
实验内容主要包括:
(1)安装kubernetes集群环境,并安装部署dashboard,以可视化方式管理集群中的pod、service、delpoyment。
(2)将基于微服务架构的Online Boutique应用部署在上述kubernetes环境中。
(3)针对Online Boutique在熔断、限流、监控、认证、授权、安全、负载等方面的不足,将其升级到服务网格架构,为微服务启用Istio支持。
(4)*在kubernetes中为Istio配置Kiali,实现Istio服务网格的可视化,为Online Boutique项目提供服务拓扑图、全链路跟踪、指标遥测、配置校验、健康检查等功能。
(5)*在kubernetes中为 Istio 配置 Jaeger,为 Online Boutique 项目提供分布式调用链追踪系统,用于监控和排查基于微服务的分布式系统问题。
(6)*在 Kubernetes 中安装和配置Prometheus、Grafana,完成整个集群、工作负载在使用Locust压力负载的情况下的运行情况、健康状态监控。
(7)总结和整理以上各项技术平台的底层实现机制,以及在 Online Boutique 项目中的配置和使用步骤。
目 录
配置kiali、jaeger、prometheus、grafana
1 概述
1.1 选题背景与实验目的
研究基于云原生微服务架构的 web商城应用Online Boutique,部署在kubernetes环境中,并进行深入的研究实验的实验目的是了解云计算的业务模型、部署模型和服务模式,掌握基本的云计算核心技术,并熟悉当前主流的公有云平台并使用其中的云主机、云数据库、对象存储服务、弹性伸缩服务、负载均衡策略等主要产品;培养学生根据应用上云的不同实际需求,选择合适平台、工具,提出相应的云平台解决方案,开发适合于分布式环境的应用,并将应用部署于云平台生产环境的能力;了解公有云平台的优势和不足,基于资源节约、数据安全、环境可持续发展的原则,具备理解与评价应用是否适合上云的能力;在使用云计算平台和技术的小组实验过程中,学会分析问题、独立思考、总结经验、表达观点,相互协作,培养有效沟通并共同解决问题的能力;关注云计算领域最新热点问题,持续跟踪DevOps、云原生等前沿技术发展趋势,具备持续集成、持续交付、持续部署的能力。
1.2 实验内容
(1)安装kubernetes集群环境,并安装部署dashboard,以可视化方式管理集群中的pod、service、delpoyment。其中安装kubernetes集群的方式有多种,包括二进制安装方式,kubeadm安装方式,还有minukube、kubesphere等各种
安装方式,可以任选其中之一。安装完成之后,应该可以看到如下类似管理界面。
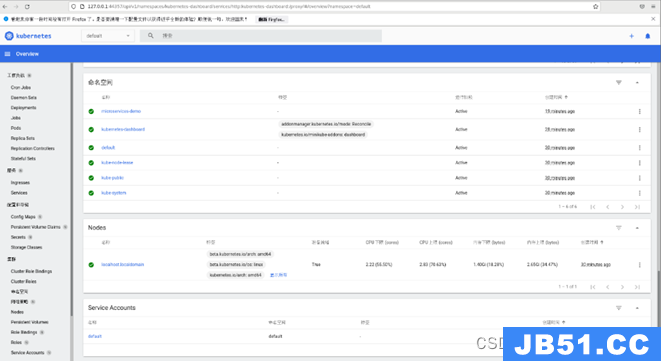
图1.2.1 kubernetes dashboard界面
(2)将基于微服务架构的Online Boutique应用部署在上述kubernetes环境中。部署成功之后,应能访问到该应用的首页,如下图所示。

图1.2.2 Online Boutique 应用部署验证
(3)针对Online Boutique在熔断、限流、监控、认证、授权、安全、负载等方面的不足,将其升级到服务网格架构,为微服务启用Istio支持。支持服务拓扑发现、全链路跟踪、指标遥测、健康检查等,实现服务治理。

图1.2.3 启用Istio支持的Online Boutique服务治理架构
(4)*在kubernetes中为Istio配置Kiali,实现Istio服务网格的可视化,为Online Boutique项目提供服务拓扑图、全链路跟踪、指标遥测、配置校验、健康检查等功能。

图1.2.4 安装kiali插件实现服务网格可视化

图1.2.5 安装kiali插件实现链路跟踪
(5)*在kubernetes中为 Istio 配置 Jaeger,为 Online Boutique 项目提供分布式调用链追踪系统,用于监控和排查基于微服务的分布式系统问题,包括:分布式上下文传播、分布式事务监控、根因分析、服务依赖关系分析、性能 / 延迟优化等任务。

图1.2.6 安装Jaeger插件实现链路跟踪与监控
(6)*在 Kubernetes 中安装和配置Prometheus、Grafana,完成整个集群、工作负载在使用Locust压力负载的情况下的运行情况、健康状态监控。

图1.2.7 安装Prometheus和Grafana实现日志与健康状态监控
(7)*在 Online Boutique 项目中,将其中至少一个非 Java 实现的微服务,改写成SpringBoot的微服务,完成整体新项目Kubernetes中的部署,重新使用步骤2-6中的组件,完成调试、分析和管理。
(8)总结和整理以上各项技术平台的底层实现机制,以及在 Online Boutique 项目中的配置和使用步骤。
2 实验一
2.1实验说明
安装kubernetes集群环境,并安装部署dashboard,以可视化方式管理集群中的pod、service、delpoyment。其中安装kubernetes集群的方式有多种,包括二进制安装方式,kubeadm安装方式,还有minukube、kubesphere等各种
安装方式,可以任选其中之一。安装完成之后,应该可以看到如下类似管理界面。
图2.1.1 kubernetes dashboard界面
2.2实验步骤
安装k8s集群
(1)准备华为云HECS服务器两台,分别作为k8s-master和k8s-node-1。其中k8s-master云服务器配置如图2.2.1所示,k8s-node-1云服务器配置如图2.2.2所示。并使其处于同一安全组中,即互相可以ping通内网IP,设置相应的出入方向规则。
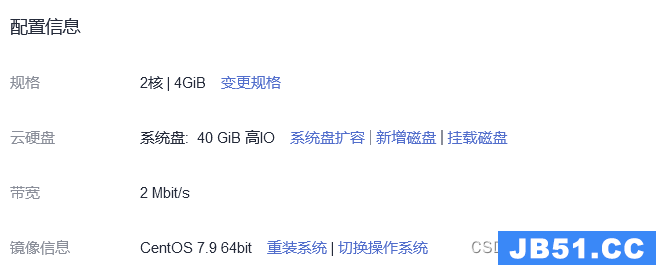
图2.2.1 k8s-master配置信息
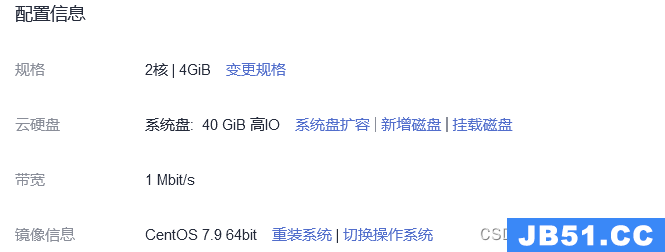
图2.2.2 k8s-node-1配置信息
或者也可以准备相同或更高配置的虚拟机两台,为其配置静态IP。配置静态IP步骤如下:
i)打开网卡配置文件
vi /etc/sysconfig/network-scripts/ifcfg-ens33
图2.2.3 虚拟机网卡配置文件
ii)修改网卡配置文件
如果ONBOOT字段为no,需要将其改为yes。该字段表示该网卡是否开机自启。
将BOOTPROTO字段修改为static(静态模式),即使用静态的IP地址。所以接下来我们需要设置静态IP地址的相关信息,诸如:网关、子网掩码等信息
iii)查看虚拟机中该网卡的子网IP
在配置文件中配置的静态IP地址,并不是随意填写的。需要根据该网卡所分配到的子网IP地址所处的网段进行配置。
在vmware虚拟机管理软件中通过“编辑”按钮打开“虚拟网络编辑器”。
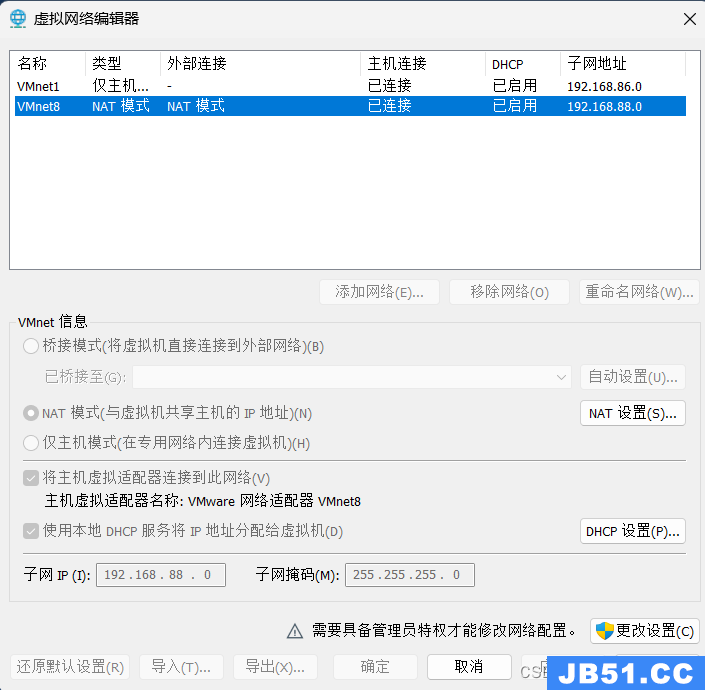
图2.2.4 虚拟网络编辑器
该网卡使用的是NAT模式,即与虚拟机共享主机IP地址。点击“NAT设置”按钮,查看该虚拟机的网络配置。

图2.2.5 NAT设置
通过显示的配置文件,编辑网卡的配置信息。

图2.2.6 网卡配置
其中,IPADDR字段表示该网卡的IP地址,只要与子网IP处于同一个网段即可。可以处于192.168.141.0~192.168.141.255,此处设置为201并无特殊含义。NETMASK表示子网掩码,GATEWAY表示网关,均只需根据虚拟机的网络配置即可。DNS表示域名解析器地址,可以设置多个,常用的地址如下:

图2.2.7 域名解析器地址
iv)重启网卡
通过如下命令重启网卡:
systemctl restart network(2)确定环境与安装版本如下:
Docker 20.10.14
Kubeadm-1.23.5-0
Kubelet-1.23.5-0
Kubectl-1.23.5-0
以下步骤两台机器都需要执行:
(3)更新并安装依赖
yum -y update
yum install -y conntrack ipvsadm ipset jq sysstat curl iptables libseccomp(4)安装Docker
- 在每一台机器上都安装好Docker,版本为20.10.14
sudo yum install -y yum-utils \
device-mapper-persistent-data \
lvm2- 设置repo
sudo yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo- 设置国内镜像并重启daemon
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://j16wttpi.mirror.aliyuncs.com"]
}
EOF
wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -O /etc/yum.repos.d/docker-ce.repo- 进行安装命令
yum install -y docker-ce-20.10.14 docker-ce-cli-20.10.14 containerd.io- 设置docker自动重启
sudo systemctl start docker && sudo systemctl enable docker- 查看是否成功
docker info(5)修改hosts文件
- 分别设置master和node-1的hostname
sudo hostnamectl set-hostname k8s-master
sudo hostnamectl set-hostname k8s-node-1- 修改hosts文件
vi /etc/hosts
192.168.0.188 k8s-master
192.168.0.197 k8s-node-1- 使用ping测试一下(确保两台机器直接可以互相ping通)
(6)系统前提配置
- 关闭防火墙
systemctl stop firewalld && systemctl disable firewalld- 关闭selinux
setenforce 0
sed -i 's/^SELINUX=enforcing$/SELINUX=permissive/' /etc/selinux/config- 关闭swap
swapoff -a
sed -i '/swap/s/^\(.*\)$/#\1/g' /etc/fstab- 配置iptables的ACCEPT规则
iptables -F && iptables -X && iptables -F -t nat && iptables -X -t nat && iptables -P FORWARD ACCEPT- 设置系统参数
cat <<EOF > /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sysctl --system(7)安装kubeadm、kubelet、kubectl
- 配置yum源
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg
http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF- 安装kubeadm kubelet kubectl
yum list kubeadm --showduplicates | sort -r
yum install -y kubeadm-1.23.5-0 kubelet-1.23.5-0 kubectl-1.23.5-0- docker和k8s设置同一个cgroup
cat <<EOF > /etc/docker/daemon.json
{
"registry-mirrors": ["https://j16wttpi.mirror.aliyuncs.com"],"exec-opts": ["native.cgroupdriver=systemd"]
}
EOF
systemctl restart docker- kubelet配置
若输出directory not exist,也是没有问题的,可以继续往下进行
sed -i "s/cgroup-driver=systemd/cgroup-driver=cgroupfs/g" /etc/systemd/system/kubelet.service.d/10-kubeadm.conf
systemctl enable kubelet && systemctl start kubelet(8)proxy/pause/scheduler等国内镜像
- 查看kubeadm使用的镜像
kubeadm config images list可以发现这里都是国外的镜像
- 解决国外镜像不能访问的问题,执行kubeadm-v1.23.sh脚本,用于拉取镜像/打tag/删除原有镜像
wget -O kubeadm-v1.23.sh https://files.rundreams.net/sh/kubeadm-v1.23.sh && sh kubeadm-v1.23.sh- 查看镜像
docker images以下操作只需要在master节点上进行
(9)kube init初始化master
- kube初始化流程
01-进行一系列检查,以确定这台机器可以部署kubernetes
02-生成kubernetes对外提供服务所需要的各种证书可对应目录
/etc/kubernetes/pki/*
03-为其他组件生成访问kube-ApiServer所需的配置文件
ls /etc/kubernetes/
admin.conf controller-manager.conf kubelet.conf scheduler.conf
04-为 Master组件生成Pod配置文件。
ls /etc/kubernetes/manifests/*.yaml
kube-apiserver.yaml
kube-controller-manager.yaml
kube-scheduler.yaml
05-生成etcd的Pod YAML文件。
ls /etc/kubernetes/manifests/*.yaml
kube-apiserver.yaml
kube-controller-manager.yaml
kube-scheduler.yaml
etcd.yaml
06-一旦这些 YAML 文件出现在被 kubelet 监视的/etc/kubernetes/manifests/目录下,kubelet就会自动创建这些yaml文件定义的pod,即master组件的容器。master容器启动后,kubeadm会通过检查localhost:6443/healthz这个master组件的健康状态检查URL,等待master组件完全运行起来
07-为集群生成一个bootstrap token
08-将ca.crt等 Master节点的重要信息,通过ConfigMap的方式保存在etcd中,工后续部署node节点使用
09-最后一步是安装默认插件,kubernetes默认kube-proxy和DNS两个插件是必须安装的
- 初始化master节点
kubeadm init --kubernetes-version=1.23.5 --apiserver-advertise-address=192.168.0.188 --image-repository registry.aliyuncs.com/google_containers --service-cidr=10.10.0.0/12 --pod-network-cidr=172.17.0.0/16 --ignore-preflight-errors=all若要重新初始化集群状态
kubeadm reset- 根据日志提示
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config- 保存好最后的kubeadm join信息
kubeadm join 192.168.0.188:6443 --token 3o4wrj.zwrpmnszo36razm3 \
--discovery-token-ca-cert-hash sha256:52cbe2686b09e8c0b4325203f93879b1d01b253a7f44505832eb1d5662725d29- 查看pod验证一下
kubectl get pods -n kube-system- 健康检查
curl -k https://localhost:6443/healthz(10)部署calico网络插件
- 在k8s中安装calico
kubectl apply -f https://docs.projectcalico.org/v3.22/manifests/calico.yaml- 确认一下calico是否安装成功
kubectl get pods --all-namespaces -w
kubectl get pods -n kube-system -w(11)kube join
- 在node-1节点上执行命令
kubeadm join 192.168.0.188:6443 --token 3o4wrj.zwrpmnszo36razm3 \
--discovery-token-ca-cert-hash sha256:52cbe2686b09e8c0b4325203f93879b1d01b253a7f44505832eb1d5662725d29- 在master节点上检查集群信息
kubectl get nodes如图:

图2.2.8 在master节点上检查集群信息
安装部署dashboard
(1)在master节点执行
wget https://raw.githubusercontent.com/kubernetes/dashboard/v2.5.1/aio/deploy/recommended.yaml
# 创建 pod
kubectl apply -f recommended.yaml这里k8s是v1.23.5,对应dashboard是v2.5.1版本
k8s和dashboard版本对应可以参考
https://github.com/kubernetes/dashboard/releases
(2)查看,成功创建
[root@k8s-master dashboard]# kubectl get pods --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system calico-kube-controllers-5bb5d4f7f4-hl9nv 1/1 Running 0 19h
kube-system calico-node-wkjtj 1/1 Running 0 19h
kube-system calico-node-xxkvd 1/1 Running 0 19h
kube-system coredns-6d8c4cb4d-l2wwf 1/1 Running 0 19h
kube-system coredns-6d8c4cb4d-p5c52 1/1 Running 0 19h
kube-system etcd-k8s-master 1/1 Running 3 19h
kube-system kube-apiserver-k8s-master 1/1 Running 5 19h
kube-system kube-controller-manager-k8s-master 1/1 Running 7 19h
kube-system kube-proxy-2pb6z 1/1 Running 0 19h
kube-system kube-proxy-tgh78 1/1 Running 0 19h
kube-system kube-scheduler-k8s-master 1/1 Running 8 19h
kubernetes-dashboard dashboard-metrics-scraper-5f6ccbd9c4-hpznl 1/1 Running 0 65s
kubernetes-dashboard kubernetes-dashboard-597bf6cb58-bxndl 1/1 Running 0 65s
(3)删除现有的dashboard服务,dashboard服务的namespace是kubernetes-dashboard,但是该服务的类型是ClusterIP,不便于我们通过浏览器访问,因此需要改成NodePort型
[root@k8s-master dashboard]# kubectl get svc --all-namespaces
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
default kubernetes ClusterIP 10.0.0.1 <none> 443/TCP 19h
kube-system kube-dns ClusterIP 10.0.0.10 <none> 53/UDP,53/TCP,9153/TCP 19h
kubernetes-dashboard dashboard-metrics-scraper ClusterIP 10.6.172.215 <none> 8000/TCP 2m2s
kubernetes-dashboard kubernetes-dashboard ClusterIP 10.1.104.107 <none> 443/TCP 2m2s
# 删除
kubectl delete service kubernetes-dashboard --namespace=kubernetes-dashboard
(4)创建配置文件
vim dashboard-svc.yaml
# 内容
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
spec:
type: NodePort
ports:
- port: 443
targetPort: 8443
nodePort: 30000
selector:
k8s-app: kubernetes-dashboard
# 执行
kubectl apply -f dashboard-svc.yaml
(5)再次查看服务,成功
[root@k8s-master dashboard]# kubectl get svc --all-namespaces
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
default kubernetes ClusterIP 10.0.0.1 <none> 443/TCP 19h
kube-system kube-dns ClusterIP 10.0.0.10 <none> 53/UDP,9153/TCP 19h
kubernetes-dashboard dashboard-metrics-scraper ClusterIP 10.6.172.215 <none> 8000/TCP 5m5s
kubernetes-dashboard kubernetes-dashboard NodePort 10.11.228.230 <none> 443:30442/TCP 16s
(6)想要访问dashboard服务,就要有访问权限,创建kubernetes-dashboard管理员角色
vim dashboard-svc-account.yaml
# 结果
apiVersion: v1
kind: ServiceAccount
metadata:
name: dashboard-admin
namespace: kube-system
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: dashboard-admin
subjects:
- kind: ServiceAccount
name: dashboard-admin
namespace: kube-system
roleRef:
kind: ClusterRole
name: cluster-admin
apiGroup: rbac.authorization.k8s.io
# 执行
kubectl apply -f dashboard-svc-account.yaml
(7)获取token
[root@k8s-master dashboard]# kubectl get secret -n kube-system |grep admin|awk '{print $1}'
dashboard-admin-token-78r8q
[root@k8s-master dashboard]# kubectl describe secret dashboard-admin-token-78r8q -n kube-system|grep '^token'|awk '{print $2}'
eyJhbGciOiJSUzI1NiIsImtpZCI6IkVjamxXOWVzamlrbnVKSG93QUo5MkJaRW1IYzVpNWhGOU05WHU3d2Nqc1EifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlLXN5c3RlbSIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJkYXNoYm9hcmQtYWRtaW4tdG9rZW4tNzhyOHEiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoiZGFzaGJvYXJkLWFkbWluIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQudWlkIjoiY2UwYjFjYTItNzVkZS00ODBmLWJhZWMtNmE2ODBhZGNiYmMwIiwic3ViIjoic3lzdGVtOnNlcnZpY2VhY2NvdW50Omt1YmUtc3lzdGVtOmRhc2hib2FyZC1hZG1pbiJ9.YFEm2luL8PqnBMZqIx9CA0rM2-kJEgR8NtxFBq5Qq4XIF_nIeSJiztlKJiaGRoqjjwRtFBJ8fsmmGdo0hxtjL_eBBS1I4rc8OxHNO71A-ciD6O59C5K0Q4MsMm83gtTHcQb0AQrPyf3XA7fyPu5ro1fYNPGYjoYwnNu4V3qJmN-NU4gqvZLNjJltNMxXwBXS8KFumQIW24I7vxOfgtFixsVwCgp4Rp62263yIJrTvwlwqJQetoj14dct72eTdLGoUsdsXWWq6DkEGnTHkuBZDvaRthP6vOSzl3ImhB7wfo0G__ZUAaZyBQX1rJ7C12m4wwoW92FeXn23DHW2wWPgFA
(8)访问
公网:
https://123.60.30.244:30000
虚拟机:
http://192.168.88.200:30000
把上面的token粘贴到令牌
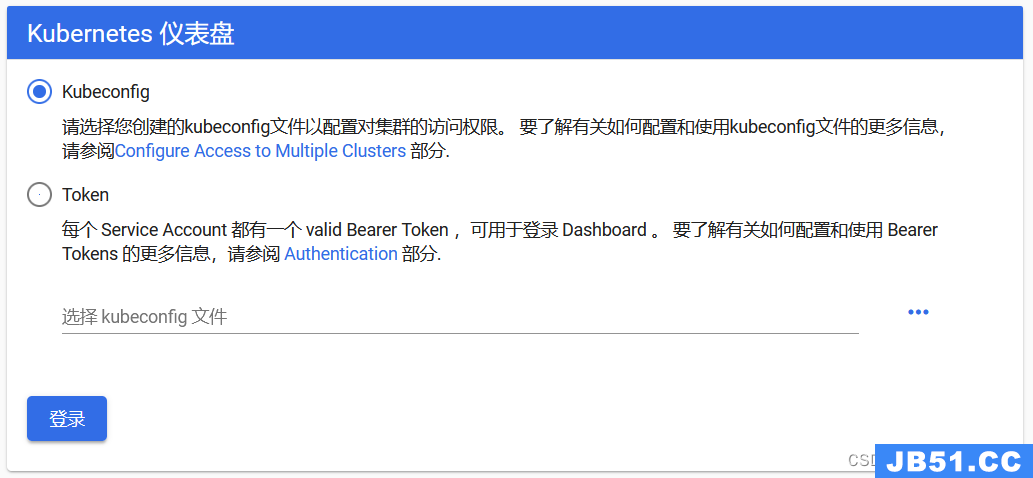
图2.2.9 Kubernetes仪表盘

图2.2.10 kubernetes dashboard界面
2.3注意事项
- 注意操作系统、Docker、kubeadm、kubelet、kubectl等的版本问题,这里采用CentOS7.9、Docker20.10.14、kubeadm-1.23.5-0、kubelet-1.23.5-0、kubectl-1.23.5-0。从 k8s-1.24开始,dockershim已经从kubelet中移除,但因为历史问题docker却不支Kubernetes 主推的CRI(容器运行时接口)标准,所以docker不能再作为k8s的容器运行时了,即从k8sv1.24开始不再使用docker了。如果想继续使用docker的话,可以在kubelet和docker之间加上一个中间层cri-docker。
- k8s在master节点上初始化时需要加上一个参数“--ignore-preflight-errors=all”,忽略检查的一些错误。
- 根据recommended.yaml配置文件创建的dashboard容器和服务后不能直接访问。Dashboard服务的namespace是kubernetes-dashboard,但是该服务的类型是ClusterIP,不便于我们通过浏览器访问,因此需要改成NodePort型。且访问的协议为https而不是http。
2.4实现机制
Kubernetes简称 k8s,是支持云原生部署的一个平台,起源于谷歌。谷歌早在十几年之前就对其应用,通过容器方式进行部署。k8s 本质上就是用来简化微服务的开发和部署的,关注点包括自愈和自动伸缩、调度和发布、调用链监控、配置管理、Metrics 监控、日志监控、弹性和容错、API 管理、服务安全等,k8s 将这些微服务的公共关注点以组件形式封装打包到 k8s 这个大平台中,让开发人员在开发微服务时专注于业务逻辑的实现,而不需要去特别关系微服务底层的这些公共关注点,大大简化了微服务应用的开发和部署,提高了开发效率。
k8s总体架构采用了经典的master slave架构模式,分master节点和 worker节点,节点可以是虚拟机也可以是物理机。
master 节点由以下组件组成:
- etcd,一种的分布式存储机制,底层采用 Raft 协议,k8s 集群的状态数据包括配置、节点等都存储于 etcd 中,它保存了整个集群的状态。
- API server,对外提供操作和获取 k8s 集群资源的的 API,是唯一操作 etcd 的组件,其他的组件包括管理员操作都是通过 API server 进行交互的,可以将它理解成 etcd 的 “代理人”。
- Scheduler,在 k8s 集群中做调动决策,负责资源的调度,按照预定的调度策略将 Pod 调度到相应的机器上。
- Controller Manager,相当于集群状态的协调者,观察着集群的实际状态,与 etcd 中的预期状态进行对比,如果不一致则对资源进行协调操作让实际状态和预期状态达到最终的一致,维护集群的状态,比如故障检测、自动扩展、滚动更新等。
worker 节点由以下组件组成:
- Controller Runtime,下载镜像和运行容器的组件,负责镜像管理以及 Pod 和容器的真正运行(CRI)。
- Pod,k8s 中特有的一个概念,可以理解为对容器的包装,是 k8s 的基本调度单位,实际的容器时运行在 Pod 中的,一个节点可以启动一个或多个 Pod。
- kubelet,负责管理 worker 节点上的组件,与 master 节点上的 API server 节点进行交互,接受指令执行操作。
- kube-proxy,负责对 Pod 进行寻址和负载均衡
用户操作 k8s 集群一般是通过 kubectl 命令行工具或者 dashboard;Pod 之间进行通讯是通过集群内部的覆盖网络 Overlay Network,外部流量想要进入集群访问 Pod 则是通过负载均衡 Load Balander 设备进行。
k8s中的一些核心概念:
- 集群 Cluster:集群有多个节点组成且可以按需添加节点(物理机/虚拟机),每一个节点都包含一定数量的CPU和内存RAM。
- 容器Container:k8s本身是一个容器调度平台,从宿主机操作系统来看,容器就是一个一个的进程。从容器内部来看容器就是一个操作系统,它有着自己的网络、CPU、文件系统等资源。
- POD:k8s也不是直接调度容器的,而是将其封装成了一个个POD,POD才是k8s的基本调度单位。每个POD中可以运行一个或多个容器,共享POD 的文件系统、IP和网络等资源,每一个POD只有一个IP。
- 副本集ReplicaSet:一个应用发布时会发布多个POD实例,副本集可对应一个应用的一组POD,它可以通过模板来规范某个应用的容器镜像、端口,副本数量等。运行时副本集会监控和维护POD的数量,数量过多则会下线 POD,过少则启动POD。
- 服务service:POD在k8s中是不固定的,可能会挂起或者重启,且挂起重启都是不可预期的,那么这就会导致服务的IP也随着不停的变化,给用户的寻址造成一定的困难。而service就是用来解决这个问题的,它屏蔽了应用的IP寻址和负载均衡,消费方可直接通过服务名来访问目标服务,寻址和负载均衡均由service底层进行。
- 发布Deployment:副本集就是一种基本的发布机制,可以实现基本的或者高级的应用发布,但操作较为繁琐。为了简化这些操作,k8s引入了Deployment来管理ReplicaSet,实现一些高级发布机制。
- ConfigMap/Secret:微服务在上线时需要设置一些可变配置,环境不同则配置值不同,有些配置如数据库的连接字符串在启动时就应该配好,有些配置则可以在运行中动态调整。为了实现针对不同环境灵活实现动态配置,微服务就需要ConfigMap的支持。k8s平台内置支持微服务的配置(ConfigMap),开发人员将配置填写在ConfigMap中,k8s再 将ConfigMap中的配置以环境变量的形式注入POD,这样POD中的应用就可以访问这些配置。Secret是一种特殊的ConfigMap,提供更加安全的存储和访问配置机制。
- DaemonSet:在微服务中,每个节点需要配置一个常驻守护进程。DaemonSet 可支持在每一个worker节点上面配置一个守护进程POD并且保证每一个节点上有且仅有一个POD。
k8s工作流程:运维人员向kube-apiserver发出指令(我想干什么,我期望
事情是什么状态)。api响应命令,通过一系列认证授权,把pod数据存储到etcd,创建deployment资源并初始化。(期望状态)controller通过list-watch机制,监测发现新的deployment,将该资源加入到内部工作队列,发现该资源没有关联的pod和replicaset,启用deployment controller创建replicaset资源,再启用replicaset controller创建pod。所有controller被创建完成后.将deployment,replicaset,pod资源更新存储到etcd。scheduler通过list-watch机制,监测发现新的pod,经过主机过滤、主机打分规则,将pod绑定(binding)到合适的主机。将绑定结果存储到etcd。kubelet每隔 20s(可以自定义)向apiserver通过NodeName获取自身Node上所要运行的pod清单.通过与自己的内部缓存进行比较,新增加pod。kubelet创建pod。kube-proxy为新创建的pod注册动态DNS到CoreOS。给pod的service添加iptables/ipvs规则,用于服务发现和负载均衡。controller通过control loop(控制循环)将当前pod状态与用户所期望的状态做对比,如果当前状态与用户期望状态不同,则controller会将pod修改为用户期望状态,实在不行会将此pod删掉,然后重新创建pod。
3实验二、三
3.1实验说明
将基于微服务架构的Online Boutique应用部署在上述kubernetes环境中。部署成功之后,应能访问到该应用的首页,如下图所示。
图3.1.1 Online Boutique 应用部署验证
针对Online Boutique在熔断、限流、监控、认证、授权、安全、负载等方面的不足,将其升级到服务网格架构,为微服务启用Istio支持。支持服务拓扑发现、全链路跟踪、指标遥测、健康检查等,实现服务治理。
图3.1.2 启用Istio支持的Online Boutique服务治理架构
3.2实验步骤
安装Istio
(1)下载 GetMesh CLI。我们可以使用以下命令下载最新版本的 GetMesh 并认证 Istio。
#安装getmesh[root@k8s-master ~]# curl -sL https://istio.tetratelabs.io/getmesh/install.sh | bash
tetratelabs/getmesh info checking GitHub for latest tag
tetratelabs/getmesh info found version: 1.1.4 for v1.1.4/linux/amd64
tetratelabs/getmesh info installed /root/.getmesh/bin/getmesh
tetratelabs/getmesh info updating user profile (/root/.bash_profile)...
tetratelabs/getmesh info the following two lines are added into your profile (/root/.bash_profile):
export GETMESH_HOME="$HOME/.getmesh"
export PATH="$GETMESH_HOME/bin:$PATH"
Finished installation. Open a new terminal to start using getmesh!
(2)修改配置文件使所有人都可以使用getmesh命令
[root@k8s-master ~]# cd .getmesh/
[root@k8s-master .getmesh]# pwd
/root/.getmesh
[root@k8s-master .getmesh]# vim /etc/profile.d/getmesh.sh
[root@k8s-master .getmesh]# cat /etc/profile.d/getmesh.sh
export GETMESH_HOME="/root/.getmesh"
export PATH="$GETMESH_HOME/bin:$PATH"
#使配置文件生效
[root@k8s-master .getmesh]# source /etc/profile.d/getmesh.sh
(3)运行version命令以确保GetMesh被成功安装。版本命令输出GetMesh的版本、活跃的Istio CLI的版本以及Kubernetes集群上安装的Istio的版本。
getmesh version
(4)使用GetMesh安装Istio。该命令将检查集群,以确保它准备好安装Istio,一旦确认,安装程序将继续使用选定的配置文件安装Istio。
getmesh istioctl install --set profile=demo
部署Online Boutique应用
(1)Istio安装完成后,创建一个命名空间online-boutique,新的项目就部署在online-boutique命名空间下,给命名空间online-boutique设置上istio-injection=enabled 标签,启用sidecar 自动注入。
#创建命名空间online-boutique
kubectl create ns online-boutique
#切换命名空间
kubectl config set-context $(kubectl config current-context) --namespace= online-boutique
#让命名空间online-boutique启用sidecar 自动注入
kubectl label ns online-boutique istio-injection=enabled
[root@k8s-master ~]# kubectl get ns -l istio-injection --show-labels
NAME STATUS AGE LABELS
online-boutique Active 16m istio-injection=enabled,kubernetes.io/metadata.name=online-boutique
(2)在集群和Istio准备好后,我们可以克隆Online Boutique应用库了。使用git克隆代码仓库
#安装git
yum -y install git
#查看git版本
git version
#创建并进入online-boutique目录,项目放在该目录下
mkdir online-boutique
cd online-boutique/
#git克隆代码
[root@k8s-master online-boutique]# git clone https://github.com/GoogleCloudPlatform/microservices-demo.git
正克隆到 'microservices-demo'...
remote: Enumerating objects: 8195,done.
remote: Counting objects: 100% (332/332),done.
remote: Compressing objects: 100% (167/167),done.
remote: Total 8195 (delta 226),reused 241 (delta 161),pack-reused 7863
接收对象中: 100% (8195/8195),30.55 MiB | 154.00 KiB/s,done.
处理 delta 中: 100% (5823/5823),done.
[root@k8s-master online-boutique]# ls
microservices-demo
(3)前往microservices-demo目录,istio-manifests.yaml、kubernetes-manifests.yaml是主要的安装文件
[root@k8s-master online-boutique]# cd microservices-demo/
[root@k8s-master microservices-demo]# ls
cloudbuild.yaml CODEOWNERS docs istio-manifests kustomize pb release SECURITY.md src
CODE_OF_CONDUCT.md CONTRIBUTING.md hack kubernetes-manifests LICENSE README.md renovate.json skaffold.yaml terraform
[root@k8s-master microservices-demo]# cd release/
[root@k8s-master release]# ls
istio-manifests.yaml kubernetes-manifests.yaml
(4)查看所需的镜像
[root@k8s-master release]# vim kubernetes-manifests.yaml
#可以看到安装此项目需要13个镜像,gcr.io表示是Google的镜像
[root@k8s-master release]# grep image kubernetes-manifests.yaml
image: gcr.io/google-samples/microservices-demo/emailservice:v0.4.0
image: gcr.io/google-samples/microservices-demo/checkoutservice:v0.4.0
image: gcr.io/google-samples/microservices-demo/recommendationservice:v0.4.0
image: gcr.io/google-samples/microservices-demo/frontend:v0.4.0
image: gcr.io/google-samples/microservices-demo/paymentservice:v0.4.0
image: gcr.io/google-samples/microservices-demo/productcatalogservice:v0.4.0
image: gcr.io/google-samples/microservices-demo/cartservice:v0.4.0
image: busybox:latest
image: gcr.io/google-samples/microservices-demo/loadgenerator:v0.4.0
image: gcr.io/google-samples/microservices-demo/currencyservice:v0.4.0
image: gcr.io/google-samples/microservices-demo/shippingservice:v0.4.0
image: redis:alpine
image: gcr.io/google-samples/microservices-demo/adservice:v0.4.0
[root@k8s-master release]# grep image kubernetes-manifests.yaml | uniq | wc -l
13
(5)在k8s集群的worker节点提前下载镜像,将以下命令打包成文件,文件名为command
docker pull gcr.lank8s.cn/google-samples/microservices-demo/emailservice:v0.4.0
docker pull gcr.lank8s.cn/google-samples/microservices-demo/currencyservice:v0.4.0
docker pull gcr.lank8s.cn/google-samples/microservices-demo/loadgenerator:v0.4.0
docker pull gcr.lank8s.cn/google-samples/microservices-demo/paymentservice:v0.4.0
docker pull gcr.lank8s.cn/google-samples/microservices-demo/productcatalogservice:v0.4.0
docker pull gcr.lank8s.cn/google-samples/microservices-demo/recommendationservice:v0.4.0
docker pull gcr.lank8s.cn/google-samples/microservices-demo/shippingservice:v0.4.0
docker pull gcr.lank8s.cn/google-samples/microservices-demo/checkoutservice:v0.4.0
docker pull gcr.lank8s.cn/google-samples/microservices-demo/cartservice:v0.4.0
docker pull gcr.lank8s.cn/google-samples/microservices-demo/adservice:v0.4.0
docker pull gcr.lank8s.cn/google-samples/microservices-demo/frontend:v0.4.0
docker pull busybox:latest
docker pull redis:alpine
#运行脚本
bash command
(6)镜像下载之后,使用sed把kubernetes-manifests.yaml文件中的gcr.io修改为gcr.lank8s.cn
sed -i 's/gcr.io/gcr.lank8s.cn/' kubernetes-manifests.yaml此时kubernetes-manifests.yaml文件中的镜像就全被修改了
[root@k8s-master release]# grep image kubernetes-manifests.yaml
image: gcr.lank8s.cn/google-samples/microservices-demo/emailservice:v0.4.0
image: gcr.lank8s.cn/google-samples/microservices-demo/checkoutservice:v0.4.0
image: gcr.lank8s.cn/google-samples/microservices-demo/recommendationservice:v0.4.0
image: gcr.lank8s.cn/google-samples/microservices-demo/frontend:v0.4.0
image: gcr.lank8s.cn/google-samples/microservices-demo/paymentservice:v0.4.0
image: gcr.lank8s.cn/google-samples/microservices-demo/productcatalogservice:v0.4.0
image: gcr.lank8s.cn/google-samples/microservices-demo/cartservice:v0.4.0
image: busybox:latest
image: gcr.lank8s.cn/google-samples/microservices-demo/loadgenerator:v0.4.0
image: gcr.lank8s.cn/google-samples/microservices-demo/currencyservice:v0.4.0
image: gcr.lank8s.cn/google-samples/microservices-demo/shippingservice:v0.4.0
image: redis:alpine
image: gcr.lank8s.cn/google-samples/microservices-demo/adservice:v0.4.0
istio-manifests.yaml文件没有镜像
[root@k8s-master release]# vim istio-manifests.yaml
[root@k8s-master release]# grep image istio-manifests.yaml
(7)创建 Kubernetes 资源
kubectl apply -f /root/online-boutique/microservices-demo/release/kubernetes-manifests.yaml -n online-boutique(8)检查所有 Pod 都在运行
[root@k8s-master release]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
adservice-66f55574f5-mglz9 2/2 Running 0 12h 172.17.235.196 k8s-master <none> <none>
cartservice-7cb76849b4-clddj 2/2 Running 0 12h 172.17.109.89 k8s-node-1 <none> <none>
checkoutservice-f6df96fd9-xmvtb 2/2 Running 0 12h 172.17.109.66 k8s-node-1 <none> <none>
currencyservice-5f7cd94b69-5nhhr 2/2 Running 0 12h 172.17.109.76 k8s-node-1 <none> <none>
emailservice-7b9884b797-gtpmx 2/2 Running 0 12h 172.17.109.127 k8s-node-1 <none> <none>
frontend-78b7c4c99-dtqsl 2/2 Running 0 12h 172.17.109.67 k8s-node-1 <none> <none>
loadgenerator-68869b5774-fs59b 2/2 Running 0 12h 172.17.109.83 k8s-node-1 <none> <none>
paymentservice-6c4cd96c57-pl8qj 2/2 Running 0 12h 172.17.109.68 k8s-node-1 <none> <none>
productcatalogservice-d7bd7977c-7wzlc 2/2 Running 0 12h 172.17.109.87 k8s-node-1 <none> <none>
recommendationservice-7d5d4cb595-w964n 2/2 Running 0 12h 172.17.109.65 k8s-node-1 <none> <none>
redis-cart-849bbcb78b-k5hhl 2/2 Running 0 12h 172.17.109.85 k8s-node-1 <none> <none>
shippingservice-57b765998c-nkss4 2/2 Running 0 12h 172.17.109.82 k8s-node-1 <none> <none>
(9)创建Istio资源
[root@k8s-master microservices-demo]# pwd
/root/online-boutique/microservices-demo
[root@k8s-master microservices-demo]# ls istio-manifests/
allow-egress-googleapis.yaml frontend-gateway.yaml frontend.yaml
[root@k8s-master microservices-demo]# kubectl apply -f ./istio-manifests
serviceentry.networking.istio.io/allow-egress-googleapis created
serviceentry.networking.istio.io/allow-egress-google-metadata created
gateway.networking.istio.io/frontend-gateway created
virtualservice.networking.istio.io/frontend-ingress created
virtualservice.networking.istio.io/frontend created
部署MetalLB负载均衡器
(1)下载release版本
wget https://github.com/metallb/metallb/archive/refs/tags/v0.12.1.tar.gz
tar -zxvf metallb-0.12.1.tar.gz
cd metallb-0.12.1/manifests(2)执行yaml文件进行安装
kubectl apply -f namespace.yaml
kubectl apply -f metallb.yaml(3)查看运行的pods,metalLB包含两个部分:a cluster-wide controller,a per-machine protocol speaker
[root@k8s-master manifests]# kubectl -n metallb-system get pods
NAME READY STATUS RESTARTS AGE
controller-57fd9c5bb-5z9c7 1/1 Running 0 12h
speaker-nndf5 1/1 Running 0 12h
speaker-rz8jr 1/1 Running 0 12h
(4)查看其它信息,包含了“controller”deployment和the“speaker” DaemonSet。目前还没有宣布任何内容,因为我们没有提供ConfigMap,也没有提供负载均衡地址的服务。
[root@k8s-master manifests]# kubectl -n metallb-system get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
controller 1/1 1 1 12h
[root@k8s-master manifests]# kubectl -n metallb-system get ds
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
speaker 2 2 2 2 2 kubernetes.io/os=linux 12h
(5)配置Layer2模式。创建config.yaml提供IP地址池,查看提供的默认示例configmap
vim example-layer2-config.yaml 修改ip地址池,从集群IP地址段中为MetalLB分配部分IP地址
apiVersion: v1
kind: ConfigMap
metadata:
namespace: metallb-system
name: config
data:
config: |
address-pools:
- name: default
protocol: layer2
addresses:
- 192.168.0.200-192.168.0.250
kubectl apply -f example-layer2-config.yaml(6)得到入口网关的 IP 地址并打开前端服务
INGRESS_HOST="$(kubectl -n istio-system get service istio-ingressgateway -o jsonpath='{.status.loadBalancer.ingress[0].ip}')"
echo "$INGRESS_HOST"
[root@k8s-master sbin]# kubectl get service -n istio-system istio-ingressgateway -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
istio-ingressgateway LoadBalancer 10.0.164.222 192.168.0.201 15021:30561/TCP,80:31671/TCP,443:32213/TCP,31400:32075/TCP,15443:31787/TCP 3d1h app=istio-ingressgateway,istio=ingressgateway
nginx安装与配置(虚拟机无需进行这一步)
(1)下载安装包并解压
wget https://nginx.org/download/nginx-1.21.6.tar.gz
tar xvf nginx-1.21.6.tar.gz
cd nginx-1.21.6(2)配置(带有https模块)
./configure --prefix=/usr/local/nginx --with-http_stub_status_module --with-http_ssl_module(3)编译和安装
make
make install(4)查看安装路径
whereis nginx(5)设置开机启动
vim /lib/systemd/system/nginx.service
[Unit]
Description=nginx service
After=network.target
[Service]
Type=forking
ExecStart=/usr/local/nginx/sbin/nginx
ExecReload=/usr/local/nginx/sbin/nginx -s reload
ExecStop=/usr/local/nginx/sbin/nginx -s stop
PrivateTmp=true
[Install]
WantedBy=multi-user.target
说明:
Description:描述服务
After:描述服务类别
[Service]服务运行参数的设置
Type=forking是后台运行的形式
ExecStart为服务的具体运行命令
ExecReload为重启命令
ExecStop为停止命令
PrivateTmp=True表示给服务分配独立的临时空间
注意:[Service]的启动、重启、停止命令全部要求使用绝对路径
[Install]运行级别下服务安装的相关设置,可设置为多用户,即系统运行级别为3
保存退出
(6)加入开机自启动
systemctl enable nginx.service(7)启动
cd /usr/local/nginx/sbin
./nginx(8)nginx.conf配置文件修改
vi /usr/local/nginx/conf/nginx.conf
server {
listen 31671;
server_name 123.60.30.244;
#charset koi8-r;
#access_log logs/host.access.log main;
location / {
proxy_pass https://192.168.0.201:80;
proxy_ssl_server_name on;
proxy_ssl_session_reuse off;
root html;
index index.html index.htm;
}
(9)重新运行nginx
./nginx -s reload浏览器中访问并删除frontend-external服务
(1)在浏览器中访问地址http://123.60.30.244:31671/
或者http://192.168.88.210
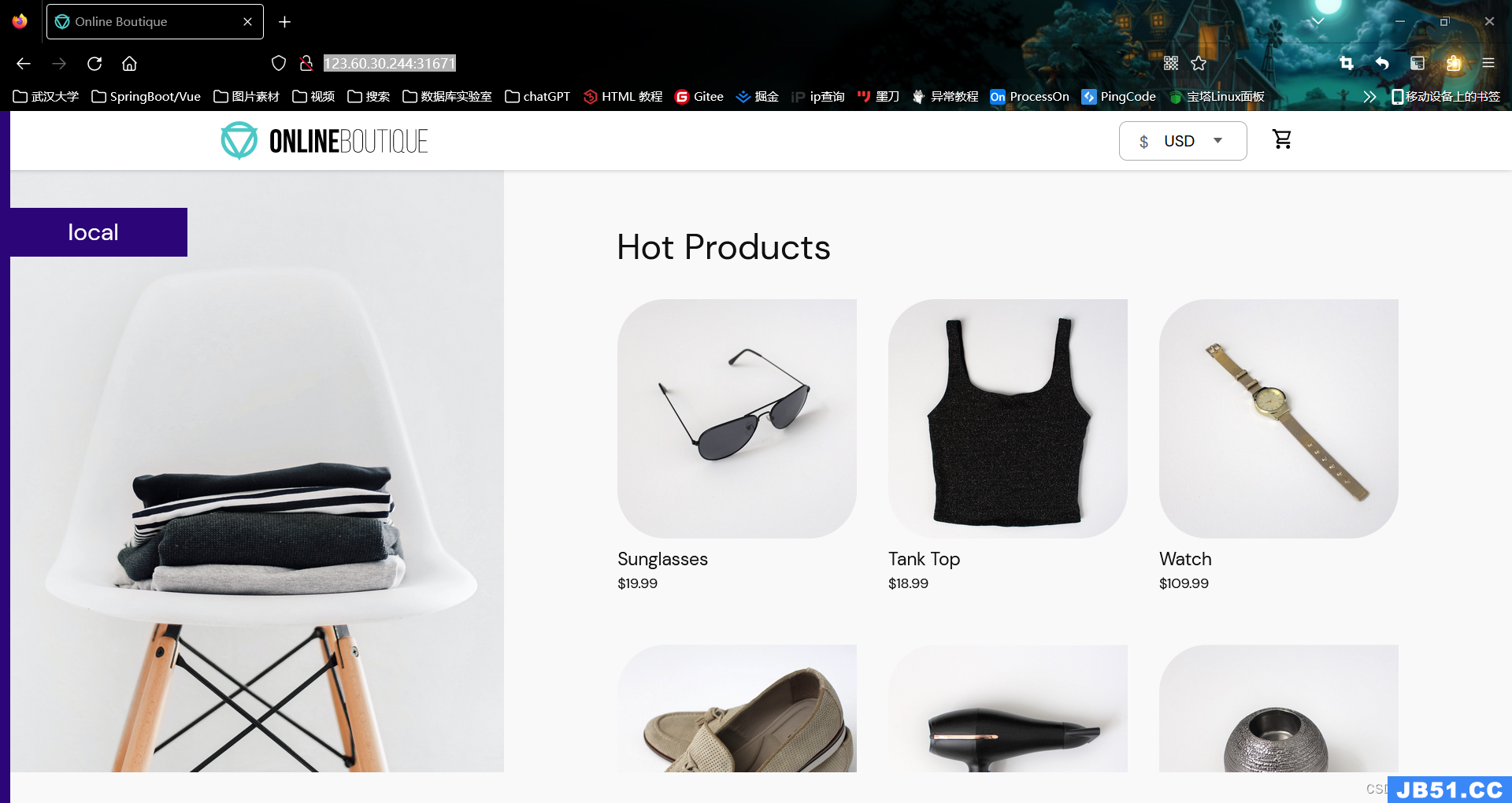
图3.2.1 浏览器中访问Online Boutique(公网)

图3.2.2 浏览器中访问Online Boutique(虚拟机)
(2)删除frontend-external服务。frontend-external服务是一个 LoadBalancer服务,它暴露了前端。由于我们正在使用 Istio 的入口网关,所以我们不再需要这个 LoadBalancer 服务了
[root@k8s-master ~]# kubectl get svc | grep frontend-external
frontend-external LoadBalancer 10.13.37.6 192.168.0.200 80:32063/TCP 25h
[root@k8s-master ~]# kubectl delete svc frontend-external
service "frontend-external" deleted
[root@k8s-master ~]# kubectl get svc | grep frontend-external
3.3注意事项
- 安装Istio过程中,由于GetMesh下载地址为外网地址,所以很容易下载 GetMesh CLI失败,此时也可以直接使用Istio安装包进行安装。
- 部署Online Boutique项目过程中,创建Kubernetes资源需要等待较长时间才能创建完成,有时候也会提示资源不足导致Pod一直处于Pending状态,这时可以考虑删除online boutique的命名空间重新进行创建或者更换docker镜像版本。
- 无论是服务器端还是本地虚拟机,部署完项目后创建Istio资源后都无法自动分配Service的EXTERNAL-IP,此时需要通过部署MetalLB负载均衡器来分配内网IP作为EXTERNAL-IP,然后才可以通过浏览器访问online boutique项目。
- 由于MetalLB负载均衡器分配的EXTERNAL-IP是内网地址,因此在服务器端还需安装配置nginx代理服务器进行反向代理才可以直接在浏览器中进行访问。配置过程中需注意监听端口号必须使用Service提供的映射端口才可以正常访问。
- 一切部署完成后还需要删除frontend-external服务,该服务是一个 LoadBalancer服务,它暴露了前端。由于我们正在使用 Istio 的入口网关,所以我们不再需要这个 LoadBalancer 服务了。
3.4实现机制
Istio定义:Istio提供一种简单的方式来建立已部署的服务的网络,具备负载均衡,服务到服务认证,监控等等功能,而不需要改动任何服务代码。简单的说,有了Istio,你的服务就不再需要任何微服务开发框架(典型如Spring Cloud,Dubbo),也不再需要自己手动实现各种复杂的服务治理功能(很多是Spring Cloud和Dubbo也不能提供的,需要自己动手)。只要服务的客户端和服务端可以进行简单的直接网络访问,就可以通过将网络层委托Istio,从而获得一系列的完备功能。可以近似的理解为:Istio = 微服务框架 + 服务治理。
Istio的关键功能:
HTTP/1.1,HTTP/2,gRPC和TCP流量的自动区域感知负载平衡和故障切换。
通过丰富的路由规则,容错和故障注入,对流行为的细粒度控制。
支持访问控制,速率限制和配额的可插拔策略层和配置API。
集群内所有流量的自动量度,日志和跟踪,包括集群入口和出口。
安全的服务到服务身份验证,在集群中的服务之间具有强大的身份标识。
Istio整体架构:
Istio服务网格逻辑上分为数据面板和控制面板。

图3.4.1 Istio服务网格逻辑
当前流行的两款开源的服务网格 Istio 和 Linkerd 实际上都是这种构造,只不过 Istio 的划分更清晰,而且部署更零散,很多组件都被拆分,控制平面中包括 Mixer、Pilot、Auth,数据平面默认是用Envoy;而 Linkerd 中只分为 Linkerd 做数据平面,namerd 作为控制平面。数据面板由一组智能代理(Envoy)组成,代理部署为边车,调解和控制微服务之间所有的网络通信。控制面板负责管理和配置代理来路由流量,以及在运行时执行策略。Istio中Envoy (或者说数据面板)扮演的角色是底层干活的民工,而该让这些民工如何工作,由包工头控制面板来负责完成。
控制平面的特点:
- 不直接解析数据包
- 与数据平面中的代理通信,下发策略和配置
- 负责网络行为的可视化
- 通常提供API或者命令行工具可用于配置版本化管理,便于持续集成和部署
数据平面的特点:
- 通常是按照无状态目标设计的,但实际上为了提高流量转发性能,需要缓存一些数据,因此无状态也是有争议的
- 直接处理入站和出站数据包,转发、路由、健康检查、负载均衡、认证、鉴权、产生监控数据等
- 对应用来说透明,即可以做到无感知部署
在Istio的架构中,这两个模块的分工非常的清晰,体现在架构上也是经纬分明: Mixer,Pilot和Auth这三个模块都是Go语言开发,代码托管在Github上,三个仓库分别是 Istio/mixer,Istio/pilot/auth。而Envoy来自Lyft,编程语言是c++,代码托管在Github但不是Istio下。从团队分工看,Google和IBM关注于控制面板中的Mixer,Pilot和Auth,而Lyft继续专注于Envoy。Istio的这个架构设计,将底层Service Mesh的具体实现,和Istio核心的控制面板拆分开。从而使得Istio可以借助成熟的Envoy快速推出产品,未来如果有更好的Service Mesh方案也方便集成。
4实验四、五、六
4.1实验说明
在kubernetes中为Istio配置Kiali,实现Istio服务网格的可视化,为Online Boutique项目提供服务拓扑图、全链路跟踪、指标遥测、配置校验、健康检查等功能。
图4.1.1 安装kiali插件实现服务网格可视化
图4.1.2 安装kiali插件实现链路跟踪
在kubernetes中为 Istio 配置 Jaeger,为 Online Boutique 项目提供分布式调用链追踪系统,用于监控和排查基于微服务的分布式系统问题,包括:分布式上下文传播、分布式事务监控、根因分析、服务依赖关系分析、性能 / 延迟优化等任务。
图4.1.3 安装Jaeger插件实现链路跟踪与监控
在 Kubernetes 中安装和配置Prometheus、Grafana,完成整个集群、工作负载在使用Locust压力负载的情况下的运行情况、健康状态监控。
图4.1.4 安装Prometheus和Grafana实现日志与健康状态监控
4.2实验步骤
配置kiali、jaeger、prometheus、grafana
(1)下载istio安装包istio-1.17.2-linux-amd64.tar.gz安装分析工具
(2)进入对应目录
[root@k8s-master addons]# pwd
/root/istio-1.17.2/samples/addons
[root@k8s-master addons]# ls
extras grafana.yaml jaeger.yaml kiali.yaml prometheus.yaml README.md
[root@k8s-master addons]# kubectl apply -f prometheus.yaml
serviceaccount/prometheus created
configmap/prometheus created
clusterrole.rbac.authorization.k8s.io/prometheus created
clusterrolebinding.rbac.authorization.k8s.io/prometheus created
service/prometheus created
deployment.apps/prometheus created
[root@k8s-master addons]# kubectl apply -f grafana.yaml
serviceaccount/grafana created
configmap/grafana created
service/grafana created
deployment.apps/grafana created
configmap/istio-grafana-dashboards created
configmap/istio-services-grafana-dashboards created
[root@k8s-master addons]# kubectl apply -f jaeger.yaml
deployment.apps/jaeger created
service/tracing created
service/zipkin created
service/jaeger-collector created
[root@k8s-master addons]# kubectl apply -f kiali.yaml
serviceaccount/kiali created
configmap/kiali created
clusterrole.rbac.authorization.k8s.io/kiali-viewer created
clusterrole.rbac.authorization.k8s.io/kiali created
clusterrolebinding.rbac.authorization.k8s.io/kiali created
role.rbac.authorization.k8s.io/kiali-controlplane created
rolebinding.rbac.authorization.k8s.io/kiali-controlplane created
service/kiali created
deployment.apps/kiali created
(3)可以看到prometheus,grafana,kiali,jaeger被安装在istio-system命名空间下
[root@k8s-master addons]# kubectl get pod -n istio-system
NAME READY STATUS RESTARTS AGE
grafana-b854c6c8-kfdm4 1/1 Running 0 14m
istio-egressgateway-856866df45-cdj4z 1/1 Running 0 3d19h
istio-ingressgateway-77bfcf8995-nrwd7 1/1 Running 0 3d19h
istiod-8cd868b5-cgkkr 1/1 Running 0 3d19h
jaeger-5556cd8fcf-b8dmd 1/1 Running 0 14m
kiali-648847c8c4-qs56z 1/1 Running 0 14m
prometheus-7b8b9dd44c-xn9n2 2/2 Running 0 14m
访问Kiali
(1)可以看到kiali这个service的类型为ClusterIP,外部环境访问不了
[root@k8s-master addons]# kubectl get service -n istio-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
grafana ClusterIP 10.1.121.133 <none> 3000/TCP 3m24s
istio-egressgateway ClusterIP 10.1.139.102 <none> 80/TCP,443/TCP 3d19h
istio-ingressgateway LoadBalancer 10.0.164.222 192.168.0.201 15021:30561/TCP,15443:31787/TCP 3d19h
istiod ClusterIP 10.5.21.31 <none> 15010/TCP,15012/TCP,443/TCP,15014/TCP 3d19h
jaeger-collector ClusterIP 10.11.89.82 <none> 14268/TCP,14250/TCP,9411/TCP 3m9s
kiali ClusterIP 10.6.212.216 <none> 20001/TCP,9090/TCP 2m59s
prometheus ClusterIP 10.4.56.113 <none> 9090/TCP 3m40s
tracing ClusterIP 10.15.232.165 <none> 80/TCP,16685/TCP 3m9s
zipkin ClusterIP 10.11.95.234 <none> 9411/TCP 3m9s
(2)修改kiali这个service的类型为NodePort,这样外部环境就可以访问kiali了,把type: ClusterIP修改为type: NodePort即可
[root@k8s-master addons]# kubectl edit service kiali -n istio-system
service/kiali edited
(3)现在kiali这个service的类型为NodePort,浏览器输入物理机ip:32016即可访问kiali网页了
[root@k8s-master addons]# kubectl get service -n istio-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
grafana ClusterIP 10.1.121.133 <none> 3000/TCP 6m47s
istio-egressgateway ClusterIP 10.1.139.102 <none> 80/TCP,9411/TCP 6m32s
kiali NodePort 10.6.212.216 <none> 20001:32016/TCP,9090:32276/TCP 6m22s
prometheus ClusterIP 10.4.56.113 <none> 9090/TCP 7m3s
tracing ClusterIP 10.15.232.165 <none> 80/TCP,16685/TCP 6m32s
zipkin ClusterIP 10.11.95.234 <none> 9411/TCP 6m32s
(4)k8s-master机器的地址为123.60.30.244,我们可以在浏览器中打开 http://123.60.30.244:32016或http://192.168.88.201:30016,进入 kiali,kiali首页如下图所示


图4.2.2 kiali首页(虚拟机)
(5)在online-boutique命名空间点击Graph,查看服务的拓扑结构
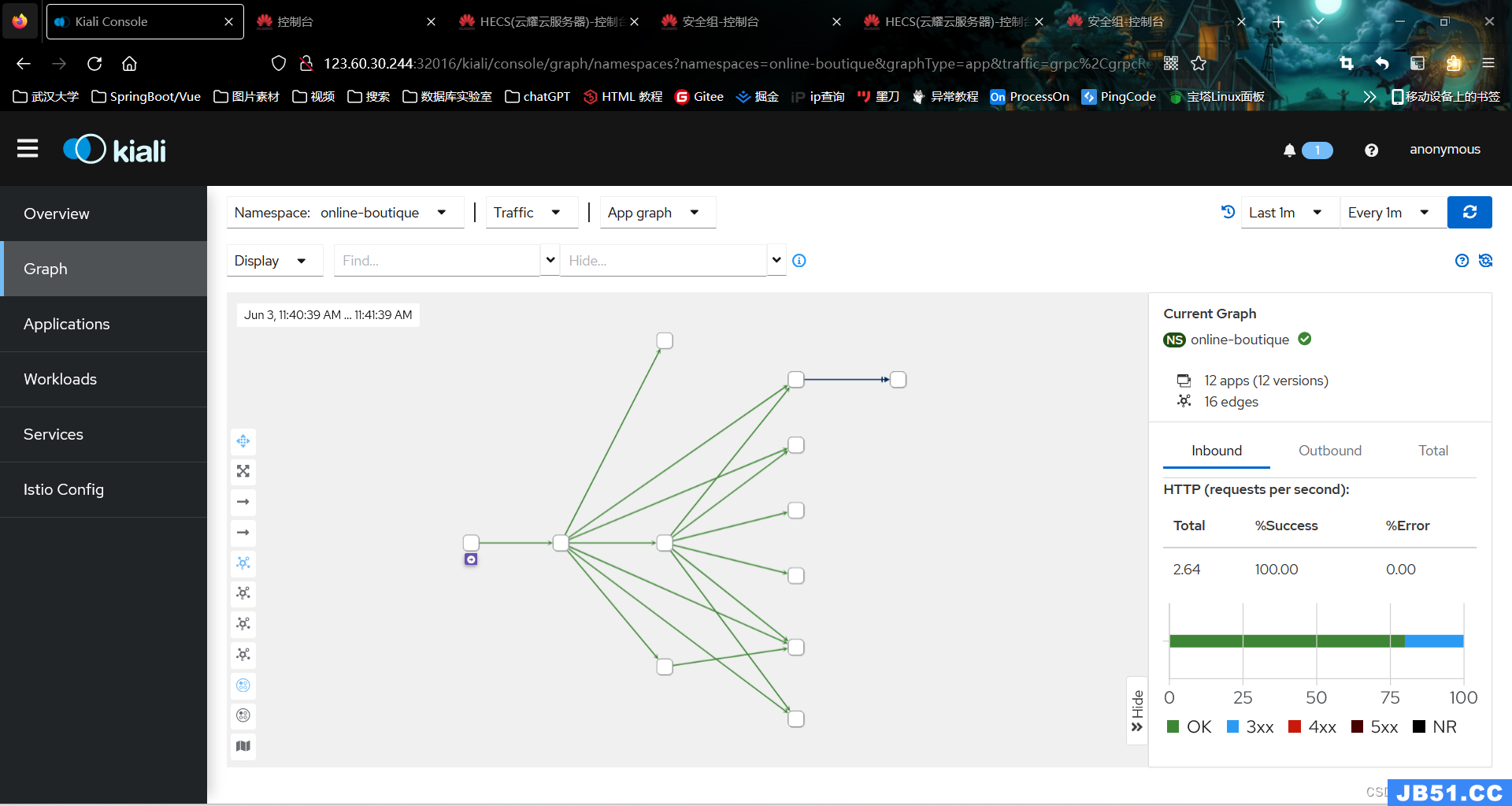
图4.2.3 服务的拓扑结构(公网)
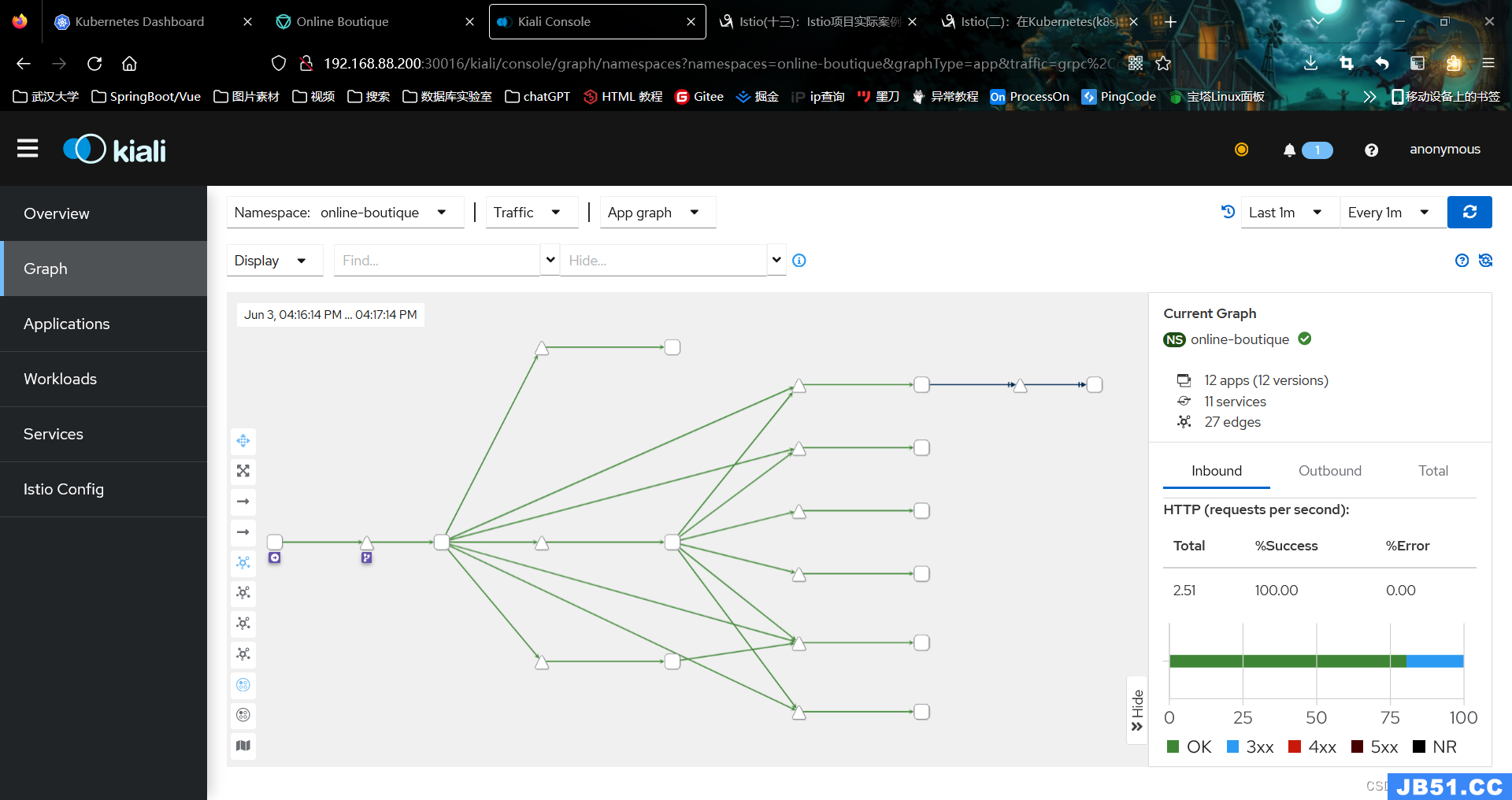
图4.2.4 服务的拓扑结构(虚拟机)
访问jaeger/zipkin
(1)查看service
[root@k8s-master addons]# kubectl get svc -n istio-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
grafana ClusterIP 10.11.222.230 <none> 3000/TCP 3h8m
istio-egressgateway ClusterIP 10.1.198.30 <none> 80/TCP,443/TCP 3h37m
istio-ingressgateway LoadBalancer 10.6.96.131 192.168.88.210 15021:31766/TCP,80:32319/TCP,443:31776/TCP,31400:31810/TCP,15443:31252/TCP 3h37m
istiod ClusterIP 10.8.183.53 <none> 15010/TCP,15014/TCP 3h37m
jaeger-collector ClusterIP 10.8.123.13 <none> 14268/TCP,9411/TCP 3h8m
kiali NodePort 10.7.102.44 <none> 20001:30016/TCP,9090:31578/TCP 3h8m
prometheus ClusterIP 10.10.62.4 <none> 9090/TCP 3h8m
tracing ClusterIP 10.10.8.235 <none> 80/TCP 3h8m
zipkin ClusterIP 10.10.116.195 <none> 9411/TCP 3h8m
(2)在jaeger.yaml文件中可以看到如图注释,表明Jaeger实现了Zipkin API,为了支持切换跟踪后端,使用了一个名为Zipkin的服务。因此为了可以将zipkin暴露在k8s集群外访问,需要将tracing的ClusterIP服务类型更改为NodePort。执行语句如下:
kubectl patch svc -n istio-system tracing -p '{"spec":{"type": "NodePort"}}'
图4.2.5 jaeger.yaml中注释
(3)查看svc端口
[root@k8s-master addons]# kubectl get svc -n istio-system|grep tracing
tracing NodePort 10.10.8.235 <none> 80:32455/TCP 3h53m
可以看到暴露的端口为:32455
浏览器访问http://192.168.88.201:32455
由于服务器被攻击被迫被拿去挖矿,所以后面截图都是在虚拟机中的截图。
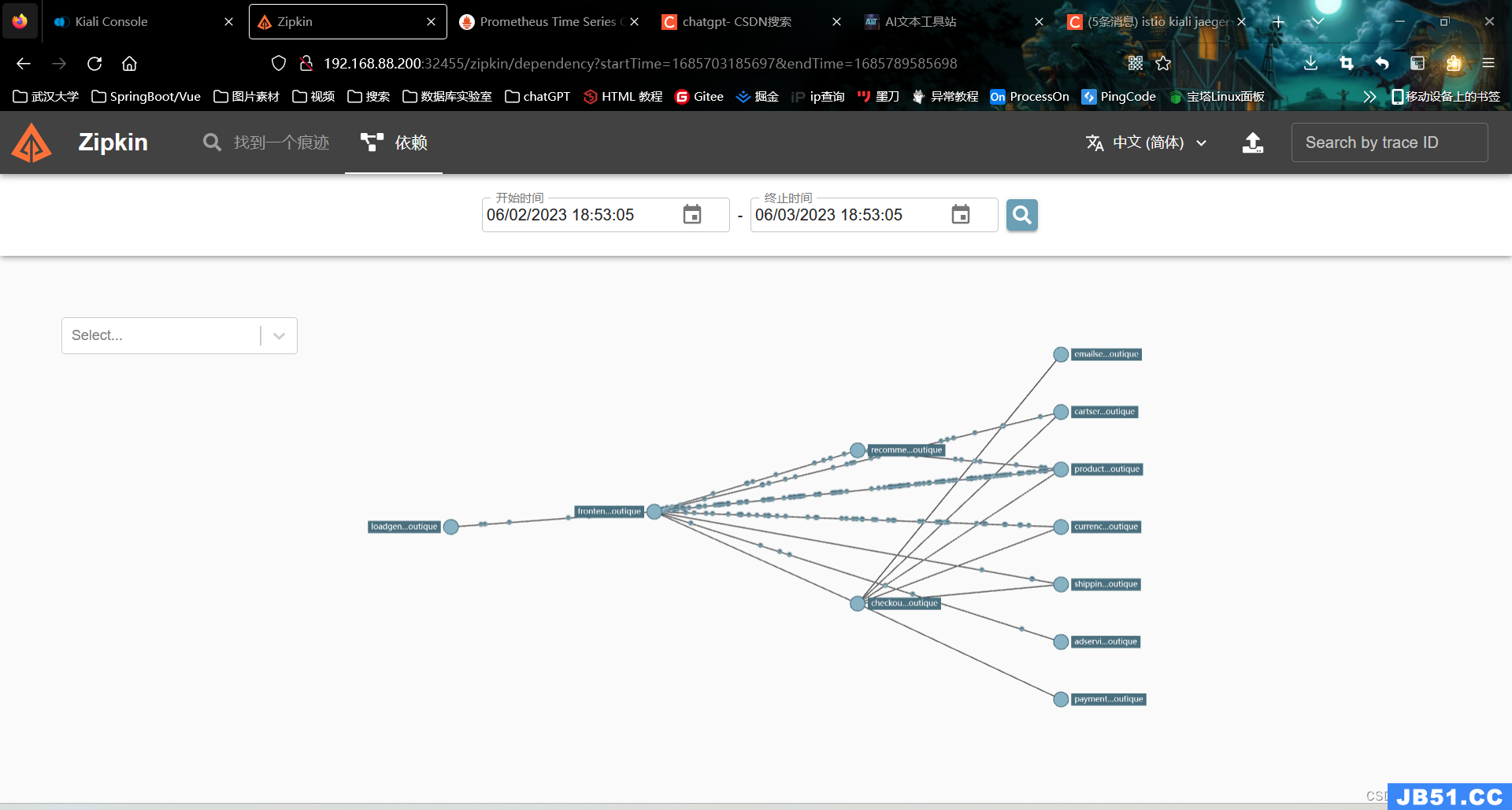
图4.2.6 ZipKin页面
(4)在用户界面上,我们可以选择跟踪查询的标准。点击按钮,从下拉菜单中选择 serviceName

图4.2.7 ZipKin用户界面
(4)然后选择advervice.online-boutique service,点击搜索按钮(或按回车键),就可以搜索到 trace 信息。

图4.2.8 搜索trace信息
(4)我们可以点击个别 trace 来深入挖掘不同的跨度。详细的视图将显示服务之间的调用时间,以及请求的细节,如方法、协议、状态码等。
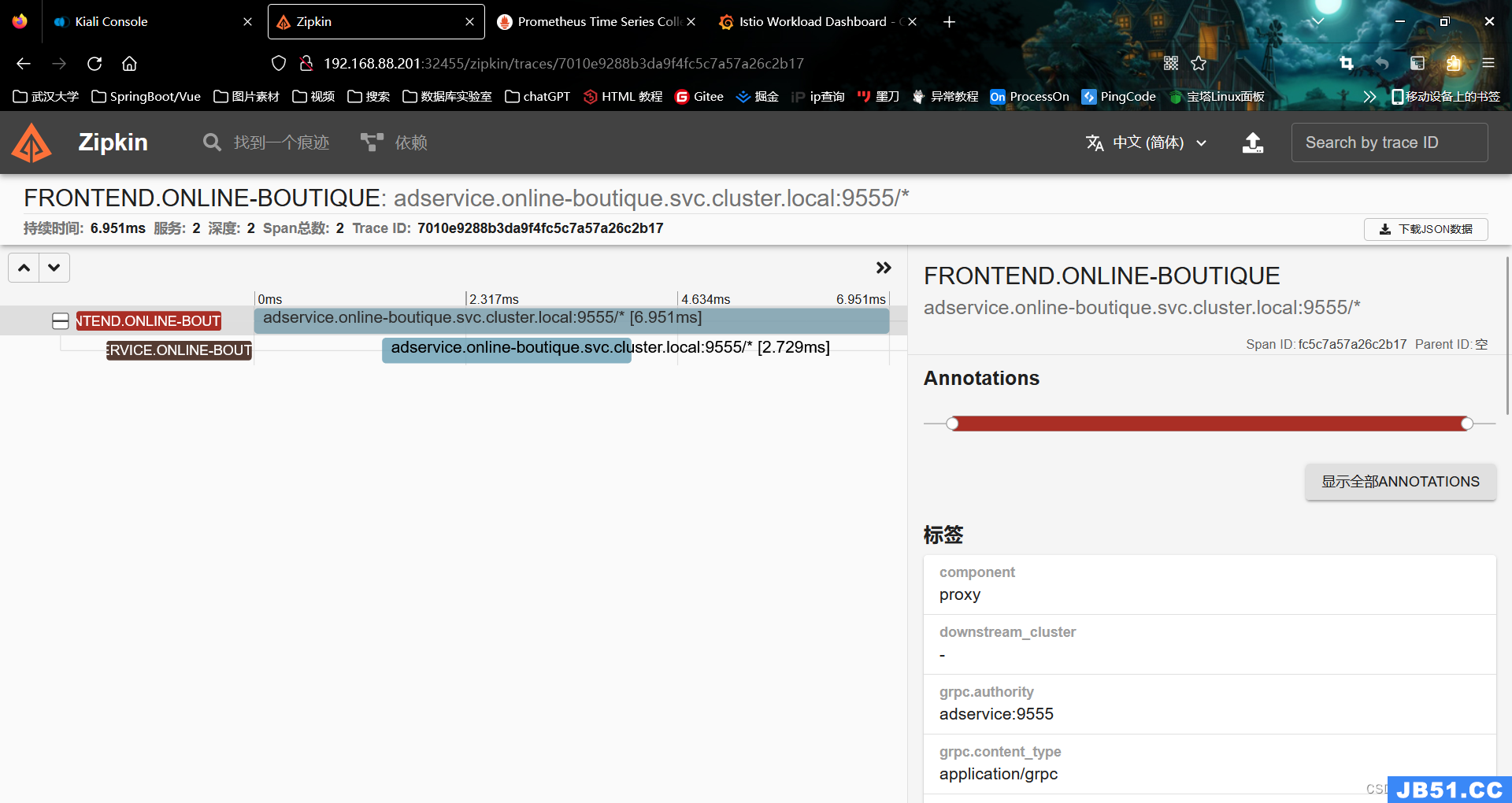
图4.2.9 详细视图
设置kiali jaeger外部链接地址
(1)编辑kiali configmap
kubectl edit configmap -n istio-system kiali(2)在external_services.tracing.url内容下添加jaeger外部链接,链接地址就是istio-system 命名空间下tracing服务的宿主机地址和nodeport
external_services:
custom_dashboards:
enabled: true
tracing:
url: http://192.168.88.200:32455/zipkin
in_cluster_url: http://tracing/zipkin
(3)编辑kiali configmap 后,需要删除并重新生成 kiali pod,好让配置挂载生效,执行语句如下
kubectl delete pod -n istio-system $(kubectl get pod -n istio-system | grep -i kiali | awk '{print $1}')(4)执行完后,再次查看kiali pod
[root@k8s-master addons]# kubectl get pods -n istio-system|grep kiali
kiali-648847c8c4-s8nvb 1/1 Running 1 (14h ago) 16h
查看发现 url 值已经生效
[root@k8s-master addons]# kubectl -n istio-system exec -it kiali-648847c8c4-s8nvb -- cat /kiali-configuration/config.yaml
再次刷新访问 kiali,就会在左侧栏出现Distributed Tracing,点击它,就会打开zipkin,效果同上。

图4.2.10 出现Distributed Tracing
访问Prometheus
(1)通过以下命令查看service,发现prometheus这个service的类型为ClusterIP,外部环境访问不了
kubectl get service -n istio-system -o wide (2)修改prometheus这个service的类型为NodePort,这样外部环境就可以访问prometheus了
kubectl patch svc -n istio-system prometheus -p '{"spec":{"type": "NodePort"}}'(3)现在prometheus这个service的类型为NodePort,浏览器输入物理机ip:30403即可访问prometheus网页了
[root@k8s-master addons]# kubectl get service -n istio-system -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
grafana ClusterIP 10.11.222.230 <none> 3000/TCP 21h app.kubernetes.io/instance=grafana,app.kubernetes.io/name=grafana
istio-egressgateway ClusterIP 10.1.198.30 <none> 80/TCP,443/TCP 21h app=istio-egressgateway,istio=egressgateway
istio-ingressgateway LoadBalancer 10.6.96.131 192.168.88.210 15021:31766/TCP,15443:31252/TCP 21h app=istio-ingressgateway,istio=ingressgateway
istiod ClusterIP 10.8.183.53 <none> 15010/TCP,15014/TCP 21h app=istiod,istio=pilot
jaeger-collector ClusterIP 10.8.123.13 <none> 14268/TCP,9411/TCP 21h app=jaeger
kiali NodePort 10.7.102.44 <none> 20001:30016/TCP,9090:31578/TCP 21h app.kubernetes.io/instance=kiali,app.kubernetes.io/name=kiali
prometheus NodePort 10.10.62.4 <none> 9090:30403/TCP 21h app=prometheus,component=server,release=prometheus
tracing NodePort 10.10.8.235 <none> 80:32455/TCP 21h app=zipkin
zipkin ClusterIP 10.10.116.195 <none> 9411/TCP 21h app=zipkin
图4.2.11 prometheus界面

图4.2.12 尝试使用prometheus
访问Grafana
(1)通过以下命令查看service,发现grafana这个service的类型为ClusterIP,外部环境访问不了
kubectl get service -n istio-system -o wide (2)修改grafana这个service的类型为NodePort,这样外部环境就可以访问prometheus了
kubectl patch svc -n istio-system grafana -p '{"spec":{"type": "NodePort"}}'(3)现在grafana这个service的类型为NodePort,浏览器输入物理机ip:32644即可访问grafana网页了
[root@k8s-master addons]# kubectl get service -n istio-system -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
grafana NodePort 10.11.222.230 <none> 3000:32644/TCP 21h app.kubernetes.io/instance=grafana,istio=pilot
jaeger-collector ClusterIP 10.8.123.13 <none> 14268/TCP,app.kubernetes.io/name=kiali
prometheus NodePort 10.10.62.4 <none> 9090:30403/TCP 21h app=prometheus,release=prometheus
tracing NodePort 10.10.8.235 <none> 80:32455/TCP 21h app=zipkin
zipkin ClusterIP 10.10.116.195 <none> 9411/TCP 21h app=zipkin

图4.2.13 grafana界面
(4)点击搜索框和 istio 文件夹,查看已安装的仪表盘,如下图所示。

图4.2.14 查看已安装的仪表盘
(5)Istio Grafana 安装时预配置了以下仪表盘:
- Istio 控制平面仪表盘(Istio Control Plane Dashboard)
从 Istio 控制平面仪表盘,我们可以监控 Istio 控制平面的健康和性能。

图4.2.15 Istio控制平面仪表盘(Istio Control Plane Dashboard)
Istio Control Plane Dashboard 仪表盘将向我们展示控制平面的资源使用情况(内存、CPU、磁盘、Go routines),以及关于 Pilot、Envoy 和 Webhook 的信息。
- Istio 网格仪表盘(Istio Mesh Dashboard)
网格仪表盘为我们提供了在网格中运行的所有服务的概览。仪表盘包括全局请求量、成功率以及 4xx 和 5xx 响应的数量。

图4.2.16 Istio 网格仪表盘(Istio Mesh Dashboard)
- Istio 性能仪表盘(Istio Performance Dashboard)
性能仪表盘向我们展示了 Istio 主要组件在稳定负载下的资源利用率。

图4.2.17 Istio 性能仪表盘(Istio Performance Dashboard)
- Istio 服务仪表盘(Istio Service Dashboard)
服务仪表盘允许我们在网格中查看服务的细节。我们可以获得关于请求量、成功率、持续时间的信息,以及显示按来源和响应代码、持续时间和大小的传入请求的详细图表。
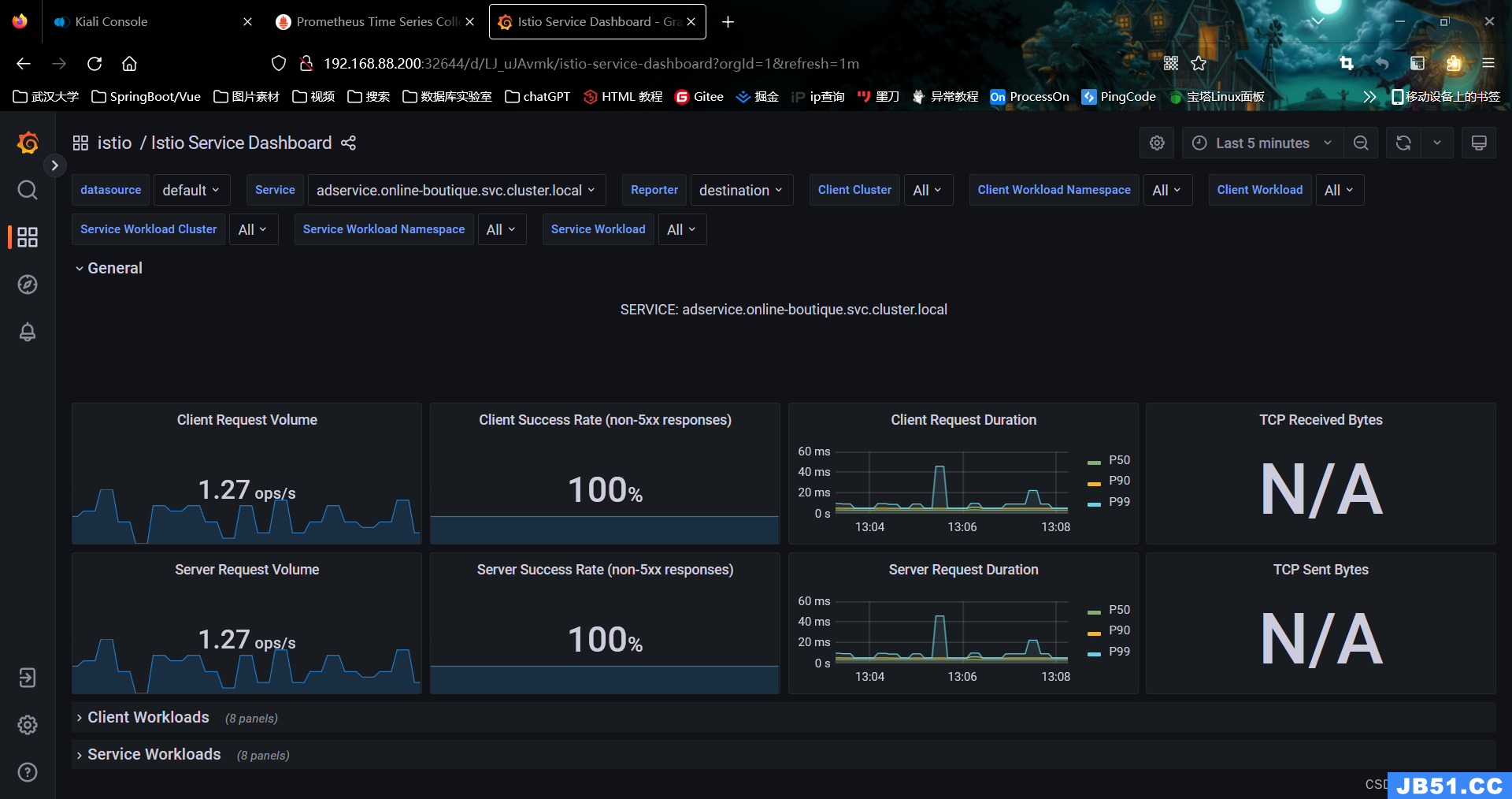
图4.2.18 Istio 服务仪表盘(Istio Service Dashboard)
- Istio Wasm 扩展仪表盘(Istio Wasm Extension Dashboard)
Istio Wasm 扩展仪表盘显示与 WebAssembly 模块有关的指标。从这个仪表盘,我们可以监控活动的和创建的 Wasm 虚拟机,关于获取删除 Wasm 模块和代理资源使用的数据。

图 4.2.19 Istio Wasm 扩展仪表盘(Istio Wasm Extension Dashboard)
- Istio 工作负载仪表盘(Istio Workload Dashboard)
这个仪表盘为我们提供了一个工作负载的详细指标分类。

图4.2.20 Istio 工作负载仪表盘(Istio Workload Dashboard)
4.3注意事项
- 在jaeger.yaml文件中可以看到注释“#Jaeger implements the Zipkin API. To support swapping out the tracing backend,we use a Service named Zipkin”,表明Jaeger实现了Zipkin API,为了支持切换跟踪后端,使用了一个名为Zipkin的服务。因此为了可以将zipkin暴露在k8s集群外访问,需要将tracing的ClusterIP服务类型更改为NodePort。
- 要将Kiali、Jaeger、Prometheus、Grafana的Service修改为NodePort才能被外部环境访问到,服务器端还需修改Nginx配置文件
4.4实现机制
Kiali:Kiali运行于Isito之上,用于可视化服务网格拓扑,以提供对断路器、请求速率等功能的可见性。Kiali提供了从Application到Service和Workload的不同层次的Service Mesh组件的可见性。Kiali实时提供了namespace的交互式图形化界面。Kiali可以在多个层次(Application、versions、workloads)上显示所选图形节点或边缘的上下文和图表信息。
Prometheus:Prometheus是一个开源的服务监控工具。Prometheus以指定的时间间隔从配置的目标收集metrics,评估规则表达式,显示结果,并在观察到某些条件为真时触发警报。Grafana或其他API Consumer被用于可视化展示收集到的数据。
Jaeger:Jaeger是一个开源的分布式跟踪系统。您可以使用jaeger来监控和排查基于微服务的分布式系统的故障。使用jaeger,您可以执行跟踪组成应用程序的各种微服务执行请求的路径。默认情况下,jaeger是作为 Service Mesh 的一部分安装的。
Grafana:Grafana是一个开源工具,用于创建监控、metrics分析、并提供可视化的dashboard。您可以使用grafana查询metrics、可视化metrics、告警,无论它们存储在graphite、elasticsearch、opentsdb、prometheus或infloxdb。Istio通过Prometheus和Grafana进行监控。
5总结
5.1云计算应用与影响
云原生的应用场景
- 大规模互联网应用
随着互联网的快速发展,越来越多的企业开始将业务转移到互联网上,这就需要构建大规模的互联网应用。互联网应用需要具备啊用性、高性能和高可扩展性等要求,而这些要求正是云原生技术所擅长的领域。采用云原生技术可以将应用程序拆分成多个微服务,在容器中运行,并通过服务发现、负载均衡等技术实现高可用性和可扩展性。
- 金融业务应用
金融业务是一个高度安全性、 舸靠性、可用性的领域,而云原生技术可以提供一种安全、可靠、高效的应用程序开发和部署方式。云原生技术可以实现容器化部署、自动化运维、 负载均衡、服务发现等功能,从而提高金融业务应用的可靠性和安全性。
- 人工智能和大数据应用
人工智能和大数据是当今科技领域的热i ]话题,而酝原生技术可以为这些应用提供一种高效、可扩展、弹性伸缩的应用程序开发和部署方式。通过将Al和大数据应用程序拆分成多个微服务,采用容器化部署方式,可以实现应用程序的快速部署和弹性伸缩,同时还可以提高应用程序的可靠性和可维护性。
- 物联网应用
物联网是一个快速发展的领域,物联网应用需要处理海量的传感器数据,并根据数据进行实时分析和决策。云原生技术可以为物联网应用提供一种高效、可扩展、弹性伸缩的应用程序开发和部署方式。通过采用容器化部署方式,可以实现快速部署和弹性伸缩,同时还可以提高应用程序的可靠性和可维护性。
- 区块链应用
区块链是一个新兴的技术领域,它可以为金融、物流等领域提供安全、可信赖的解决方案。而云原生技术可以为区块链应用提供-种高效、可扩展、弹性伸缩的应用程序开发和部署方式。通过采用容器化部署方式,可以实现快速部署和弹性伸缩,同时还可以提高应用程序的可靠性和可维护性。总之 ,云原生技术将成为未来应用程序开发和部署的主流方式,它可以帮助企业实现快速迭代、敲开发和部署、弹性伸缩等目标,从而提高企业的竞争力和创新能力。
云原生在金融行业的应用
云原生技术在金融行业的演进
在过去的40年中,我国金融行业IT架构经历了多次变迁,总体来讲就是从“零”到“大集中”的过程:金融机构自20世纪80年代开始引入计算机系统进行电算化处理,到20世纪90年代末实现数据大集中。近年来,随着金融线上业务的发展以及数字化转型的推进,传统的金融IT架构存在很多难以解决的问题:
一是研发周期长。当前,绝大多数金融机构的系统研发流程为传统的瀑布方式,需求交付周期以月来计算,导致失去了很多市场先机。
二是交付标准多。各业务系统部署安装的基础设施标准不一,导致金融机构运维复杂,成百上千台机器以及上百个应用需要一个庞大的运维团队来支撑。
三是协作沟通难。业务、开发与运营之间存在着信息“鸿沟”,开发人员希望基础设施响应速度更快,运营人员要求可靠性和安全性更高,而业务人员的目标则是交付速度更快。
为满足业务快速多变的诉求,金融行业的架构升级已经迫在眉睫,在此背景下,云原生开始引起金融机构的重视,并与大集中架构融合共同形成目前银行IT系统的主流架构。云原生是一种构建和运行应用程序的方法,是一套技术体系和方法论,应用程序从设计之初即考虑到云的环境,充分利用和发挥云平台的“弹性+分布式”优势,在云上以最佳的方式运行。这一概念在2013年由Pivotal公司首次提出,后经云原生计算基金会(CNCF)进一步发展和提炼,形成狭义云原生概念,其内容包括容器技术、服务网格、微服务、不可变基础设施和声明式API等。随着云计算技术的发展和普及,云原生不仅仅是一项技术,还是一套敏捷架构方法,既涵盖技术范畴(如云计算、微服务、DevOps、云原生芯片、云原生大数据、云原生AI等),也涵盖管理和架构范畴(如架构体系设计、中台化、编排重组、持续交付、无服务化等)。云原生具有应用简便、部署快捷、伸缩灵活等优势,已逐步成为数字化时代企业技术架构升级的一项进阶选择。
云原生时代金融科技的变革与挑战
云原生不仅是一种基于云的全新技术体系,更是一种全新的软件架构思想和研发实践方法论。在银行业数字化转型不断重塑技术生态、金融生态的当下,云原生因其为应用研发、系统运维、业务运营和企业级治理带来显著的改善,逐步成为银行构建新一代数字化平台的基石和数字化转型的强大推动力。
- 充分释放云时代技术红利,为银行业务应用稳态运行提供底层保障
云原生定义了一条能够让应用最大程度发挥云价值的最佳路径。“云”具有前所未有的强大计算能力、高可靠性、高通用性、高扩展性和低成本等特点,与大型银行夯实数字化转型所需的关键基础能力相一致。开发者可充分利用云平台的弹性和分布式优势,实现快速部署、按需伸缩、不停机交付,充分保障软件产品稳健运行。
- 打造组织级云原生技术生态圈,为软件交付和企业级治理提供有力支撑
云原生使企业级基础能力、服务、资源的平台化和“云”化更为彻底,同时通过一系列标准、过程、工具实现了应用系统“敏态”和技术底座“稳态”的有机结合:通过微服务,将传统的庞大系统功能分解成多个高内聚、低耦合的细粒度应用,实现了能力复用、动态协同,全面提高应用开发的敏捷迭代效率;通过应用容器、网格、Serverless等技术,显著提升基础技术能力的平台化水平,使系统运行环境更为标准化、轻量级、可适配,极大提升了应用系统开发部署和运行维护的效率。
- 重塑金融业务系统的组织流程,助力业务创新快速实现
面对银行业务规模的不断扩大和传统应用系统复杂度的不断提高,云原生强调以“应用”为核心,使业务应用“生于云,长于云”。依托于强大的技术中台能力,通过灵活的微服务开发方式、标准化容器环境的部署方式,应用的设计、开发、测试、部署等全过程可便捷地在云上完成,提升了自动化程度,大大缩短了业务获得IT服务的链路和周期。同时,云原生提供了高效的“端到端”交付、精准的灰度发布,使得在可控范围内快速验证业务新功能成为可能,业务人员甚至可以借助低代码平台自行组合新的业务服务,实现快速投产上线并及时获取反馈。
综上所述,云原生将从技术手段、管理模式上为银行业数字化转型带来巨大变革,全面转型云原生已是大势所趋,但大型银行因其原有应用系统、组织架构的复杂性,在推动云原生技术转型过程中面临着系统架构平滑演进难和推动组织流程再造难的双重挑战。
大型银行对系统稳定性、业务连续性、强监管遵从有着很高的要求,云原生转型需循序渐进、逐步升级。因此,在相当长的时期内,云原生技术底座将与原有多类型技术栈并存,以混合架构形态对外服务。大型银行需准确认识自身混合架构的技术特点,构建起架构平滑演进的机制和能力路线,实现企业级服务治理。
云原生不仅颠覆了企业技术栈,也使企业的组织形态与工作模式随之而变。大型银行需要依照全新的能力图谱升级自身管理体系,推动软件开发向软件研发转型,优化角色分工,培养熟悉DevOps、微服务、容器化等云原生核心技术的应用开发者和技术开发者,推动开发、测试、运维一体化,促进传统流程融合重塑,合理规划、提前布局,打造适应时代发展的新理念、新思维、新文化。
金融科技向云原生架构转型的趋势
- 标准化是云原生可持续发展的基石
谁掌握标准,谁就掌握未来。云原生作为金融科技发展的关键技术底座,关乎金融科技的自主掌控和可持续发展,必须将标准化上升至战略高度,标准先行,推进标准化和科技创新协同发展。
云原生整个生态还处于新技术快速发展期,商业银行应当牢牢把握新技术发展的历史性窗口,积极参与标准制定等相关工作,并与科技创新相融合,提升自身在行业中的话语权,夺取金融科技发展的制高点。
云原生生态已经形成一系列标准,如容器标准接口CNI、Kubernetes声明式API和CRD机制、服务网格XDS标准协议以及多运行时环境标准接口等。在规划和技术选型时要严格遵守标准化原则,遵循云原生生态开放标准,相关产品可按需升级和替换,避免与特定产品或厂商绑定,实现关键核心技术自主可控,确保金融科技创新和发展的主动权。
- 共性特征剥离及下沉是云原生的发展规律
共性特征包括共性技术特征和共性业务特征。将共性特征从应用系统中剥离出来,下沉至基础设施和能力中心是云原生发展的趋势和规律。应用系统开发将聚焦于核心业务逻辑代码,相关公共功能特性代码从应用中剥离,通过声明方式按需进行配置和控制,实现应用系统的轻量化、简单化。基于基础设施的通用技术能力,无服务器架构实现代码逻辑运行与环境无关,也是云原生下一步演进的方向之一。
云设施提供企业级标准的非功能能力,支持非功能特性集中统一管控,实现自动化、智能化运维。服务网格通过控制面和数据面协作将服务治理能力从应用中解耦,实现了企业级的服务治理能力和对服务治理的集中统一管控,实现了服务的可观测、可治理、可度量;多运行环境将应用分布式能力下沉至基础设施,通过标准API向应用提供能力服务,支持开发人员以业务逻辑为核心进行组装开发,显著降低开发可扩展、可维护的分布式应用的技术门槛。
- 能力服务化是云原生的输出形式
微服务是云原生的标配。“微”不代表越小越好,而是需要合适的粒度和边界。后台应用以能力为中心,基于领域驱动设计(DDD)对领域行为和模型进行高度抽象,形成一组小而专、低耦合、高度自治的服务组件,以接口契约定义业务关系,以标准协议实现互联互通。后台应用基于高代码平台研发,支持业务代码热插拔。
前台应用以客户为中心,基于标准服务能力进行编排,从发布态变更进化到运行态变更,有效支撑业务的快速创新。前台应用基于低代码平台进行可视化编排是未来发展的方向。
- 高性能是云原生的基本要求
以容器和Kubernetes为基础的云原生架构可实现系统资源需求秒级甚至毫秒级的弹性响应,应用按需进行资源申请和释放,实现资源使用的分时复用。实现资源需求响应的快速弹性需要较小的资源粒度,以尽可能少的资源承载尽可能多的业务处理需求,实现高性能,成为云原生应用的基本要求。基于响应式编程实现全链路异步是云原生架构实现应用高性能的有效手段。
云计算对环境保护和可持续发展之间的影响
云计算有助于环境保护可持续性发展的4种主要方式
1. 基础设施、应用和数据的可持续平台
微软公司和WSP USA公司日前进行了一项研究,发现采用微软云平台的企业的能源效率提高了93%。此外,采用微软Azure云平台的碳排放量比内部部署数据中心要低出98%。这项研究凸显了云计算基础设施在维持可持续性方面的效率,并且带来更多的环境效益。埃森哲公司发布的一份报告也指出,“企业将业务迁移到公共云,每年可以减少5900万吨二氧化碳排放量,相当于减少2200万辆汽车的碳排放量” 。这样的统计并不是夸大其辞,而是现实。
人们可以了解云计算基础设施提供可持续性选项的不同方式:
(1) 绿色数据中心
内部部署数据中心通常会过多消耗能源,因为需要冗余稳定的电力容量供电以及采用冷却系统以避免过热等,还有一些服务器没有得到充分利用而导致能源浪费。
此外,当IT设备的生命周期结束时,也会带来大量的电子垃圾。例如,根据美国能源部发布的调查数据,美国目前运营的数据中心占其整体能耗和碳排放量的2%~3%。因此,企业将业务迁移到云平台可以显著减少数量惊人的能源成本和资源浪费。与内部部署数据中心相比,这将更好地利用服务器,并减少硬件需求。
此外,公共云提供商可以利用可再生能源来运营绿色数据中心。例如,微软公司的绝大多数的数据中心使用风能、太阳能和水力发电等可再生能源。
(2) 非物质化
迁移到云平台将采用虚拟技术取代高碳排放的IT设备。这样的替换可以显著减少企业的碳足迹。例如,云计算技术支持视频流等无缝虚拟服务,而不是使用消耗更多能源的硬件设备。在日常运营中消除重要的物理硬件可以确保非物质化,并减少成本、浪费、工作量和环境影响。
2. 以可持续发展为中心的解决方案的快速创新
很多企业致力采用新技术来创造更可持续的业务,同时确保最大限度地减少对环境的影响。使用云计算基础设施的创新技术推动了可持续发展目标。例如,虚拟会议应用程序是迄今为止最引人注目的云计算驱动创新之一。企业可以在网上定期召开员工会议,从而节省更多的成本、能源和时间。即使在疫情持续蔓延期间,这也成为一种最具价值的可持续创新,而无缝的沟通互动确保了业务连续性。此外,机器学习和云计算基础设施正被用于购物中心、机场、商业建筑等行业领域,降低了整体能源消耗。
微软公司进行的一项研究表明,云计算可以帮助为ICT行业提供可扩展的技术解决方案,例如智能电网、智能建筑等。此外,很多企业也在利用云计算的力量来寻求可持续的解决方案。以澳大利亚能源开发商AGL公司为例,该公司利用微软公司的Azure云平台远程管理其太阳能发电设施。该公司能够在云计算基础设施的帮助下有效地获得可持续的解决方案。云计算创新的另一个用例是Ecolab公司,微软公司的云平台帮助该公司节省水资源。此外,微软公司还推出了数据驱动的Azure FarmBeats精准农业系统。该系统非常强大,可以通过卫星图像创建农场地图,帮助农民监测不同的作物参数,如氮和氧水平、土壤湿度和温度等。
这些用例无疑强调了云计算基础设施不仅本质上是一种可持续的解决方案,而且是一种推动以可持续性为中心的快速创新的基础设施。
3. 软件即服务(SaaS)解决方案
SaaS改变了人们工作、交流和共享数据的方式,对于可持续发展的要求变得至关重要且复杂。因此,企业拥有安全、可访问和准确的数据变得至关重要。SaaS平台本质上提供了云计算应用解决方案,通过管理和自动化关键活动来推动业务运营。
4. 来自超大规模企业的创新和投资
由于云计算服务和云计算用户数量的增加,超大规模企业可以在数据中心绿色节能的技术创新方面投入大量资金。例如,微软公司投资建设基于其前沿设计的数据中心(例如微软公司开发并运行了一个水下数据中心)以提高PUE值。在使用云计算业务应用程序时,对绿色环保基础设施的投资将显著减少用户的碳足迹。
5.2心得和体会
我在完成大作业的过程中不可谓过程不坎坷。
一开始我在华为云上用代金券购买了一台2核4GiB的华为云耀服务器,另外正好赶上其免费体验活动,免费领取了一台同样是2核4GiB的华为云耀服务器,两台服务器的使用期限都是一个月。同时想到一般集群例子都采用了一主两从的模式,因此我借用其他同学的华为云账号,又免费领取了一台2核4GiB的华为云耀服务器,并开始了我公网搭建k8s集群的过程。过程中我按照之前在虚拟机中搭建的k8s集群教程按步进行搭建,当所有环境都配置完毕之后,在master主机上却始终初始化失败,提示超时错误。部署过程一度陷入僵局,我和同班同学一起讨论了该问题,发现他也面临同样的困境。之后通过查询各种资料,最后确定问题的原因应该在于:因为华为云主机网络是VPC,公网IP只能在控制台上看到,在系统里面看到的是内部网卡的IP,华为云采用NAT方式将公网IP映射到HECS的位于私网的网卡上,所以在网卡上看不到公网IP,使用ifconfig查看到的也是私有网卡的IP,导致etcd无法启动。根据该问题,我先后尝试了使用iptables进行IP重定向,将内网IP转到外网IP,结果还是无法成功。接着我又尝试了在init过程中,另启一个命令行窗口修改初始化生成的etcd.yaml文件,但尝试还是失败。但万幸的是后面发现华为云耀服务器在同一个账号下的两台服务器是在同一个关联组中,因此它们之间可以利用内网IP互相PING通,所以最终我使用了两台华为云耀服务器,利用它们的私网IP,进行了k8s集群的搭建,并开始了后面的部署过程。
在部署dashboard的过程中,我遇到的主要问题就是在最后访问的dashboard页面的时候访问链接的协议应该是https而不是http,由于没注意到这个问题,dashboard的部署过程我有反复尝试了几次。
在dashboard之后便是online boutique项目的部署。在这过程中,我直接在部署的时候便启用了istio,然而在最后创建istio资源之后发现Service一直的外部访问IP一直处于peng的状态,经过查询需要安装并配置MetalLB负载均衡器,由它来为Service提供外部访问IP。但在安装配置完MetalLB之后发现,它提供的外部访问IP是一个内网地址,即无法通过本地笔记本电脑直接访问到,只能在云服务器的内网中用curl命令访问到网页,这显然与作业要求不符。后面又想到可以利用nginx进行反向代理,然而尝试修改了很多次nginx配置文件并重启nginx,依然无法访问到。最后无奈转而打算想在本地虚拟机中完成,因此我之后在本地配置了三台2核4GiB的虚拟机,并配置了前面所说的环境以及静态IP地址,然而在创建online boutique资源的时候始终无法创建成功,并提示虚拟机资源不足的问题。没有办法,最后还是继续研究尝试在服务器上配置nginx来提供访问,好在皇天不负有心人,我在一次查看dashboard页面的过程中注意到istio提供的service进行了端口映射,所以想到nginx配置中的监听端口是否不能随意指定,因此我修改了nginx中的配置文件中的监听端口,将其改为service的映射外部访问端口,然后重启nginx服务,这次修改使我终于可以访问到了online boutique项目。
但是事情并不总是一帆风顺。一天早晨当我想要继续完成大作业时,连上服务器后发现服务器的CPU以及内存使用全都变成了百分百,之前部署的项目也无法访问,试着重启了服务器还是无法改变,华为云官网的工作台显示入侵检测,于是猜测一手服务器被拉去挖矿了,之后尝试删除那个占用资源最多的进程也无济于事,看了网上一些方案也没什么效果,遂放弃。并想着再试试看虚拟机。这次我只配置了两台虚拟机,并给了其中一台虚拟机4核8GiB的配置,并重复上述过程,终于在本地配置成功。
整个大作业的完成过程使我在虚拟机和服务器间反复横跳,虽然操作繁琐反复,但也间接提高了我对项目的熟练度以及对于k8s相关知识的认识,所谓熟能生巧应该就是这样,但是不断的重复也难免会产生枯燥的感觉,希望自己以后的学习工作可以是既有重复的东西同时也不乏新鲜事物。
参考资料及演示视频
【云原生 • Kubernetes】认识 k8s、k8s 架构、核心概念点介绍_k8s宿主机系统一般是什么_敬 之的博客-CSDN博客
K8S架构原理及其工作流程_k8s工作流程_王大雏的博客-CSDN博客
istio简介和基础组件原理(服务网格Service Mesh)_腾讯数据架构师的博客-CSDN博客
(4) -- Jaeger,GRAFANA使用指引 - 简书
云原生的应用场景_云原生应用场景_wusefengye的博客-CSDN博客
https://www.cnblogs.com/renshengdezheli/p/16841875.html
https://www.cnblogs.com/renshengdezheli/p/16836943.html
【云原生-K8s】kubeadm搭建k8s集群v1.23版本【不成功手把手教学】_adm的脚本_rundreamsFly的博客-CSDN博客
K8S 安装 Dashboard_k8s 安装dashboard_tom.ma的博客-CSDN博客
Kuberntes部署MetalLB负载均衡器_freesharer的博客-CSDN博客
虚拟机设置静态IP地址_虚拟机配置静态ip_为你暴走的博客-CSDN博客
istio kiali jaeger 关联_shykevin的博客-CSDN博客
演示视频地址:https://download.csdn.net/download/qq_52666912/88677037
原文地址:https://blog.csdn.net/qq_52666912/article/details/131500751
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。