward_projection = tf.matmul(forward_outputs, tf.expand_dims(tf.transpose(self.forward_softmax_w), 0))
forward_projection = tf.nn.bias_add(forward_projection, self.forward_softmax_b)
backward_projection = tf.matmul(backward_outputs, tf.expand_dims(tf.transpose(self.backward_softmax_w), 0))
backward_projection = tf.nn.bias_add(backward_projection, self.backward_softmax_b)
return forward_outputs, backward_outputs, forward_projection, backward_projection
上面只是定义了一层的LSTM网络,但是通过残差连接,把一层的输入和输出连接在一起了。就相当于将不同层的隐状态集成到一起了。
模型训练
def train(self, data, global_step_variable=None):
forward_output, backward_output, _, _ = self.forward(data)
## 注意data[target]只是比输入延后了一步
forward_target = data["target"]
forward_pred = tf.cast(tf.argmax(tf.nn.softmax(forward_output, -1), -1), tf.int32)
forward_correct = tf.equal(forward_pred, forward_target)
forward_padding = tf.sequence_mask(data["target_len"], maxlen=self.seq_len, dtype=tf.float32)
forward_softmax_target = tf.cast(tf.reshape(forward_target, [-1, 1]), tf.int64)
forward_softmax_input = tf.reshape(forward_output, [-1, self.hidden_size])
forward_train_loss = tf.nn.sampled_softmax_loss(
weights=self.forward_softmax_w, biases=self.forward_softmax_b,
labels=forward_softmax_target, inputs=forward_softmax_input,
num_sampled=self.config["softmax_sample_size"],
num_classes=self.config["word_vocab_size"]
)
forward_train_loss = tf.reshape(forward_train_loss, [-1, self.seq_len])
forward_train_loss = tf.multiply(forward_train_loss, forward_padding)
forward_train_loss = tf.reduce_mean(forward_train_loss)
## 反向模型需要将target翻转,因为是从后向前预测的。
backward_target = tf.reverse_sequence(data["target"], data["target_len"], seq_axis=1, batch_axis=0)
backward_pred = tf.cast(tf.argmax(tf.nn.softmax(backward_output, -1), -1), tf.int32)
backward_correct = tf.equal(backward_pred, backward_target)
backward_padding = tf.sequence_mask(data["target_len"], maxlen=self.seq_len, dtype=tf.float32)
backward_softmax_target = tf.cast(tf.reshape(backward_target, [-1, 1]), tf.int64)
backward_softmax_input = tf.reshape(backward_output, [-1, self.hidden_size])
backward_train_loss = tf.nn.sampled_softmax_loss(
weights=self.backward_softmax_w, biases=self.backward_softmax_b,
labels=backward_softmax_target, inputs=backward_softmax_input,
num_sampled=self.config["softmax_sample_size"],
num_classes=self.config["word_vocab_size"]
)
backward_train_loss = tf.reshape(backward_train_loss, [-1, self.seq_len])
backward_train_loss = tf.multiply(backward_train_loss, backward_padding)
backward_train_loss = tf.reduce_mean(backward_train_loss)
train_loss = forward_train_loss + backward_train_loss
train_correct = tf.concat([forward_correct, backward_correct], axis=-1)
train_acc = tf.reduce_mean(tf.cast(train_correct, tf.float32))
tf.summary.scalar("train_acc", train_acc)
tf.summary.scalar("train_loss", train_loss)
train_ops = tf.train.AdamOptimizer().minimize(train_loss)
return train_loss, train_acc, train_ops
获得EMLo词向量
def pred(self, data):
-,-, forward_projection, backward_projection= self.forward(data)
eval_output = tf.concat([forward_projection, backward_projection], axis=-1)
return eval_output
上面的 forward_projection,backward_projection 分别表示正向,反向网络集成各层隐状态得到词向量表示,将其连接起来就得到了上某种形式的EMLo 词向量。
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 [email protected] 举报,一经查实,本站将立刻删除。