
引言
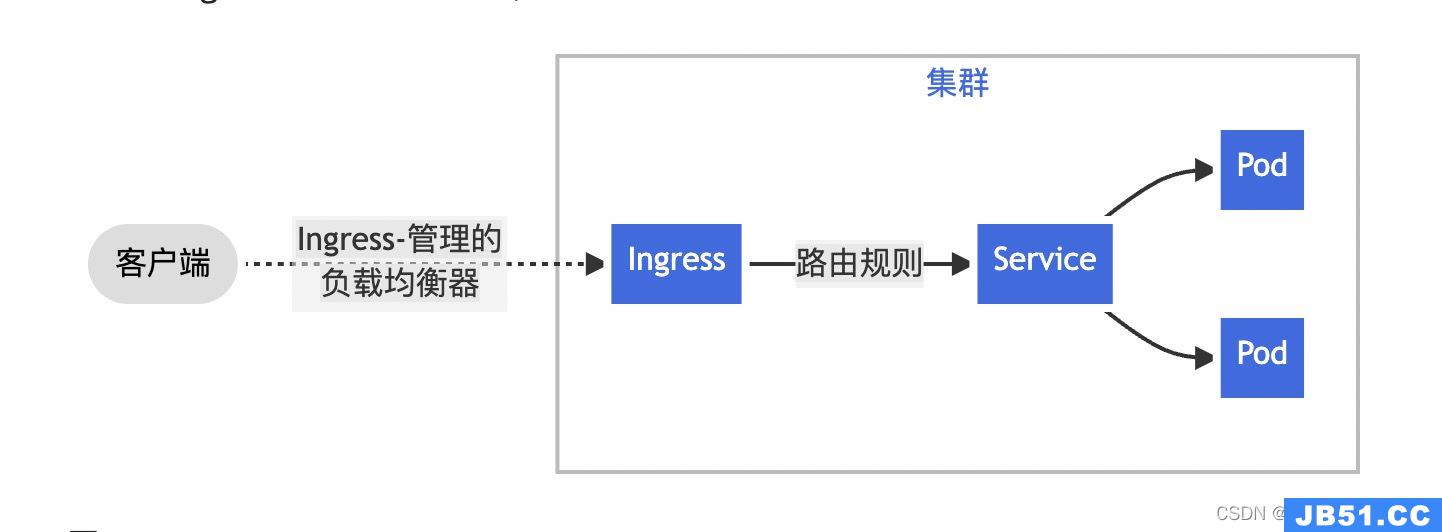
Ingress是Kubernetes集群中的一种资源类型,用于实现用域名的方式访问Kubernetes内部应用。它为Kubernetes集群中的服务提供了入口,可以提供负载均衡、SSL终止和基于名称的虚拟主机。在生产环境中常用的Ingress有Treafik、Nginx、HAProxy、Istio等。基本概念是在Kubernetes v 1.1版中添加的Ingress用于从集群外部到集群内部Service的HTTP和HTTPS路由,流量从Internet到Ingress再到Services最后到Pod上。通常情况下,Ingress部署在所有的Node节点上,可以配置提供服务外部访问的URL、负载均衡、终止SSL,并提供基于域名的虚拟主机,但它不会暴露任意端口或协议。
配置示例
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: minimal-ingress
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
ingressClassName: nginx-example
rules:
- http:
paths:
- path: /testpath
pathType: Prefix
backend:
service:
name: test
port:
number: 80
Ingress 需要指定 apiVersion、kind、 metadata和 spec 字段。 Ingress 对象的命名必须是合法的 DNS 子域名名称。 关于如何使用配置文件的一般性信息,请参见部署应用、 配置容器、 管理资源。 Ingress 经常使用注解(Annotations)来配置一些选项,具体取决于 Ingress 控制器, 例如 rewrite-target 注解。 不同的 Ingress 控制器支持不同的注解。 查看你所选的 Ingress 控制器的文档,以了解其所支持的注解。
Ingress 规约 提供了配置负载均衡器或者代理服务器所需要的所有信息。 最重要的是,其中包含对所有入站请求进行匹配的规则列表。 Ingress 资源仅支持用于转发 HTTP(S) 流量的规则。
如果 ingressClassName 被省略,那么你应该定义一个默认的 Ingress 类。
有些 Ingress 控制器不需要定义默认的 IngressClass。比如:Ingress-NGINX 控制器可以通过参数 --watch-ingress-without-class 来配置。 不过仍然推荐 按下文所示来设置默认的 IngressClass。
负载均衡的实现
Ingress可以通过定义规则将外部流量路由到集群内部的服务,具体实现方式如下:
- 在Kubernetes集群中部署一个Ingress Controller组件,它可以根据Ingress中定义的规则提供对应的代理能力。
- Ingress Controller会解析处理Ingress中定义的规则,并且动态地监听集群中Ingress规则变化,实时的进行刷新操作。
- 通过
HTTP和HTTPS的形式暴露集群内部服务,通过指定的域名规则定义,可以将集群外部的流量路由传输到集群内部的服务,最终到达Pod中被应用程序接收和处理。
负载均衡策略
Ingress的负载均衡策略主要有以下几种:
- round_robin :轮询调度,默认的负载均衡策略,按照每个后端服务的权重进行请求分配。
- ewma :指数加权移动平均策略,它是一种动态的负载均衡策略,权重计算基于后端服务的响应时间。如果某个服务的响应时间较长,那么它的权重会相应降低,从而分配到的请求会减少。
- chash :基于哈希的负载均衡策略,它将请求的URL和HTTP方法作为key,将后端服务作为value,相同的key会被映射到相同的服务。
- chashsubset :基于哈希子集的负载均衡策略,它将请求的URL和HTTP方法作为key,将后端服务作为value,相同的key会被映射到相同的服务。同时,它还会根据后端服务的性能和健康状况动态地调整权重。
- sticky :粘性负载均衡策略,它根据客户端的IP地址和请求的URL和HTTP方法来分配请求。同一个IP地址的请求会被映射到同一个后端服务。
以上是Ingress支持的一些负载均衡策略,可以根据实际需求选择合适的策略。
实现模式
Ingress在Kubernetes中主要有两种实现模式,分别是HostNetwork模式和NodePort模式。
- HostNetwork模式:在每个节点上都创建一个ingress-controller的容器,该容器的网络模式设为hostNetwork。这意味着访问请求通过80/443端口将直接进入到pod中,然后ingress-controller根据ingress规则再将流量转发到对应的业务容器中。
- NodePort模式:访问流量先通过NodePort进入到节点,然后经iptables (svc) 转发至ingress-controller容器,再根据规则转发至后端各业务的容器中。
实现方案
Ingress的实现方案通常涉及到以下几个组件:
- Ingress资源:这是Kubernetes中的一个API对象,用于定义路由规则,将外部的HTTP/HTTPS请求路由到集群内部的服务。Ingress资源描述了哪些主机和路径应该路由到哪些服务,这是Ingress实现方案的基础。
- Ingress控制器:Ingress控制器是实际执行路由功能的组件。它需要解析Ingress资源中的规则,并设置相应的代理或负载均衡策略。当Ingress资源发生变化时,Ingress控制器需要动态地更新其配置,以保持与Ingress资源的同步。
具体来说,实现Ingress的方案通常如下:
- 首先,需要部署一个Ingress控制器,例如Nginx、Traefik等。这个控制器会运行在Kubernetes集群中,并监听Ingress资源的变化。
- 接下来,创建Ingress资源,定义路由规则。例如,可以定义一个规则,将所有以example.com为域名的请求路由到名为my-service的服务。
- Ingress控制器会解析这个Ingress资源,并根据定义的规则设置代理或负载均衡。例如,如果Ingress资源指定了使用轮询策略进行负载均衡,那么Ingress控制器就会配置其代理组件以轮询方式将请求发送到后端服务。
- 当外部请求到达Ingress控制器时,它会根据定义的规则将请求转发到相应的服务。这样,就可以通过简单的配置实现复杂的路由和负载均衡策略。
需要注意的是,Ingress的实现方案可能会因所选的Ingress控制器而有所不同。不同的Ingress控制器可能支持不同的功能、性能和扩展性。因此,在选择Ingress控制器时,需要根据实际需求进行评估和选择。
Nginx类型Ingress实现
Nginx类型的Ingress实现是通过Nginx Ingress Controller来完成的。Nginx Ingress Controller是一个符合Kubernetes Ingress规范的实现,它使用Nginx作为反向代理来实现Ingress的功能。具体实现过程如下:
- 安装Nginx Ingress Controller:首先需要安装Nginx Ingress Controller。可以通过Kubernetes的官方 Helm chart 或者其他方式进行安装。安装完成后,Nginx Ingress Controller会以Kubernetes Pod的形式运行在集群中。
-
创建Ingress资源:定义Ingress资源,描述路由规则。Ingress资源会包含一些字段,比如
host、path等,用于匹配并路由请求到对应的服务。例如,可以根据不同的主机名和路径将请求路由到不同的后端服务。 - Nginx Ingress Controller解析Ingress资源:Nginx Ingress Controller会监听Kubernetes API Server中的Ingress资源变化,并及时解析Ingress资源中的规则。
- 配置Nginx:根据解析得到的规则,Nginx Ingress Controller会动态生成Nginx配置文件,并更新Nginx的配置。这样,Nginx就可以根据配置文件的规则,将请求正确地代理到后端服务。当Ingress资源发生变化时,Nginx Ingress Controller会相应地更新Nginx的配置,以保持与实际路由规则的一致。
- 请求路由:一旦Nginx的配置更新完成,外部的请求到达Nginx时,就会根据配置文件中的规则被路由到正确的后端服务。这样,通过Nginx Ingress Controller和Nginx的配合,就实现了Ingress的路由功能。
需要注意的是,Nginx类型的Ingress实现可以通过扩展Nginx Ingress Controller来实现更多的功能,比如认证、限流、重定向等。同时,也可以根据实际需求调整Nginx的配置参数,以满足特定的性能和安全要求。
Treafik类型Ingress实现
Treafik类型的Ingress实现是通过Traefik Ingress Controller来完成的。Traefik是一个现代的HTTP反向代理和负载均衡器,可以很好地与Kubernetes集成,并实现Ingress的功能。具体实现过程如下:
- 安装Traefik Ingress Controller:首先需要在Kubernetes集群中安装Traefik Ingress Controller。可以通过Kubernetes的官方Helm chart或其他方式进行安装。安装完成后,Traefik会以Kubernetes Pod的形式运行在集群中。
- 配置Traefik:根据实际需求配置Traefik。Traefik支持通过配置文件、环境变量或Kubernetes自定义资源等方式进行配置。可以配置一些参数,比如监听端口、访问日志、SSL证书等。
-
创建Ingress资源:定义Ingress资源,描述路由规则。Ingress资源会包含一些字段,比如
host、path等,用于匹配并路由请求到对应的服务。 - Traefik解析Ingress资源:Traefik会监听Kubernetes API Server中的Ingress资源变化,并及时解析Ingress资源中的规则。它会自动发现Kubernetes服务,并根据Ingress资源的定义生成相应的路由配置。
- 请求路由:一旦Traefik的配置和路由规则生成完成,外部的请求到达Traefik时,就会根据配置的规则被路由到正确的后端服务。Traefik会根据请求的主机名、路径等信息匹配Ingress资源中的规则,并将请求代理到相应的服务。
- 扩展功能:Traefik还支持许多扩展功能,比如自动SSL证书管理(通过Let’s Encrypt等)、认证和授权、限流、重定向等。可以根据实际需求启用和配置这些功能。
需要注意的是,Traefik类型的Ingress实现可以通过自定义中间件来扩展功能。中间件是在请求到达后端服务之前或之后执行的插件,可以实现各种功能,比如请求头修改、请求体转换等。
总结来说,通过Traefik Ingress Controller和Traefik的配合,可以实现灵活且功能丰富的Ingress路由方案。
HAProxy类型ingress实现
HAProxy类型的Ingress实现是通过HAProxy Ingress Controller来完成的。HAProxy是一个高性能的负载均衡器和反向代理服务器,可以作为Ingress控制器来实现Ingress的功能。具体实现过程如下:
- 安装HAProxy Ingress Controller:首先需要在Kubernetes集群中安装HAProxy Ingress Controller。可以通过Kubernetes的官方Helm chart或其他方式进行安装。安装完成后,HAProxy Ingress Controller会以Kubernetes Pod的形式运行在集群中。
- 配置HAProxy:根据实际需求配置HAProxy。HAProxy支持通过配置文件、环境变量或Kubernetes自定义资源等方式进行配置。可以配置一些参数,比如监听端口、会话保持、SSL证书等。
-
创建Ingress资源:定义Ingress资源,描述路由规则。Ingress资源会包含一些字段,比如
host、path等,用于匹配并路由请求到对应的服务。 - HAProxy解析Ingress资源:HAProxy Ingress Controller会监听Kubernetes API Server中的Ingress资源变化,并及时解析Ingress资源中的规则。它会自动发现Kubernetes服务,并根据Ingress资源的定义生成相应的路由配置。
- 请求路由:一旦HAProxy的配置和路由规则生成完成,外部的请求到达HAProxy时,就会根据配置的规则被路由到正确的后端服务。HAProxy会根据请求的主机名、路径等信息匹配Ingress资源中的规则,并将请求代理到相应的服务。
- 扩展功能:HAProxy还支持许多扩展功能,比如自动SSL证书管理(通过Let’s Encrypt等)、会话保持、重定向等。可以根据实际需求启用和配置这些功能。
需要注意的是,HAProxy类型的Ingress实现也可以通过自定义中间件来扩展功能。中间件是在请求到达后端服务之前或之后执行的插件,可以实现各种功能,比如请求头修改、请求体转换等。
总结来说,通过HAProxy Ingress Controller和HAProxy的配合,可以实现高性能、可扩展且功能丰富的Ingress路由方案。
Istio类型ingress实现
Istio类型的Ingress实现是通过Istio Ingress Controller来完成的。Istio是一个服务网格平台,提供了强大的流量管理和安全功能。它提供了与Kubernetes集成的Ingress功能,可以轻松地实现复杂的路由和负载均衡策略。具体实现过程如下:
- 安装Istio:首先需要在Kubernetes集群中安装Istio。可以通过Kubernetes的官方Helm chart或其他方式进行安装。安装完成后,Istio会以Kubernetes Pod的形式运行在集群中,并自动发现Kubernetes服务。
-
创建Ingress资源:定义Ingress资源,描述路由规则。Ingress资源会包含一些字段,比如
host、path等,用于匹配并路由请求到对应的服务。Istio支持多种类型的Ingress,包括v1alpha1和 networking.gRPC API。 - Istio解析Ingress资源:Istio Ingress Controller会监听Kubernetes API Server中的Ingress资源变化,并及时解析Ingress资源中的规则。它会自动发现Kubernetes服务,并根据Ingress资源的定义生成相应的路由配置。
- 配置Istio Ingress Controller:通过配置文件或Kubernetes自定义资源等方式配置Istio Ingress Controller。可以配置一些参数,比如监听端口、SSL证书等。在Istio中,Ingress Controller与Egress Controller协同工作,实现了强大的流量管理和安全功能。
- 请求路由:一旦Istio的配置和路由规则生成完成,外部的请求到达Istio时,就会根据配置的规则被路由到正确的后端服务。Istio会根据请求的主机名、路径等信息匹配Ingress资源中的规则,并将请求代理到相应的服务。它还提供了许多扩展功能,比如认证、限流、重定向等。可以根据实际需求启用和配置这些功能。
需要注意的是,Istio类型的Ingress实现具有强大的流量管理和安全功能,但也需要更多的配置和维护工作。在使用Istio时,需要仔细考虑其性能和可扩展性方面的影响,并根据实际需求进行配置和优化。
APISIX类型ingress实现
APISIX是阿里巴巴开源的一个高性能、可扩展的API网关,它提供了Ingress功能,可以作为Kubernetes集群的Ingress Controller。以下是APISIX类型Ingress的实现过程:
- 安装APISIX:在Kubernetes集群中安装APISIX。可以通过Kubernetes的官方Helm chart或其他方式进行安装。安装完成后,APISIX会以Kubernetes Pod的形式运行在集群中。
- 配置APISIX:根据实际需求配置APISIX。可以配置一些参数,比如监听端口、访问日志、SSL证书等。APISIX提供了丰富的配置项和插件机制,可以灵活地满足不同的需求。
-
创建Ingress资源:定义Ingress资源,描述路由规则。Ingress资源会包含一些字段,比如
host、path等,用于匹配并路由请求到对应的服务。 - APISIX解析Ingress资源:APISIX会监听Kubernetes API Server中的Ingress资源变化,并及时解析Ingress资源中的规则。它会自动发现Kubernetes服务,并根据Ingress资源的定义生成相应的路由配置。
- 请求路由:一旦APISIX的配置和路由规则生成完成,外部的请求到达APISIX时,就会根据配置的规则被路由到正确的后端服务。APISIX会根据请求的主机名、路径等信息匹配Ingress资源中的规则,并将请求代理到相应的服务。它支持多种协议和负载均衡算法,可以根据实际需求进行配置。
- 扩展功能:APISIX还支持许多扩展功能,比如自动SSL证书管理(通过Let’s Encrypt等)、认证和授权、限流、重定向等。可以根据实际需求启用和配置这些功能。
需要注意的是,使用APISIX作为Ingress Controller时,需要考虑到性能和可扩展性方面的影响。APISIX具有很高的性能和可扩展性,但也需要根据实际需求进行配置和优化。同时,需要仔细考虑与Kubernetes的集成和自动化部署等方面的问题。
更多
原文地址:https://blog.csdn.net/zhangzehai2234/article/details/134616667
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。