
一、前言
K8S集群中着这各类资源,比如计算资源,API资源等,其中最重要的是计算资源,包括CPU,缓存,存储等。管理这些资源就是要在资源创建时进行约束和限制,在运行时监控这些资源的指标,确保资源在高于或低于既定范围内,能自动伸缩,有序调度,使得整个集群健康可控。
本章重点讲述K8S如何进行计算资源的管理。
二、request和limit
我们之前在创建Pod时,都没有对容器的使用的CPU和Memory进行约束,容器对于这些计算资源的使用可以"随心所欲",但是K8S集群中每个节点的资源是有限的,一旦超额使用,有可能导致节点上其他Pod异常,乃至节点,甚至集群崩溃。
K8S对于Pod中每个容器通过设置Requet和Limit来进行限制。Requests表示容器申请时的最小需求量,Limits表示容器运行的最大限制量。其关系如下图所示,limit资源限制量要高于request资源限制量。

这里的资源包括 CPU和Memory,CPU的资源单位一般为m(毫核,1000毫核=1个核),Memory的资源单位为Mi,Gi等(1Mi=1024*1024B)。
1、Requests
Requests是申请时的最小值限制值,节点上的剩余资源需要满足Pod的Requests要求,才能被调度上来。如下图所示:

节点1的CPU和Memory可以满足Pod的Requests,节点2剩余的CPU满足Pod的Requests要求,但是Memory却不满足,所以该Pod可以被调度到节点1上,但无法调度到节点2上。
Requests的资源值是为K8S管理调度而服务的,一旦节点的所有Pod的Requests资源和,超过节点的总资源量,将不再有Pod调度到该节点,即使这些Pod在实际运行中,消耗的资源比申请时的要少。我们来看下面的实例。
一个节点资源总数,CPU为2个核,Memory为3Gi,其上已调度两个Pod运行,此时有个PodC需要调度,能否调度到该节点,其资源分析:
| request资源 | 使用资源 | |||
| CPU | Memory | CPU | Memory | |
| Pod A | 1 | 1.5 | 0.5 | 1 |
| Pod B | 0.5 | 0.5 | 0.1 | 0.3 |
| 当前总量 | 1.5 | 2 | 0.6 | 1.3 |
| Pod C | 1 | 1 | 1 | 1 |
| 调度后总量 | 2.5>2 | 3=3 | 1.6<2 | 2.3<3 |
答案是否定的,虽然从使用资源上,Pod C是可以调度到该节点后,但是调度时看的是Requests资源量,而非实际使用量。接下来,我们看下Requests的两个资源值定义.
(1)spec.container[].resources.requests.cpu
request的CPU是设置在container上的,一方面是服务于K8S的管理调度(如上面所说),另一方面,作为参数传给容器,用于定义时间比例。
在容器运行中,CPU的分配是按照时间分配的,而并不是实际的CPU个数。比如某个容器定义了200m,而该节点有2个核,如果其他的容器不负载,那么该容器是可以使用2核CPU的。
在多个容器产生CPU竞争时,CPU的时间是如何划分的呢?比如某个节点下有两个容器,分别申请200m,400m的CPU资源,那么就按照1:2的比例将CPU资源分配给这两个容器使用。
(2)spec.container[].resources.requests.memory
这个参数值只提供给Kubernetes调度器作为调度和管理的依据,不会作为任何参数传
[root@k8s-master yaml]# kubectl describe node k8s-node1
...
Allocatable:
cpu: 2
ephemeral-storage: 37986740981
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 3911712Ki
pods: 110
....
Resource Requests Limits
-------- -------- ------
cpu 350m (17%) 0 (0%)
memory 90Mi (2%) 0 (0%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-1Gi 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)k8s-node1节点一共2核4Mi(近似),已经用去了350m核,90Mi(注意,这是个Requests额度)。所以理论上还能申请的只有1650m核,以及3910Mi。
我们创建一个pod,使其request资源数超过剩余资源数(cpu为2000Mi),其yaml文件如下:
[root@k8s-master yaml]# cat request-nginx-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: request-nginx-pod
labels:
app: nginx-pod
spec:
containers:
- name: nginx
image: nginx:1.8
resources:
requests:
memory: "500Mi"
cpu: "2000m"我们执行下这个文件,并创建Pod
[root@k8s-master yaml]# kubectl apply -f request-nginx-pod.yaml
pod/request-nginx-pod created
[root@k8s-master yaml]# kubectl get pods
NAME READY STATUS RESTARTS AGE
request-nginx-pod 0/1 Pending 0 8s
[root@k8s-master yaml]# kubectl describe pod request-nginx-pod
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 55s (x2 over 77s) default-scheduler 0/2 nodes are available: 1 Insufficient cpu,1 node(s) had taint {node-role.kubernetes.io/master: },that the pod didn't tolerate.可以看到,两个node都无法满足,k8s-node1是因为CPU不满足要求(1 Insufficient cpu),而k8s-master是因为主节点,不满足调度容忍度要求。
我们修改下CPU的Requests值为500m核
[root@k8s-master yaml]# cat request-nginx-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: request-nginx-pod
labels:
app: request-nginx-pod
spec:
containers:
- name: nginx
image: nginx:1.8
resources:
requests:
memory: "500Mi"
cpu: "500m"再次执行后,正确调度并运行。
[root@k8s-master yaml]# kubectl get pod
NAME READY STATUS RESTARTS AGE
request-nginx-pod 1/1 Running 0 8m34s[root@k8s-master yaml]# kubectl describe node k8s-node1
...
Allocated resources:
(Total limits may be over 100 percent,i.e.,overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 850m (42%) 0 (0%)
memory 590Mi (15%) 0 (0%)
...此时的已用资源已经加上了刚才pod申请的资源。
2、limits
为了确保节点运行正常,K8S提供了 limits配置,limits可以认为是动态量最大值限制。与Requests类似,可以设置cpu和memory两个值。
(1)spec.container[].resources.limits.cpu
这里cpu最终会转化为容器的–cpu-period参数(一个周期内能运行的时间),它会与–cpu-period(一个周期时间)一起,决定在一个周期内,最多分配给该容器的运行时间。
(2)spec.container[].resources.limits.memory
该值会转化为容器的--memory参数,为内存的限制值,由于内存是不可压缩资源,一旦超标,就会导致容器kill或者重启,但是,不一定是当前的超标容器,这需要看容器的QoS等级。
3、Qos等级
在一个超卖的系统中,QoS等级决定着哪个容器第一个被杀掉,这样释放出的资源可以提供给高优先级的Pod使用。那如何判断谁的优先级高呢,K8S将容器划分为3个QoS等级,从高到低,分别为Guaranteed(完全可靠的)、Burstable(弹性波动、较可靠的)和BestEffort(尽力而为、不太可靠的).
(1)Guaranteed
Guaranteed这个等级是指, Pod中所有容器的资源都都定义了Limits和Requests,且所有容器的Limits值都和Requests值相等,需要注意的是,容器中仅定义Limits,没有定义Requests,那么Requests默认等于Limits。也是属于Guaranteed级别,如下面的例子
[root@k8s-master yaml]# cat guaranteed-ngnix-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: guaranteed-nginx-pod
labels:
app: guaranteed-nginx-pod
spec:
containers:
- name: nginx
image: nginx:1.8
resources:
requests:
memory: "50Mi"
cpu: "50m"
limits:
memory: "50Mi"
cpu: "50m"(2)BestEffort
[root@k8s-master yaml]# cat bestEffort-ngnix-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: bestEffort-nginx-pod
labels:
app: bestEffort-nginx-pod
spec:
containers:
- name: nginx
image: nginx:1.8(3)Burstable
除了以上两种状态,其他的都属于Burstable,这类的配置情况比较多,比如一部分容器都配置了Requests和Limits值,其Requests小于Limits值;一部分容器仅配置了Request值,另一部分容器仅配置了Limits值等等。如下面的例子:
[root@k8s-master yaml]# cat burstable-ngnix-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: burstable-nginx-pod
labels:
app: burstable-nginx-pod
spec:
containers:
- name: nginx
image: nginx:1.8
resources:
requests:
memory: "30Mi"
cpu: "30m"
limits:
memory: "50Mi"
cpu: "50m"(4)Qos的工作特点
Qos主要是针对不可压缩资源,也就是内存,当内存资源紧缺的情况下,会按照优先级从低到高,也就是BestEffort->Burstable->Guaranteed进行Pod的回收。
对于同一级别的Pod,计算内存实际使用量与内存申请量比例,比例高的会优先kill(与内存实际使用量绝对值没有关系)。如下图所示:
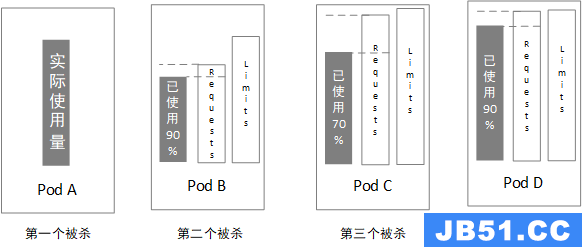
三、LimitRange
以上介绍,我们了解了Requests和Limits的作用,但是需要为每个Pod中的容器配置,其工作是相当繁琐的,一方面,默认的情况下,容器是没有配置的,对于重要容器的Qos无法得到保证,另一方面,容器资源配置没有限制,理论上可以配置整个节点的资源。为了解决这些问题,K8S提供了LimitRange准入控制器,以命名空间为维度,进行全局的限制。我们来创建一个LimitRange对象。
[root@k8s-master yaml]# cat limitrang-dev.yaml
apiVersion: v1
kind: LimitRange
metadata:
name: limitrang-dev
namespace: dev
spec:
limits:
- type: Pod # 对于Pod的资源限制定义
min: # Pod中所有容器的Requests值的总和下限
cpu: "100m"
memory: "50Mi"
max: # Pod中所有容器的Limits值的总和上限
cpu: "4"
memory: "4Gi"
maxLimitRequestRatio: #Pod中所有容器的Limits值与Requests值比例上限
cpu: 10
memory: 20
- type: Container # 对于Container的资源限制定义
default: # 容器没有指定limits值的默认值
cpu: "500m"
memory: "500Mi"
defaultRequest: # 容器没有指定Requests值的默认值
cpu: "100m"
memory: "50Mi"
max: # 容器中的Limits的上限值
cpu: "1"
memory: "1Gi"
min: # 容器中的Requests的下限值
cpu: "50m"
memory: "30Mi"
maxLimitRequestRatio: #容器的Limits值与Requests值比例上限
cpu: 10
memory: 20相关参数的意义,参见注释。limitRange可以对Pod和Container进行资源限制,Max是对limits值上限的限制,Min是对Requests值的下限限制,maxLimitRequestRatio是对Limits与Requests比例值的最大值的限制。除此之外,对于容器,还增加了default和defaultRequest属性,如果没有定义,则使用默认值。
执行该文件,创建 limitRange对象。
[root@k8s-master yaml]#
[root@k8s-master yaml]# kubectl apply -f limitrang-dev.yaml
limitrange/limitrang-dev created
[root@k8s-master yaml]# kubectl get limits --namespace=dev
NAME CREATED AT
limitrang-dev 2023-07-02T04:35:15Z下面我们分别来测试几种场景,看下limitRange是否能按照配置的进行准入限制。
1、不配置Requests和Llimits值
此种情况下,看下能否按照默认值进行配置,创建Pod的yaml文件,内容如下:
[root@k8s-master yaml]# cat limitrange-default-nginx-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: limitrange-default-nginx-pod
labels:
app: limitrange-default-nginx-pod
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.8创建完成后,看下Pod的详情
[root@k8s-master yaml]# kubectl describe pod limitrange-default-nginx-pod --namespace=dev
...
Containers:
nginx:
Container ID: docker://5a6e415f45125b8d824f73f081dc3ead845b21487537552b2b0cc23e015ffdca
Image: nginx:1.8
Image ID: docker-pullable://nginx@sha256:c97ee70c4048fe79765f7c2ec0931957c2898f47400128f4f3640d0ae5d60d10
Port: <none>
Host Port: <none>
State: Running
Started: Sun,02 Jul 2023 12:59:17 +0800
Ready: True
Restart Count: 0
Limits:
cpu: 500m
memory: 500Mi
Requests:
cpu: 100m
memory: 50Mi
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-5ckfr (ro)
....可以看到,正确的写入了limitRange的默认值。
2、创建超过限制资源配置的Pod
创建Pod,其yaml文件内容如下:
[root@k8s-master yaml]# cat limitrange-nok-nginx-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: limitrange-nok-nginx-pod
labels:
app: limitrange-nok-nginx-pod
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.8
resources:
requests:
memory: "30Mi"
cpu: "30m"
limits:
memory: "50Mi"
cpu: "50m"执行该文件,创建Pod
[root@k8s-master yaml]# kubectl apply -f limitrange-nok-nginx-pod.yaml
Error from server (Forbidden): error when creating "limitrange-nok-nginx-pod.yaml": pods "limitrange-nok-nginx-pod" is forbidden: [minimum cpu usage per Pod is 100m,but request is 30m,minimum memory usage per Pod is 50Mi,but request is 31457280,minimum cpu usage per Container is 50m,but request is 30m]可以看到,该Pod中只有一个容器,所以即违反了Pod总量最小值要求,又违反了容器对于cpu的最低要求,创建失败。
3、创建一个正常的Pod
创建Pod,其yaml内容如下:
[root@k8s-master yaml]# cat limitrange-ok-nginx-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: limitrange-ok-nginx-pod
labels:
app: limitrange-ok-nginx-pod
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.8
resources:
requests:
memory: "50Mi"
cpu: "100m"
limits:
memory: "500Mi"
cpu: "500m"执行该文件,创建Pod
[root@k8s-master yaml]# kubectl apply -f limitrange-ok-nginx-pod.yaml
pod/limitrange-ok-nginx-pod created
[root@k8s-master yaml]# kubectl describe pod limitrange-ok-nginx-pod --namespace=dev
...
Restart Count: 0
Limits:
cpu: 500m
memory: 500Mi
Requests:
cpu: 100m
memory: 50Mi
...可以看到,Pod创建成功。
四、ResourceQuota
通过limitRange可以实现在命名空间下,对于每个Pod和以及Pod下每个容器的资源限制,但是无法限制所有Pod的资源总额,在实际工程中,在同一集群中,给予不同命名空间(不同业务)的总资源是需要约束的,否则容器出现资源被某类业务独占,其他业务无法申请的情况。limitRange与ResourceQuota的关系如下图所示:

创建ResourceQuota对象,其yaml如下:
[root@k8s-master yaml]# cat resourcequota-dev.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: resourcequota-resource-dev
namespace: dev
spec:
hard:
requests.cpu: 200m
requests.memory: 200Mi
limits.cpu: 400m
limits.memory: 400Mi这里定义了在namespace:dev下,Requests以及Limits的cpu和memory总和。
我们先删除dev命名空间下所有的pod,再执行该文件。
[root@k8s-master yaml]# kubectl apply -f resourcequota-dev.yaml
resourcequota/resourcequota-resource-dev created
[root@k8s-master yaml]# kubectl get resourcequota --namespace=dev
NAME AGE REQUEST LIMIT
resourcequota-resource-dev 41s requests.cpu: 0/200m,requests.memory: 0/200Mi limits.cpu: 0/400m,limits.memory: 0/400Mi我们再来创建 前一章节的limitrange-ok-nginx-pod,看下能否创建成功
[root@k8s-master yaml]# kubectl apply -f limitrange-ok-nginx-pod.yaml
Error from server (Forbidden): error when creating "limitrange-ok-nginx-pod.yaml": pods "limitrange-ok-nginx-pod" is forbidden: exceeded quota: resourcequota-resource-dev,requested: limits.cpu=500m,limits.memory=500Mi,used: limits.cpu=0,limits.memory=0,limited: limits.cpu=400m,limits.memory=400Mi因为在resourcequota中定义了limits的cpu和memory总和分别为400m和400Mi,但是在limitrange-ok-nginx-pod中配置limit资源分别为500m和500Mi,这样就超过了总和的限制,导致创建失败。
ResourceQuota除了限制计算资源总和,还可以限制对象资源的个数,主要包括:
- Pod
- ReplicationController
- Secret
- ConfigMap
- Persistent Volumn Clain
- Service
接下来,我们在创建一个限制对象资源总和的ResourceQuota的例子,其yaml内容如下:
[root@k8s-master yaml]# cat resourcequota-object-dev.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: resourcequota-object-dev
namespace: dev
spec:
hard:
pods: 2
services: 5大家感兴趣,可以自行完成对象资源的验证。
五、总结
本篇主要介绍了K8S对于计算资源的管理,主要是针对CPU和Memory资源。
Requests和Limits作为资源管理最基本两个设置,Requests是容器申请时最小限制,主要用于K8S在Pod调度时,节点的剩余资源能否满足Pod的要求。Limits是容器运行时的最大限制,主要控制Pod运行时,对于资源超额使用的限制,一旦超过Limits定义的量,就有可能引起Pod的kill或者重启。
K8S将Pod划分为三个QoS等级,优先级从高到低分别为Guaranteed、Burstable和BestEffort。一旦资源超卖,就会从低到高选择Pod进行kill,将资源保障给高优先级的Pod。
LimitRange是以命名空间的维度,对Pod进行统一配置限制值和默认值,从而避免逐个配置Pod的繁琐。
ResourceQuota是以命名空间的维度,对于资源总额进行限制。
附:
K8S初级入门系列之四-Namespace/ConfigMap/Secret
K8S初级入门系列之六-控制器(RC/RS/Deployment)
K8S初级入门系列之七-控制器(Job/CronJob/Daemonset)
原文地址:https://blog.csdn.net/tcy83/article/details/131263353
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。