
k8s环境规划:
podSubnet(pod网段) 10.244.0.0/16
serviceSubnet(service网段): 10.96.0.0/12
实验环境规划:
操作系统:银河麒麟V10 SP2(X86_64)
配置: 4Gib内存/2vCPU/20G硬盘
网络:NAT模式
| K8S集群角色 |
IP |
主机名 |
安装的组件 |
| 控制节点1 |
192.168.153.221 |
master01 |
apiserver、controller-manager、schedule、kubelet、etcd、kube-proxy、容器运行时、calico、kuboard |
| 控制节点2 |
192.168.153.222 |
master02 |
apiserver、controller-manager、schedule、kubelet、etcd、kube-proxy、容器运行时、calico |
| 工作节点1 |
192.168.153.224 |
node01 |
Kube-proxy、calico、coredns、容器运行时、kubelet |
1 基础配置(所有节点都需要操作,以下只演示master01节点的操作)
1.1 初始化安装k8s集群的实验环境
1.1.1 修改机器IP,变成静态IP
vim /etc/sysconfig/network-scripts/ifcfg-ens160TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=static
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ens160
UUID=bce6accf-8e67-4c69-b896-282c1c96d5ef
DEVICE=ens160
ONBOOT=yes
IPADDR=192.168.153.221
NETMASK=255.255.255.0
GATEWAY=192.168.153.2
DNS1=192.168.153.2修改配置文件之后需要重启网络服务才能使配置生效,重启网络服务命令如下:
systemctl restart network1.1.2 关闭selinux,所有k8s机器均操作
sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config临时生效
setenforce 0登录到机器,执行如下命令:
getenforce如果显示Disabled说明selinux已经关闭

1.1.3 配置机器主机名
在192.168.153.221上执行如下:
hostnamectl set-hostname master01在192.168.153.222上执行如下:
hostnamectl set-hostname master02在192.168.153.224上执行如下:
hostnamectl set-hostname node011.1.4 配置主机hosts文件,相互之间通过主机名互相访问
修改每台机器的/etc/hosts文件,文件最后增加如下内容:
vim /etc/hosts
192.168.153.221 master01
192.168.153.222 master02
192.168.153.224 node01
1.1.5 配置主机之间无密码登录
配置master01到其他机器免密登录(其他机器同理)
ssh-keygen #一路回车,不输入密码
把本地生成的密钥文件和私钥文件拷贝到远程主机
ssh-copy-id master02
1.1.6 关闭交换分区swap,提升性能
临时关闭
swapoff -a
永久关闭:注释swap挂载,给swap这行开头加一下注释
vim /etc/fstab
#/dev/mapper/swap swap swap defaults 0 0问题1:为什么要关闭swap交换分区?
swap是交换分区,如果机器内存不够,会使用swap分区,但是swap分区的性能较低,k8s设计的时候为了能提升性能,默认是不允许使用交换分区的。Kubeadm初始化的时候会检测swap是否关闭,如果没关闭,那就初始化失败。如果不想要关闭交换分区,安装k8s的时候可以指定--ignore-preflight-errors=Swap来解决。
1.1.7 修改机器内核参数
modprobe br_netfilter
cat > /etc/sysctl.d/k8s.conf <<EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
EOF
sysctl -p /etc/sysctl.d/k8s.conf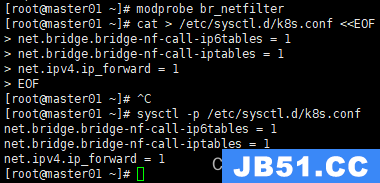
1.1.8 关闭firewalld防火墙
systemctl stop firewalld
systemctl disable firewalld1.1.9 配置时间同步
安装ntpdate命令
yum install ntpdate -y配置时间同步
vim /etc/ntp.conf
#在最后添加一行,其他节点则添加主节点的ip
server 127.127.1.0 #本地时钟源启动ntp服务,并配置开机启动
systemctl start ntpd
systemctl enable ntpd.service检查是否设置成功
ntpq -p把时间同步做成计划任务
crontab -e
0-59/30 * * * * /usr/sbin/ntpdate 192.168.153.221 && /sbin/hwclock -w重启crond服务
systemctl restart crond1.1.10 配置ipvs功能
在kubernetes中service有两种代理模型,一种是基于iptables的,一种是基于ipvs的,两者比较的话,ipvs的性能明显要高一些,但是如果要使用它,需要手动载入ipvs模块。麒麟系统自带了Ipset,因此安装ipvsadm:将rpm包导入到服务器中。
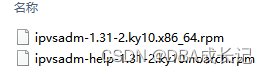
rpm -ivh ipvsadm-help-1.31-2.ky10.noarch.rpm
rpm -ivh ipvsadm-1.31-2.ky10.x86_64.rpm
添加需要加载的模块写入脚本文件:
cat <<EOF > /etc/sysconfig/modules/ipvs.modules
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack
EOF
为脚本文件添加执行权限:
chmod +x /etc/sysconfig/modules/ipvs.modules执行脚本文件:
/bin/bash /etc/sysconfig/modules/ipvs.modules查看对应的模块是否加载成功:
lsmod | grep -e ip_vs -e nf_conntrack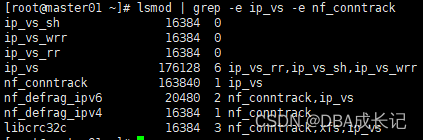
1.1.11 安装docker
下载docker包,选择自己合适的版本,我下载的是20.10.7,导入到服务器中,解压docker并赋执行权限
tar -zxvf docker-20.10.7.tgz
chmod +x ./docker/*
将docker文件夹下的所有可执行文件复制到/usr/bin/下面
cp docker/* /usr/bin/编辑docker的系统服务文件
vi /usr/lib/systemd/system/docker.service
[Unit]
Description=Docker Application Container Engine
Documentation=https://docs.docker.com
After=network-online.target firewalld.service
Wants=network-online.target
[Service]
Type=notify
ExecStart=/usr/bin/dockerd
ExecReload=/bin/kill -s HUP $MAINPID
LimitNOFILE=infinity
LimitNPROC=infinity
TimeoutStartSec=0
Delegate=yes
KillMode=process
Restart=on-failure
StartLimitBurst=3
StartLimitInterval=60s
[Install]
WantedBy=multi-user.target为docker.service添加执行权限
chmod +x /usr/lib/systemd/system/docker.service编辑daemon.json
mkdir /etc/docker
vi /etc/docker/daemon.json
{
"registry-mirrors": ["https://registry.docker-cn.com"],"exec-opts": ["native.cgroupdriver=cgroupfs"]
}并执行:
systemctl daemon-reload
#启动docker
systemctl start docker
#开机自启动
systemctl enable docker
#查看docker版本
docker -v
1.1.11 安装初始化k8s需要的软件包
直接安装可能会提示缺少conntrack和socat依赖项,需要先安装k8s-dependency下的包
mkdir k8s_rpm && cd k8s_rpm导入所有依赖包
rpm -ivh *.rpm --nodeps --force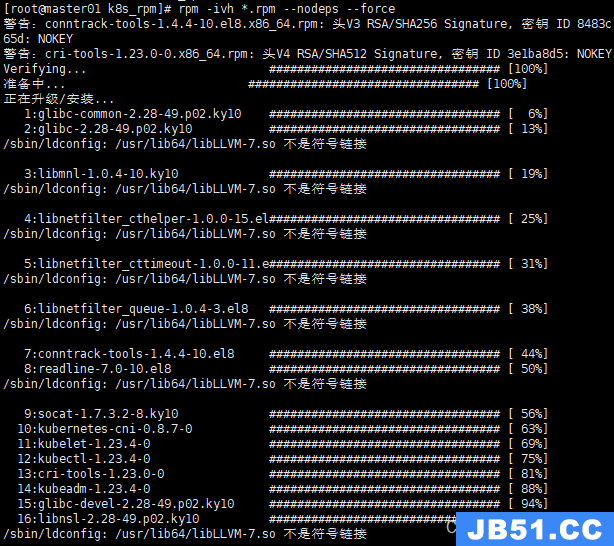
配置kubelet的cgroup
vim /etc/sysconfig/kubelet
KUBELET_EXTRA_ARGS="--cgroup-driver=cgroupfs"
KUBE_PROXY_MODE="ipvs"设置kubelet开机自启
systemctl enable kubelet1.1.12 准备镜像(k8s组件及网络插件calico及界面管理工具kuboard)
导入并加载k8s集群镜像:k8s_1.23.4.tar.gz
docker load -i k8s_1.23.4.tar.gz
docker images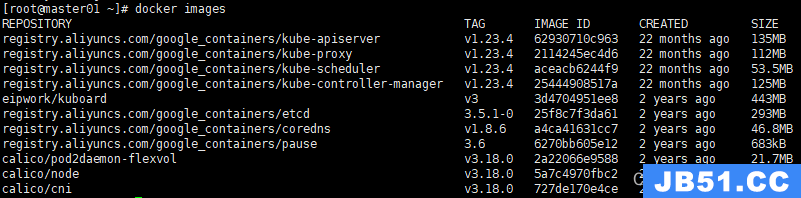
2 创建集群(仅在master01上操作)
2.1 初始化集群
kubeadm init \
--apiserver-advertise-address=192.168.153.221 \
--image-repository registry.aliyuncs.com/google_containers \
--kubernetes-version v1.23.4 \
--service-cidr=10.96.0.0/12 \
--pod-network-cidr=10.244.0.0/16 \
--ignore-preflight-errors=all显示如下,说明安装完成:

配置kubectl的配置文件config,相当于对kubectl进行授权,这样kubectl命令可以使用这个证书对k8s集群进行管理
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
export KUBECONFIG=/etc/kubernetes/admin.conf2.2 扩容k8s集群-添加第一个工作节点
在master01上查看加入节点的命令:
kubeadm token create --print-join-command把node01加入k8s集群:
kubeadm join 192.168.153.221:6443 --token x508ks.jb209tvtclc8iprk \
--discovery-token-ca-cert-hash sha256:f98fbc58e6765a72b68e1d88344922cefdc0c05e1d9fee8b5db1bc77d1f61f8f看到下图说明node01节点已经加入到集群了,充当工作节点

在master01上查看集群节点状况:
kubectl get nodes
可以对node01打个标签,显示work
kubectl label nodes node01 node-role.kubernetes.io/work=work
kubectl get nodes
2.3 安装kubernetes网络组件-Calico
上传calico.yaml到master01上,使用yaml文件安装calico网络插件:
kubectl apply -f calico.yaml
kubectl get pod --all-namespaces -o wide
2.4 扩容k8s集群,添加第二个控制节点
【把master02加入到K8s集群】
在master02创建证书存放目录:
cd /root && mkdir -p /etc/kubernetes/pki/etcd &&mkdir -p ~/.kube/把master01节点的证书拷贝到master02上:
scp /etc/kubernetes/pki/ca.crt master02:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/ca.key master02:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/sa.key master02:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/sa.pub master02:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/front-proxy-ca.crt master02:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/front-proxy-ca.key master02:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/etcd/ca.crt master02:/etc/kubernetes/pki/etcd/
scp /etc/kubernetes/pki/etcd/ca.key master02:/etc/kubernetes/pki/etcd/检查 kubeadm-config ConfigMap 是否正确配置了 controlPlaneEndpoint。可以使用 kubectl 命令获取 kubeadm-config ConfigMap 的信息,在master01上执行:
kubectl -n kube-system edit cm kubeadm-config -o yaml
#添加如下字段:
controlPlaneEndpoint: "192.168.153.221:6443"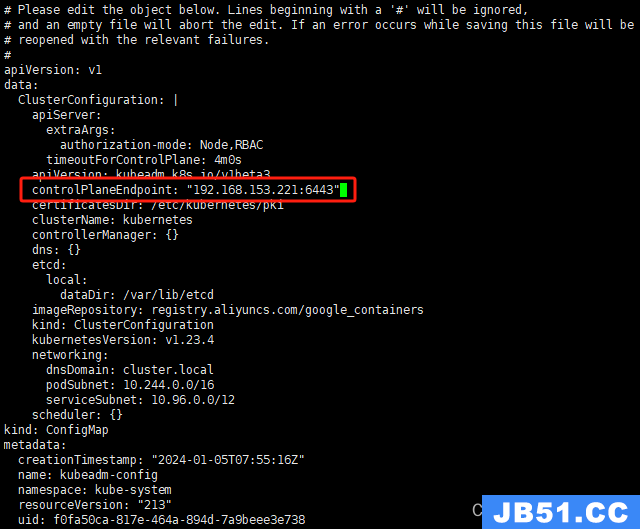
重启kubelet:
systemctl restart kubelet在master01上查看加入节点的命令:
kubeadm token create --print-join-command
#显示如下:
kubeadm join 192.168.153.221:6443 --token hs57tn.1emods9ktxcplulv --discovery-token-ca-cert-hash sha256:f98fbc58e6765a72b68e1d88344922cefdc0c05e1d9fee8b5db1bc77d1f61f8f在master02上执行该命令:
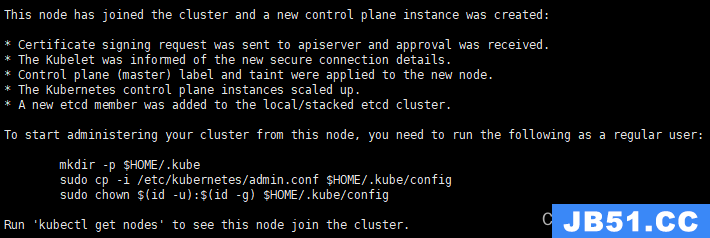
kubeadm join 192.168.153.221:6443 --token hs57tn.1emods9ktxcplulv --discovery-token-ca-cert-hash sha256:f98fbc58e6765a72b68e1d88344922cefdc0c05e1d9fee8b5db1bc77d1f61f8f --control-plane --ignore-preflight-errors=SystemVerification看到下图说明master02节点已经加入到集群了,充当控制节点
配置kubectl的配置文件config,相当于对kubectl进行授权,这样kubectl命令可以使用这个证书对k8s集群进行管理
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config在master01上查看集群状况,可以看到master02已经加入到集群了
kubectl get nodes
3 安装界面化管理工具
上传kuboard.sh到服务器中,执行以下命令:
sh kuboard.sh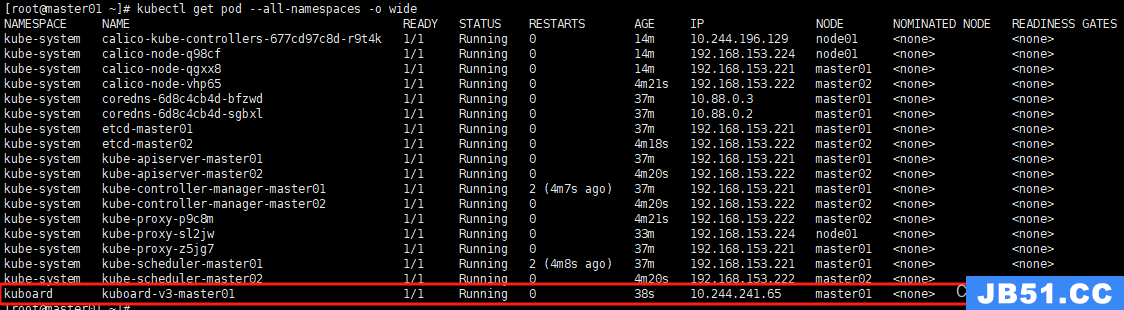
访问http://192.168.153.221:80
用户名:admin
密码:Kuboard123
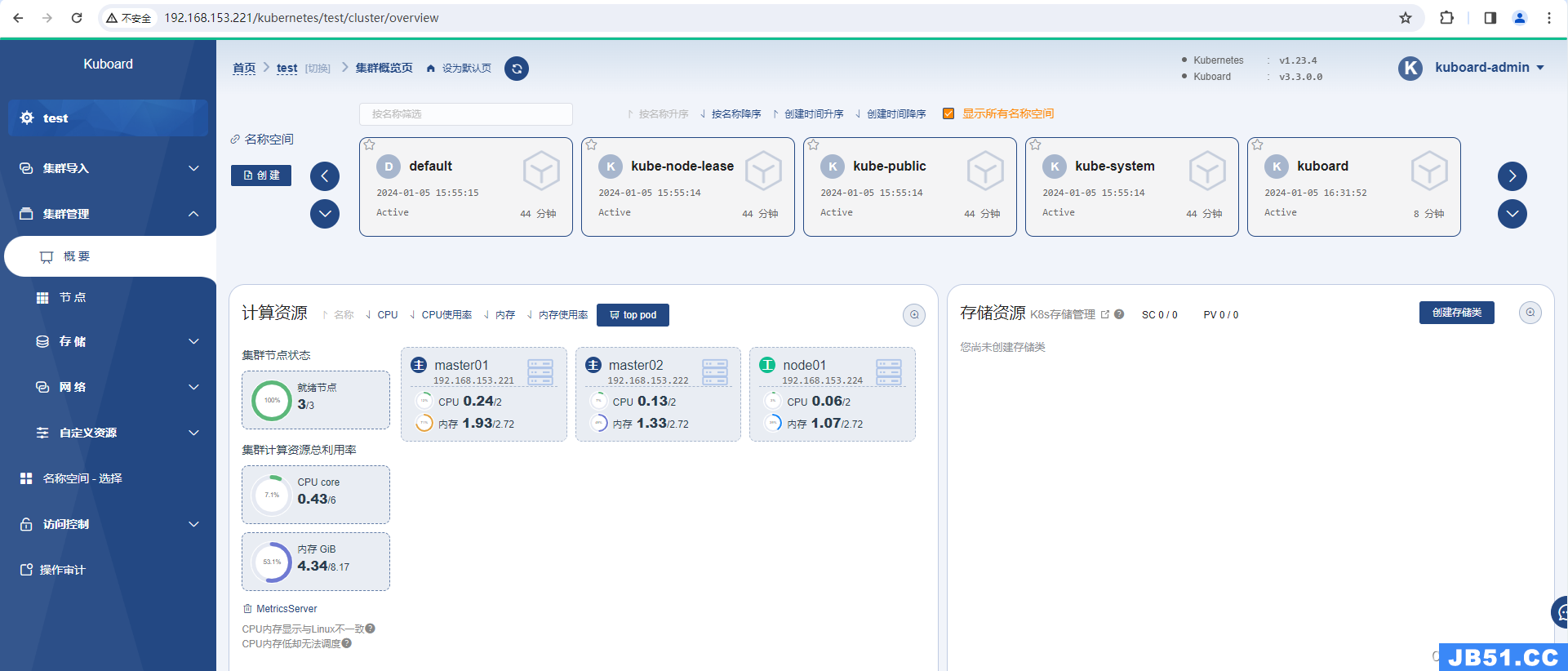
按照提示进行添加集群和安装metrics-server,到此集群部署完成。
总结:k8s离线部署也是趟了n多坑,至今还会遇到各种问题,希望可以和谐的与大家共同探讨、学习与进步,可以正确安装的话希望可以点个赞,非常感谢!
如果需要上述的安装包的话,请移步:
https://download.csdn.net/download/qq_41642843/88716565
PS: 需要的人多的话,每个人都发邮箱实在有些麻烦,我有点懒,不介意的话可以用几个积分下载一下。
原文地址:https://blog.csdn.net/qq_41642843/article/details/135454656
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。