
文章目录
CRD 概述
CR(Custom Resource)其实就是在 Kubernetes 中定义一个自己的资源类型,是一个具体的 “自定义 API 资源” 实例,为了能够让 Kubernetes 认识这个 CR,就需要让 Kubernetes 明白这个 CR 的宏观定义是什么,也就是需要创建所谓的 CRD(Custom Resource Definition)来表述。
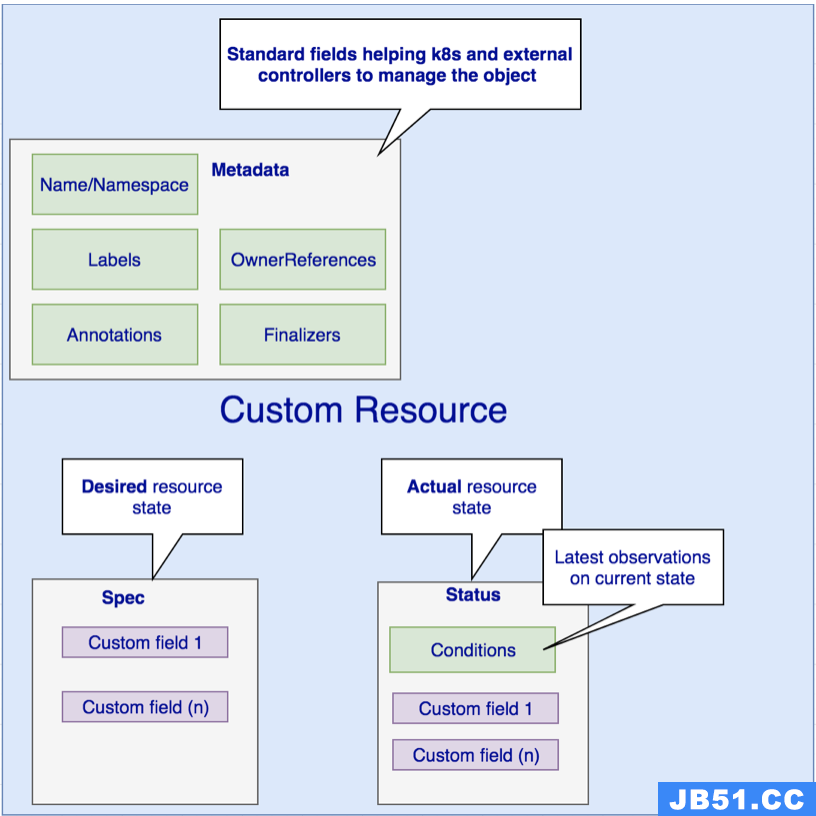
可能这么说并不是太直观,换个方式表达一下,我们想要创建一个 Pod 的时候,那么会编写一个 YAML 配置,然后前两行一般会这么写:
[root@liqiang.io]# head -2 pod.yaml
apiVersion: v1
kind: Pod
这里的 Resource 就是 Pod,我们可以它通过在 Kubernetes 中创建一个真实的 Pod,但是这个 Pod 要运行哪些 Container?这些 Container 我们要怎么在 pod.yaml 中定义,这个要怎么知道呢?这就需要有个描述文件用来定义 Pod 这个 Resource 需要具有哪些属性,这些属性的类型是什么,结构是怎样的,这个描述文件就是所谓的 CRD。
CR 是 Custom Resource 的缩写,它实际是 CRD 的一个实例。因此删除的时候,
先删除 全部的的cr,才能删除crd。
当然,Pod 作为一个内置资源,是没有这种所谓的 CRD 的,这里是作为一个介绍,当我们要创建一个非内置资源的时候,就需要有这么一个叫做 CRD 的描述文件了。
1. 操作CRD
1.1 创建 CRD
在 Kubernetes 中,CRD 本身也是一种资源,它是 Kubernetes 内部 apiextensions-apiserver 提供的 API Group:apiextensions.k8s.io/v1,注意,这里是 v1 版本,在 Kubernetes 1.16 版本中,CRD 转正了,成为了正式版本 CRD GA,但是,在 v1.16 之前以及 v1.7 以及之后,都是以 v1beta1 的版本存在,所以在编写的时候注意一下你的 Kubernetes 版本。
自己定义一个 CRD 也需要编写 YAML 文件,这里是我的一个示例,我通过这个 CRD 来定义我的网站 liqiang.io 的管理员的 CR,当我想添加一个管理员的时候,只需要直接添加一个 CR 就可以了:
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
name: admins.admin.liqiang.io
spec:
group: admin.liqiang.io
names:
kind: Admin
plural: admins
scope: Namespaced
versions:
- name: v1
served: true
storage: true
schema:
openAPIV3Schema:
description: Admin define the admin user for liqiang.io website.
type: object
properties:
spec:
type: object
properties:
username:
type: string
password:
type: string
email:
type: string
-
apiVersion 就是指 CRD 的一个 apiVersion 声明,声明它是一个 CRD 的需求或者说定义的 Schema。
-
kind 就是
CustomResourcesDefinition,指 CRD。 -
metadata.name是一个用户自定义资源中自己自定义的一个名字。一般我们建议使用“顶级域名.xxx.APIGroup”这样的格式,比如这里就是 admins.admin.liqiang.io,APIGroup对应spec.group标签,值为 “admin.liqiang.io” 。 -
spec 用于指定该 CRD 的 group、version。比如在创建 Pod 或者 Deployment 时,它的 group 可能为 apps/v1 或者 apps/v1beta1 之类,这里我们也同样需要去定义 CRD 的 group。
- 图中的 group 为 admin.liqiang.io;
- verison 为 v1alpha1;
- names 指的是它的 kind 是什么,比如 Deployment 的 kind 就是 Deployment,Pod 的 kind 就是 Pod,这里的 kind 被定义为了 Foo;
- plural 字段就是一个昵称,比如当一些字段或者一些资源的名字比较长时,可以用该字段自定义一些昵称来简化它的长度;
- scope 字段表明该 CRD 是否被命名空间管理。比如 ClusterRoleBinding 就是 Cluster 级别的。再比如 Pod、Deployment 可以被创建到不同的命名空间里,那么它们的 scope 就是 Namespaced 的。这里的 CRD 就是 Namespaced 的。
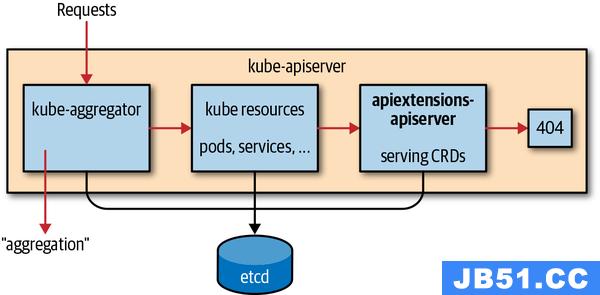
当写完这个 CRD 的描述文件之后,可以直接通过 kubectl apply 00-admin-crd.yaml 在 Kubernetes 集群中注册 CRD 对象。然后 Kubernetes 中的 kube-apiserver 组件中运行的 apiextensions-apiserver 就会检查对应 CRD 的名字是否合法之类的,当一切检查都 OK 之后,那么就会返回给你创建成功的状态了:
[root@liqiang.io]# kubectl apply -f 00-admin-crd.yaml
customresourcedefinition.apiextensions.k8s.io/admins.admin.liqiang.io created
k get crds
NAME CREATED AT
admins.admin.liqiang.io 2019-11-23T06:52:23Z
内部的流程是这样的:
1.2 操作 CRD
现在在 Kubernetes 中已经多了一种新的资源叫做 admins.admin.liqiang.io,可以使用它来定义系统的管理员了,这里我就添加一个:

记得,需要 apply 一下:
[root@liqiang.io]# kubectl apply -f 01-admin-cr.yaml
admin.admin.liqiang.io/liuliqiang created
[root@liqiang.io]# kubectl get admins.admin.liqiang.io
NAME AGE
liuliqiang 117s
现在就创建成功了。然后,不要了,那就删除掉,删除也是很简单的:
[root@liqiang.io]# kubectl delete admins.admin.liqiang.io liuliqiang
admin.admin.liqiang.io "liuliqiang" deleted
[root@liqiang.io]# kubectl get admins.admin.liqiang.io
No resources found in default namespace.
这个新建和删除 Admin 的过程虽然用得挺简单,但是,事实上,他们除了把 Kubernetes 当作一个 DB 之外,没有太多的实际价值。他们更多的价值体现在我后续介绍的 Controller 和 Operator 之上。所以,管理 CRD 的定义以及使用的基本内容就是这么多了,非常简单。
2. 其他笔记
2.1 Kubectl 发现机制
在我创建完 CRD 之后,kubectl 会通过 API 服务器的 discovery information 来查找关于新资源的信息,下面展示当使用 kubectl 获取一个 CR 时,内部的流程:

这个过程是通过 discovery RESTMapper 实现的,关于 RESTMapper 我在后面会继续介绍。
2.2 校验 CR
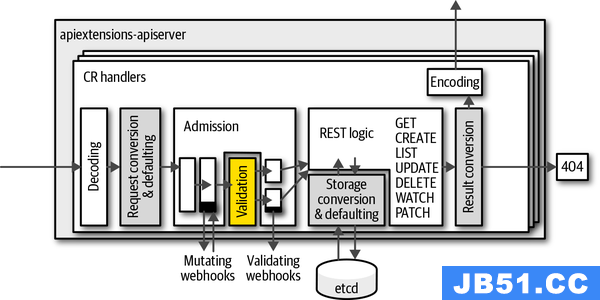
创建资源的时候,肯定不是任由我们随意得编写 YAML 声明文件,当提交给 Kubernetes 之后,Kubernetes 会对我们提交得声明文件进行校验,从前边 CRD 的定义中可以看到,CRD 是基于 OpenAPI v3 schema 进行的。

同时也可以看到,这种校验是比较初级的,比较简略的。如果想要实现更加复杂的校验,那么可以通过 Kubernetes 的 admission webhook 来实现,这个在我介绍 Istio 的时候有介绍过,如果没印象,不妨找来看看。
Adminssion webhook 的内部校验流程是这样的:
2.3 简称和属性
当我输入 kubectl api-resources 的时候,可以看到我定义的 CRD 和一些内置的 Resource 还是有一些区别的,例如内置的 Service 有简写: svc,那么 CRD 是否可以有简写,答案是肯定的:

如果通过
kubectl get all来列举所有的资源,然后会发现并不会看到自己的 CRD,如果想要让自己的 CRD 对应的 CR 出现在 get all 中,那么可以在 CRD 的声明中加入 categories 属性:
3. 架构设计
3.1 控制器概览
只定义一个 CRD 其实没有什么作用,它只会被 API Server 简单地计入到 etcd 中。如何依据这个 CRD 定义的资源和 Schema 来做一些复杂的操作,则是由 Controller,也就是控制器来实现的。
Controller 其实是 Kubernetes 提供的一种可插拔式的方法来扩展或者控制声明式的 Kubernetes 资源。它是 Kubernetes 的大脑,负责大部分资源的控制操作。以 Deployment 为例,它就是通过 kube-controller-manager 来部署的。
比如说声明一个 Deployment 有 replicas、有 2 个 Pod,那么 kube-controller-manager 在观察 etcd 时接收到了该请求之后,就会去创建两个对应的 Pod 的副本,并且它会去实时地观察着这些 Pod 的状态,如果这些 Pod 发生变化了、回滚了、失败了、重启了等等,它都会去做一些对应的操作。
所以 Controller 才是控制整个 Kubernetes 资源最终表现出来的状态的大脑。
用户声明完成 CRD 之后,也需要创建一个控制器来完成对应的目标。比如之前的 Foo,它希望去创建一个 Deployment,replicas 为 1,这就需要我们创建一个控制器用于创建对应的 Deployment 才能真正实现 CRD 的功能。
控制器工作流程概览
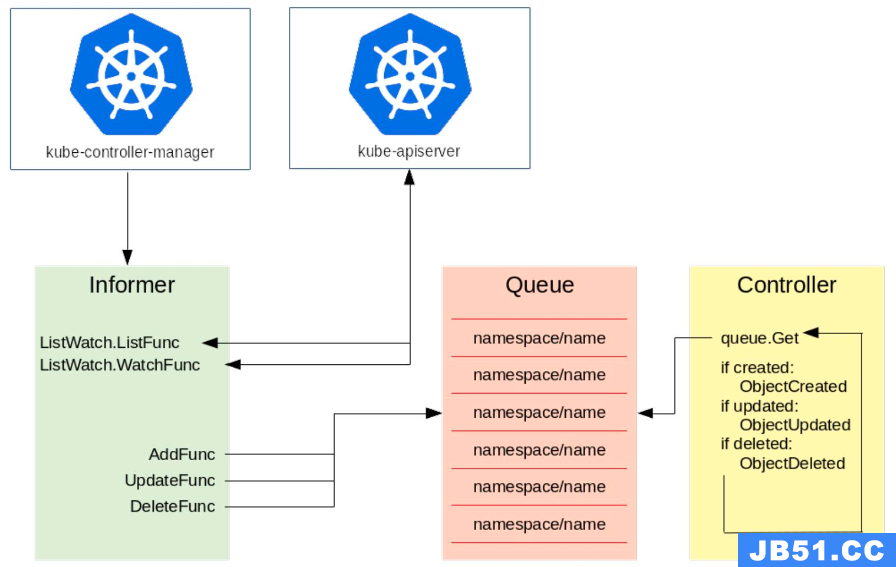
这里以 kube-controller-manager 为例。
如上图所示,左侧是一个 Informer,它的机制就是通过去 watch kube-apiserver,而 kube-apiserver 会去监督所有 etcd 中资源的创建、更新与删除。Informer 主要有两个方法:一个是 ListFunc;一个是 WatchFunc。
- ListFunc 就是像 “kuberctl get pods” 这类操作,把当前所有的资源都列出来;
- WatchFunc 会和 apiserver 建立一个长链接,一旦有一个新的对象提交上去之后,apiserver 就会反向推送回来,告诉 Informer 有一个新的对象创建或者更新等操作。
Informer 接收到了对象的需求之后,就会调用对应的函数(比如图中的三个函数 AddFunc,UpdateFunc 以及 DeleteFunc),并将其按照 key 值的格式放到一个队列中去,key 值的命名规则就是 “namespace/name”,name 就是对应的资源的名字。比如我们刚才所说的在 default 的 namespace 中创建一个 foo 类型的资源,那么它的 key 值就是 “default/example-foo”。Controller 从队列中拿到一个对象之后,就会去做相应的操作。
下图就是控制器的工作流程。
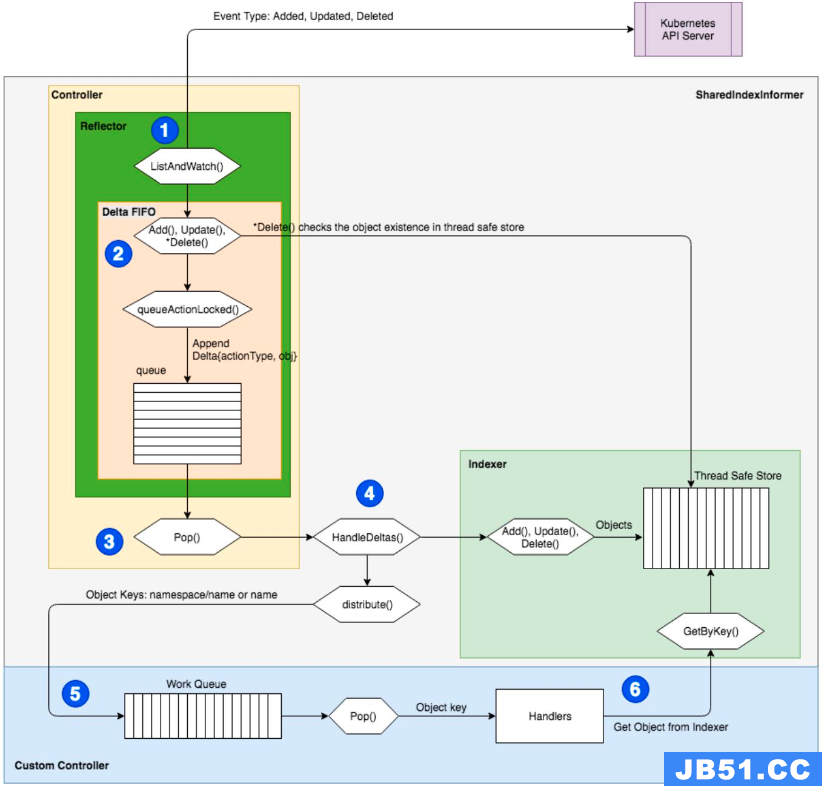
首先,通过 kube-apiserver 来推送事件,比如 Added,Updated,Deleted;然后进入到 Controller 的 ListAndWatch() 循环中;ListAndWatch 中有一个先入先出的队列,在操作的时候就将其 Pop() 出来;然后去找对应的 Handler。Handler 会将其交给对应的函数(比如 Add(),Update(),Delete())。
一个函数一般会有多个 Worker。多个 Worker 的意思是说比如同时有好几个对象进来,那么这个 Controller 可能会同时启动五个、十个这样的 Worker 来并行地执行,每个 Worker 可以处理不同的对象实例。
工作完成之后,即把对应的对象创建出来之后,就把这个 key 丢掉,代表已经处理完成。如果处理过程中有什么问题,就直接报错,打出一个事件来,再把这个 key 重新放回到队列中,下一个 Worker 就可以接收过来继续进行相同的处理。
参考
Kubernetes CRD 介绍
从零开始入门 K8s | Kubernetes API 编程范式
原文地址:https://blog.csdn.net/m0_45406092/article/details/134881906
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。