

作者:Mintimate
博客:https://www.mintimate.cn Mintimate’s Blog,只为与你分享
前言
最近挺好奇的,B站每天Top100,具体什么视频最多,播放量和视频的弹幕数有没有比例关系。
所以,我们就来写一个Python爬虫,批量看看B站Top100是什么内容吧。同时,我自己又有腾讯云的轻量应用服务器,性能强劲,运行个爬虫没问题;写好爬虫后,配合Cron定时任务,就可以连续爬取数据了。
受限篇幅,只展现关键代码。Cron定时任务等,就不做展示啦。代码没有重构,如果有很大小伙伴需要,我重构了放GitHub吧~
最终效果(可视化数据):https://mintimate.github.io/BilibiliSpiderDemo/
环境依赖
首先是Python的环境依赖,Python3自然不用多说。部分的依赖:
- bilibili_api==9.0.2
- matplotlib==3.3.4
- numpy==1.18.2
- pandas==1.2.4
- Pillow==9.0.0
- pyecharts==1.9.0
- requests==2.23.0
这里重点介绍两个依赖包:bilibili_api和pyecharts。
bilibili_api
项目地址:https://github.com/MoyuScript/bilibili-api
使用这个库文件,主要是用于解决B站弹幕二进制加密问题:
from bilibili_api import video, sync
# 根据视频BV号,获取视频信息
v = video.Video(bvid='BV1AV411x7Gs')
# 弹幕
dms = sync(v.get_danmakus(0))
for dm in dms:
print(dm)另外,这个库可能不会再更新:

但是,还有另外一个项目:https://github.com/SocialSisterYi/bilibili-API-collect
如果bilibili_api失效,可以用这个代替(比如:B站弹幕获取)。
pyecharts
这个Pyecharts完全可以替换原来的matplotlib库,还不用处理中文字库问题。
之所以刚开始还用matplotlib…… 主要是,我平时Python写的不多,代码写到一半,才发现有Pyecharts这个好用的库⁄(⁄ ⁄ ⁄ω⁄ ⁄ ⁄)⁄
支持的图多:

数据爬取
首先,我们需要爬取B站视频Top前100,观察页面,可以看到数据接口:

request请求参数
使用request模拟请求:
POPULAR_URL = "https://api.bilibili.com/x/web-interface/popular"
HEADERS = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'referer': 'https://www.bilibili.com/',
'x-csrf-token': '',
'x-requested-with': 'XMLHttpRequest',
'cookie': ''
,
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36'
}参数已经脱敏
如果再观察上述的数据接口,可以发现,这个请求的参数:
-
pn:页数。
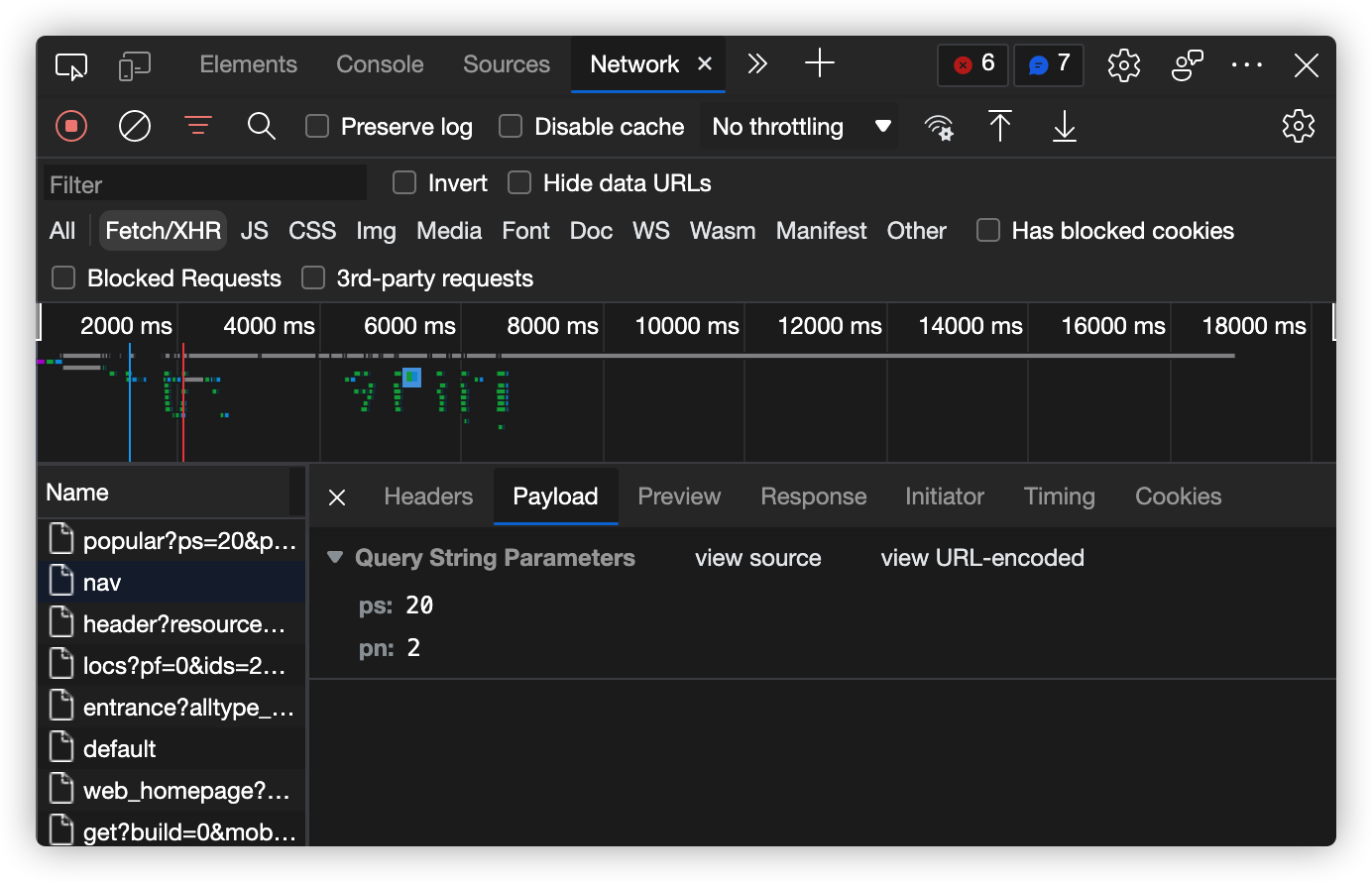
其中,pn=1代表Top20,pn=2代表Top21-40,以此类推。所以需要写一个for循环;配合数据接口内的分析:
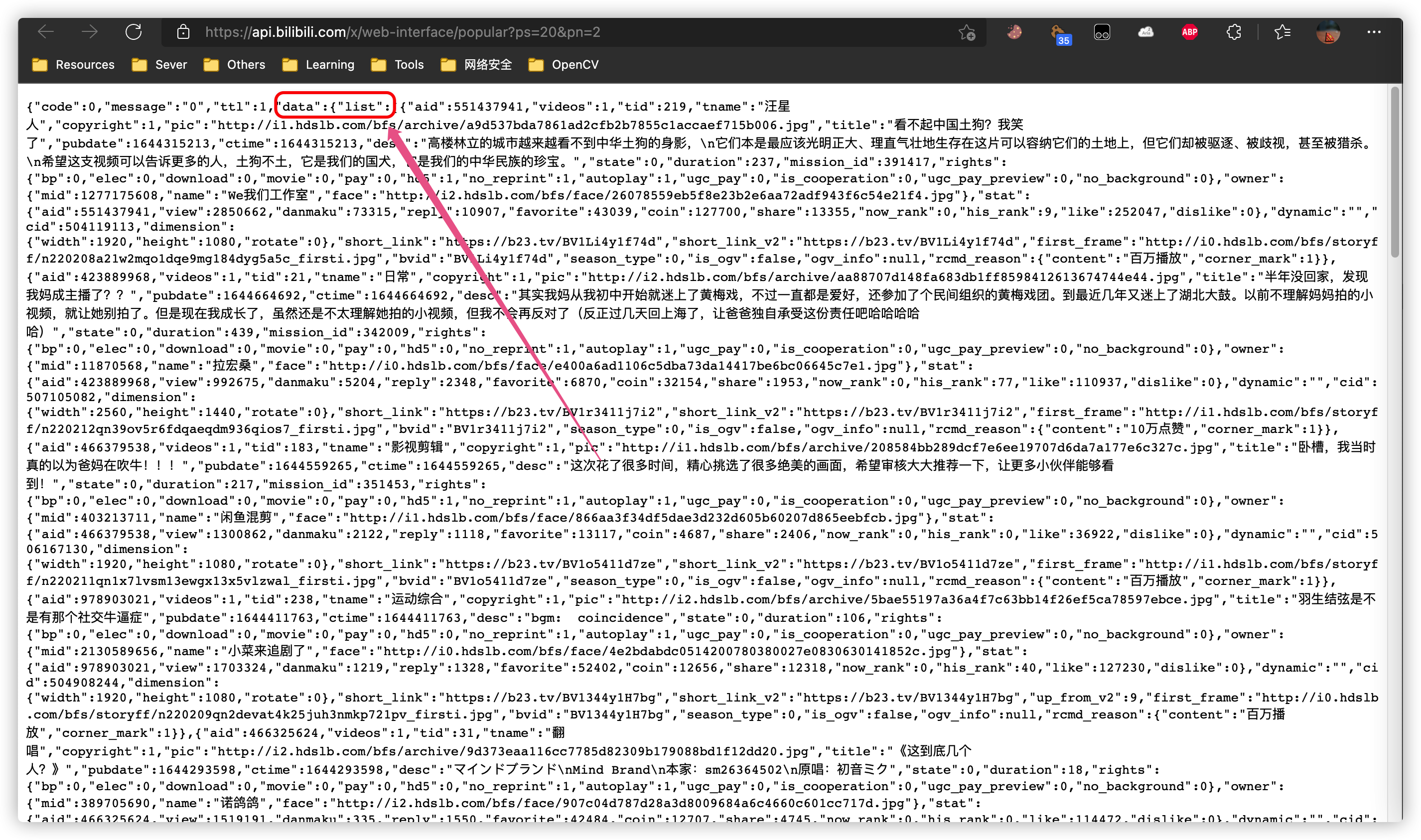
代码如下:
def get_popular_list():
"""
获取排行榜1-100
:param pn:
:return: All bvid_list
"""
bvidList = []
for i in range(1, 6):
query = "pn=" + str(i)
r = requests.get(POPULAR_URL, headers=HEADERS, params=query)
resultList = r.json()['data']['list']
for item in resultList:
bvidList.append(
bilibili_api.aid2bvid(
item['aid']
)
)
return bvidList
bilibili_api.aid2bvid为aid转bvid,由bilibili_api提供。
最后,运行看看效果:
if __name__ == '__main__':
for i in get_popular_list():
print(i)
视频详情获取
bilibili_api内提供了获取视频详情的方法,比如:
from bilibili_api import video, sync
def _method_get_videos_info(bvid):
# 实例化 Video 类
v = video.Video(bvid=bvid)
# 获取视频信息
info = sync(v.get_info())
# 打印视频信息
return info
if __name__ == '__main__':
print(_method_get_videos_info("BV1cL411w7RB"))输出:

所以,刚刚我们已经用request获取了全部Top100视频的Bv号,现在只需要for循环一次,就可以得到全部视频的信息了。
既然这么简单,我们就多一步,将信息变成文件流,存储到csv文件内:
def _method_save_to_csv(filename_last, video_info):
file_path = ("../数据/videoTop_%s.csv" % filename_last)
# 判断路径是否存在
if not os.path.exists("../数据/"):
os.makedirs("../数据/")
# 如果文件存在,则覆盖写入
f = open(file_path, mode="w", encoding='utf-8', newline='')
csv_writer1 = csv.DictWriter(f,
fieldnames=[
'视频bvid', '视频aid', 'videos', '视频分类', '版权所有',
'视频封面', '视频标题', '上传时间', '公开时间', '视频描述',
'播放量', '点赞量']
)
csv_writer1.writeheader()
for info in video_info:
info = _method_get_videos_info(info)
data_dict1 = {
'视频bvid': info.get('bvid', "None"),
'视频aid': info.get('aid', "None"),
'videos': info.get('videos', "None"),
'视频分类': info.get('tname', "None"),
'版权所有': info.get('copyright', "None"),
'视频封面': info.get('pic', "None"),
'视频标题': info.get('title', "None"),
'上传时间': info.get('ctime', "None"),
'公开时间': info.get('pubdate', "None"),
'视频描述': info.get('desc', "None"),
'播放量': info.get('stat', "None").get('view', "None"),
'点赞量': info.get('stat', "None").get('like', "None")
}
csv_writer1.writerow(data_dict1)
f.close()最后结果:
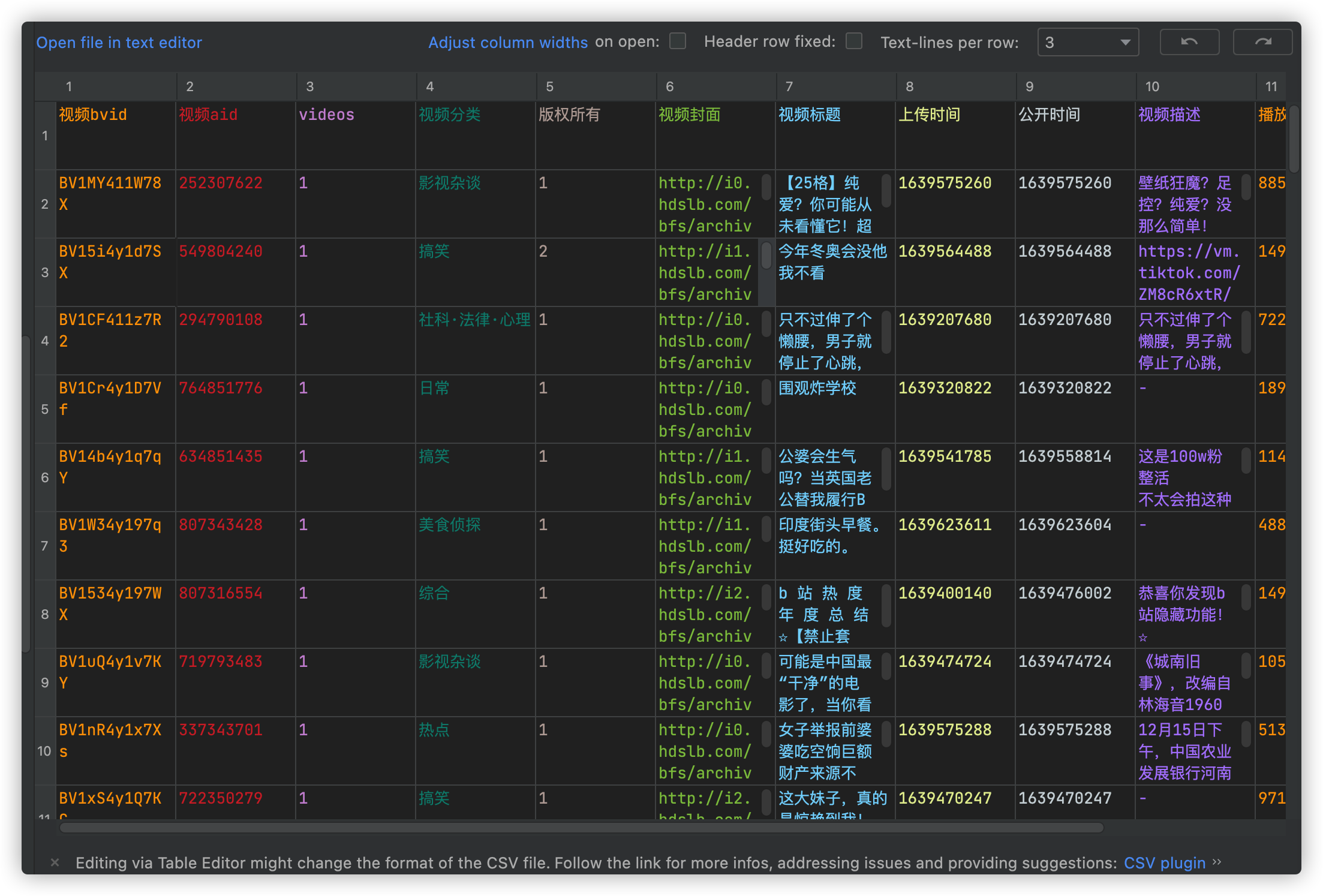
这样,我们的视频详情就获取完毕了。
弹幕获取
弹幕怎么获取呢?其实也很简单,和刚刚一样,用外部包:
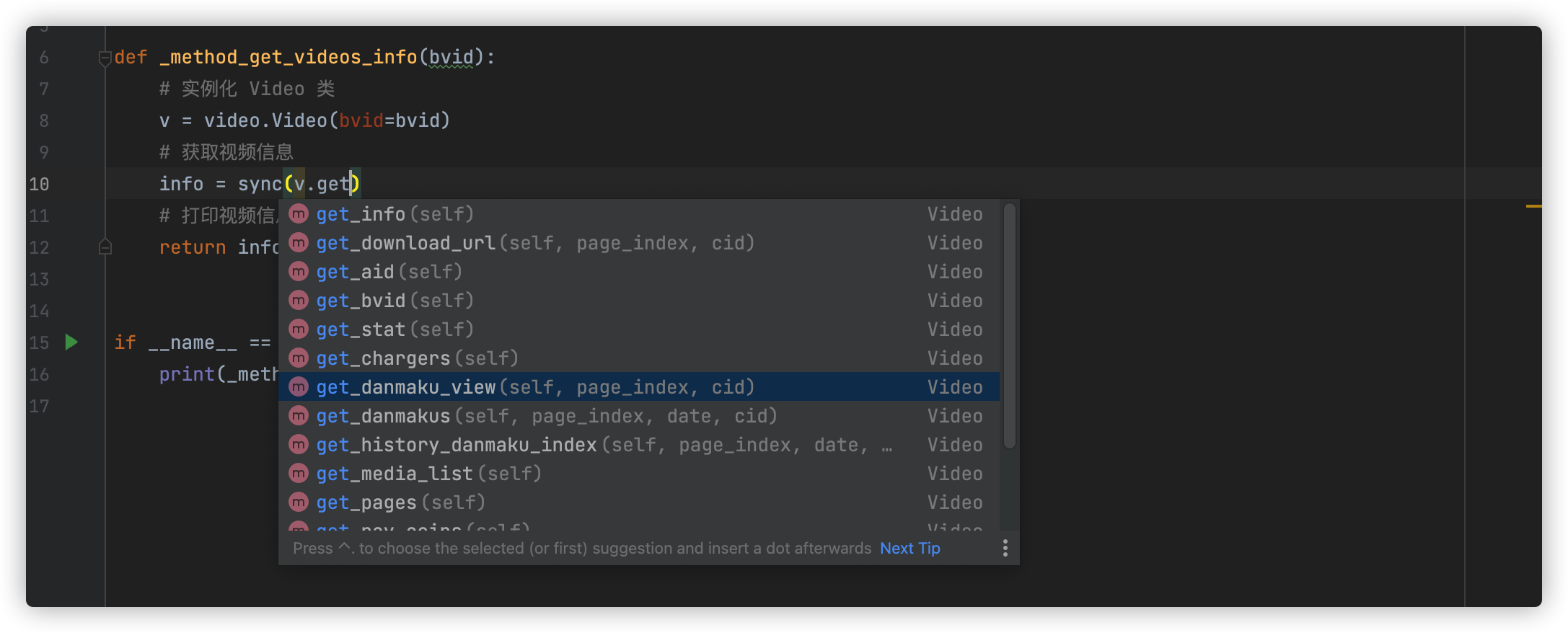
需要注意的是:B站弹幕获取有IP响应次数限制。解决的方法:
- 使用time.sleep,对主线程休眠。
- 使用IP池。
还需要注意,一些视频关闭弹幕功能,需要进行try...catch:
try:
dms = sync(v.get_danmakus(0))
# 敏感视频,关闭弹幕功能
except DanmakuClosedException:
dms = []
except ResponseCodeException:
dms = []
except KeyError:
dms = []源码就不展示了:

另外,如果你爬取时候不行(因为B站更改了数据接口,而Bilibili_api项目停更了),可以注释源码内的这条数据:
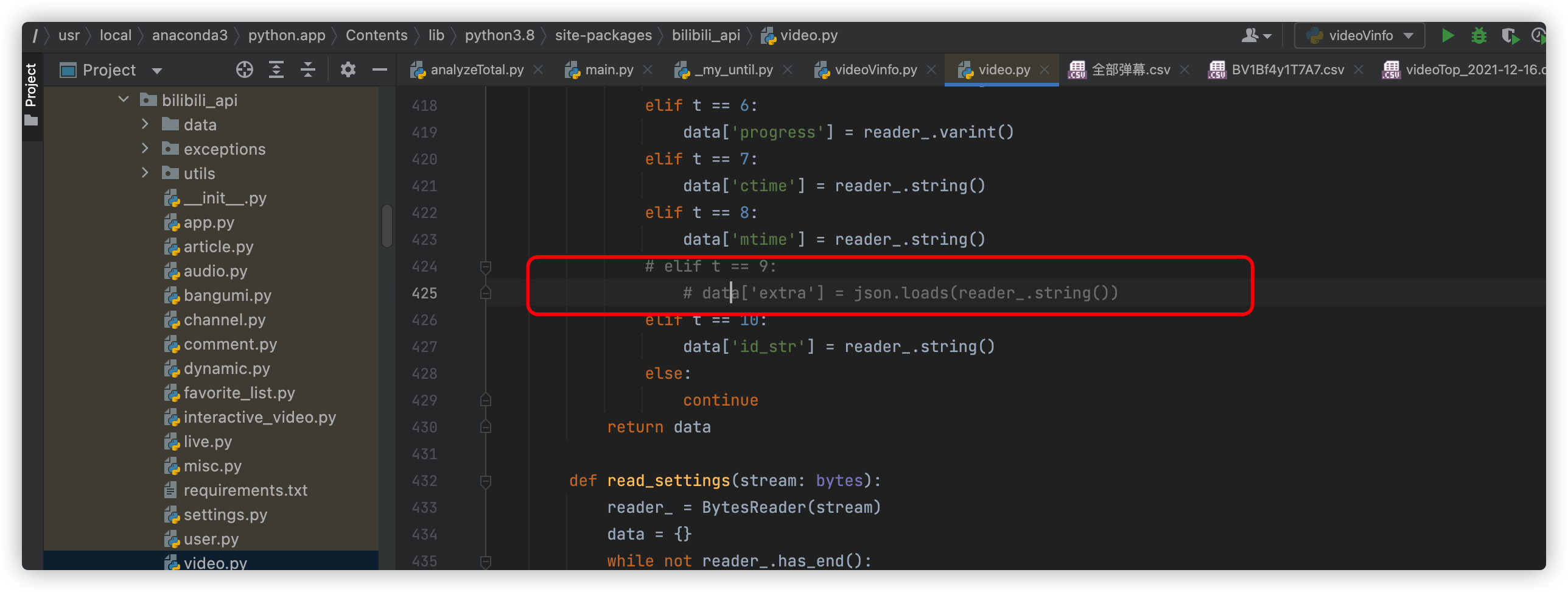
或者你可以使用B站的数据接口:http://api.bilibili.com/x/v2/dm/web/seg.so
参数:
参数名 |
类型 |
内容 |
必要性 |
备注 |
|---|---|---|---|---|
type |
num |
弹幕类 |
必要 |
1:视频弹幕 |
oid |
num |
视频cid |
必要 |
|
pid |
num |
稿件avid |
非必要 |
|
segment_index |
num |
分包 |
必要 |
6分钟一包 |
下载下来是seg.so文件,需要解密,用protobuf编译:https://github.com/SocialSisterYi/bilibili-API-collect/blob/master/grpc_api/bilibili/community/service/dm/v1/dm.proto
就可以解析下载下来的二进制文件:
视频前6分钟,有一个弹幕投票…… 所以观众发的都是投票弹幕…… ╮( ̄▽ ̄\"\")╭
看看存储的效果:
接下来就是数据可视化了。
数据可视化
首先,数据可视化前,一定需要有足够的数据。上文数据爬取,其实我在服务器上用cron定期执行了一个月了。所以得到的数据比较多:
所以,数据可视化时候,我先合并了数据。之后,进行画图。
首先,获取了视频分类的词频:
classify_list = []
for item in _method_get_videos_info_documents("../数据"):
classify_list.extend(_method_get_classify_info("../数据/" + item))
classify_top = collections.Counter(classify_list)其中,_method_get_videos_info_documents方法:
def _method_get_videos_info_documents(filepath):
'''
根据弹幕文件夹名获取当天视频Top100文件(videoTop_xxx.csv)
:param video_top_file_name:
:return:
'''
video_top_list = []
for item in method_get_danmu_folders(filepath):
video_top_list.append("videoTop_" + item)
return video_top_list
def _method_get_classify_info(video_top_file_name):
'''
根据视频信息csv文件,获取视频全部分类
:param video_top_file_name:
:return:
'''
df = pd.read_csv(video_top_file_name + ".csv", low_memory=False)
return df['视频分类'].tolist()为了做词云,提取全部弹幕,并选取前500词:
# 获取清洗好后的弹幕list
world_list = _method_get_danmu_content_by_path("../数据清洗/全部弹幕.csv")
# 用collections进行词频统计
result = collections.Counter(world_list)
# 获取前1000
too_100 = result.most_common(500)现在就可以画图了。
定义页面
首先,我们定义一个页面:
def page_simple_layout(data_list,
world_list,
date_list, view_count_list, danmu_count_list):
'''
画图页面
:param data_list: 视频信息list
:param world_list: Top前500弹幕
:param date_list: 日期list
:param view_count_list: 播放量list
:param danmu_count_list: 每天对应的弹幕数list
:return: None
'''
print(data_list.most_common(50))
page = Page()
page.add(
draw_pie(data_list.most_common(10)),
draw_line(data_list.most_common(50)),
draw_bar(date_list, view_count_list, danmu_count_list),
draw_word_cloud(world_list),
)
page.render("Total.html")这个是pyecharm的页面方法,其中page.add内的内容,为其他图的方法名。可以看到,我们依次会渲染:
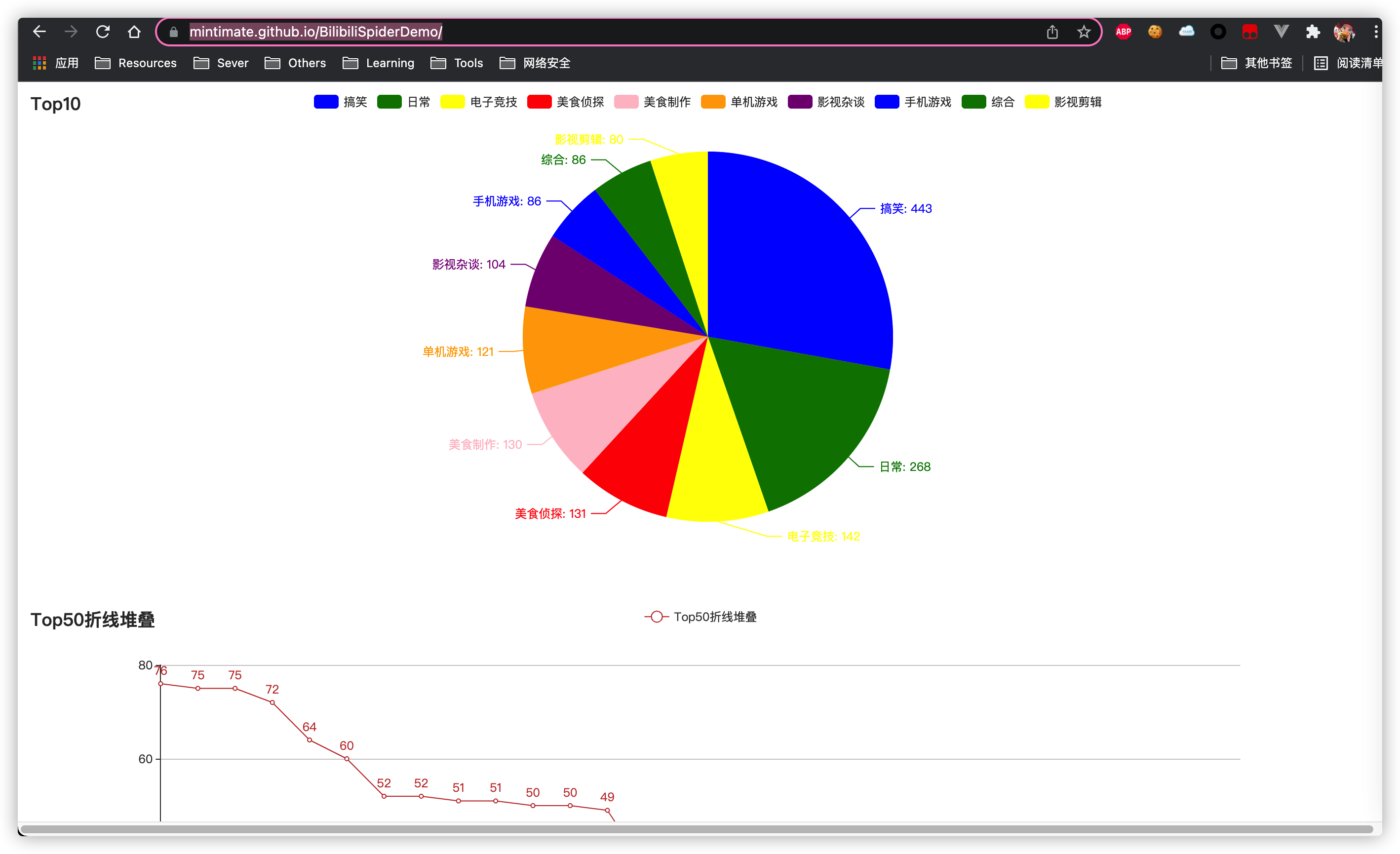
- 饼图:视频分类Top10
- 折线图:视频Top分类50
- 柱状图:视频播放量和弹幕关系
- 词云:弹幕词云
page.render为最后写入的地址,需要为HTML,最后Python会进行渲染。
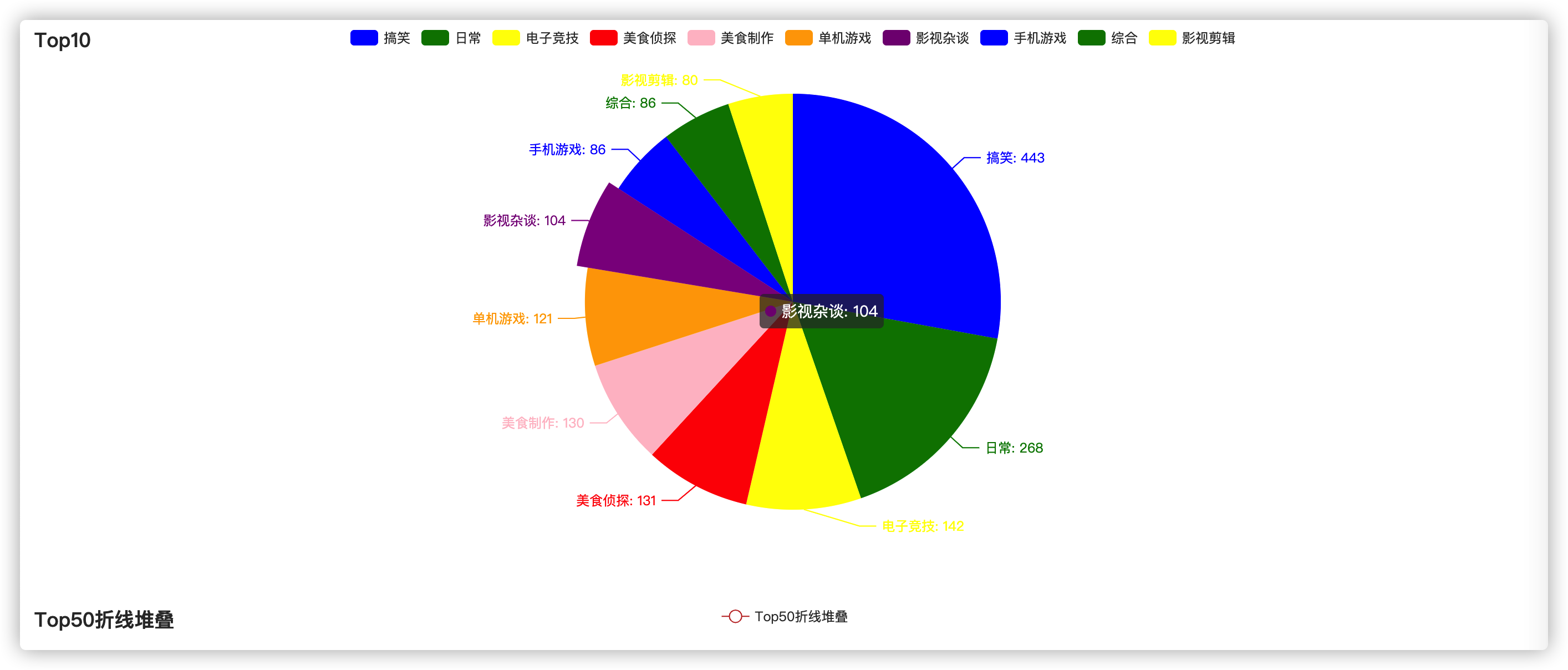
饼图:视频分类Top10
这个很简单,更着官方文档自己写一下就出来了:
def draw_pie(data_list) -> Pie:
choose_list = []
values_list = []
for item in data_list:
choose_list.append(item[0])
values_list.append(item[1])
c = (
Pie(init_opts=opts.InitOpts(width="100%"))
.add("", [list(z) for z in zip(choose_list, values_list)])
.set_colors(["blue", "green", "yellow", "red", "pink", "orange", "purple"])
.set_global_opts(
title_opts=opts.TitleOpts(title="Top10"),
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
# .render("饼图.html")
)
return c需要注意,这里是作为对象返回一个Pie实例,用于给Page渲染。
提前看看效果:
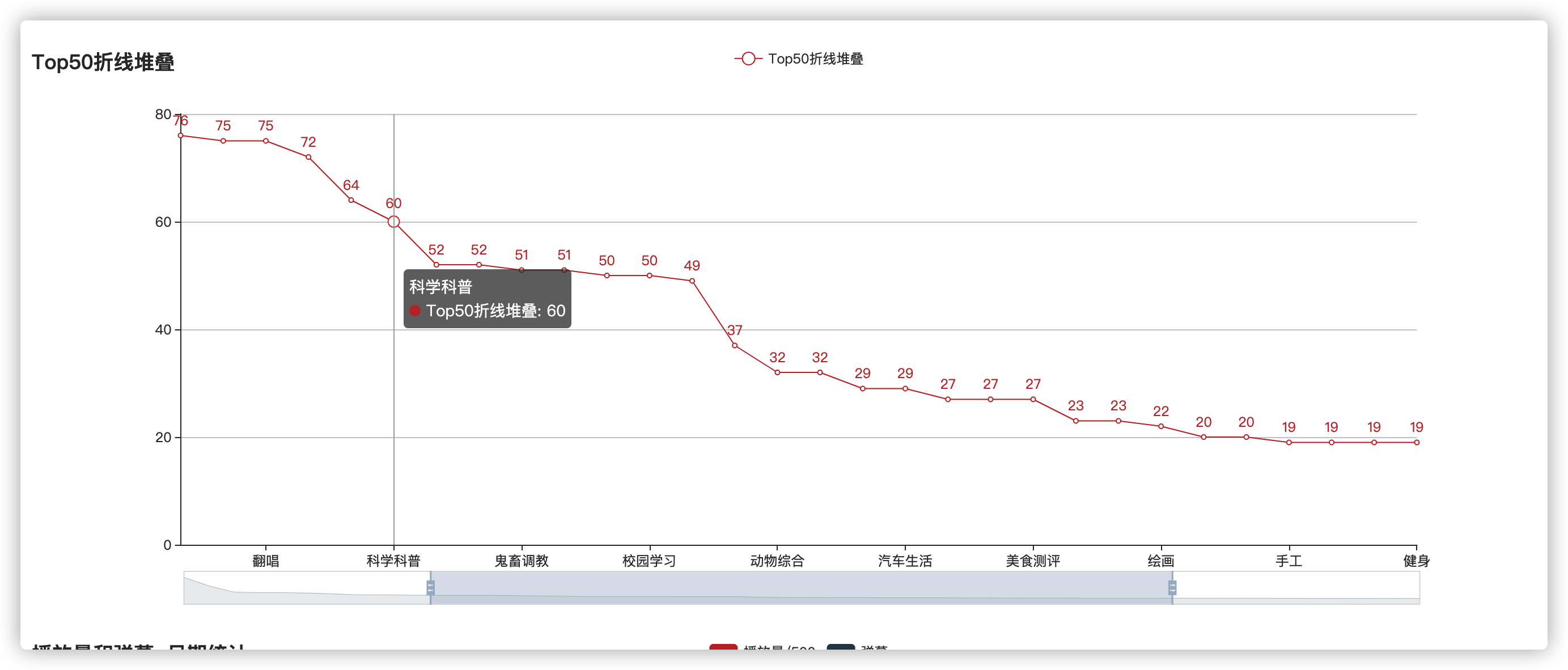
折线图:视频Top分类50
折线图也是一样的:
def draw_line(data_list) -> Line:
x_data = []
y_data = []
for item in data_list:
x_data.append(item[0])
y_data.append(item[1])
line = (Line(init_opts=opts.InitOpts(width="100%")).add_xaxis(xaxis_data=x_data)
.add_yaxis(
series_name="Top50折线堆叠",
stack="总计",
y_axis=y_data,
label_opts=opts.LabelOpts(is_show=True), )
.set_global_opts(
title_opts=opts.TitleOpts(title="Top50折线堆叠"),
datazoom_opts=[opts.DataZoomOpts()],
tooltip_opts=opts.TooltipOpts(trigger="axis"),
yaxis_opts=opts.AxisOpts(
type_="value",
axistick_opts=opts.AxisTickOpts(is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=True),
),
xaxis_opts=opts.AxisOpts(type_="category", boundary_gap=False), )
)
# .render("折线图.html")
return line最后效果:
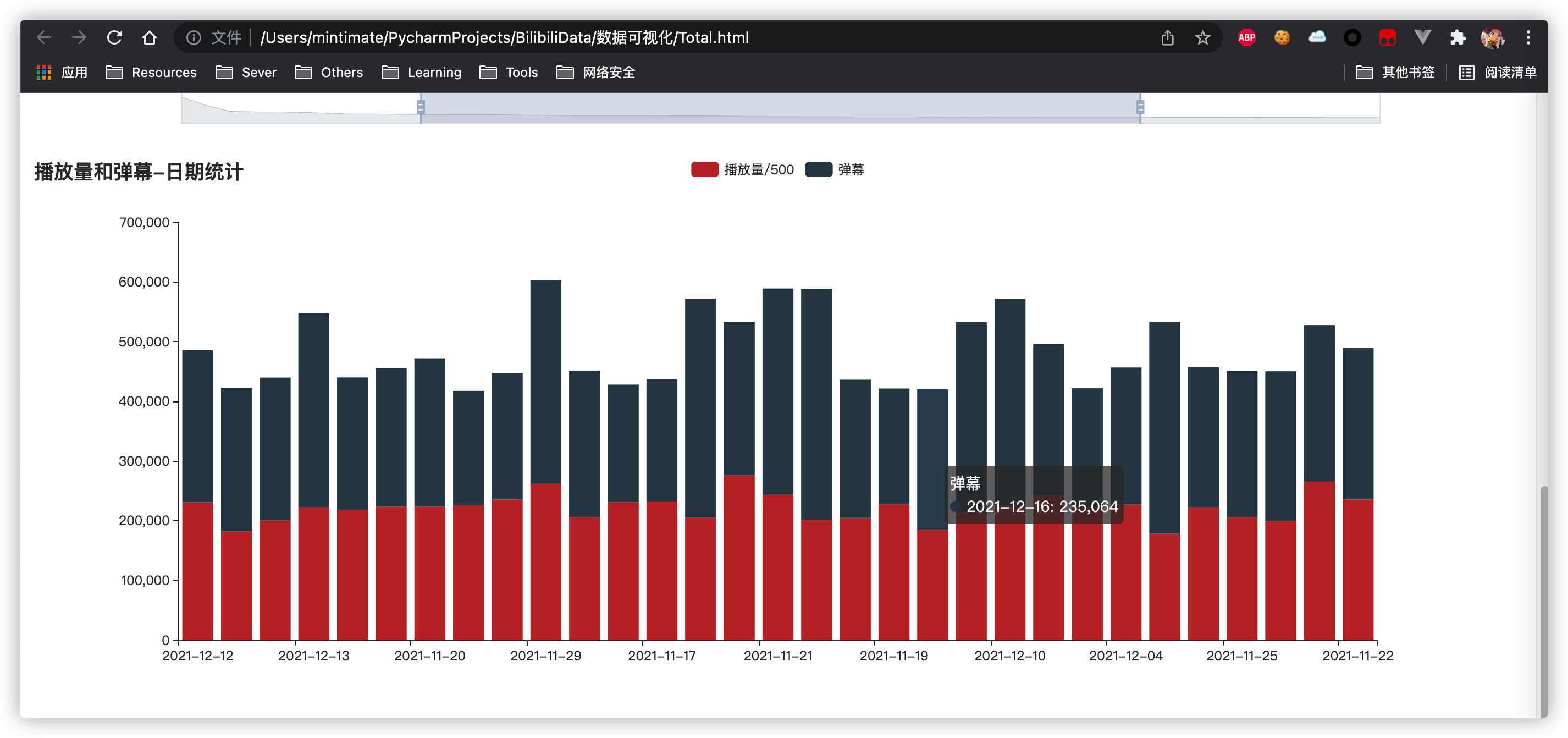
柱状图:视频播放量和弹幕关系
柱状图?应该是最简单的一个了:
def draw_bar(xaxis, yaxis1, yaxis2):
c = (
Bar(init_opts=opts.InitOpts(width="100%"))
.add_xaxis(xaxis)
.add_yaxis("播放量/500", yaxis1, stack="stack1")
.add_yaxis("弹幕", yaxis2, stack="stack1")
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(title_opts=opts.TitleOpts(title="播放量和弹幕-日期统计"))
)
return c最后效果:
词云:弹幕词云
词语就是前期的collection集合词频处理比较麻烦,不然也是很简单的:
def draw_word_cloud(word_list):
wc = (WordCloud(init_opts=opts.InitOpts(width="100%"))
.add("", data_pair=word_list, word_size_range=[10, 100], width="90%", height="85%")
.set_global_opts(
title_opts=opts.TitleOpts(title="弹幕Top100词云图"),
)
)
return wc最后效果:

为什么我前文说是Top 500弹幕,结果这里变成Top 100呢?其实是……500太多,页面无法展示全……所以临时改成100……
END
最后,我们来分析一下数据吧:
对于想投入自媒体的用户,建议选择“日常”类 或“搞笑”视频类的的视频,作为自己的创作目标,容易流量变现。
最后,根据这近20天的单天分析,可以轻易得出,周五到周天,普遍的网络用语会更多,应该是周末学生放假,或者上班族休息的原因,可以想到,Bilibili这个平台流量很大,总的用户群体很年轻。
原文地址:https://cloud.tencent.com/developer/article/1943166
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。