

注意:后续技术分享,第一时间更新,以及更多更及时的技术资讯和学习技术资料,将在公众号CTO Plus发布,请关注公众号:CTO Plus

1.创建、更新和删除应用程序、服务和负载均衡器等资源
2.管理集群节点的状态和部署
3.管理Kubernetes集群的配置和存储
4.监控集群和应用程序的状态
5.诊断和调试应用程序和集群故障
6.扩展和调整集群规模和资源使用
7.与Kubernetes API服务器通信
Kubectl是使用Kubernetes进行部署和管理的核心工具之一,使得管理员能够轻松地进行操作和管理,提高了Kubernetes的可用性和效率。
使用kubectl来管理Kubernetes集群。可以在 https://github.com/kubernetes/kubernetes 找到更多的信息。
kubectl 选项
--alsologtostderr[=false]: 同时输出日志到标准错误控制台和文件。
--api-version="": 和服务端交互使用的API版本。
--certificate-authority="": 用以进行认证授权的.cert文件路径。
--client-certificate="": TLS使用的客户端证书路径。
--client-key="": TLS使用的客户端密钥路径。
--cluster="": 指定使用的kubeconfig配置文件中的集群名。
--context="": 指定使用的kubeconfig配置文件中的环境名。
--insecure-skip-tls-verify[=false]: 如果为true,将不会检查服务器凭证的有效性,这会导致你的HTTPS链接变得不安全。
--kubeconfig="": 命令行请求使用的配置文件路径。
--log-backtrace-at=:0: 当日志长度超过定义的行数时,忽略堆栈信息。
--log-dir="": 如果不为空,将日志文件写入此目录。
--log-flush-frequency=5s: 刷新日志的最大时间间隔。
--logtostderr[=true]: 输出日志到标准错误控制台,不输出到文件。
--match-server-version[=false]: 要求服务端和客户端版本匹配。
--namespace="": 如果不为空,命令将使用此namespace。
--password="": API Server进行简单认证使用的密码。
-s,--server="": Kubernetes API Server的地址和端口号。
--stderrthreshold=2: 高于此级别的日志将被输出到错误控制台。
--token="": 认证到API Server使用的令牌。
--user="": 指定使用的kubeconfig配置文件中的用户名。
--username="": API Server进行简单认证使用的用户名。
--v=0: 指定输出日志的级别。
--vmodule=: 指定输出日志的模块,格式如下:pattern=N,使用逗号分隔。以下将按照分类对K8S常用命令进行详解
node
查看服务器节点
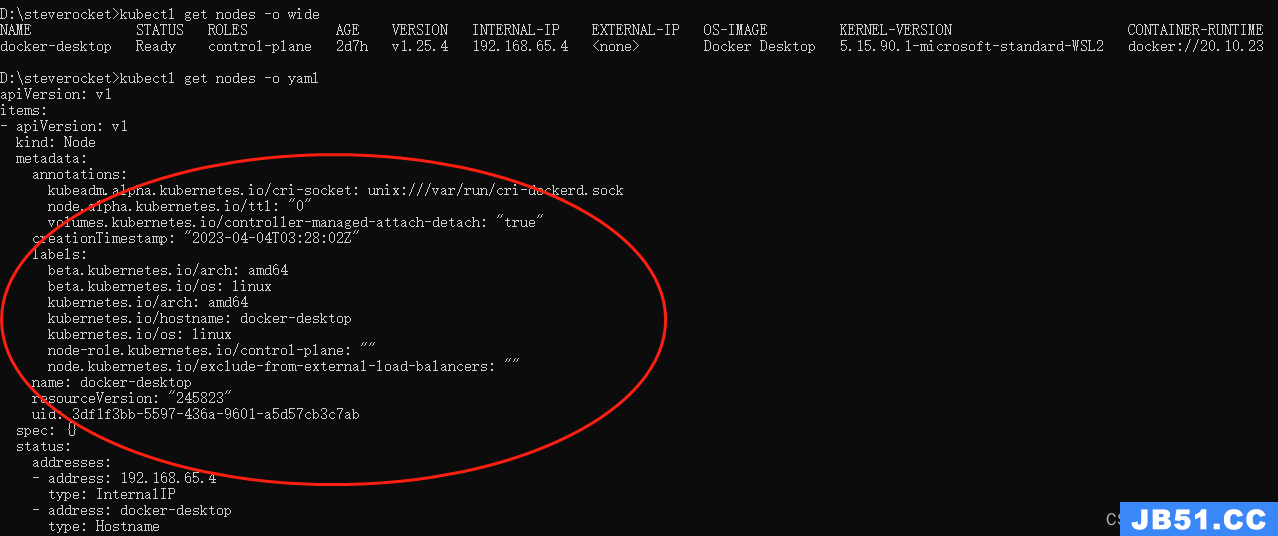
kubectl get nodes

查看服务器节点详情
kubectl get nodes -o wide
结果展示除了wide格式外还支持:custom-columns、custom-columns-file、go-template、go-template-file、json、jsonpath、jsonpath-as-json、jsonpath-file、name、template、templatefile、wide、yaml
节点打标签
kubectl label nodes <节点名称> labelName=<标签名称>
查看节点标签
kubectl get node --show-labels

删除节点标签
kubectl label node <节点名称> labelName-
pod
获取K8s集群下pod节点信息
kubectl get pod

查看pod节点详情
kubectl get pod -o wide

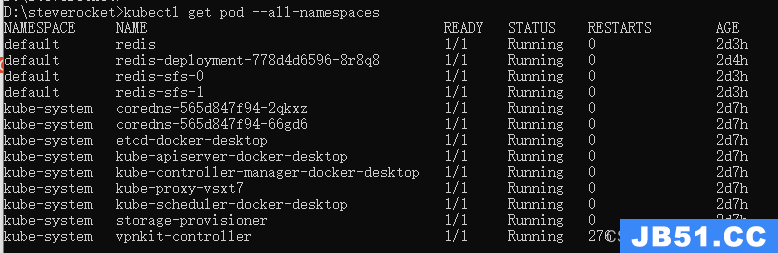
查看所有名称空间下的pod
kubectl get pod --all-namespaces
根据yaml文件创建pod
kubectl apply -f <文件名称>
根据yaml文件删除pod
kubectl delete -f <文件名称>
删除pod节点
kubectl delete pod <pod名称> -n <名称空间>
查看异常的pod节点
kubectl get pods -n <名称空间> | grep -v Running
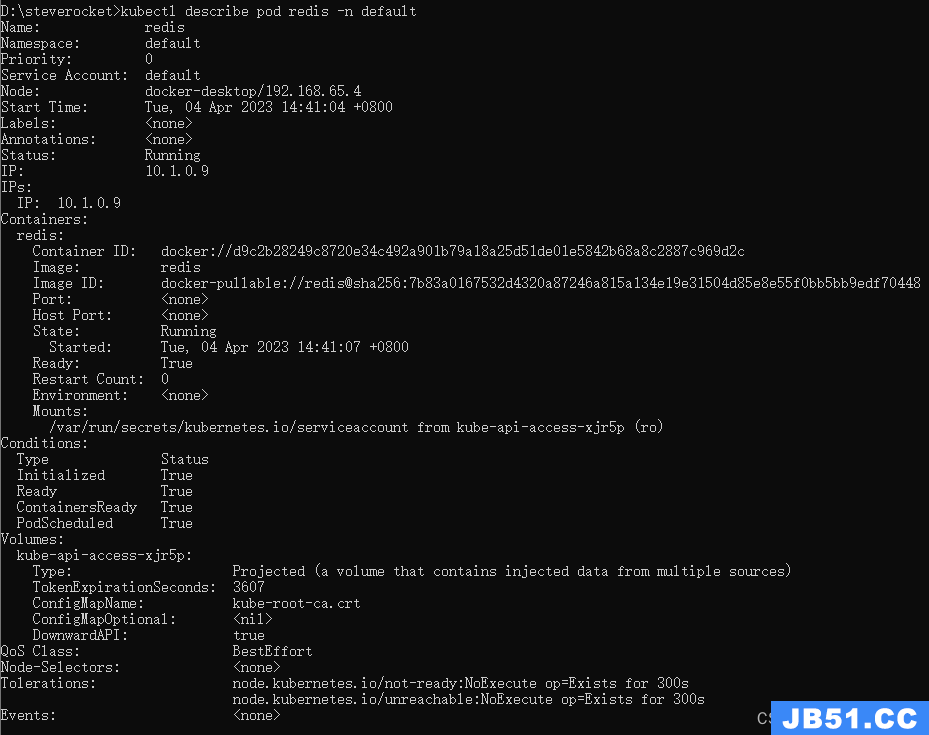
查看异常pod节点的日志
kubectl describe pod <pod名称> -n <名称空间>
指定资源的信息
格式:kubectl get <resource_type>/<resource_name>,比如获取deployment nginx_app的信息
kubectl get deployment/nginx_app -o wide
对指定的资源进行格式化输出,比如输出格式为json、yaml等
kubectl get deployment/nginx_app -o json
对输出结果进行自定义,比如对pod只输出容器名称和镜像名称
kubectl get pod httpd-app-5bc589d9f7-rnhj7 -o custom-columns=CONTAINER:.spec.containers[0].name,IMAGE:.spec.containers[0].image
获取某个特定key的值还可以输入如下命令得到,此目录参照go template的用法,且命令结尾'\n'是为了输出结果换行
kubectl get pod httpd-app-5bc589d9f7-rnhj7 -o template --template='{{(index spec.containers 0).name}}{{"\n"}}'
还有一些可选项可以对结果进行过滤,可参照kubectl get --help说明
本篇:https://blog.csdn.net/zhouruifu2015/article/details/130056507
svc
查看服务
kubectl get svc

查看服务详情
kubectl get svc -o wide

查看所有名称空间下的服务
kubectl get svc --all-namespaces

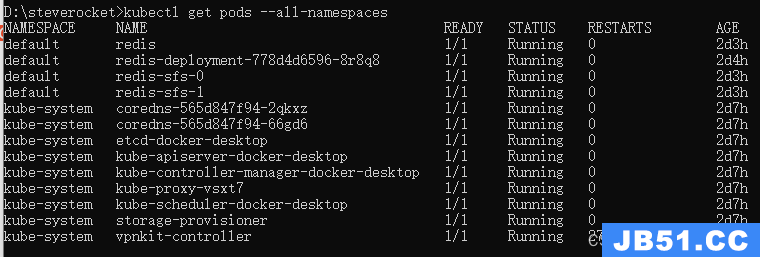
查看所有namespace的pods运行情况
kubectl get pods --all-namespaces
查看具体pods,记得后边跟namespace名字哦
kubectl get pods kubernetes-dashboard-76479d66bb-nj8wr --namespace=kube- system
查看pods具体信息
kubectl get pods -o wide kubernetes-dashboard-76479d66bb-nj8wr --namespace=kube-system
获取所有deployment
kubectl get deployment --all-namespaces
查看kube-system namespace下面的pod/svc/deployment 等等(-o wide 选项可以查看存在哪个对应的节点)
kubectl get pod /svc/deployment -n kube-system
列出该 namespace 中的所有 pod 包括未初始化的
kubectl get pods --include-uninitialized
查看deployment()
kubectl get deployment nginx-app
查看rc和servers
kubectl get rc,services
查看pods结构信息,对控制器和服务,node同样有效
kubectl describe pods xxxxpodsname --namespace=xxxnamespace
其他控制器类似,就是kubectl get 控制器 控制器具体名称
查看pod日志
kubectl logs $POD_NAME
查看pod变量
kubectl exec my-nginx-5j8ok -- printenv | grep SERVICE
集群
查看集群健康状态
kubectl get cs

集群核心组件运行情况
kubectl cluster-info

表空间名
kubectl get namespaces

版本
kubectl version

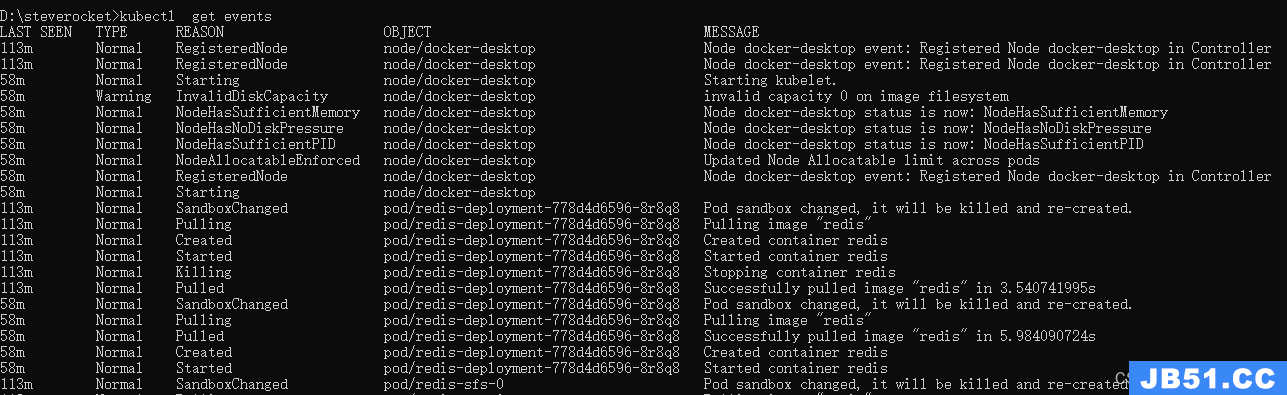
查看事件
kubectl get events
获取全部节点
kubectl get nodes

删除节点
kubectl delete node k8s2
kubectl rollout status deploy nginx-test
kubectl get deployment --all-namespaces
kubectl get svc --all-namespaces
创建资源
通过文件或者命令创建
kubectl create -f ./nginx.yaml # 创建资源
创建+更新,可以重复使用(常用)
kubectl apply -f xxx.yaml
创建当前目录下的所有yaml资源
kubectl create -f .
使用多个文件创建资源
kubectl create -f ./nginx1.yaml -f ./mysql2.yaml
通过文件创建一个Deployment
kubectl create -f /path/to/deployment.yaml
cat /path/to/deployment.yaml | kubectl create -f -
使用目录下的所有清单文件来创建资源
kubectl create -f ./dir
使用 url 来创建资源
kubectl create -f https://git.io/vPieo
创建带有终端的pod
kubectl run -i --tty busybox --image=busybox
启动一个 redis/nginx实例
kubectl run nginx --image=nginx # 启动一个 nginx 实例
kubectl run nginx --image=redis

启动多个pod
kubectl run mybusybox --image=busybox --replicas=5
通过kubectl命令直接创建
kubectl run nginx_app --image=nginx:1.9.1 --replicas=3
获取 pod 和 svc 的文档
kubectl explain pods,svc
删除
根据label删除:
kubectl delete pod -l app=flannel -n kube-system
删除 pod.json 文件中定义的类型和名称的 pod
kubectl delete -f ./pod.json
删除名为"baz"的 pod 和名为"foo"的 service
kubectl delete pod,service baz foo
删除具有 name=myLabel 标签的 pod 和 serivce
kubectl delete pods,services -l name=myLabel
删除具有 name=myLabel 标签的 pod 和 service,包括尚未初始化的
kubectl delete pods,services -l name=myLabel --include-uninitialized
删除 my-ns namespace下的所有 pod 和 serivce,包括尚未初始化的
kubectl -n my-ns delete po,svc --all
强制删除
kubectl delete pods prometheus-7fcfcb9f89-qkkf7 --grace-period=0 --force
kubectl delete deployment kubernetes-dashboard --namespace=kube-system
kubectl delete svc kubernetes-dashboard --namespace=kube-system
kubectl delete -f kubernetes-dashboard.yaml
强制替换,删除后重新创建资源。会导致服务中断。
kubectl replace --force -f ./pod.json
更新资源
滚动更新 pod frontend-v1
kubectl rolling-update python-v1 -f python-v2.json
更新资源名称并更新镜像
kubectl rolling-update python-v1 python-v2 --image=image:v2
更新 frontend pod 中的镜像
kubectl rolling-update python --image=image:v2
退出已存在的进行中的滚动更新
kubectl rolling-update python-v1 python-v2 --rollback
基于 stdin 输入的 JSON 替换 pod
cat pod.json | kubectl replace -f -
kubectl replace:使用配置文件来替换资源
kubectl replace -f /path/to/new_nginx_app.yaml
为 nginx RC 创建服务,启用本地 80 端口连接到容器上的 8000 端口
kubectl expose rc nginx --port=80 --target-port=8000
更新单容器 pod 的镜像版本(tag)到 v4
kubectl get pod nginx-pod -o yaml | sed 's/\(image: myimage\):.*$/\1:v4/' | kubectl replace -f -
添加标签
kubectl label pods nginx-pod new-label=awesome
添加注解(更新资源的注解)
kubectl annotate pods nginx-pod icon-url=http://goo.gl/XXBTWq
自动扩展 deployment “foo”
kubectl autoscale deployment foo --min=2 --max=10
更新资源kubectl patch
使用补丁修改、更新某个资源的字段,比如更新某个node
kubectl patch node/node-0 -p '{"spec":{"unschedulable":true}}'
kubectl patch -f node-0.json -p '{"spec": {"unschedulable": "true"}}'
编辑/更新资源
相当于先用get去获取资源,然后进行更新,最后对更新后的资源进行apply
编辑名为 docker-registry 的 service
kubectl edit svc/docker-registry
使用其它编辑器
KUBE_EDITOR="nano" kubectl edit svc/docker-registry
修改启动参数
vim /etc/systemd/system/kubelet.service.d/10-kubeadm.conf
动态伸缩pod
将foo副本集变成3个
kubectl scale --replicas=3 rs/foo
缩放“foo”中指定的资源。
kubectl scale --replicas=3 -f foo.yaml
将deployment/mysql从2个变成3个
kubectl scale --current-replicas=2 --replicas=3 deployment/mysql
变更多个控制器的数量
kubectl scale --replicas=5 rc/foo rc/bar rc/baz
查看变更进度
kubectl rollout status deploy deployment/mysql
label 操作
增加节点lable值 spec.nodeSelector: zone: north 指定pod在哪个节点
kubectl label:添加label值 kubectl label nodes node1 zone=north
增加lable值 key=value
kubectl label pod redis-master-1033017107-q47hh role=master
删除lable值
kubectl label pod redis-master-1033017107-q47hh role-
修改lable值
kubectl label pod redis-master-1033017107-q47hh role=backend –overwrite
滚动升级
配置文件滚动升级
kubectl rolling-update:滚动升级 kubectl rolling-update redis-master -f redis- master-controller-v2.yaml
命令升级
kubectl rolling-update redis-master --image=redis-master:2.0
pod版本回滚
kubectl rolling-update redis-master --image=redis-master:1.0 –rollback
etcdctl 常用操作
检查网络集群健康状态
etcdctl cluster-health
带有安全认证检查网络集群健康状态
etcdctl --endpoints=https://192.168.71.221:2379 cluster-health
etcdctl member list
etcdctl set /k8s/network/config ‘{ “Network”: “10.1.0.0/16” }’
etcdctl get /k8s/network/config
交互
dump 输出 pod 的日志(stdout)
kubectl logs nginx-pod

dump 输出 pod 中容器的日志(stdout,pod 中有多个容器的情况下使用)
kubectl logs nginx-pod -c my-container
流式输出 pod 的日志(stdout)
kubectl logs -f nginx-pod

流式输出 pod 中容器的日志(stdout,pod 中有多个容器的情况下使用)
kubectl logs -f nginx-pod -c my-container
交互式 shell 的方式运行 pod
kubectl run -i --tty busybox --image=busybox -- sh
连接到运行中的容器
kubectl attach nginx-pod -i
转发 pod 中的 6000 端口到本地的 5000 端口
kubectl port-forward nginx-pod 5000:6000
在已存在的容器中执行命令(只有一个容器的情况下)
kubectl exec nginx-pod -- ls /
在已存在的容器中执行命令(pod 中有多个容器的情况下)
kubectl exec nginx-pod -c my-container -- ls /
显示指定 pod和容器的指标度量
kubectl top pod POD_NAME --containers
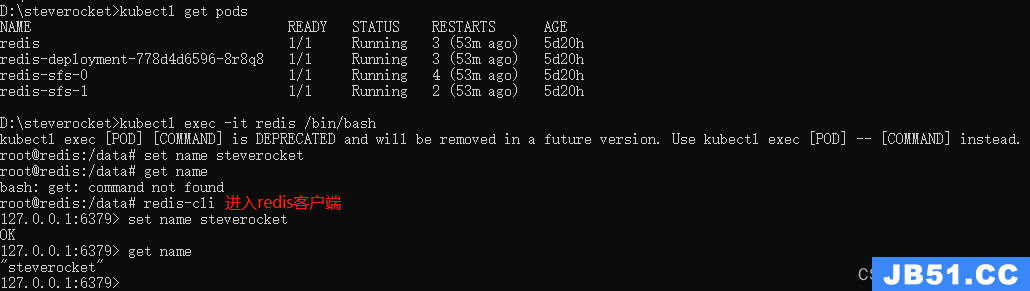
进入pod
kubectl exec -ti podName /bin/bash
调度配置
标记 my-node 不可调度
kubectl cordon k8s-node
清空 my-node 以待维护
kubectl drain k8s-node
标记 my-node 可调度
kubectl uncordon k8s-node
显示 my-node 的指标度量
kubectl top node k8s-node
将当前集群状态输出到 stdout
kubectl cluster-info dump
将当前集群状态输出到 /path/to/cluster-state
kubectl cluster-info dump --output-directory=/path/to/cluster-state
如果该键和影响的污点(taint)已存在,则使用指定的值替换
kubectl taint nodes foo dedicated=special-user:NoSchedule
查看kubelet进程启动参数
ps -ef | grep kubelet
查看日志:
journalctl -u kubelet –f
导出配置文件
导出proxy
kubectl get ds -n kube-system -l k8s-app=kube-proxy -o yaml>kube-proxy- ds.yaml
导出kube-dns
kubectl get deployment -n kube-system -l k8s-app=kube-dns -o yaml >kube-dns- dp.yaml
kubectl get services -n kube-system -l k8s-app=kube-dns -o yaml >kube-dns- services.yaml
导出所有 configmap
kubectl get configmap -n kube-system -o wide -o yaml > configmap.yaml
复杂操作命令
删除kube-system下Evicted状态[WU1] 的所有pod
kubectl get pods -n kube-system |grep Evicted| awk ‘{print $1}’|xargs kubectl delete pod -n kube-system
扩展阅读:
kube-system是Kubernetes系统默认的命名空间,其中包含了许多系统的控制器和核心服务,状态主要可以分为以下几种:
1. Running:运行状态,表示该Pod组件正在运行中;
2. Completed:完成状态,表示该组件已经完成了它的任务;
3. CrashLoopBackOff:崩溃循环状态,表示该组件在启动时遇到了错误,并尝试重启;
4. ImagePullBackOff:拉取镜像失败状态,表示该组件无法拉取所需的镜像;
5. ErrImagePull:拉取镜像错误状态,表示该组件无法拉取所需镜像并且已达到重试上限;
6. Pending:挂起状态,表示该组件正在等待资源分配(等待调度);
7. Unknown:未知状态,表示该Pod组件当前的状态无法被确认,如该组件在启动时出现了错误并被误报为成功。
8. Evicted:表示Kubernetes系统已经将一个Pod从其所在的节点上驱逐出去,通常发生在与节点资源不足有关的错误情况下,例如内存、CPU、存储等。Pod被驱逐后,将会停止运行并且不会自动重启,需要手动重启Pod以重新启动应用程序。
9. Succeeded:Pod的所有容器已经成功完成了它们的任务。
10. Failed:Pod的某个容器已经失败。
cordon & uncordon命令
设置是否能够将pod调度到该节点上。
不可调度
kubectl cordon node-0
当某个节点需要维护时,可以驱逐该节点上的所有pods(会删除节点上的pod,并且自动通过上面命令设置该节点不可调度,然后在其他可用节点重新启动pods)
kubectl drain node-0
待其维护完成后,可再设置该节点为可调度
kubectl uncordon node-0
taint命令
目前仅能作用于节点资源,一般这个命令通常会结合pod的tolerations字段结合使用,对于没有设置对应toleration的pod是不会调度到有该taint的节点上的,这样就可以避免pod被调度到不合适的节点上。一个节点的taint一般会包括key、value和effect(effect只能在NoSchedule,PreferNoSchedule,NoExecute中取值)。
设置taint
kubecl taint nodes node-0 key1=value1:NoSchedule
移除taint
kubecl taint nodes node-0 key1:NoSchedule-
如果pod想要被调度到上述设置了taint的节点node-0上,则需要在该pod的spec的tolerations字段设置:
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoSchedule"
# 或者
tolerations:
- key: "key1"
operator: "Exists"
effect: "NoSchedule"部署命令
部署命令包括资源的运行管理命令、扩容和缩容命令和自动扩缩容命令。
rollout命令
管理资源的运行,比如eployment、Daemonet、StatefulSet等资源。
查看部署状态:比如更新deployment/nginx_app中容器的镜像后查看其更新的状态。
kubectl set image deployment/nginx_app nginx=nginx:1.9.1
kubectl rollout status deployment/nginx_app
资源的暂停及恢复:发出一次或多次更新前暂停一个 Deployment,然后再恢复它,这样就能在Deployment暂停期间进行多次修复工作,而不会发出不必要的rollout。
暂停
kubectl rollout pause deployment/nginx_app
完成所有的更新操作命令后进行恢复
kubectl rollout resume deployment/nginx_app
回滚:如上对一个Deployment的image做了更新,但是如果遇到更新失败或误更新等情况时可以对其进行回滚。
回滚之前先查看历史版本信息
kubectl rollout history deployment/nginx_app
回滚
kubectl rollout undo deployment/nginx_app
也可以指定版本号回滚至指定版本
kubectl rollout undo deployment/nginx_app --to-revision=<version_index>
scale命令
对一个Deployment、RS、StatefulSet进行扩/缩容。
扩容
kubectl scale deployment/nginx_app --replicas=5
缩容,把对应的副本数设置的比当前的副本数小即可,另外,还可以针对当前的副本数目做条件限制,比如当前副本数是5则进行缩容至副本数目为3
kubectl scale --current-replicas=5 --replicas=3 deployment/nginx_app
autoscale命令
通过创建一个autoscaler,可以自动选择和设置在K8s集群中Pod的数量。
基于CPU的使用率创建3-10个pod
kubectl autoscale deployment/nginx_app --min=3 --max=10 --cpu_percent=80
维护环境相关命令
重启kubelet服务
systemctl daemon-reload
systemctl restart kubelet
映射端口允许外部访问
kubectl expose deployment/nginx_app --type='NodePort' --port=80
通过kubectl get services -o wide来查看被随机映射的端口,这样就可以通过node的外部IP和端口来访问nginx服务了
转发本地端口访问Pod的应用服务程序
kubectl port-forward nginx_app_pod_0 8090:80
这样本地可以访问:curl -i localhost:8090
在创建或启动某些资源的时候没有达到预期结果,可以使用如下命令先简单进行故障定位
kubectl describe deployment/nginx_app
kubectl logs nginx_pods
kubectl exec nginx_pod -c nginx-app <command>
集群内部调用接口(比如用curl命令),可以采用代理的方式,根据返回的ip及端口作为baseurl
kubectl proxy &
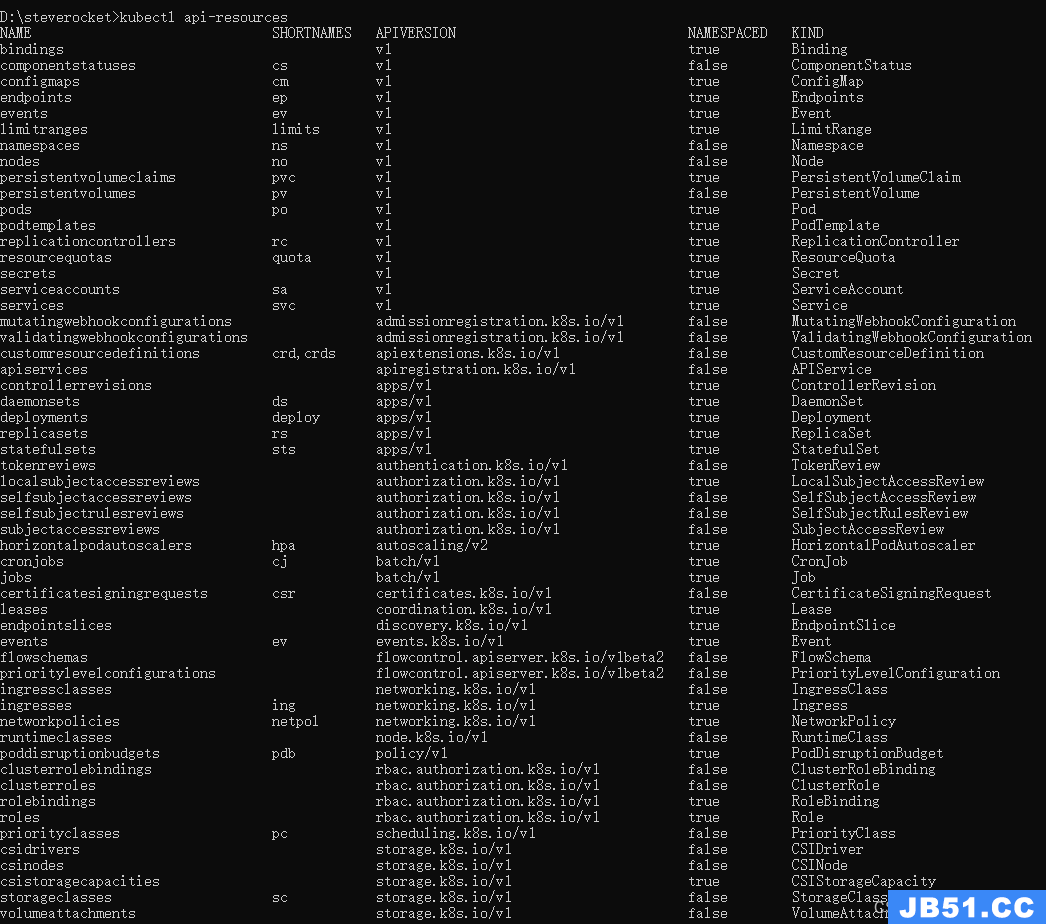
查看K8s支持的完整资源列表
kubectl api-resources
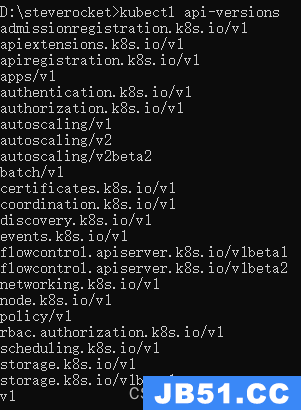
查看K8s支持的api版本
kubectl api-versions
微信公众号搜索【CTO Plus】关注后,获取更多,我们一起学习交流。
参考资料
[1]官网:https://kubernetes.io/zh-cn/
[2]文社区中文文档:http://docs.kubernetes.org.cn/
本篇:https://blog.csdn.net/zhouruifu2015/article/details/130056507
四、Kubernetes(K8S):kubectl概述、安装、设置https://blog.csdn.net/zhouruifu2015/article/details/130057847
 https://mp.weixin.qq.com/s/0yqGBPbOI6QxHqK17WxU8Q
https://mp.weixin.qq.com/s/0yqGBPbOI6QxHqK17WxU8Q原文地址:https://blog.csdn.net/zhouruifu2015/article/details/130056507
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。