
一、拉取镜像
docker pull clickhouse/clickhouse-server二、构建容器
docker run -d --name some-clickhouse-server --ulimit nofile=262144:262144 clickhouse/clickhouse-server三、将容器的配置文件复制到宿主机
docker cp some-clickhouse-server:/etc/clickhouse-server/users.xml /docker/clickhouse/conf/users.xml
docker cp some-clickhouse-server:/etc/clickhouse-server/config.xml /docker/clickhouse/conf/config.xml
四、删除容器重新创建
docker rm -f some-clickhouse-server五、构建容器
docker run -d --name some-clickhouse-server -p 8123:8123 -p 9009:9009 -p 9090:9000 --ulimit nofile=262144:262144 --volume=/docker/clickhouse/data:/var/lib/clickhouse --volume=/docker/clickhouse/log:/var/log/clickhouse-server --volume=/docker/clickhouse/conf/config.xml:/etc/clickhouse-server/config.xml --volume=/docker/clickhouse/conf/users.xml:/etc/clickhouse-server/users.xml clickhouse/clickhouse-server
六、修改配置文件users.xml可编辑连接密码
客户端连接工具: https://dbeaver.io/download/
ClickHouse创建库和表(分布式 on cluster default_cluster)
CREATE DATABASE demo on cluster default_cluster ENGINE = Atomic;基础数据类型
Int8 Int16 Int32 Int64 String DateTime Float32 Float64 Enum8
创建分布表
1.分布式表(local本地表) ReplicatedMergeTree 只能用于分布式
CREATE TABLE demo.members_local
(
`id` Int64,`enterprise_id` Int64,`userid` String,`name` String,`mobile` String,`created_at` Int64,`updated_at` Int64,`deleted_at` Int64
)
ENGINE = ReplicatedMergeTree('/clickhouse/tables/demo.members/{shard}','{replica}')
PARTITION BY toYYYYMM(toDate(created_at))
ORDER BY idPARTITION BY toYYYYMM(toDate(created_at)) 根据表里的创建时间转换成年月创建分区
ORDER BY id 等同于索引2.分布式逻辑表
CREATE TABLE demo.members
(
`id` Int64,`deleted_at` Int64
)
ENGINE = Distributed('default_cluster','demo','members_local',id)
3.本地表和物理表本地表是存储在单个节点上的物理表。逻辑表是面向分布式环境设计的概念,它是由多个本地表组成的虚拟表。逻辑表不存储任何数据,而是定义了所有参与查询的物理表和它们之间的关系。当查询请求到达节点时,节点会将查询请求发送给所有相关节点,并在本地执行部分查询操作,最后将结果汇总返回给客户端。
四.分区数据合并原理
1.分区目录的命名规则
如果进入数据表所在的磁盘目录后,会发现分区目录的完整物理名称并不是只有ID而已,在ID之后还跟着一串奇怪的数字,
例如201905.1L1.0那么这些数字又代表着什么呢?对于MergeTree而言,它最核心的特点是其分区目录的合并动作。从分区目录的命名中便能够解读出它的合并逻辑,我们会着重对命名公式中各分项进行解读,一个完整分区目录的命名公式如下所示:PartitionID MinBlockNum MaxBlockNum Level
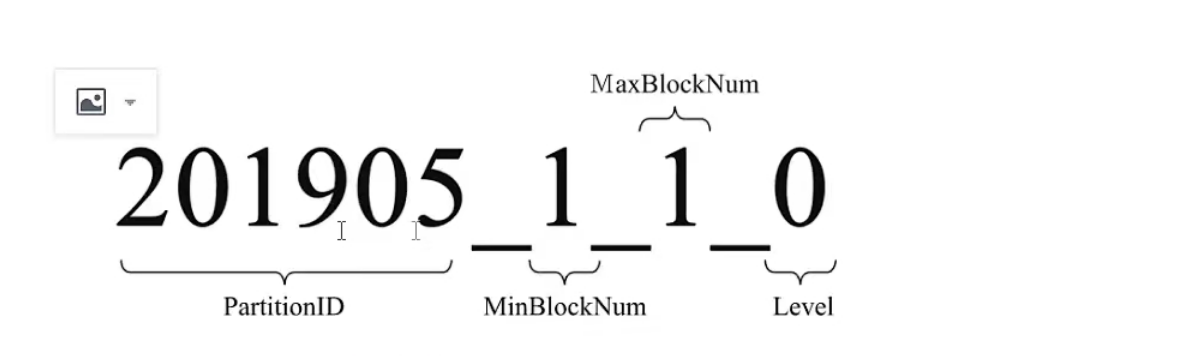
201905表示分区目录的ID; 11分别表示最小的数据块编号与最大的数据块编号; 而最后的_0则表示目前合并的层级。
接下来开始分别解释它们的含义: (1) PartitionID:分区ID,无须多说。
(2)MinBlockNum和MaxBlocNum:顾名思义,最小数据块编号与最大数据块编号。这里的BlockNum是一个整型的自增长编号。如果将其设为n的话,那么计数n在单张MergeTree数据表内全局累加,从1开始,每当新创建一个分区目录时,计数就会累积加1。对于一个新的分区目录而言,MinBlockNum与MaxBlockNum取值-样,同等于n 例201905_1L1 0、201906 2.2_0以此类推但是也有例外,当分区目录发生合并时,对于新产生的合并目录MinBlockNum与MaxBlockNum有着另外的取值规则。
(3)Level:合并的层级,可以理解为某个分区被合并过的次数,或者这个分区的年龄。数值越高表示年龄越大。Leve计数与BlockNum有所不同,它并不是全局累加的。对于每一个新创建的分区目录而言,其初始值均为0。之后,以分区为单位,如果相同分区发生合并动作,则在相应分区内计数累和加1
分区目录的合并过程
MergeTree的分区目录和传统意义上其他数据库有所不同。首先,Mergeree的分区目录并不是在数据表被创建之后就存在的,而是在数据写入过程中被创建的也就是说如果一张数据表没有任何数据,那么也不会有任何分区目录存在。其次,它的分区目录在建立之后也并不是一成不变的。在其他某些数据库的设计中,追加数据后目录自身不会发生变化,只是在相同分区目录中追加新的数据文件。而MergeTree完全不同,随着每一批数据的写入(一次INSERT语句)MergeTree都会生成一批新的分区目录,即便不同批次写入的数据属于相同分区,也会生成不同的分区目录,也就是说,对于同一个分区而言,也会存在多个区目录的情况。在之后的某个时刻(写入后的10~ 15分钟,也可以手动执行optimize查询语句),ClckHouse会通过后台任务再将属于相同分区的多个目录合成一个新的目录。已经存在的旧分区目录并不会立即被删除,而是在之后的某个时刻通过后台任务被删除(默认8分钟)。属于同一个分区的多个目录,在合并之后会生成一个全新的目录,目录中的索引和数据文件也会相应地进行合并。新目录各称的合并方式遵循以下规则,其中 MinBlockNum: 取同一分区内所有目录中最小的MinBlockNum值。 MaxBlockNum: 取同一分区内所有目录中最大的MaxBlockNum值 Level: 取同一分区内最大Level值并加1。

版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。