
Kuboard 是Kubernetes 多集群管理工具,是一个界面化的web网站,使用起来非常方便。在Kuboard中可以导入集群,在kuboard上可以完成很多的运维工作,比如创建命名空间、创建标签、运行服务、修改pod数量等等。
一:kuboard的版本说明
Kuboard目前已经发展到了v3.x版本了。Kuboard v3.x 支持 amd64 (x86) 架构和 arm68 (armv8) 架构的 CPU
兼容性

二:kuboard的安装
kuboard 官方推荐在 K8S 中安装 Kuboard,并且使用 hostPath 提供持久化存储,将 kuboard 所依赖的 Etcd 部署到 Master 节点,并将 etcd 的数据目录映射到 Master 节点的本地目录。
使用 hostPath 提供持久化
1、在安装etcd节点添加 k8s.kuboard.cn/role=etcd 的标签,来增加 kuboard-etcd 的实例数量
执行如下指令,可以为 your-node-name 节点添加所需要的标签
kubectl label nodes your-node-name k8s.kuboard.cn/role=etcd
2、在线安装,当你的集群可以连接外网的时候,可以用,非常方便,只要在master1上执行下面的命令:
kubectl apply -f https://addons.kuboard.cn/kuboard/kuboard-v3.yaml
如果要卸载:
kubectl delete -f https://addons.kuboard.cn/kuboard/kuboard-v3.yaml
3、如果是集群没有外网需要离线安装
在您的镜像仓库服务中创建一个名为 kuboard 的 repository(harbor 中称之为项目、华为镜像仓库中称之为组织)
输入您镜像仓库地址及 repository 名称(替换输入框中 registry.mycompayn.com 为你的镜像仓库服务地址即可):registry.mycompany.com/kuboard
将所需镜像导入到您的私有镜像仓库
docker pull eipwork/kuboard-agent:v3
docker pull eipwork/etcd-host:3.4.16-1
docker pull eipwork/kuboard:v3
docker pull questdb/questdb:6.0.4
docker tag eipwork/kuboard-agent:v3 registry.mycompany.com/kuboard/kuboard-agent:v3
docker tag eipwork/etcd-host:3.4.16-1 registry.mycompany.com/kuboard/etcd-host:3.4.16-1
docker tag eipwork/kuboard:v3 registry.mycompany.com/kuboard/kuboard:v3
docker tag questdb/questdb:6.0.4 registry.mycompany.com/kuboard/questdb:6.0.4
docker push registry.mycompany.com/kuboard/kuboard-agent:v3
docker push registry.mycompany.com/kuboard/etcd-host:3.4.16-1
docker push registry.mycompany.com/kuboard/kuboard:v3
docker push registry.mycompany.com/kuboard/questdb:6.0.4
在您的镜像仓库设置导入的镜像为公开可访问(无需镜像仓库的用户名密码)
获取 YAML 文件,并将该文件保存到集群 master 节点(或者 kubectl 客户端所在机器,假设文件名为 kuboard-v3.yaml)
执行安装指令:
kubectl apply -f kuboard-v3.yaml
获取yaml文件,可以从官网上获取:https://kuboard.cn/install/v3/install-in-k8s.html#%E5%AE%89%E8%A3%85
如果要卸载:
kubectl delete -f kuboard-v3.yaml
清理遗留数据:
在 master 节点以及带有 k8s.kuboard.cn/role=etcd 标签的节点上执行
rm -rf /usr/share/kuboard
访问 Kuboard
在浏览器中打开链接: http://your-node-ip-address:30080
输入初始用户名和密码,并登录
用户名: admin
密码: Kuboard123
三:kuboard使用
登录kuboard后的第一件是就是导入集群,根据提示进行操作
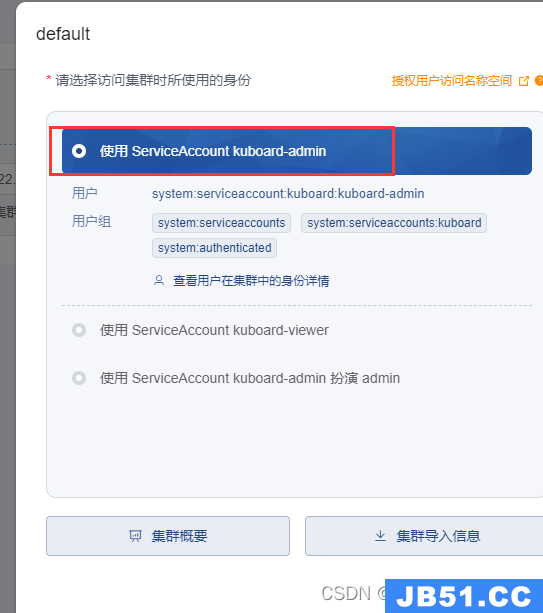
选择使用ServiceAccount kuboard-admin.
集群导入成功后是这样的:
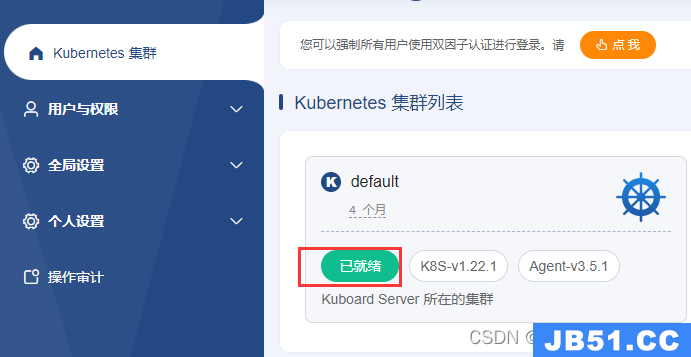
会显示已就绪。
1、名称空间的使用:
名称空间的用途是,为不同团队的用户(或项目)提供虚拟的集群空间,也可以用来区分开发环境/测试环境、准上线环境/生产环境。
名称空间为 名称 提供了作用域。名称空间内部的同类型对象不能重名,但是跨名称空间可以有同名同类型对象。名称空间不可以嵌套,任何一个Kubernetes对象只能在一个名称空间中。
名称空间可以用来在不同的团队(用户)之间划分集群的资源
比如我有一个项目我可以创建一个名称空间名为 minispace
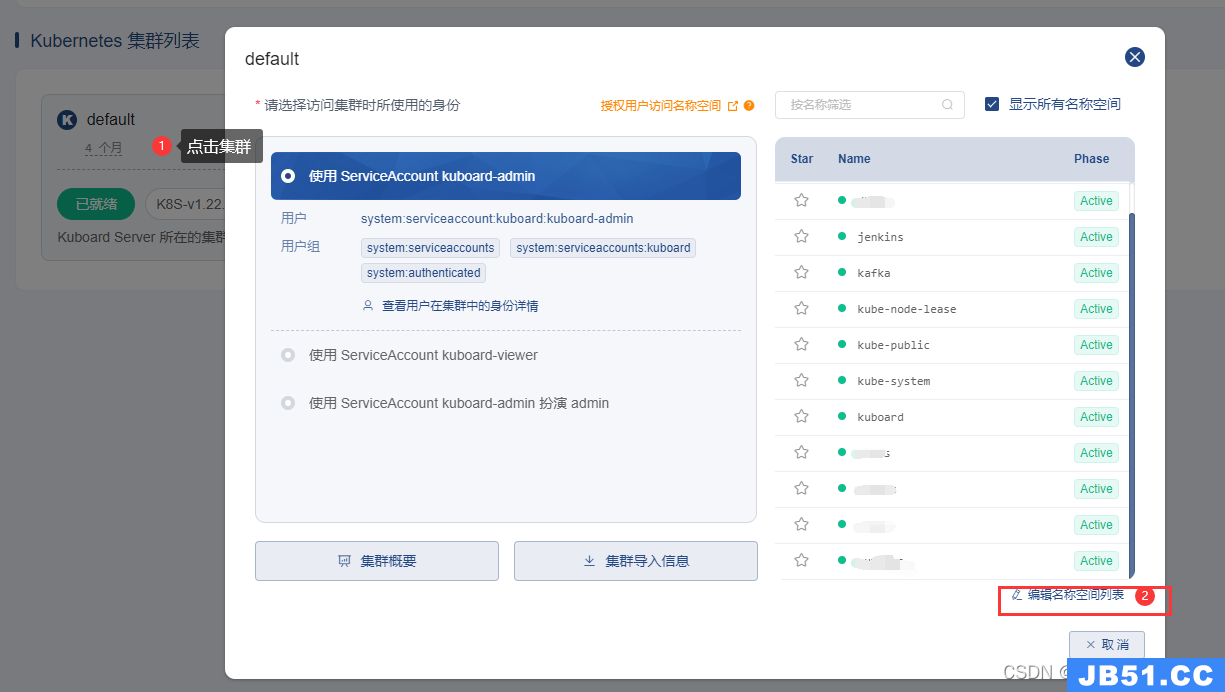
点击创建


2、发布一个java的服务
1)、进入对应的名称空间,点击创建工作负载。

2)、填写基本信息
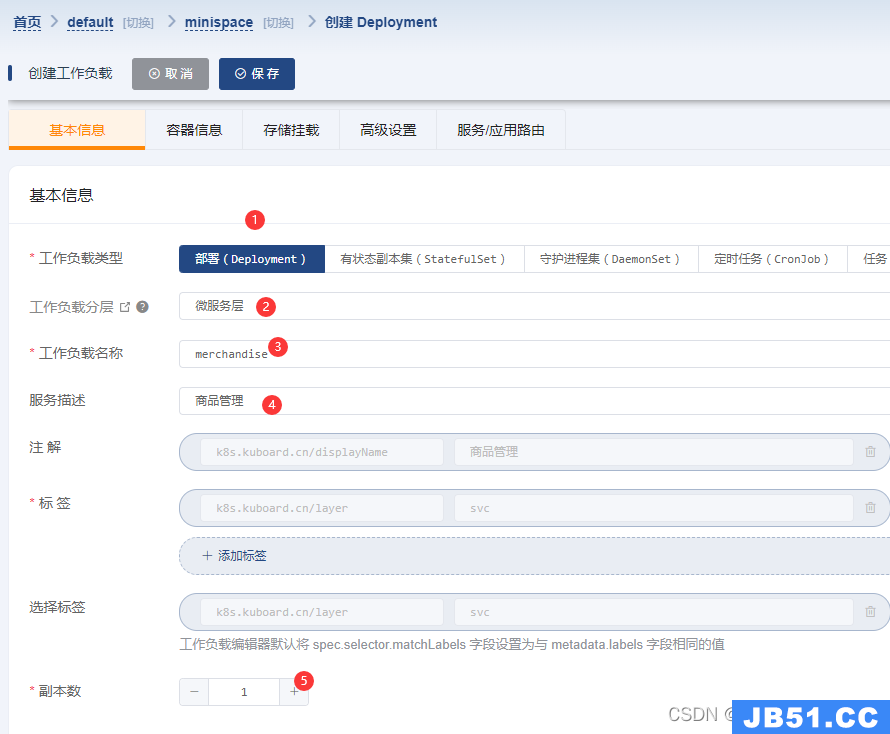
1、负载类型: deployment
2、工作负载分层: 根据需要选择,一般的服务就选微服务层
3、工作负载名称:必须是全英文切小写,一个名称空间内要唯一
4、服务描述:对这个服务的描述,方便查看
5、副本数: 就是控制pod数量的,根据集群资源和自己的要求配置
3)、容器信息填写
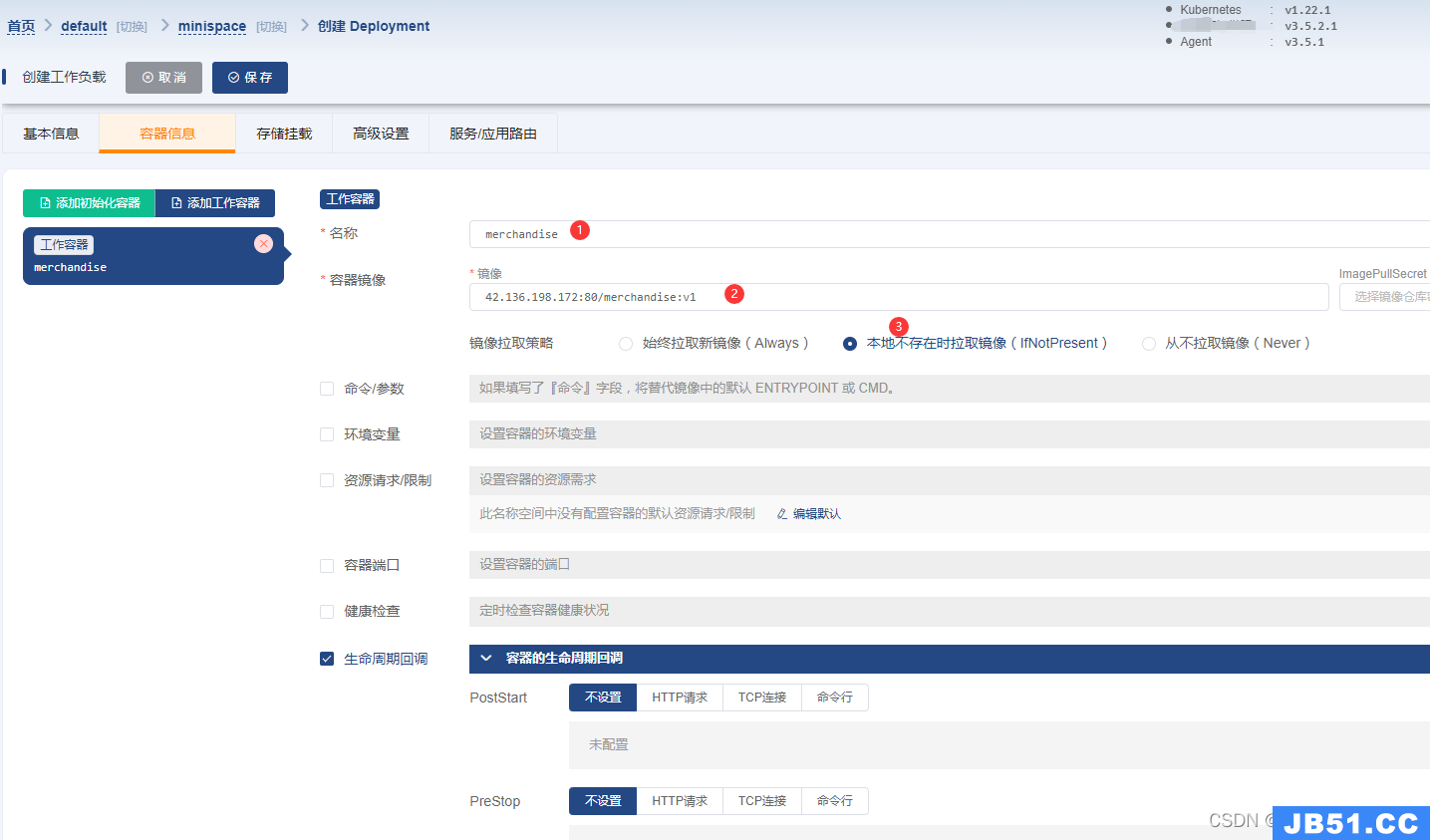
创建的容器名称
容器的镜像地址,自己的镜像要事先上传到镜像仓库。
镜像拉取策略:如果镜像就在当前的这台服务器上,就可以选择从不拉取,如果镜像在仓库,就选择always 或者是Ifnotpresent.
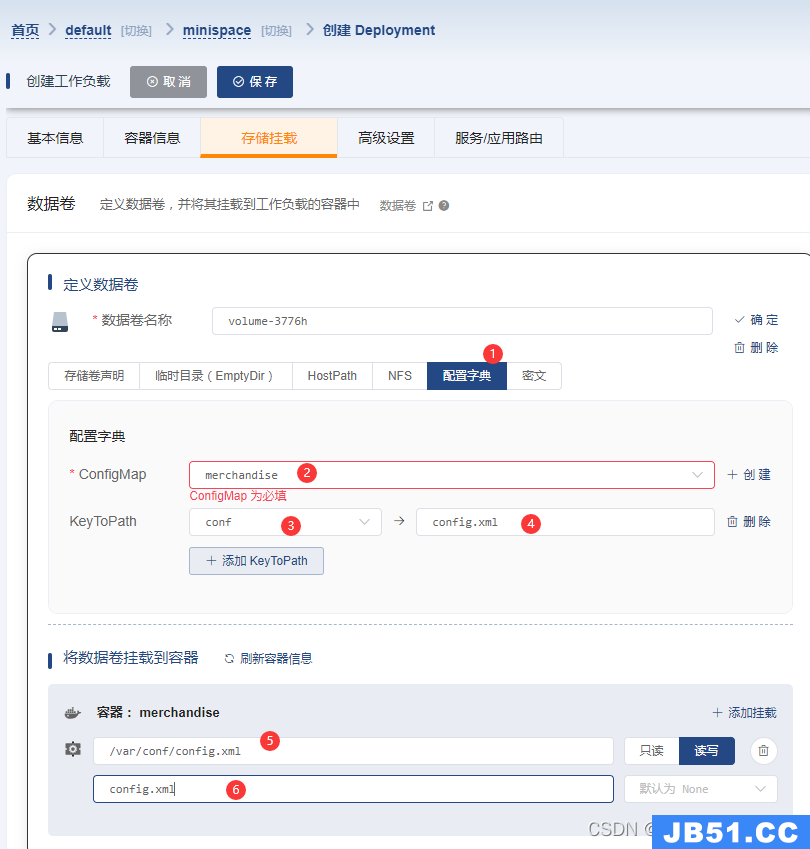
4)、存储挂载
比如有配置文件,或者日志文件都可以配置到这里,可以把容器内的文件映射到宿主机
比如有一个配置文件可以在配置中心先配置了,在这里挂载,根据自己存储卷的不同类型选择。
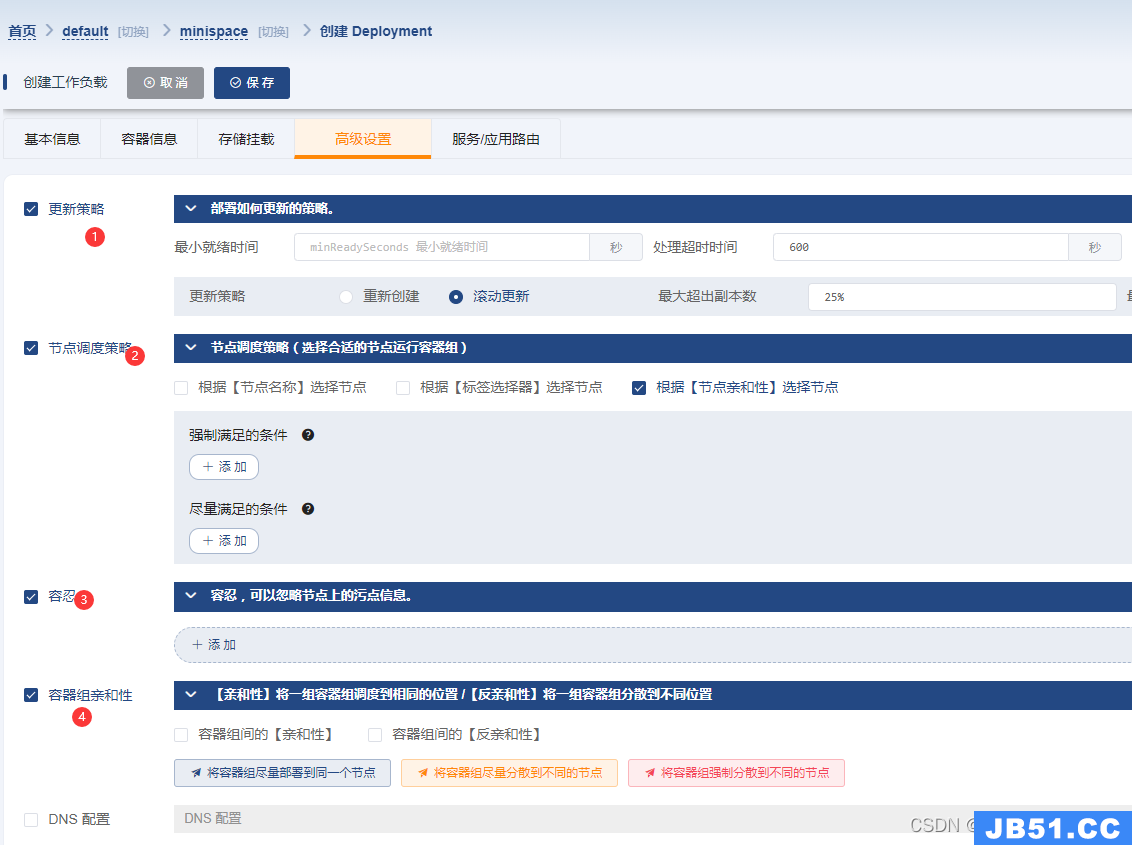
5)、高级设置
6)服务与应用
如果没有对外的暴露端口就不需要设置。
这样一个服务就发布好了。
原文地址:https://blog.csdn.net/javascript_good/article/details/131530461
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。