
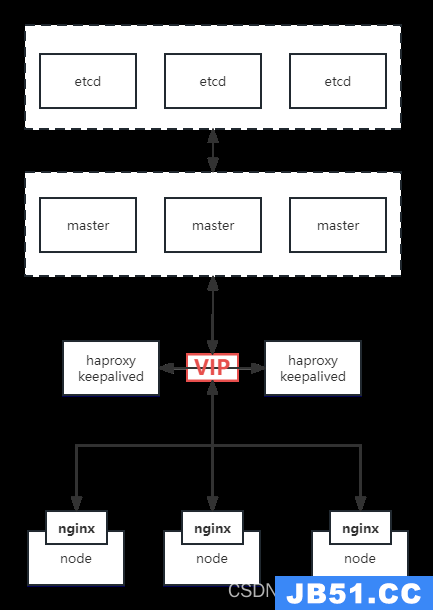
1. 生产环境部署架构
(1)多master节点,实现master节点的高可用和高性能。
(2)单独的etcd分布式集群(生产使用SSD盘),高可用持久化k8s资源对象数据,并实现高可用。
(3)多node节点运行业务pod,node节点可以是不同硬件规格、如CPU节点、Memory节点、GPU节点、bigdata节点等。
(4)各node节点通过负载均衡器与Master连接,由负载均衡器实现对master的轮训调用及状态监测及故障转移,以在master出现宕机的时候依然可以保持node与master的通信。
(5)各节点可弹性伸缩。
简单点来说就是etcd集群独立部署,不在k8s集群内。然后通过haproxy实现apiserver访问高可用性,客户端请求都先到vip,由haproxy代理到master上的apiserver。
然后每个node上都有一个nginx,当node请求apiserver时,先请求本地nginx,由nginx代理请求到3个master上的apiserver。
2. 服务器配置规划
如果自建机房,请把核心组件的机器分布到不同机柜中。
服务器可以是私有云的虚拟机或物理机,也可以是公有云环境的虚拟机环境,如果是公司托管的IDC环境,可以直
接将harbor和node节点部署在物理机环境,master节点、etcd、负载均衡等可以是虚拟机。
下面是我的学习环境,所以资源分配都比较少
| 角色 | IP | 主机名 | 内存cpu | VIP |
|---|---|---|---|---|
| K8s-Master | 10.31.200.101 | k8s-master01 | 2核2G | 10.31.200.100 |
| K8s-Master | 10.31.200.102 | k8s-master02 | 10.31.200.100 | |
| K8s-Master | 10.31.200.103 | k8s-master03 | 并且master节点不运行业务pod,数据盘也不需要太大 | 10.31.200.100 |
| Harbor | 10.31.200.104 | k8s-harbor01 | ansible一键部署节点 | |
| Etcd | 10.31.200.105 | k8s-etcd01 | 1核1G | |
| Etcd | 10.31.200.106 | k8s-etcd02 | ||
| Etcd | 10.31.200.107 | k8s-etcd03 | ||
| Haproxy | 10.31.200.108 | k8s-haproxy01 | ||
| Haproxy | 10.31.200.109 | k8s-haproxy02 | ||
| K8s-Node | 10.31.200.110 | k8s-node01 | 4核4G | |
| K8s-Node | 10.31.200.111 | k8s-node02 | ||
| K8s-Node | 10.31.200.112 | k8s-node03 |
2.1 关于实际工作中,集群规划建议
(1)master节点
对于生产的k8s集群来说,一般都是3M组成,并且3M可以是虚拟机,并且M节点只运行M节点相关的pod,其他pod一律不准调度到M节点。
一般小型生产环境4C8G就行,能支持数百POD。
中型生产环境8C16G,能支上千POD。
大型生产环境16C32G,能支上万POD。
(2)etcd集群
生产一般都是3个节点或者5个节点组成etcd集群,并且磁盘最好使用ssd盘,因为etcd集群非常消耗磁盘IO,如果用机械盘,会存在一些隐患,比如k8s集群get操作的时候,半天才能显示数据出来。
CPU和内存的配置,官方文档有明确的给出多少IOPS配置多少CPU内存:etcd.io/docs/v3.5/op-guide/hardware
(3)node节点
生产中,node节点最好按照不同的业务类型划分成不同的主机组进行分类,打上标签和污点,业务分类如下:
a: CPU密集型业务:特点是需要大量CPU,如 MySQL、人工智能、视屏转码、机密解密、数据计算等,并且一般这种业务,内存消耗也大。
b:内存密集型业务:特点是需要大量内存,如 java业务服务、ES等。
c: GPU密集型业务:特点是需要大量GPU资源,如 人工智能语音模型训练等。
d: IO密集型业务:特点消耗磁盘IO,由于K8S集群中部署的大部分都是无状态应用,所以这种比较少,顶多就是自建中间件会涉及到。
3. 安装前的系统初始化
3.1 修改yum源
所有节点操作
(1)备份原来的yum源
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
(2)下载阿里的yum源
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
(3)清理yum缓存
yum clean all
(4)生成新的yum缓存
yum makecache fast
(5)更新yum源
yum -y update
3.2 安装基础软件包
所有节点操作
yum -y install wget net-tools nfs-utils lrzsz gcc gcc-c++ make cmake libxml2-devel openssl-devel curl curl-devel unzip sudo ntp libaio-devel wget vim ncurses-devel autoconf automake zlib-devel python-devel epel-release openssh-server socat ipvsadm conntrack ntpdate yum-utils device-mapper-persistent-data lvm2
3.3 关闭防火墙
所有节点操作
systemctl stop firewalld && systemctl disable firewalld
3.4 时间同步配置
所有节点操作
3.4.1 命令行时间同步
ntpdate cn.pool.ntp.org
3.4.2 配置定时任务
1)crontab -l
* */1 * * * /usr/sbin/ntpdate cn.pool.ntp.org
3.5 关闭selinux
所有节点操作
关闭selinux,设置永久关闭,这样重启机器selinux也处于关闭状态
修改/etc/sysconfig/selinux和/etc/selinux/config文件,把
SELINUX=enforcing变成SELINUX=disabled,也可用下面方式修改:
sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/sysconfig/selinux
sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config
上面文件修改之后,需要重启虚拟机,可以强制重启:
reboot -f
3.6 关闭交换分区
所有节点操作
swapoff -a # 如果不关闭,初始化k8s的时候会报错
#永久禁用,打开/etc/fstab注释掉swap那一行。
sed -i 's/.*swap.*/#&/' /etc/fstab
3.7 修改内核参数
~]# cat /etc/sysctl.conf
net.ipv4.ip_forward=1
vm.max_map_count=262144
kernel.pid_max=4194303
fs.file-max=1000000
net.ipv4.tcp_max_tw_buckets=6000
net.netfilter.nf_conntrack_max=2097152
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
vm.swappiness=0
~]# sysctl -p
3.8 配置hosts文件
所有节点操作
~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
10.31.200.101 k8s-master01
10.31.200.102 k8s-master02
10.31.200.103 k8s-master03
10.31.200.104 k8s-harbor01
10.31.200.105 k8s-etcd01
10.31.200.106 k8s-etcd02
10.31.200.107 k8s-etcd03
10.31.200.108 k8s-haproxy01
10.31.200.109 k8s-haproxy02
10.31.200.110 k8s-node01
10.31.200.111 k8s-node02
10.31.200.112 k8s-node03
# 测试下ping主机名能不能通
~]# for i in `awk 'NR>2{print $NF}' /etc/hosts|xargs`; do ping $i -c 1;done
3.9 升级系统内核
所有节点操作相同
内核rpm下载地址:https://elrepo.org/linux/kernel/el7/x86_64/RPMS/
3.9.1 安装最新稳定版内核
(1)启用 ELRepo 仓库
rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
rpm -Uvh http://www.elrepo.org/elrepo-release-7.0-2.el7.elrepo.noarch.rpm
(2)仓库启用后,可以使用下面的命令列出可用的内核相关包
yum --disablerepo="*" --enablerepo="elrepo-kernel" list available
(3)安装最新的主线稳定内核
yum --enablerepo=elrepo-kernel install kernel-ml -y
3.9.2 设置内核的默认启动版本
(1)查看当前默认启动内核
~]# grub2-editenv list
saved_entry=CentOS Linux (3.10.0-1062.el7.x86_64) 7 (Core)
(2)罗列所有内核
~]# cat /boot/grub2/grub.cfg | grep menuentry
if [ x"${feature_menuentry_id}" = xy ]; then
menuentry_id_option="--id"
menuentry_id_option=""
export menuentry_id_option
menuentry 'CentOS Linux (6.2.11-1.el7.elrepo.x86_64) 7 (Core)' --class centos --class gnu-linux --class gnu --class os --unrestricted $menuentry_id_option 'gnulinux-3.10.0-1062.el7.x86_64-advanced-2b533453-1363-4b3b-b193-add11ebfe4a4' {
menuentry 'CentOS Linux (3.10.0-1062.el7.x86_64) 7 (Core)' --class centos --class gnu-linux --class gnu --class os --unrestricted $menuentry_id_option 'gnulinux-3.10.0-1062.el7.x86_64-advanced-2b533453-1363-4b3b-b193-add11ebfe4a4' {
menuentry 'CentOS Linux (0-rescue-fbc64785ea6c42a894303c0ab4b8db34) 7 (Core)' --class centos --class gnu-linux --class gnu --class os --unrestricted $menuentry_id_option 'gnulinux-0-rescue-fbc64785ea6c42a894303c0ab4b8db34-advanced-2b533453-1363-4b3b-b193-add11ebfe4a4' {
(3)设置默认启动内核
~]# grub2-set-default 'CentOS Linux (6.2.11-1.el7.elrepo.x86_64) 7 (Core)'
~]# grub2-editenv list
saved_entry=CentOS Linux (6.2.11-1.el7.elrepo.x86_64) 7 (Core)
(5)重启操作系统,查看默认启动内核
~]# reboot # 等待系统重启
~]# grub2-editenv list # 这就是升级后的内核
saved_entry=CentOS Linux (6.2.11-1.el7.elrepo.x86_64) 7 (Core)
3.10 安装ansible进行一键初始化系统(可选)
3.10.1 yum安装ansible
[root@k8s-harbor01 ~]# yum -y install ansible
[root@k8s-harbor01 ~]# ansible --version
ansible 2.9.27
config file = /etc/ansible/ansible.cfg
configured module search path = [u'/root/.ansible/plugins/modules',u'/usr/share/ansible/plugins/modules']
ansible python module location = /usr/lib/python2.7/site-packages/ansible
executable location = /usr/bin/ansible
python version = 2.7.5 (default,Aug 7 2019,00:51:29) [GCC 4.8.5 20150623 (Red Hat 4.8.5-39)]
~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
10.31.200.101 k8s-master01
10.31.200.102 k8s-master02
10.31.200.103 k8s-master03
10.31.200.104 k8s-harbor01
10.31.200.105 k8s-etcd01
10.31.200.106 k8s-etcd02
10.31.200.107 k8s-etcd03
10.31.200.108 k8s-haproxy01
10.31.200.109 k8s-haproxy02
10.31.200.110 k8s-node01
10.31.200.111 k8s-node02
10.31.200.112 k8s-node03
3.10.2 配置ansible主机到所有k8s节点的ssh免密
# 非交互式生成密钥对
[root@k8s-harbor01 ~]# ssh-keygen -f ~/.ssh/id_rsa -P '' -q
# 非交互式推送公钥文件
[root@k8s-harbor01 ~]# yum install sshpass -y
[root@k8s-harbor01 ~]# for i in `awk 'NR>2{print $NF}' /etc/hosts|xargs`; do sshpass -p123456 ssh-copy-id -f -i ~/.ssh/id_rsa.pub "-o StrictHostKeyChecking=no" $i;done
# 登录测试
[root@k8s-harbor01 ~]# ssh k8s-master01
Last login: Tue Apr 18 22:26:23 2023 from 10.31.200.199
[root@k8s-master01 ~]# exit
logout
Connection to k8s-master01 closed.
3.10.3 配置主机清单文件
[root@k8s-harbor01 ~]# cp /etc/ansible/hosts{,.bak}
[root@k8s-harbor01 ~]# cat /etc/ansible/hosts
[k8s_all]
10.31.200.[101:103]
10.31.200.[110:112]
[root@k8s-harbor01 ~]# ansible k8s_all -m ping|grep SUCCESS
10.31.200.103 | SUCCESS => {
10.31.200.111 | SUCCESS => {
10.31.200.102 | SUCCESS => {
10.31.200.101 | SUCCESS => {
10.31.200.110 | SUCCESS => {
10.31.200.112 | SUCCESS => {
3.10.4 编写playbook
[root@k8s-harbor01 ~]# mkdir ansible-playbook
[root@k8s-harbor01 ~]# cd ansible-playbook/
[root@k8s-harbor01 ansible-playbook]# cat init.yaml
---
# 安装k8s前的系统初始化
- hosts: k8s_all
remote_user: root
gather_facts: no
tasks:
- name: "修改yum源"
debug:
msg: "我模板机的yum源都弄好了,所以不用执行这一步!"
- name: "安装基础软件包"
yum:
name: ansible,nginx,wget,git,conntrack-tools,psmisc,nfs-utils,jq,socat,ebtables,ethtool,util-linux,bash-completion,ipset,ipvsadm,conntrack,libseccomp,net-tools,crontabs,sysstat,unzip,iftop,nload,strace,bind-utils,tcpdump,telnet,lsof,htop,vim,yum-utils,tree,chrony,gcc,gcc-c++,lrzsz,zip,pciutils
state: present
- name: "关闭防火墙"
service:
name: firewalld
state: stopped
enabled: no
- name: "配置时间同步"
shell:
cmd: 'ntpdate cn.pool.ntp.org'
- name: "配置时间同步定时任务"
cron:
name: "时间同步"
minute: '*'
hour: '*/1'
day: '*'
month: '*'
weekday: '*'
job: '/usr/sbin/ntpdate cn.pool.ntp.org'
- name: "关闭selinux"
selinux:
state: disabled
#- name: "命令行关闭selinux"
# shell:
# cmd: 'setenforce 0'
- name: "关闭交换分区"
shell:
cmd: "swapoff -a && sysctl -w vm.swappiness=0 && sed -ri '/^[^#]*swap/s@^@#@' /etc/fstab"
- name: "修改内核参数"
copy:
src: /root/ansible-playbook/sysctl.conf
dest: /etc/sysctl.conf
backup: yes
- name: "生效内核参数"
shell:
cmd: 'sysctl --system'
- name: "配置hosts文件"
copy:
src: /etc/hosts
dest: /etc/hosts
backup: yes
- name: "下载最新稳定版内核"
copy:
src: /root/ansible-playbook/kernel-ml-6.2.12-1.el7.elrepo.x86_64.rpm # 由于官网更新速度太快了 所以最好手动下载到本地
dest: /root/kernel-ml-6.2.12-1.el7.elrepo.x86_64.rpm
- name: "安装内核"
yum:
name: /root/kernel-ml-6.2.12-1.el7.elrepo.x86_64.rpm
- name: "设置默认内核(1)"
shell:
cmd: 'grub2-set-default 0 && grubby --default-kernel'
- name: "设置默认内核(2)"
shell:
cmd: "mv /boot/initramfs-6.2.12-1.el7.elrepo.x86_64.img /boot/initramfs-6.2.12-1.el7.elrepo.x86_64.img-bak && dracut -v /boot/initramfs-6.2.12-1.el7.elrepo.x86_64.img 6.2.12-1.el7.elrepo.x86_64"
- name: "系统初始化完毕!"
debug:
msg: "请重启系统生效配置!"
[root@k8s-harbor01 ansible-playbook]# wget https://elrepo.org/linux/kernel/el7/x86_64/RPMS/kernel-ml-6.2.12-1.el7.elrepo.x86_64.rpm
[root@k8s-harbor01 ansible-playbook]# cat sysctl.conf
# sysctl settings are defined through files in
# /usr/lib/sysctl.d/,/run/sysctl.d/,and /etc/sysctl.d/.
#
# Vendors settings live in /usr/lib/sysctl.d/.
# To override a whole file,create a new file with the same in
# /etc/sysctl.d/ and put new settings there. To override
# only specific settings,add a file with a lexically later
# name in /etc/sysctl.d/ and put new settings there.
#
# For more information,see sysctl.conf(5) and sysctl.d(5).
net.ipv4.ip_forward=1
vm.max_map_count=262144
kernel.pid_max=4194303
fs.file-max=1000000
net.ipv4.tcp_max_tw_buckets=6000
net.netfilter.nf_conntrack_max=2097152
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
vm.swappiness=0
3.10.5 执行playbook
[root@k8s-harbor01 ansible-playbook]# ansible-playbook -C init.yaml # 先测试语法有无问题
[root@k8s-harbor01 ansible-playbook]# cat /etc/ansible/hosts
[k8s_all]
10.31.200.[101:103]
10.31.200.[110:112]
[root@k8s-harbor01 ansible-playbook]# head -3 init.yaml
---
# 安装k8s前的系统初始化
- hosts: k8s_all # 把hosts修改为主机清单里面的名称
# 执行批量初始化
[root@k8s-harbor01 ansible-playbook]# ansible-playbook init.yaml
…………省略部分内容
TASK [系统初始化完毕!] *******************************************************************************************************************************************************
ok: [10.31.200.102] => {
"msg": "请重启系统生效配置!"
}
ok: [10.31.200.103] => {
"msg": "请重启系统生效配置!"
}
ok: [10.31.200.110] => {
"msg": "请重启系统生效配置!"
}
ok: [10.31.200.111] => {
"msg": "请重启系统生效配置!"
}
ok: [10.31.200.112] => {
"msg": "请重启系统生效配置!"
}
[root@k8s-harbor01 ansible-playbook]# ansible k8s_all -m 'reboot'
3.10.6 配置检查
检查剧本中的配置有没有真的在目的主机上执行
略
4. 安装haproxy和keepalived
keepalived:生成虚拟IP
haproxy:做高可用
4.1 haproxy-01操作
4.1.1 安装haproxy和keepalived
[root@k8s-haproxy01 ~]# yum -y install haproxy keepalived
4.1.2 配置keepalived
如果没有生成配置文件就find找一下
[root@k8s-haproxy01 ~]# cp /etc/keepalived/keepalived.conf{,.bak}
[root@k8s-haproxy01 ~]# vim /etc/keepalived/keepalived.conf
[root@k8s-haproxy01 ~]# cat /etc/keepalived/keepalived.conf
global_defs {
router_id lb01 # 不同的keepalived节点id不能相同
}
vrrp_instance VI_1 { # 主要修改这里的配置
state MASTER
interface ens192 #网卡接口 注意自己机器的网卡接口名
virtual_router_id 51
priority 100 # 这个我定义为主,所以优先级不用改
advert_int 1
authentication {
auth_type PASS
auth_pass 123456 # 密码自定义就行
}
virtual_ipaddress {
10.31.200.100 dev ens192 label ens192:0 # 定义虚拟IP,ens192:0表示使用ens192网卡的第一个接口
}
}
4.2 haproxy-02操作
4.2.1 安装haproxy和keepalived
[root@k8s-haproxy02 ~]# yum -y install haproxy keepalived
4.2.2 配置keepalived
[root@k8s-haproxy02 ~]# vim /etc/keepalived/keepalived.conf
global_defs {
router_id lb02 # 不同的keepalived节点id不能相同
}
vrrp_instance VI_1 {
state BACKUP # 改这里
interface ens192 # 改这里
virtual_router_id 51
priority 80 # 改这里
advert_int 1
authentication {
auth_type PASS
auth_pass 123456 # 改这里
}
virtual_ipaddress {
10.31.200.100 dev ens192 label ens192:0 # 改这里
}
}
4.3 启动keepalived
4.3.1 haproxy02操作
[root@k8s-haproxy02 ~]# systemctl start keepalived.service
[root@k8s-haproxy02 ~]# systemctl enable keepalived.service
Created symlink from /etc/systemd/system/multi-user.target.wants/keepalived.service to /usr/lib/systemd/system/keepalived.service.
[root@k8s-haproxy02 ~]# ip a
……省略部分输出
2: ens192: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:50:56:87:29:d4 brd ff:ff:ff:ff:ff:ff
inet 10.31.200.109/24 brd 10.31.200.255 scope global noprefixroute ens192
valid_lft forever preferred_lft forever
inet 10.31.200.100/32 scope global ens192:0 # 虚拟ip
valid_lft forever preferred_lft forever
inet6 fe80::250:56ff:fe87:29d4/64 scope link
valid_lft forever preferred_lft forever
4.3.2 haproxy01操作
[root@k8s-haproxy01 ~]# systemctl start keepalived.service
[root@k8s-haproxy01 ~]# systemctl enable keepalived.service
Created symlink from /etc/systemd/system/multi-user.target.wants/keepalived.service to /usr/lib/systemd/system/keepalived.service.
[root@k8s-haproxy01 ~]# ip a
…………省略部分输出
2: ens192: <BROADCAST,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:50:56:87:d5:5e brd ff:ff:ff:ff:ff:ff
inet 10.31.200.108/24 brd 10.31.200.255 scope global noprefixroute ens192
valid_lft forever preferred_lft forever
inet 10.31.200.100/32 scope global ens192:0 # 可以看到虚拟IP到master节点了
valid_lft forever preferred_lft forever
inet6 fe80::250:56ff:fe87:d55e/64 scope link
valid_lft forever preferred_lft forever
4.3.3 连通性测试
[root@k8s-haproxy01 ~]# ping 10.31.200.100
PING 10.31.200.100 (10.31.200.100) 56(84) bytes of data.
64 bytes from 10.31.200.100: icmp_seq=1 ttl=64 time=0.047 ms
[root@k8s-haproxy02 ~]# ping 10.31.200.100
PING 10.31.200.100 (10.31.200.100) 56(84) bytes of data.
64 bytes from 10.31.200.100: icmp_seq=1 ttl=64 time=0.399 ms
4.4 配置master的负载均衡配置
4.4.1 haproxy01操作
[root@k8s-haproxy01 ~]# cat /etc/haproxy/haproxy.cfg
…………省略部分内容
defaults
mode http
log global
option httplog
option dontlognull
option http-server-close
option forwardfor except 127.0.0.0/8
option redispatch
retries 3
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout http-keep-alive 10s
timeout check 10s
maxconn 3000
listen k8s-api-server-6443 #添加一个listen项
bind 10.31.200.100:6443 # 这里写keepalived的虚拟ip
mode tcp
server k8s-master01 10.31.200.101 check inter 2000 fall 3 rise 5 # check:开启健康检查。inter 2000:间隔时间,2s一次。fall 3:失败3次后把该机器踢出去。rise 5:连续5次检测恢复,再把机器加入到server组中接收请求。
server k8s-master02 10.31.200.102 check inter 2000 fall 3 rise 5
server k8s-master03 10.31.200.103 check inter 2000 fall 3 rise 5
…………省略部分内容
[root@k8s-haproxy01 ~]# systemctl start haproxy
[root@k8s-haproxy01 ~]# systemctl enable haproxy
Created symlink from /etc/systemd/system/multi-user.target.wants/haproxy.service to /usr/lib/systemd/system/haproxy.servic
[root@k8s-haproxy01 ~]# netstat -lntup|grep 6443 # 这里要确保配置的listen是出于监听的
tcp 0 0 10.31.200.100:6443 0.0.0.0:* LISTEN 7128/haproxy
4.4.2 haproxy02操作
这里直接把haproxy01改好的配置scp过来就行
[root@k8s-haproxy01 ~]# cat /etc/haproxy/haproxy.cfg
…………省略部分内容
defaults
mode http
log global
option httplog
option dontlognull
option http-server-close
option forwardfor except 127.0.0.0/8
option redispatch
retries 3
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout http-keep-alive 10s
timeout check 10s
maxconn 3000
listen k8s-api-server-6443 #添加一个listen项
bind 10.31.200.100:6443 # 这里写keepalived的虚拟ip
mode tcp
server k8s-master01 10.31.200.101 check inter 2000 fall 3 rise 5 # check:开启健康检查。inter 2000:间隔时间,2s一次。fall 3:失败3次后把该机器踢出去。rise 5:连续5次检测恢复,再把机器加入到server组中接收请求。
server k8s-master02 10.31.200.102 check inter 2000 fall 3 rise 5
server k8s-master03 10.31.200.103 check inter 2000 fall 3 rise 5
…………省略部分内容
# 但是这里由于haproxy02上是没有10.31.200.100这个ip的,所以启动haproxy就会报错,因为内核不允许监听不存在的地址
[root@k8s-haproxy02 ~]# systemctl start haproxy
[root@k8s-haproxy02 ~]# systemctl enable haproxy
Created symlink from /etc/systemd/system/multi-user.target.wants/haproxy.service to /usr/lib/systemd/system/haproxy.service.
[root@k8s-haproxy02 ~]# haproxy -f /etc/haproxy/haproxy.cfg
[WARNING] 108/074004 (13740) : parsing [/etc/haproxy/haproxy.cfg:45] : 'option httplog' not usable with proxy 'k8s-api-server-6443' (needs 'mode http'). Falling back to 'option tcplog'.
[WARNING] 108/074004 (13740) : config : 'option forwardfor' ignored for proxy 'k8s-api-server-6443' as it requires HTTP mode.
[ALERT] 108/074004 (13740) : Starting proxy k8s-api-server-6443: cannot bind socket [10.31.200.100:6443]
# 解决办法
[root@k8s-haproxy02 ~]# sysctl -a |grep bind
net.ipv4.ip_nonlocal_bind = 0 # 在这个配置就是监听不存在地址的配置,默认是没有打开的,打开就能监听不存在地址了
net.ipv6.bindv6only = 0
sysctl: reading key "net.ipv6.conf.all.stable_secret"
sysctl: reading key "net.ipv6.conf.default.stable_secret"
sysctl: reading key "net.ipv6.conf.ens192.stable_secret"
sysctl: reading key "net.ipv6.conf.lo.stable_secret"
net.ipv6.ip_nonlocal_bind = 0
[root@k8s-haproxy02 ~]# tail -1 /etc/sysctl.conf
net.ipv4.ip_nonlocal_bind = 1
[root@k8s-haproxy02 ~]# sysctl -p
net.ipv4.ip_nonlocal_bind = 1
[root@k8s-haproxy02 ~]# systemctl restart haproxy
[root@k8s-haproxy02 ~]# systemctl status haproxy # 这样haprox就起来了
● haproxy.service - HAProxy Load Balancer
Loaded: loaded (/usr/lib/systemd/system/haproxy.service; enabled; vendor preset: disabled)
Active: active (running) since Wed 2023-04-19 07:45:34 CST; 10s ago
……省略部分输出
[root@k8s-haproxy02 ~]# netstat -lntup |grep 10.31.200.100
tcp 0 0 10.31.200.100:6443 0.0.0.0:* LISTEN 13982/haproxy
5. 安装containerd运行时和harbor仓库
5.1 安装harbor仓库
5.1.1 harbor访问场景
(1)直接使用ip访问 # 不推荐
(2)http域名访问 # 该方式由于没有做https加密,所以只适合在公司内网使用
(3)https自签名证书访问 # 不推荐,因为非权威机构签发的证书是不被容器和浏览器信任的。
(4)https商业机构签发证书访问 # 推荐该方式
5.1.2 安装docker、docker-compose
这里直接使用之前的脚本安装
[root@k8s-harbor01 ~]# sh runtime-install.sh docker
当前系统是CentOS Linux release 7.7.1908 (Core),即将开始系统初始化、配置docker-compose与安装docker
……省略部分内容
docker server安装完成,欢迎进入docker世界!
[root@k8s-harbor01 ~]# docker info|grep 'Server Version'
Server Version: 20.10.19
[root@k8s-harbor01 ~]# cat /etc/docker/daemon.json
{
"data-root": "/data/docker","storage-driver": "overlay2","registry-mirrors": ["https://9916w1ow.mirror.aliyuncs.com"],"live-restore": false,"log-opts": {
"max-file": "5","max-size": "100m"
}
}
[root@k8s-harbor01 ~]# systemctl restart docker
5.1.3 安装harbor
[root@k8s-harbor01 ~]# tar xf harbor-offline-installer-v2.7.1.tgz
[root@k8s-harbor01 ~]# cd harbor/
[root@k8s-harbor01 harbor]# ll
total 740684
-rw-r--r-- 1 root root 3639 Feb 20 16:19 common.sh
-rw-r--r-- 1 root root 758423474 Feb 20 16:19 harbor.v2.7.1.tar.gz
-rw-r--r-- 1 root root 11567 Feb 20 16:19 harbor.yml.tmpl
-rwxr-xr-x 1 root root 3171 Feb 20 16:19 install.sh
-rw-r--r-- 1 root root 11347 Feb 20 16:19 LICENSE
-rwxr-xr-x 1 root root 1881 Feb 20 16:19 prepare
[root@k8s-harbor01 harbor]#
# 配置修改
[root@k8s-harbor01 harbor]# cp harbor.yml.tmpl harbor.yml
[root@k8s-harbor01 harbor]# vim harbor.yml
[root@k8s-harbor01 harbor]# egrep 'hostname:|password:|data_volume:' harbor.yml
hostname: 10.31.200.104
# 然后注释https相关的配置,这里不演示
harbor_admin_password: 123456
data_volume: /data/harbor
[root@k8s-harbor01 harbor]# mkdir /data/harbor
[root@k8s-harbor01 harbor]# ./install.sh
[root@k8s-harbor01 harbor]# docker-compose ps
Name Command State Ports
--------------------------------------------------------------------------------------------------------
harbor-core /harbor/entrypoint.sh Up (healthy)
harbor-db /docker-entrypoint.sh 13 Up (healthy)
harbor-jobservice /harbor/entrypoint.sh Up (healthy)
harbor-log /bin/sh -c /usr/local/bin/ ... Up (healthy) 127.0.0.1:1514->10514/tcp
harbor-portal nginx -g daemon off; Up (healthy)
nginx nginx -g daemon off; Up (healthy) 0.0.0.0:80->8080/tcp,:::80->8080/tcp
redis redis-server /etc/redis.conf Up (healthy)
registry /home/harbor/entrypoint.sh Up (healthy)
registryctl /home/harbor/start.sh Up (healthy)
5.1.4 访问并创建一个私有项目

5.1.5 测试登录
[root@k8s-harbor01 harbor]# cat /etc/docker/daemon.json
{
"insecure-registries" : ["10.31.200.104"],# 添加信任仓库
…………省略部分内容
[root@k8s-harbor01 harbor]# systemctl restart docker
[root@k8s-harbor01 harbor]# docker-compose stop
[root@k8s-harbor01 harbor]# docker-compose start
[root@k8s-harbor01 harbor]# docker login 10.31.200.104
Username: admin
Password:
WARNING! Your password will be stored unencrypted in /root/.docker/config.json.
Configure a credential helper to remove this warning. See
https://docs.docker.com/engine/reference/commandline/login/#credentials-store
Login Succeeded
[root@k8s-harbor01 harbor]# docker tag goharbor/registry-photon:v2.7.1 10.31.200.104/myserver/registry-photon:v2.7.1
[root@k8s-harbor01 harbor]# docker push 10.31.200.104/myserver/registry-photon:v2.7.1
The push refers to repository [10.31.200.104/myserver/registry-photon]
77cd695198ba: Pushed
a76104dd55c5: Pushed
a42372d3c73d: Pushed
23e70dd83173: Pushed
4f730363c02d: Pushed
d635f8a69c64: Pushed
v2.7.1: digest: sha256:3ecfedbdfa91a3220e0c6c30afeb84173953e8b66249f0bac4e00bd916800123 size: 1576
5.2 配置域名+https访问harbor仓库
5.2.1 购买域名
https://wanwang.aliyun.com/?utm_content=se_1013639142



5.2.2 下载ssl证书
阿里云搜索:数字证书管理服务
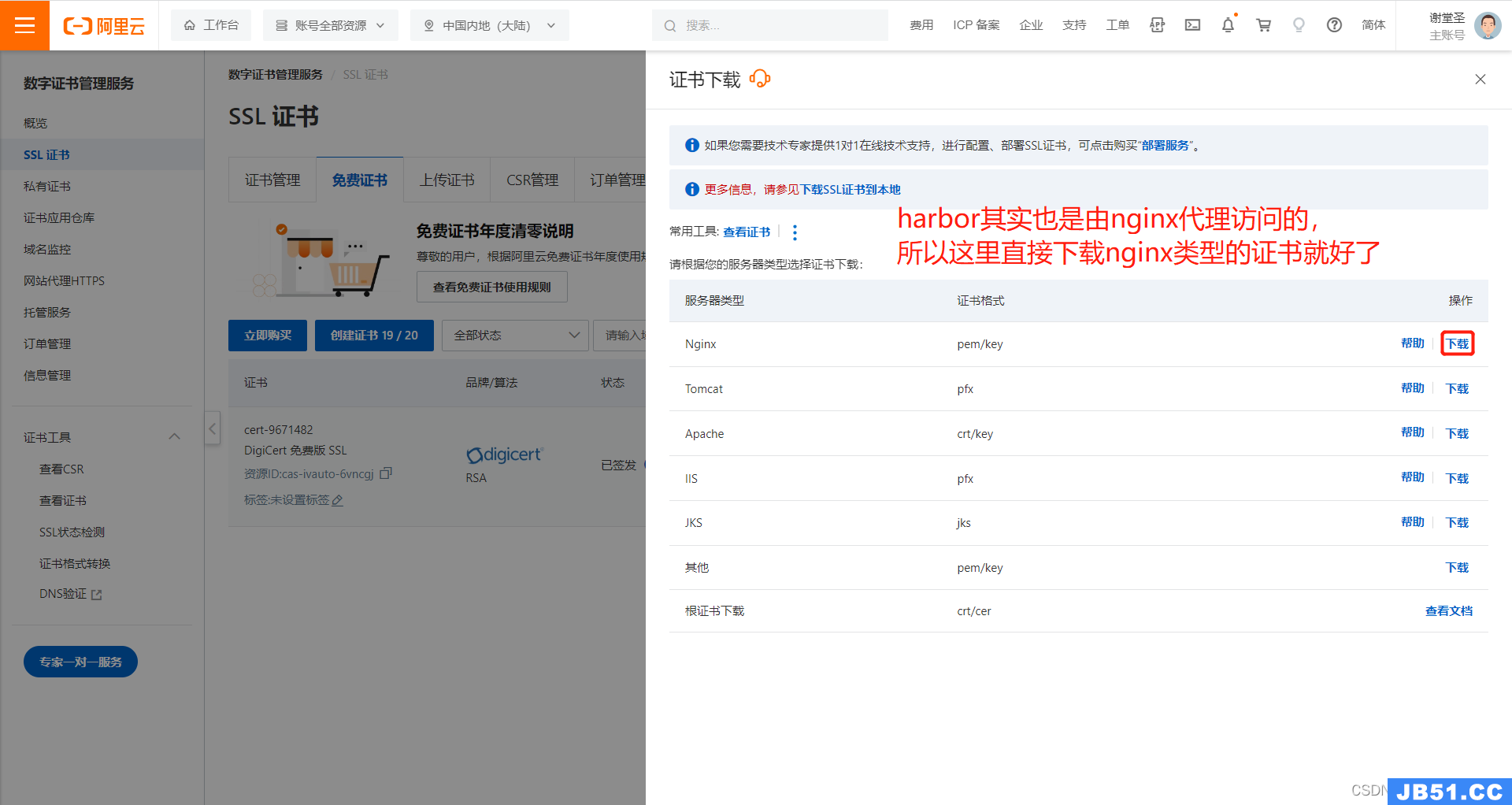
5.2.3 修改harbor配置
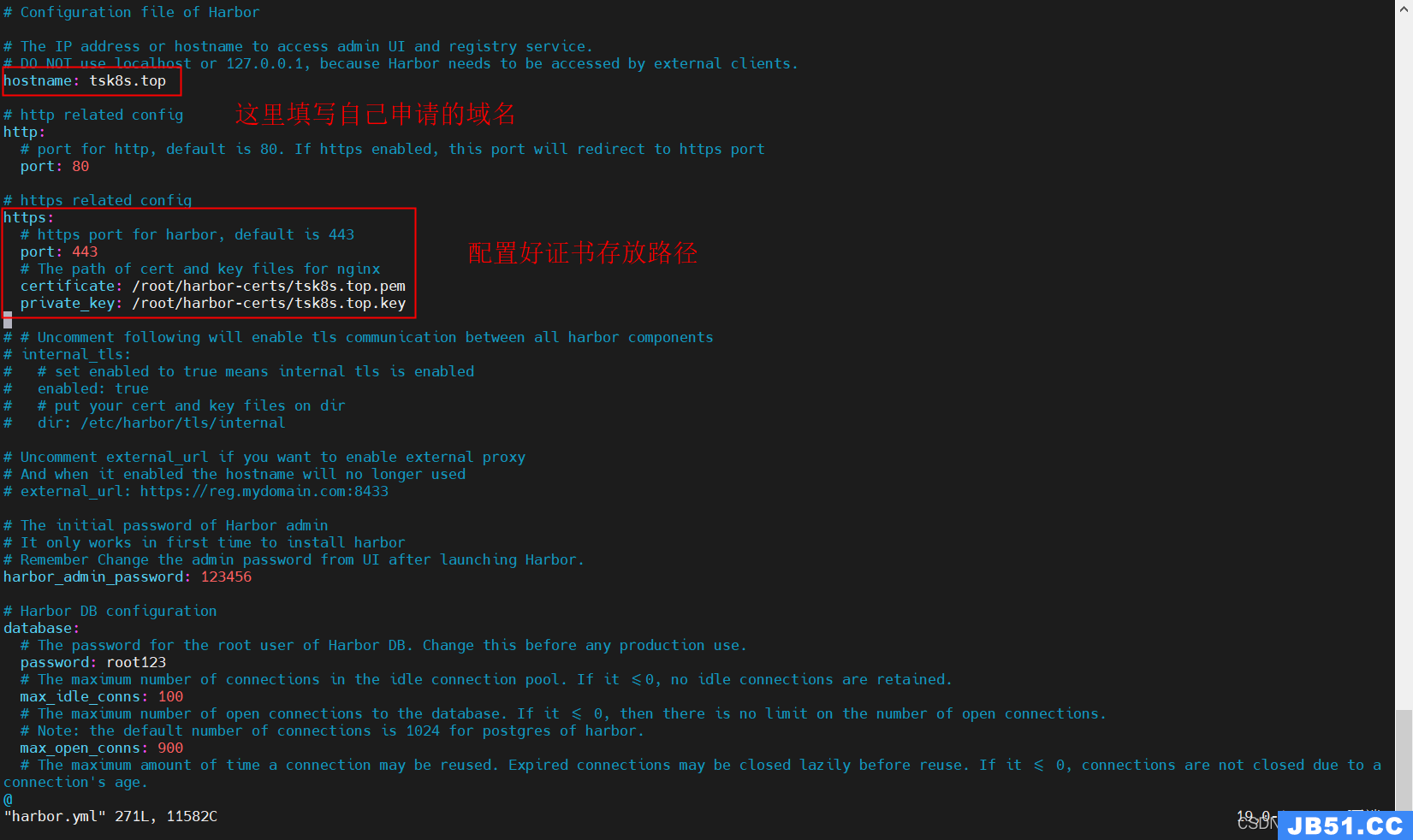
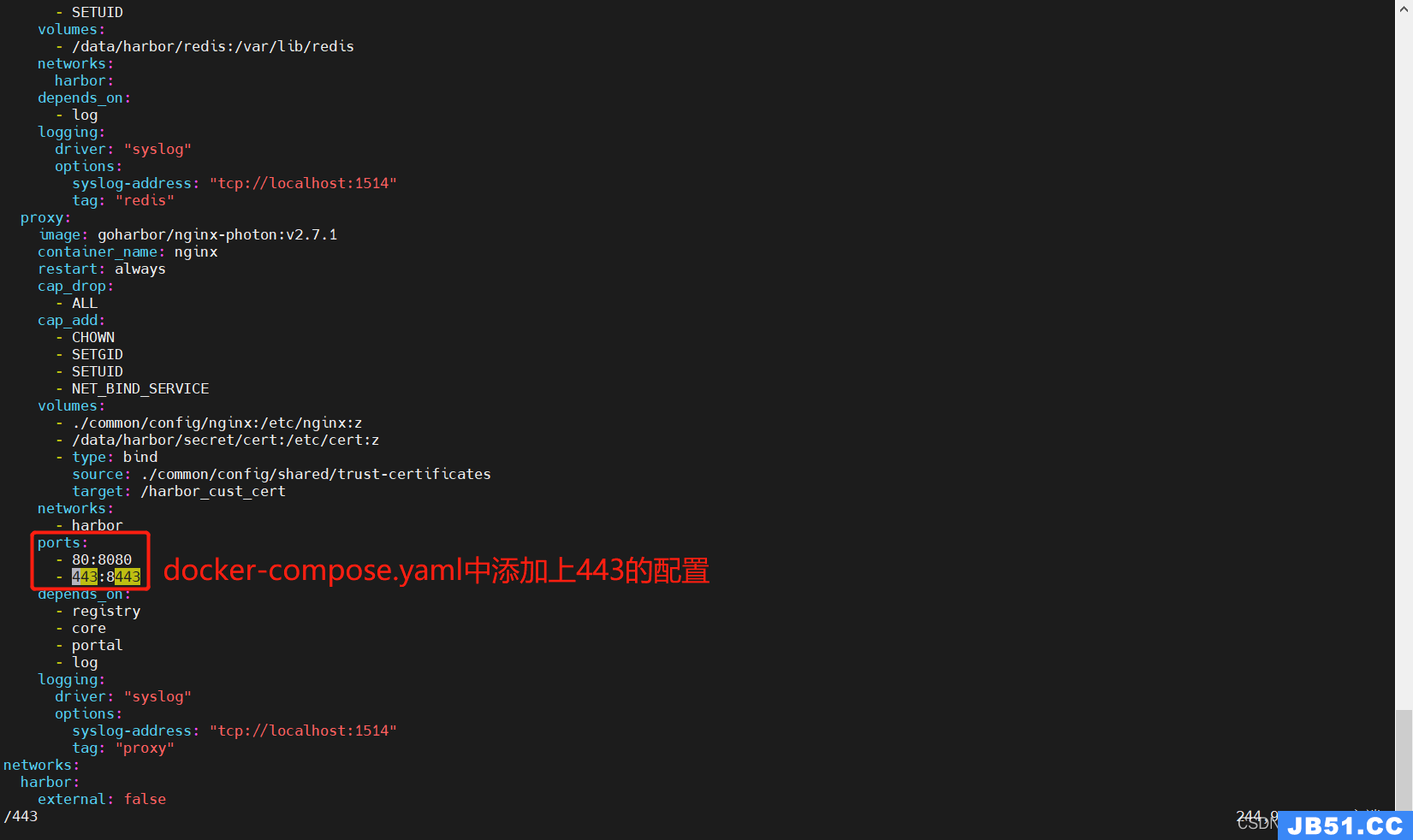
5.2.4 重启harbor
[root@k8s-harbor01 harbor]# docker-compose down
[root@k8s-harbor01 harbor]# docker-compose up -d
5.2.5 访问测试

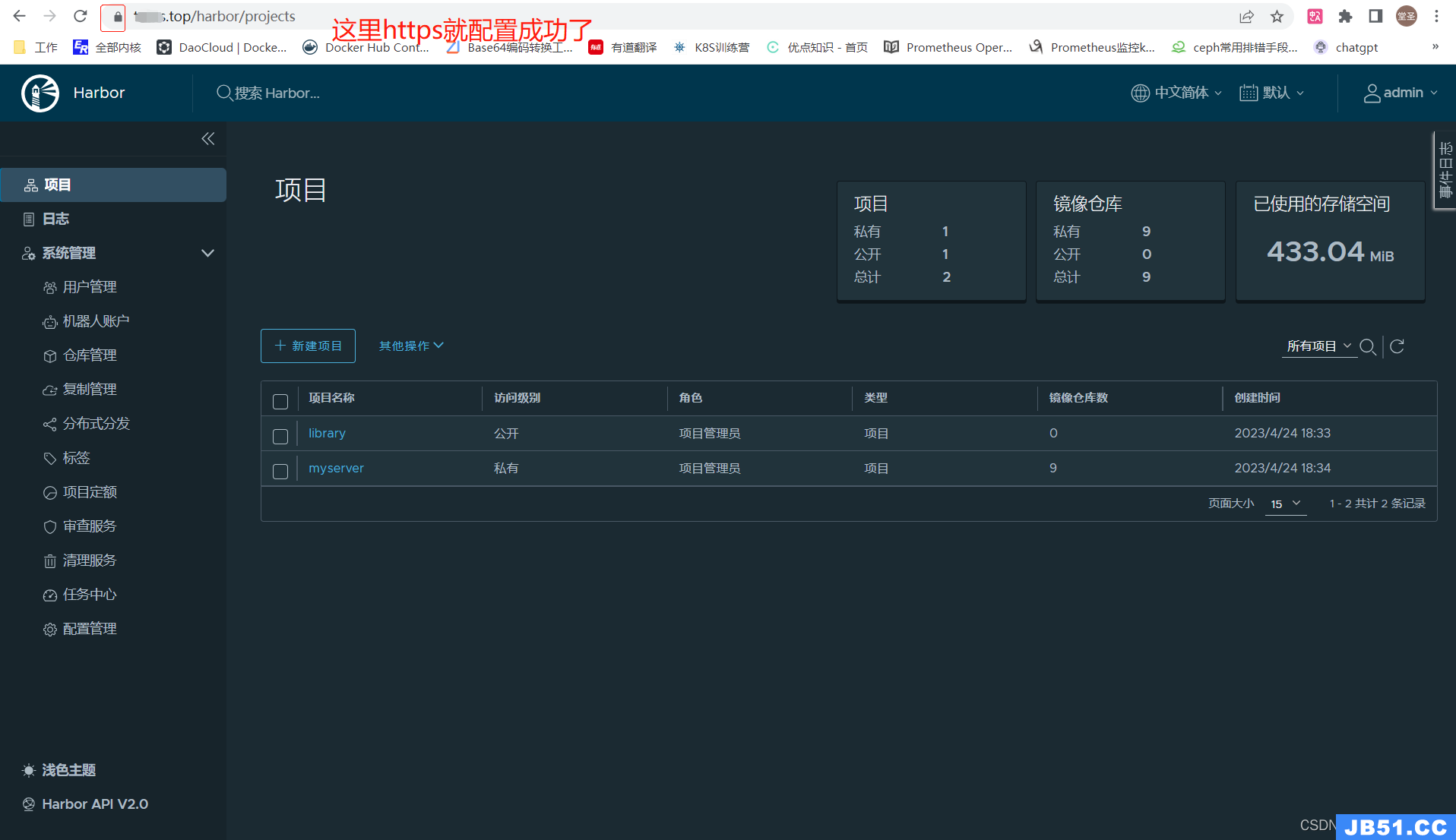
6. kubeasz部署⾼可⽤kubernetes(1.26.x)
kubeasz官网:https://github.com/easzlab/kubeasz
kubeasz 致力于提供快速部署高可用k8s集群的工具,同时也努力成为k8s实践、使用的参考书,基于二进制方式部署和利用ansible-playbook实现自动化;既提供一键安装脚本,也可以根据安装指南分步执行安装各个组件。
kubeasz 从每一个单独部件组装到完整的集群,提供最灵活的配置能力,几乎可以设置任何组件的任何参数;同时又为集群创建预置一套运行良好的默认配置,甚至自动化创建适合大规模集群的BGP Route Reflector网络模式。
6.1 使用 kubeasz前提条件
(1)部署服务器到被部署服务器之间配置好免密登录,并安装好ansible。# 这里我上面已经做了,所以就不用做了。这些步骤kubeasz官网也有
(2)kubeasz不同版本对应不同的k8s版本,下载的时候一定要注意。比如我要安装1.26的k8s集群,那么kubeasz版本就需要3.5.2
6.2 下载kubeasz 3.5.2
[root@k8s-harbor01 ~]# mkdir -p app/k8s
[root@k8s-harbor01 ~]# cd app/k8s
[root@k8s-harbor01 ~]# wget https://github.com/easzlab/kubeasz/releases/download/3.5.2/ezdown
[root@k8s-harbor01 k8s]# ll -h
total 28K
-rw------- 1 root root 25K Apr 20 11:37 ezdown
6.3 执行ezdown脚本
这就是个shell脚本,内容可以自定义
[root@k8s-harbor01 k8s]# chmod u+x ezdown
[root@k8s-harbor01 k8s]# ./ezdown -D # 这里会安装容器运行时和下载很多镜像、配置文件等
…………省略部分内容
2023-04-20 12:08:34 INFO Action successed: download_all
[root@k8s-harbor01 k8s]# ll /etc/kubeasz/
total 92
-rw-rw-r-- 1 root root 20304 Feb 9 22:50 ansible.cfg
drwxr-xr-x 3 root root 4096 Apr 20 11:58 bin
drwxrwxr-x 8 root root 94 Feb 9 23:14 docs
drwxr-xr-x 2 root root 285 Apr 20 12:08 down
drwxrwxr-x 2 root root 70 Feb 9 23:14 example
-rwxrwxr-x 1 root root 26174 Feb 9 22:50 ezctl
-rwxrwxr-x 1 root root 25433 Feb 9 22:50 ezdown
drwxrwxr-x 10 root root 145 Feb 9 23:14 manifests
drwxrwxr-x 2 root root 94 Feb 9 23:14 pics
drwxrwxr-x 2 root root 4096 Feb 9 23:14 playbooks
-rw-rw-r-- 1 root root 5556 Feb 9 22:50 README.md
drwxrwxr-x 22 root root 323 Feb 9 23:14 roles
drwxrwxr-x 2 root root 48 Feb 9 23:14 tools
6.4 重要文件介绍
6.4.1 集群模板文件
[root@k8s-harbor01 example]# ll
total 16
-rw-rw-r-- 1 root root 7231 Feb 9 22:50 config.yml
-rw-rw-r-- 1 root root 2138 Feb 9 22:50 hosts.allinone
-rw-rw-r-- 1 root root 2308 Feb 9 22:50 hosts.multi-node # 这个模版文件,会拷贝给每个集群
[root@k8s-harbor01 example]# pwd
/etc/kubeasz/example
# 'etcd' cluster should have odd member(s) (1,3,5,...)
[etcd] # etcd集群的地址,这个需要自定义。并且还要做好免密认证
192.168.1.1
192.168.1.2
192.168.1.3
[kube_master] # master节点地址,还有主机名(get no显示的名称),这个需要自定义
192.168.1.1 k8s_nodename='master-01'
192.168.1.2 k8s_nodename='master-02'
192.168.1.3 k8s_nodename='master-03'
[kube_node] # node节点配置,需要自定义
192.168.1.4 k8s_nodename='worker-01'
192.168.1.5 k8s_nodename='worker-02'
[harbor] # harbor仓库,默认关闭状态,如果已经自建好了,这个不用开
#192.168.1.8 NEW_INSTALL=false
[ex_lb] # 这个是官方架构图中,提供给kubectl访问的外部负载均衡,默认也是关闭状态。如果需要的话,可以打开或者自建,这里我们已经创建好了haproxy
#192.168.1.6 LB_ROLE=backup EX_APISERVER_VIP=192.168.1.250 EX_APISERVER_PORT=8443
#192.168.1.7 LB_ROLE=master EX_APISERVER_VIP=192.168.1.250 EX_APISERVER_PORT=8443
[chrony] # 时间同步服务器,默认也是关闭的。
#192.168.1.1
[all:vars] # 这个key下面的所有参数,都会传给k8s集群
SECURE_PORT="6443" # api server端口
CONTAINER_RUNTIME="containerd" # k8s集群的容器运行时
CLUSTER_NETWORK="calico" # k8s集群的网络组件,默认使用的calico
PROXY_MODE="ipvs" # kube-proxu的代理模式,默认使用ipvs
SERVICE_CIDR="10.68.0.0/16" # k8s service的网段
CLUSTER_CIDR="172.20.0.0/16" # pod的网段
NODE_PORT_RANGE="30000-32767" # nodeport端口范围
CLUSTER_DNS_DOMAIN="cluster.local" # svc的域名后缀,一般不改这个
bin_dir="/opt/kube/bin" # 二进制文件目录
base_dir="/etc/kubeasz" # kubeasz的部署路径
cluster_dir="{{ base_dir }}/clusters/_cluster_name_" # 集群配置文件生成目录
ca_dir="/etc/kubernetes/ssl" # k8s证书存放目录
k8s_nodename='' # 默认k8sNode节点名称,这个一般都是自定义
6.4.2 config.yml k8s集群配置文件
这里只展示部分配置
CA_EXPIRY: "876000h" # 证书过期时间:ca默认100年
CERT_EXPIRY: "438000h" # 证书过期时间:ca签发的certs默认50年
# kubeconfig 配置参数,这个cluster1是我们下面生成集群配置文件的时候指定的,会添加到kubeconfig配置中
CLUSTER_NAME: "cluster1"
CONTEXT_NAME: "context-{{ CLUSTER_NAME }}"
# k8s version,k8s集群的版本
K8S_VER: "1.26.1"
K8S_NODENAME: "{%- if k8s_nodename != '' -%} \ # 这个值会取hosts里面配置的nodename
{{ k8s_nodename|replace('_','-')|lower }} \
{%- else -%} \
{{ inventory_hostname }} \
{%- endif -%}"
# 设置不同的wal目录,可以避免磁盘io竞争,提高性能
ETCD_DATA_DIR: "/var/lib/etcd" # etcd的数据存储目录,建议使用ssd盘挂载,尽量不要使用机械盘,因为它非常消耗磁盘IO
ETCD_WAL_DIR: ""
# [containerd]基础容器镜像
SANDBOX_IMAGE: "easzlab.io.local:5000/easzlab/pause:3.9" # 容器运行时会按照这个地址去下载pause,可以修改这个地址或者提前把镜像下载下来传到本地harbor仓库
# [containerd]容器持久化存储目录
CONTAINERD_STORAGE_DIR: "/var/lib/containerd" # 这个生产环境的话,建议挂块SSD,来给容器做数据持久化。
# k8s 集群 master 节点证书配置,可以添加多个ip和域名(比如增加公网ip和域名)
MASTER_CERT_HOSTS: # 这个配置是给master签发证书的,我们使用的是haproxy带代理kubectl的请求到apiserver的,所以配置vip就行
- "10.1.1.1" # 这里可以写vip地址
- "k8s.easzlab.io" # 这里写apiserver的域名,有就写 没有就不写
#- "www.test.com"
# node 节点上 pod 网段掩码长度(决定每个节点最多能分配的pod ip地址)
NODE_CIDR_LEN: 24 # 这个就是说每个node可以运行的pod数量,一般一个node运行不到254个pod,因为资源可能会不够,所以这个地址可以适当按需调小
# Kubelet 根目录
KUBELET_ROOT_DIR: "/var/lib/kubelet" # 这个可以不改
# node节点最大pod 数
MAX_PODS: 110 # 这个也可以不改,就算资源不足,也会有调度算法控制调度。但是不要太小,否则就算node有资源,一旦pod数量达到设置的这个值,也会无法调度
# k8s 官方不建议草率开启 system-reserved,除非你基于长期监控,了解系统的资源占用状况;
# 并且随着系统运行时间,需要适当增加资源预留,数值设置详见templates/kubelet-config.yaml.j2
# 系统预留设置基于 4c/8g 虚机,最小化安装系统服务,如果使用高性能物理机可以适当增加预留
# 另外,集群安装时候apiserver等资源占用会短时较大,建议至少预留1g内存
SYS_RESERVED_ENABLED: "no"
# role:network [flannel,calico,cilium,kube-ovn,kube-router] # 网络组件配置,可以只改本次使用的网络组件
# [flannel]设置flannel 后端模型"host-gw","vxlan"等
FLANNEL_BACKEND: "vxlan" # 网络模式
DIRECT_ROUTING: false # 在上面的网络模式下,是否开启直接路由。开:跨主机通信直接通过路由表进行,不在通过隧道封装(因为vxlan默认需要隧道封装),但是打开这个开关后,会不能跨子网通信,不适合复杂的网络环境。
# [flannel]
flannel_ver: "v0.19.2"
# [calico] IPIP隧道模式可选项有: [Always,CrossSubnet,Never],跨子网可以配置为Always与CrossSubnet(公有云建议使用always比较省事,其他的话需要修改各自公有云的网络配置,具体
可以参考各个公有云说明)
# 其次CrossSubnet为隧道+BGP路由混合模式可以提升网络性能,同子网配置为Never即可.
CALICO_IPV4POOL_IPIP: "Always" # Always表示一直开启,这里默认是ipip网络模式,通常情况下,该模式可以满足使用需求,可以跨子网、性能强。
# [calico]设置 calico-node使用的host IP,bgp邻居通过该地址建立,可手工指定也可以自动发现
IP_AUTODETECTION_METHOD: "can-reach={{ groups['kube_master'][0] }}" # 这里默认使用第零块网卡,一般服务器也只有一张网卡。这里会通过ansible自动获取网卡。如果需要自定义的话,可以修改calico的yaml
# [calico]设置calico 网络 backend: brid,vxlan,none
CALICO_NETWORKING_BACKEND: "brid" # brid:bgp协议,通告路由表的。有些公有云上不支持该模式,就只能使用vxlan了
# [calico]设置calico 是否使用route reflectors
# 如果集群规模超过50个节点,建议启用该特性
CALICO_RR_ENABLED: false # 默认情况下,路由表是节点之间互相通告来进行互相学习的,如果节点多,可以打开这个配置,会有一台专门的机器来通告calico的路由表
# CALICO_RR_NODES 配置route reflectors的节点,如果未设置默认使用集群master节点
# CALICO_RR_NODES: ["192.168.1.1","192.168.1.2"]
CALICO_RR_NODES: [] # 开启了上面的配置后,这里需要指定一台用于通告的node节点的ip
############################
# role:cluster-addon # 集群的附加组件,可以让这个工具装,也可以自己手动装
############################
# coredns 自动安装
dns_install: "yes" # 自己装的话改成no
corednsVer: "1.9.3"
ENABLE_LOCAL_DNS_CACHE: true # 域名解析缓存,打开可以提高洗能能,但是也有不好的地方,就是域名已经不用了,可能还会走缓存解析到
dnsNodeCacheVer: "1.22.13"
# 设置 local dns cache 地址
LOCAL_DNS_CACHE: "169.254.20.10"
6.4.3 可执行文件
[root@k8s-harbor01 bin]# pwd
/etc/kubeasz/bin # 这个目录下都是提前下载好的k8s相关的可执行文件,会分发到master节点和node节点
[root@k8s-harbor01 bin]# ll
total 1032152
-rwxr-xr-x 1 root root 4221977 Mar 10 2022 bridge
-rwxr-xr-x 1 root root 59499254 Nov 8 09:37 calicoctl
-rwxr-xr-x 1 root root 14370448 Jan 26 09:51 cfssl
-rwxr-xr-x 1 root root 11817360 Jan 26 09:51 cfssl-certinfo
-rwxr-xr-x 1 root root 7692288 Jan 26 09:51 cfssljson
-rwxr-xr-x 1 root root 1120896 Jan 10 17:48 chronyd
-rwxr-xr-x 1 root root 71020544 Jan 11 17:34 cilium
-rwxr-xr-x 1 root root 39003736 Apr 20 11:51 containerd
drwxr-xr-x 2 root root 171 Jan 26 09:51 containerd-bin
-rwxr-xr-x 1 root root 7450624 Apr 20 11:51 containerd-shim
-rwxr-xr-x 1 root root 9646080 Apr 20 11:51 containerd-shim-runc-v2
-rwxr-xr-x 1 root root 20750336 Apr 20 11:51 ctr
-rwxr-xr-x 1 root root 48045152 Apr 20 11:51 docker
-rwxr-xr-x 1 root root 44920832 Dec 20 17:26 docker-compose
-rwxr-xr-x 1 root root 57790512 Apr 20 11:51 dockerd
-rwxr-xr-x 1 root root 765808 Apr 20 11:51 docker-init
-rwxr-xr-x 1 root root 2556680 Apr 20 11:51 docker-proxy
-rwxr-xr-x 1 root root 23760896 Sep 15 2022 etcd
-rwxr-xr-x 1 root root 17960960 Sep 15 2022 etcdctl
-rwxr-xr-x 1 root root 45125632 Dec 14 23:34 helm
-rwxr-xr-x 1 root root 3241605 Mar 10 2022 host-local
-rwxr-xr-x 1 root root 21831680 Jan 25 01:27 hubble
-rwxr-xr-x 1 root root 1815560 Jan 10 17:49 keepalived
-rwxr-xr-x 1 root root 129957888 Jan 19 00:13 kube-apiserver
-rwxr-xr-x 1 root root 119775232 Jan 19 00:13 kube-controller-manager
-rwxr-xr-x 1 root root 48021504 Jan 19 00:13 kubectl
-rwxr-xr-x 1 root root 121256152 Jan 19 00:13 kubelet
-rwxr-xr-x 1 root root 45010944 Jan 19 00:13 kube-proxy
-rwxr-xr-x 1 root root 52441088 Jan 19 00:13 kube-scheduler
-rwxr-xr-x 1 root root 3295519 Mar 10 2022 loopback
-rwxr-xr-x 1 root root 1806304 Jan 10 17:48 nginx
-rwxr-xr-x 1 root root 3679140 Mar 10 2022 portmap
-rwxr-xr-x 1 root root 13851568 Apr 20 11:51 runc
-rwxr-xr-x 1 root root 3379564 Mar 10 2022 tuning
[root@k8s-harbor01 bin]# ./kube-apiserver --version
Kubernetes v1.26.1
6.5 生成k8s集群配置文件
可以同时管理多个集群,每个集群通过集群名区分,所以集群名必须唯一
6.5.1 创建集群配置文件
# 集群创建完毕后会生成相关的集群配置文件
[root@k8s-harbor01 kubeasz]# ./ezctl new k8s-cluster1
2023-04-20 16:22:08 DEBUG generate custom cluster files in /etc/kubeasz/clusters/k8s-cluster1
2023-04-20 16:22:09 DEBUG set versions
2023-04-20 16:22:09 DEBUG cluster k8s-cluster1: files successfully created.
2023-04-20 16:22:09 INFO next steps 1: to config '/etc/kubeasz/clusters/k8s-cluster1/hosts' # 这个就是上面介绍的模板文件
2023-04-20 16:22:09 INFO next steps 2: to config '/etc/kubeasz/clusters/k8s-cluster1/config.yml'
6.5.2 自定义集群配置文件
这里的操作步骤一定要特别仔细,否则配置改错集群可能会无法使用
[root@k8s-harbor01 kubeasz]# cd /etc/kubeasz/clusters/k8s-cluster1/
[root@k8s-harbor01 k8s-cluster1]# ll
total 12
-rw-r--r-- 1 root root 7131 Apr 20 16:22 config.yml
-rw-r--r-- 1 root root 2306 Apr 20 16:22 hosts
6.5.2.1 修改hosts文件
这里只展示修改的部分
[root@k8s-harbor01 k8s-cluster1]# vim hosts
[etcd] # 修改etcd的地址
10.31.200.105
10.31.200.106
10.31.200.107
[kube_master] # 修改master节点地址和节点名称
10.31.200.101 k8s_nodename='k8s-master01'
10.31.200.102 k8s_nodename='k8s-master02'
#10.31.200.103 k8s_nodename='10.31.200.103' # 这里注释一台,安装完成后演示动态扩容节点
[kube_node] # 修改node节点地址和节点名称
10.31.200.110 k8s_nodename='k8s-node01'
10.31.200.111 k8s_nodename='k8s-node02'
#10.31.200.112 k8s_nodename='10.31.200.112' # 这里注释一台,安装完成后演示动态扩容节点
SERVICE_CIDR="10.100.0.0/16" # 自定义service的网段
CLUSTER_CIDR="10.200.0.0/16" # 自定义pod的网段
bin_dir="/usr/local/bin" # 自定义二进制文件存放路径
6.5.2.1 修改config.yml文件
k8s集群配置文件,依赖上面的hosts文件
这里只展示修改的部分
ETCD_DATA_DIR: "/data/etcd" # 改这个,生产环境的服务肯定会有额外的数据盘,所以这个默认的数据存储目录改到数据盘上
SANDBOX_IMAGE: "10.31.200.104/myserver/pause:3.9" # pod网络环境基础镜像(这基础镜像先拉下来,然后传到我们自己的镜像仓库上,防止从这个默认地址拉不下来)
CONTAINERD_STORAGE_DIR: "/data/containerd" # 改这个
MASTER_CERT_HOSTS:
- "10.31.200.100" # 这个改成keepalived的vip
#- "k8s.easzlab.io" # 我不打算使用域名,所以给它注释了
# coredns 自动安装
dns_install: "no" # 改成no,我自己安装coredns
ENABLE_LOCAL_DNS_CACHE: false # 关闭缓存,等下方面理解pod间的域名解析流程,后续再开启(这个如果打开,那么下面的LOCAL_DNS_CACHE:中的ip,一定要改成coredns的cluster ip)
metricsserver_install: "no" # 这个我也自己安装
dashboard_install: "no" # 这个我也自己安装
# role:harbor
############################
# harbor version,完整版本号
HARBOR_VER: "v2.6.3"
HARBOR_DOMAIN: "harbor.test.com" # 如果harbor有域名和权威机构签发的受信任的证书,可以修改这里的配置为自己的域名,还有下面的端口(我用IP访问的,就不用改了)
HARBOR_PATH: /var/data # 这个不会生效,因为harbor是自建的
HARBOR_TLS_PORT: 8443
HARBOR_REGISTRY: "{{ HARBOR_DOMAIN }}:{{ HARBOR_TLS_PORT }}"
6.6 k8s集群初始化
初始化过程中如果有问题,想回退,可以使用:./ezctl destroy 集群名,类似于kubeadm的reset
6.6.1 准备CA/certs和kubecconfig等系统设置
[root@k8s-harbor01 k8s-cluster1]# cd ../../
[root@k8s-harbor01 kubeasz]# ./ezctl setup --help
Usage: ezctl setup <cluster> <step>
available steps:
01 prepare to prepare CA/certs & kubeconfig & other system settings
02 etcd to setup the etcd cluster
03 container-runtime to setup the container runtime(docker or containerd)
04 kube-master to setup the master nodes
05 kube-node to setup the worker nodes
06 network to setup the network plugin
07 cluster-addon to setup other useful plugins
90 all to run 01~07 all at once
10 ex-lb to install external loadbalance for accessing k8s from outside
11 harbor to install a new harbor server or to integrate with an existed one
examples: ./ezctl setup test-k8s 01 (or ./ezctl setup test-k8s prepare)
./ezctl setup test-k8s 02 (or ./ezctl setup test-k8s etcd)
./ezctl setup test-k8s all
./ezctl setup test-k8s 04 -t restart_maste
[root@k8s-harbor01 kubeasz]# ./ezctl setup k8s-cluster1 01 # 这里会去k8s-cluster1目录中找我们配置的hosts文件和config.yaml文件,进行集群配置,具体的剧本在/etc/kubeasz/playbooks
…………省略部分输出
PLAY RECAP ***************************************************************************************************************************************************************
10.31.200.101 : ok=24 changed=18 unreachable=0 failed=0 skipped=96 rescued=0 ignored=0
10.31.200.102 : ok=24 changed=18 unreachable=0 failed=0 skipped=96 rescued=0 ignored=0
10.31.200.105 : ok=24 changed=19 unreachable=0 failed=0 skipped=96 rescued=0 ignored=0
10.31.200.106 : ok=24 changed=19 unreachable=0 failed=0 skipped=96 rescued=0 ignored=0
10.31.200.107 : ok=24 changed=19 unreachable=0 failed=0 skipped=96 rescued=0 ignored=0
10.31.200.110 : ok=24 changed=18 unreachable=0 failed=0 skipped=96 rescued=0 ignored=0
10.31.200.111 : ok=24 changed=18 unreachable=0 failed=0 skipped=96 rescued=0 ignored=0
localhost : ok=33 changed=31 unreachable=0 failed=0 skipped=11 rescued=0 ignored=0
# 这里顺利执行完毕问题就不大了
6.6.2 设置etcd集群
6.6.2.1 初始化集群
[root@k8s-harbor01 kubeasz]# ./ezctl setup k8s-cluster1 02
…………省略部分输出
PLAY RECAP ***************************************************************************************************************************************************************
10.31.200.105 : ok=10 changed=9 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
10.31.200.106 : ok=8 changed=7 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
10.31.200.107 : ok=8 changed=7 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
# 剧本执行逻辑
[root@k8s-harbor01 kubeasz]# cd playbooks/
[root@k8s-harbor01 playbooks]# cat 02.etcd.yml
# to install etcd cluster
- hosts: etcd
roles:
- etcd
[root@k8s-harbor01 tasks]# pwd
/etc/kubeasz/roles/etcd/tasks
[root@k8s-harbor01 tasks]# ll
total 4
-rw-rw-r-- 1 root root 1591 Feb 9 22:50 main.yml
[root@k8s-harbor01 etcd]# ll templates/etcd.service.j2
-rw-rw-r-- 1 root root 1289 Feb 9 22:50 templates/etcd.service.j2
[root@k8s-harbor01 etcd]# ll templates/etcd-csr.json.j2
-rw-rw-r-- 1 root root 296 Feb 9 22:50 templates/etcd-csr.json.j2 # 自定义证书信息,可以修改这个文件
# 上面这些文件都会读取hosts文件里面的变量,进行相关配置
6.6.2.2 etcd集群检测
检查etcd集群是否配置成功
[root@k8s-harbor01 kubeasz]# ssh k8s-etcd01 # 随便一个etcd节点都可以
[root@k8s-etcd01 ~]# export NODE_IPS="10.31.200.105 10.31.200.106 10.31.200.107"
[root@k8s-etcd01 ~]# for ip in ${NODE_IPS}; do ETCDCTL_API=3 /usr/local/bin/etcdctl --endpoints=https://${ip}:2379 --cacert=/etc/kubernetes/ssl/ca.pem --cert=/etc/kubernetes/ssl/etcd.pem --key=/etc/kubernetes/ssl/etcd-key.pem endpoint health; done
https://10.31.200.105:2379 is healthy: successfully committed proposal: took = 11.706901ms
https://10.31.200.106:2379 is healthy: successfully committed proposal: took = 17.384497ms
https://10.31.200.107:2379 is healthy: successfully committed proposal: took = 22.479634ms
6.7 部署容器运⾏时containerd
6.7.1 修改containerd配置文件
[root@k8s-harbor01 playbooks]# cd ..
[root@k8s-harbor01 kubeasz]# vim roles/containerd/templates/config.toml.j2 # 这个配置文件里面的基础配置 官方都已经配置好了(如镜像加速、pause镜像地址、cgroups使用systemd等),本次需要修改的部分在下面
#https镜像仓库配置下载认证:
[plugins."io.containerd.grpc.v1.cri".registry.configs]
[plugins."io.containerd.grpc.v1.cri".registry.configs."10.31.200.104".tls] # 新增
insecure_skip_verify = true # 新增(跳过不安全的证书验证,没有配置自签https证书访问的,可以不加这个)
[plugins."io.containerd.grpc.v1.cri".registry.configs."10.31.200.104".auth] # 项目设置为公开,可以不配置这个
username = "admin"
password = "123456"
[plugins."io.containerd.grpc.v1.cri".registry.mirrors]
[plugins."io.containerd.grpc.v1.cri".registry.mirrors."10.31.200.104"]
endpoint = ["http://10.31.200.104"]
6.7.2 自定义nerdctl配置
这个需要自己加,kubeasz没有
6.7.2.1 修改配置文件
[root@k8s-harbor01 kubeasz]# vim roles/containerd/tasks/main.yml
# 只展示修改部分
- block:
- name: 准备containerd相关目录
file: name={{ item }} state=directory
with_items:
- "{{ bin_dir }}"
- "/etc/containerd"
- "/etc/nerdctl" # 添加这个
- name: 下载 containerd 二进制文件
copy: src={{ base_dir }}/bin/containerd-bin/{{ item }} dest={{ bin_dir }}/{{ item }} mode=0755
with_items:
- containerd
- containerd-shim
- containerd-shim-runc-v1
- containerd-shim-runc-v2
- crictl
- ctr
- runc
- nerdctl # 添加这个
- containerd-rootless-setuptool.sh # 添加这个
- containerd-rootless.sh # 添加这个
- name: 创建nerdctl配置文件 # 添加这个
template: # 添加这个
src: nerdctl.toml.j2 # 添加这个
dest: /etc/nerdctl/nerdctl.toml # 添加这个
tags: upgrade
6.7.2.2 上传所需文件
# 上传nerdctl到/etc/kubeasz/bin/containerd-bin
[root@k8s-harbor01 containerd-bin]# tar xf nerdctl-1.3.0-linux-amd64.tar.gz
[root@k8s-harbor01 containerd-bin]# ll -rt
total 218044
-rwxr-xr-x 1 root root 9431456 Aug 26 2022 runc
-rwxr-xr-x 1 root root 52586151 Dec 14 15:20 crictl
-rwxr-xr-x 1 root root 26712216 Dec 20 00:53 ctr
-rwxr-xr-x 1 root root 22735256 Dec 20 00:53 containerd-stress
-rwxr-xr-x 1 root root 9375744 Dec 20 00:53 containerd-shim-runc-v2
-rwxr-xr-x 1 root root 9359360 Dec 20 00:53 containerd-shim-runc-v1
-rwxr-xr-x 1 root root 7254016 Dec 20 00:53 containerd-shim
-rwxr-xr-x 1 root root 51529720 Dec 20 00:53 containerd
-rwxr-xr-x 1 root root 7032 Apr 5 20:21 containerd-rootless.sh # 这里
-rwxr-xr-x 1 root root 21622 Apr 5 20:21 containerd-rootless-setuptool.sh # 这里
-rwxr-xr-x 1 root root 24920064 Apr 5 20:22 nerdctl # 这里
-rw------- 1 root root 9328539 Apr 12 16:47 nerdctl-1.3.0-linux-amd64.tar.gz
[root@k8s-harbor01 containerd-bin]# rm -f nerdctl-1.3.0-linux-amd64.tar.gz
# 上传nerdctl配置文件到/etc/kubeasz/roles/containerd/templates
[root@k8s-harbor01 templates]# vim nerdctl.toml.j2
namespace = "k8s.io"
debug = false
debug_full = false
insecure_registry = true
[root@k8s-harbor01 templates]# pwd
/etc/kubeasz/roles/containerd/templates
6.7.3 部署containerd
[root@k8s-harbor01 templates]# cd /etc/kubeasz/
[root@k8s-harbor01 kubeasz]# ./ezctl setup k8s-cluster1 03
……省略部分输出
PLAY RECAP ***************************************************************************************************************************************************************
10.31.200.101 : ok=13 changed=12 unreachable=0 failed=0 skipped=18 rescued=0 ignored=0
10.31.200.102 : ok=13 changed=12 unreachable=0 failed=0 skipped=15 rescued=0 ignored=0
10.31.200.110 : ok=13 changed=12 unreachable=0 failed=0 skipped=15 rescued=0 ignored=0
10.31.200.111 : ok=13 changed=12 unreachable=0 failed=0 skipped=15 rescued=0 ignored=0
6.7.4 安装完成后检查
[root@k8s-harbor01 kubeasz]# cat /etc/ansible/hosts
[k8s_all]
10.31.200.[101:103]
10.31.200.[110:112]
[root@k8s-harbor01 kubeasz]# ansible k8s_all -m shell -a 'nerdctl images' # 因为上面有两个节点是准备后续演示扩容操作的,所以这里没有nerdctl命令
10.31.200.103 | FAILED | rc=127 >>
/bin/sh: nerdctl: command not foundnon-zero return code
10.31.200.110 | CHANGED | rc=0 >>
REPOSITORY TAG IMAGE ID CREATED PLATFORM SIZE BLOB SIZE
nginx latest 63b44e8ddb83 4 minutes ago linux/amd64 147.0 MiB 54.4 MiB
<none> <none> 63b44e8ddb83 4 minutes ago linux/amd64 147.0 MiB 54.4 MiB
10.31.200.111 | CHANGED | rc=0 >>
REPOSITORY TAG IMAGE ID CREATED PLATFORM SIZE BLOB SIZE
nginx latest 63b44e8ddb83 4 minutes ago linux/amd64 147.0 MiB 54.4 MiB
<none> <none> 63b44e8ddb83 4 minutes ago linux/amd64 147.0 MiB 54.4 MiB
10.31.200.102 | CHANGED | rc=0 >>
REPOSITORY TAG IMAGE ID CREATED PLATFORM SIZE BLOB SIZE
nginx latest 63b44e8ddb83 4 minutes ago linux/amd64 147.0 MiB 54.4 MiB
<none> <none> 63b44e8ddb83 4 minutes ago linux/amd64 147.0 MiB 54.4 MiB
10.31.200.101 | CHANGED | rc=0 >>
REPOSITORY TAG IMAGE ID CREATED PLATFORM SIZE BLOB SIZE
10.31.200.112 | FAILED | rc=127 >>
/bin/sh: nerdctl: command not foundnon-zero return code
[root@k8s-harbor01 kubeasz]# ansible k8s_all -m shell -a 'nerdctl pull nginx'
……输出太多不展示了
# 镜像上传测试
[root@k8s-harbor01 kubeasz]# ansible k8s_all -m shell -a 'nerdctl login 10.31.200.104 --username admin --password 123456' # 这里可以把私有改成公有,就不用登录了
[root@k8s-harbor01 kubeasz]# ansible k8s_all -m shell -a 'nerdctl images'
[root@k8s-harbor01 kubeasz]# ansible k8s_all -m shell -a 'nerdctl tag nginx:latest 10.31.200.104/myserver/nginx:latest'
[root@k8s-harbor01 kubeasz]# ansible k8s_all -m shell -a 'nerdctl push 10.31.200.104/myserver/nginx:latest'

6.8 部署k8s master节点
# 这一步没啥要改的,主要是执行这个文件:
[root@k8s-harbor01 kubeasz]# ll roles/kube-master/tasks/main.yml
-rw-rw-r-- 1 root root 5048 Feb 9 22:50 roles/kube-master/tasks/main.yml
[root@k8s-harbor01 kubeasz]# ./ezctl setup k8s-cluster1 04
ansible-playbook -i clusters/k8s-cluster1/hosts -e @clusters/k8s-cluster1/config.yml playbooks/04.kube-master.yml
……省略部分输出
PLAY RECAP ************************************************************************************************************************************************************
10.31.200.101 : ok=57 changed=54 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
10.31.200.102 : ok=55 changed=51 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
[root@k8s-harbor01 kubeasz]# kubectl get no # config文件默认只会生成在部署节点,所以master节点想要执行kubectl的话,需要拷贝config文件上去
NAME STATUS ROLES AGE VERSION
k8s-master01 Ready,SchedulingDisabled master 2m41s v1.26.1
k8s-master02 Ready,SchedulingDisabled master 2m41s v1.26.1
6.9 部署k8s node节点
6.9.1 部署node节点
[root@k8s-harbor01 kubeasz]# ./ezctl setup k8s-cluster1 05
ansible-playbook -i clusters/k8s-cluster1/hosts -e @clusters/k8s-cluster1/config.yml playbooks/05.kube-node.yml
……省略部分输出
PLAY RECAP ************************************************************************************************************************************************************
10.31.200.110 : ok=36 changed=35 unreachable=0 failed=0 skipped=2 rescued=0 ignored=0
10.31.200.111 : ok=36 changed=35 unreachable=0 failed=0 skipped=2 rescued=0 ignored=0
[root@k8s-harbor01 kubeasz]# kubectl get no
NAME STATUS ROLES AGE VERSION
k8s-master01 Ready,SchedulingDisabled master 47m v1.26.1
k8s-master02 Ready,SchedulingDisabled master 47m v1.26.1
k8s-node01 Ready node 14m v1.26.1
k8s-node02 Ready node 14m v1.26.1
6.9.2 关于node节点上的kube-lb说明
主要就是代理node请求本地6443的请求,到upstream
[root@k8s-node01 ~]# ps -ef |grep kube-lb # 这东西其实就是个nginx
root 815131 1 0 17:57 ? 00:00:00 nginx: master process /etc/kube-lb/sbin/kube-lb -c /etc/kube-lb/conf/kube-lb.conf -p /etc/kube-lb
[root@k8s-node01 ~]# cat /etc/kube-lb/conf/kube-lb.conf# 配置文件
user root;
worker_processes 1;
error_log /etc/kube-lb/logs/error.log warn;
events {
worker_connections 3000;
}
stream {
upstream backend {
server 10.31.200.101:6443 max_fails=2 fail_timeout=3s;
server 10.31.200.102:6443 max_fails=2 fail_timeout=3s;
}
server {
listen 127.0.0.1:6443;
proxy_connect_timeout 1s;
proxy_pass backend;
}
}
[root@k8s-node01 ~]# cat /etc/systemd/system/kube-lb.service # nginx启动配置文件
[Unit]
Description=l4 nginx proxy for kube-apiservers
After=network.target
After=network-online.target
Wants=network-online.target
[Service]
Type=forking
ExecStartPre=/etc/kube-lb/sbin/kube-lb -c /etc/kube-lb/conf/kube-lb.conf -p /etc/kube-lb -t
ExecStart=/etc/kube-lb/sbin/kube-lb -c /etc/kube-lb/conf/kube-lb.conf -p /etc/kube-lb
ExecReload=/etc/kube-lb/sbin/kube-lb -c /etc/kube-lb/conf/kube-lb.conf -p /etc/kube-lb -s reload
PrivateTmp=true
Restart=always
RestartSec=15
StartLimitInterval=0
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
6.10 部署网络服务calico
这里建议提前下载好calico镜像上传到自己的仓库中,然后修改配置文件中的地址,以便提高速度
6.10.1 上传相关镜像到镜像仓库
[root@k8s-harbor01 kubeasz]# grep "image:" roles/calico/templates/calico-v3.24.yaml.j2 #这些镜像其实在我们最开始执行ezdown的时候,已经下载到本地了
image: easzlab.io.local:5000/calico/cni:{{ calico_ver }}
image: easzlab.io.local:5000/calico/node:{{ calico_ver }}
image: easzlab.io.local:5000/calico/node:{{ calico_ver }}
image: easzlab.io.local:5000/calico/kube-controllers:{{ calico_ver }}
[root@k8s-harbor01 kubeasz]# docker tag easzlab.io.local:5000/calico/kube-controllers:v3.24.5 10.31.200.104/myserver/calico/kube-controllers:v3.24.5
[root@k8s-harbor01 kubeasz]# docker push 10.31.200.104/myserver/calico/kube-controllers:v3.24.5
[root@k8s-harbor01 kubeasz]# docker tag easzlab.io.local:5000/calico/cni:v3.24.5 10.31.200.104/myserver/calico/cni:v3.24.5
[root@k8s-harbor01 kubeasz]# docker push 10.31.200.104/myserver/calico/cni:v3.24.5
[root@k8s-harbor01 kubeasz]# docker tag easzlab.io.local:5000/calico/node:v3.24.5 10.31.200.104/myserver/calico/node:v3.24.5
[root@k8s-harbor01 kubeasz]# docker push 10.31.200.104/myserver/calico/node:v3.24.5
[root@k8s-harbor01 kubeasz]# cp roles/calico/templates/calico-v3.24.yaml.j2{,.bak}
[root@k8s-harbor01 kubeasz]# sed -i "s#easzlab.io.local:5000#10.31.200.104/myserver#g" roles/calico/templates/calico-v3.24.yaml.j2
[root@k8s-harbor01 kubeasz]# grep image: roles/calico/templates/calico-v3.24.yaml.j2
image: 10.31.200.104/myserver/calico/cni:{{ calico_ver }}
image: 10.31.200.104/myserver/calico/node:{{ calico_ver }}
image: 10.31.200.104/myserver/calico/node:{{ calico_ver }}
image: 10.31.200.104/myserver/calico/kube-controllers:{{ calico_ver }}
[root@k8s-harbor01 ~]# docker tag easzlab.io.local:5000/easzlab/pause:3.9 10.31.200.104/myserver/pause:3.9
[root@k8s-harbor01 ~]# docker push 10.31.200.104/myserver/pause:3.9

6.10.2 使用https访问仓库注意事项
因为我直接用ip访问的,所以不需要调整下相关配置
#https镜像仓库配置下载认证:
[plugins."io.containerd.grpc.v1.cri".registry.configs]
[plugins."io.containerd.grpc.v1.cri".registry.configs."10.31.200.104".tls] # 新增
insecure_skip_verify = true # 新增(跳过不安全的证书验证,没有配置自签https证书访问的,可以不加这个)
[plugins."io.containerd.grpc.v1.cri".registry.configs."10.31.200.104".auth] #新增(项目设置为公开,可以不配置这个)
username = "admin" # 新增
password = "123456" # 新增
[plugins."io.containerd.grpc.v1.cri".registry.mirrors]
[plugins."io.containerd.grpc.v1.cri".registry.mirrors."10.31.200.104"] # 新增
endpoint = ["http://10.31.200.104"] # 新增
6.10.3 部署calico
[root@k8s-harbor01 kubeasz]# ./ezctl setup k8s-cluster1 06
ansible-playbook -i clusters/k8s-cluster1/hosts -e @clusters/k8s-cluster1/config.yml playbooks/06.network.yml
……省略部分输出
#如果这里一直卡着,没有向下执行,很可能是因为pause镜像拉不下来,get po -A也会发现下面的pod不能running
[root@k8s-harbor01 kubeasz]# kubectl get po -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system calico-kube-controllers-b6445bbf8-tnnrv 1/1 Running 0 153m
kube-system calico-node-59gth 1/1 Running 0 149m
kube-system calico-node-772m2 1/1 Running 0 3h9m
kube-system calico-node-pldp8 1/1 Running 0 153m
kube-system calico-node-pr24l 1/1 Running 0 166m
# 可以在任意k8s节点执行下面的命令检查路由关系建立是否成功
[root@k8s-harbor01 kubeasz]# ansible k8s_all -m shell -a 'calicoctl node status'
10.31.200.103 | FAILED | rc=127 >>
/bin/sh: calicoctl: 未找到命令non-zero return code
10.31.200.110 | CHANGED | rc=0 >>
Calico process is running.
IPv4 BGP status
+---------------+-------------------+-------+----------+-------------+
| PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO |
+---------------+-------------------+-------+----------+-------------+
| 10.31.200.101 | node-to-node mesh | up | 03:09:52 | Established |
| 10.31.200.102 | node-to-node mesh | up | 03:09:52 | Established |
| 10.31.200.111 | node-to-node mesh | up | 03:14:13 | Established |
+---------------+-------------------+-------+----------+-------------+
IPv6 BGP status
No IPv6 peers found.
10.31.200.111 | CHANGED | rc=0 >>
Calico process is running.
IPv4 BGP status
+---------------+-------------------+-------+----------+-------------+
| PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO |
+---------------+-------------------+-------+----------+-------------+
| 10.31.200.101 | node-to-node mesh | up | 03:14:13 | Established |
| 10.31.200.102 | node-to-node mesh | up | 03:14:13 | Established |
| 10.31.200.110 | node-to-node mesh | up | 03:14:13 | Established |
+---------------+-------------------+-------+----------+-------------+
IPv6 BGP status
No IPv6 peers found.
10.31.200.112 | FAILED | rc=127 >>
/bin/sh: calicoctl: 未找到命令non-zero return code
10.31.200.101 | CHANGED | rc=0 >>
Calico process is running.
IPv4 BGP status
+---------------+-------------------+-------+----------+-------------+
| PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO |
+---------------+-------------------+-------+----------+-------------+
| 10.31.200.102 | node-to-node mesh | up | 02:57:26 | Established |
| 10.31.200.110 | node-to-node mesh | up | 03:09:52 | Established |
| 10.31.200.111 | node-to-node mesh | up | 03:14:13 | Established |
+---------------+-------------------+-------+----------+-------------+
IPv6 BGP status
No IPv6 peers found.
10.31.200.102 | CHANGED | rc=0 >>
Calico process is running.
IPv4 BGP status
+---------------+-------------------+-------+----------+-------------+
| PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO |
+---------------+-------------------+-------+----------+-------------+
| 10.31.200.101 | node-to-node mesh | up | 02:57:26 | Established |
| 10.31.200.110 | node-to-node mesh | up | 03:09:51 | Established |
| 10.31.200.111 | node-to-node mesh | up | 03:14:13 | Established |
+---------------+-------------------+-------+----------+-------------+
IPv6 BGP status
No IPv6 peers found.
6.10.4 创建pod测试网络
6.10.4.1 拷贝k8s config文件到任意master节点
[root@k8s-harbor01 ~]# scp .kube/config k8s-master01:/root/.kube/
config
[root@k8s-harbor01 ~]# !ss
ssh k8s-master01
[root@k8s-master01 ~]# grep 6443 .kube/config
server: https://10.31.200.100:6443 # 这个地址替换到我们之前设置的vip地址
[root@k8s-master01 ~]# kubectl get po -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system calico-kube-controllers-b6445bbf8-tnnrv 1/1 Running 0 3h30m
kube-system calico-node-59gth 1/1 Running 0 3h25m
kube-system calico-node-772m2 1/1 Running 0 4h5m
kube-system calico-node-pldp8 1/1 Running 0 3h29m
kube-system calico-node-pr24l 1/1 Running 0 3h42m
6.10.4.2 创建pod测试网络
[root@k8s-master01 ~]# kubectl run net-test --image=10.31.200.104/myserver/centos:7.9.2009 sleep 1000000000
pod/net-test created
[root@k8s-master01 ~]# kubectl run net-test1 --image=10.31.200.104/myserver/centos:7.9.2009 sleep 1000000000
pod/net-test created
[root@k8s-master01 ~]# kubectl run net-test2 --image=10.31.200.104/myserver/centos:7.9.2009 sleep 1000000000
pod/net-test created
[root@k8s-master01 ~]# kubectl get po -o wide # 只要每个node都有一个pod运行就行了
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
net-test 1/1 Running 0 2m6s 10.200.58.193 k8s-node02 <none> <none>
net-test1 1/1 Running 0 67s 10.200.58.194 k8s-node02 <none> <none>
net-test2 1/1 Running 0 63s 10.200.85.193 k8s-node01 <none> <none>
# 测试外网能不能通
[root@k8s-master01 ~]# kubectl exec -it net-test -- /bin/bash
[root@net-test /]# ping 223.6.6.6 # ping一个外网ip试试能不能通
PING 223.6.6.6 (223.6.6.6) 56(84) bytes of data.
64 bytes from 223.6.6.6: icmp_seq=1 ttl=116 time=3.83 ms
# 测试跨主机能通不能
[root@net-test /]# ping 10.200.85.193 # test是node02 我ping node01来检测跨宿主机通信
PING 10.200.85.193 (10.200.85.193) 56(84) bytes of data.
64 bytes from 10.200.85.193: icmp_seq=1 ttl=62 time=0.753 ms
# 这个时候是ping不通域名的,因为还没安装dns插件,所以没法进行域名解析
[root@net-test /]# ping www.baidu.com
^C
6.11 集群节点伸缩管理
集群管理主要是添加master、添加node、删除master与删除node等节点管理及监控当前集群状态。
6.11.1 添加node节点
之前一共是规划了3台node节点的,这里演示如果添加node节点到集群中
6.11.1.1 扩容前的准备工作
(1)做好被扩容节点的基础优化工作,如软件包安装、内核升级等。(我这里已经提前做过了)
(2)做好部署节点到被扩容节点的免密登录(我这里已经提前做过了)
6.11.1.2 使用ezctl扩容node节点
[root@k8s-harbor01 kubeasz]# ./ezctl add-node k8s-cluster1 10.31.200.112 k8s_nodename=\'k8s-node03\'
……省略部分输出
PLAY RECAP ************************************************************************************************************************************************************
10.31.200.112 : ok=82 changed=56 unreachable=0 failed=0 skipped=156 rescued=0 ignored=0
[root@k8s-harbor01 kubeasz]# kubectl get no
NAME STATUS ROLES AGE VERSION
k8s-master01 Ready,SchedulingDisabled master 42h v1.26.1
k8s-master02 Ready,SchedulingDisabled master 42h v1.26.1
k8s-node01 Ready node 42h v1.26.1
k8s-node02 Ready node 42h v1.26.1
k8s-node03 Ready node 2m48s v1.26.1 # 新节点添加成功
6.11.1.3 创建pod测试新加节点网络
[root@k8s-master01 ~]# kubectl run net-test3 --image=10.31.200.104/myserver/centos:7.9.2009 sleep 1000000000
[root@net-test3 /]# ping 10.200.85.193 # 跨主机通信测试
PING 10.200.85.193 (10.200.85.193) 56(84) bytes of data.
64 bytes from 10.200.85.193: icmp_seq=1 ttl=62 time=0.789 ms
^C
--- 10.200.85.193 ping statistics ---
1 packets transmitted,1 received,0% packet loss,time 0ms
rtt min/avg/max/mdev = 0.789/0.789/0.789/0.000 ms
[root@net-test3 /]# ping 8.8.8.8 # 外网通信测试
PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data.
64 bytes from 8.8.8.8: icmp_seq=1 ttl=50 time=49.6 ms
^C
6.11.2 添加mster节点
6.11.2.1 扩容前的准备工作
(1)做好被扩容节点的基础优化工作,如软件包安装、内核升级等。(我这里已经提前做过了)
(2)做好部署节点到被扩容节点的免密登录(我这里已经提前做过了)
6.11.2.2 使用ezctl扩容master节点
[root@k8s-harbor01 kubeasz]# ./ezctl add-master k8s-cluster1 10.31.200.103 k8s_nodename=\'k8s-master03\'
……省略部分输出
2023-04-23 17:58:00 INFO reconfigure and restart 'ex-lb' service
PLAY [ex_lb] **********************************************************************************************************************************************************
skipping: no hosts matched
PLAY RECAP ***********************************************************************************************************************************************************
[root@k8s-harbor01 kubeasz]# kubectl get no
NAME STATUS ROLES AGE VERSION
k8s-master01 Ready,SchedulingDisabled master 43h v1.26.1
k8s-master02 Ready,SchedulingDisabled master 43h v1.26.1
k8s-master03 Ready,SchedulingDisabled master 3m29s v1.26.1 # 节点添加成功
k8s-node01 Ready node 42h v1.26.1
k8s-node02 Ready node 42h v1.26.1
k8s-node03 Ready node 29m v1.26.1
6.11.2.3 关于扩容master节点后,node节点上的nginx配置变更
# master节点扩容完毕后,各node上的nginx配置也会实时更新
[root@k8s-node01 ~]# cat /etc/kube-lb/conf/kube-lb.conf
user root;
worker_processes 1;
error_log /etc/kube-lb/logs/error.log warn;
events {
worker_connections 3000;
}
stream {
upstream backend {
server 10.31.200.103:6443 max_fails=2 fail_timeout=3s; # 这就是添加完master节点后剧本自动添加的内容
server 10.31.200.101:6443 max_fails=2 fail_timeout=3s;
server 10.31.200.102:6443 max_fails=2 fail_timeout=3s;
}
server {
listen 127.0.0.1:6443;
proxy_connect_timeout 1s;
proxy_pass backend;
}
}
6.12 部署内部域名解析服务-CoredDNS
⽬前常⽤的dns组件有kube-dns和coredns两个,到k8s版本 1.17.X都可以使⽤,kube-dns和coredns⽤于解析k8s集群中service name所对应得到IP地址,从kubernetes v1.18开始不⽀持使⽤kube-dns。
6.12.1 准备CoredDNS的yaml
官网:https://coredns.io/plugins/kubernetes/
github上的yaml:https://github.com/coredns/deployment/blob/master/kubernetes/coredns.yaml.sed
[root@k8s-harbor01 yaml]# cat coredns-v1.9.4.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: coredns
namespace: kube-system
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
kubernetes.io/bootstrapping: rbac-defaults
addonmanager.kubernetes.io/mode: Reconcile
name: system:coredns
rules:
- apiGroups:
- ""
resources:
- endpoints
- services
- pods
- namespaces
verbs:
- list
- watch
- apiGroups:
- ""
resources:
- nodes
verbs:
- get
- apiGroups:
- discovery.k8s.io
resources:
- endpointslices
verbs:
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
annotations:
rbac.authorization.kubernetes.io/autoupdate: "true"
labels:
kubernetes.io/bootstrapping: rbac-defaults
addonmanager.kubernetes.io/mode: EnsureExists
name: system:coredns
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:coredns
subjects:
- kind: ServiceAccount
name: coredns
namespace: kube-system
---
apiVersion: v1
kind: ConfigMap
metadata:
name: coredns
namespace: kube-system
labels:
addonmanager.kubernetes.io/mode: EnsureExists
data:
Corefile: |
.:53 {
errors
health {
lameduck 5s
}
ready
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
fallthrough in-addr.arpa ip6.arpa
ttl 30
}
prometheus :9153
#forward . /etc/resolv.conf {
forward . 223.6.6.6 {
max_concurrent 1000
}
cache 600
loop
reload
loadbalance
}
myserver.online {
forward . 172.16.16.16:53
}
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: coredns
namespace: kube-system
labels:
k8s-app: kube-dns
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/name: "CoreDNS"
spec:
# replicas: not specified here:
# 1. In order to make Addon Manager do not reconcile this replicas parameter.
# 2. Default is 1.
# 3. Will be tuned in real time if DNS horizontal auto-scaling is turned on.
replicas: 2
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1
selector:
matchLabels:
k8s-app: kube-dns
template:
metadata:
labels:
k8s-app: kube-dns
spec:
securityContext:
seccompProfile:
type: RuntimeDefault
priorityClassName: system-cluster-critical
serviceAccountName: coredns
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: k8s-app
operator: In
values: ["kube-dns"]
topologyKey: kubernetes.io/hostname
tolerations:
- key: "CriticalAddonsOnly"
operator: "Exists"
nodeSelector:
kubernetes.io/os: linux
containers:
- name: coredns
image: coredns/coredns:1.9.4
imagePullPolicy: IfNotPresent
resources:
limits:
memory: 256Mi
cpu: 200m
requests:
cpu: 100m
memory: 70Mi
args: [ "-conf","/etc/coredns/Corefile" ]
volumeMounts:
- name: config-volume
mountPath: /etc/coredns
readOnly: true
ports:
- containerPort: 53
name: dns
protocol: UDP
- containerPort: 53
name: dns-tcp
protocol: TCP
- containerPort: 9153
name: metrics
protocol: TCP
livenessProbe:
httpGet:
path: /health
port: 8080
scheme: HTTP
initialDelaySeconds: 60
timeoutSeconds: 5
successThreshold: 1
failureThreshold: 5
readinessProbe:
httpGet:
path: /ready
port: 8181
scheme: HTTP
securityContext:
allowPrivilegeEscalation: false
capabilities:
add:
- NET_BIND_SERVICE
drop:
- all
readOnlyRootFilesystem: true
dnsPolicy: Default
volumes:
- name: config-volume
configMap:
name: coredns
items:
- key: Corefile
path: Corefile
---
apiVersion: v1
kind: Service
metadata:
name: kube-dns
namespace: kube-system
annotations:
prometheus.io/port: "9153"
prometheus.io/scrape: "true"
labels:
k8s-app: kube-dns
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/name: "CoreDNS"
spec:
selector:
k8s-app: kube-dns
clusterIP: 10.100.0.2
ports:
- name: dns
port: 53
protocol: UDP
- name: dns-tcp
port: 53
protocol: TCP
- name: metrics
port: 9153
protocol: TCP
6.12.2 创建coredns
[root@k8s-harbor01 yaml]# kubectl apply -f coredns-v1.9.4.yaml
serviceaccount/coredns created
clusterrole.rbac.authorization.k8s.io/system:coredns created
clusterrolebinding.rbac.authorization.k8s.io/system:coredns created
configmap/coredns created
deployment.apps/coredns created
service/kube-dns created
[root@k8s-harbor01 ~]# kubectl get po -A -o wide|grep coredns
kube-system coredns-5879bb4b8c-bq5xp 1/1 Running 0 9h 10.200.135.130 k8s-node03 <none> <none>
kube-system coredns-5879bb4b8c-qnmtc 1/1 Running 0 9h 10.200.85.194 k8s-node01 <none> <none>
6.12.3 测试域名解析
[root@k8s-harbor01 ~]# kubectl exec -it net-test3 -- ping -c 2 www.baidu.com
PING www.a.shifen.com (110.242.68.4) 56(84) bytes of data.
64 bytes from 110.242.68.4 (110.242.68.4): icmp_seq=1 ttl=44 time=10.7 ms
64 bytes from 110.242.68.4 (110.242.68.4): icmp_seq=2 ttl=44 time=10.7 ms
--- www.a.shifen.com ping statistics ---
2 packets transmitted,2 received,time 1001ms
rtt min/avg/max/mdev = 10.762/10.765/10.769/0.103 ms
6.12.4 coredns的svc为什么要叫kube-dns
[root@k8s-harbor01 ~]# kubectl get svc -A
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
default kubernetes ClusterIP 10.100.0.1 <none> 443/TCP 2d12h
kube-system kube-dns ClusterIP 10.100.0.2 <none> 53/UDP,53/TCP,9153/TCP 11h
# 原因:之所以叫kube-dns是遗留问题,在k8s早期版本,dns插件的svc名都叫kube-dns,这就导致有些组件在通过内部域名调用dns插件的时候,依然访问的是kube-dns,所以这里如果修改了coredns svc的名称,可能会导致有些插件调用失败。
6.12.5 为什么要替换原有的kube-dns
(1)k8s 1.18开始不再支持kube-dns
(2)kube-dns pod中包含了3个容器,太臃肿了:
kube-dns:提供service name域名的解析
dns-dnsmasq:提供DNS缓存,降低kubedns负载,提⾼性能
dns-sidecar:定期检查kubedns和dnsmasq的健康状态
7. 集群升级
对当前kubernetes 集群进⾏版本更新,解决已知bug或新增某些功能。
升级会涉及到服务停止,一定要规划好时间,生产环境最好晚上。
本次升级从1.26.1升级到1.26.4(小版本升级从1到10也没关系,跨大版本升级需要注意,并且要做大量的测试先)
7.1 批量更新
7.1.1 下载1.26.4软件包
这些都是二进制文件
https://dl.k8s.io/v1.26.4/kubernetes-client-linux-amd64.tar.gz
https://dl.k8s.io/v1.26.4/kubernetes-server-linux-amd64.tar.gz
https://dl.k8s.io/v1.26.4/kubernetes-node-linux-amd64.tar.gz

7.1.2 上传软件包
[root@k8s-harbor01 1.26.4]# unzip kubernetes-1.26.4.zip # 这是我自己打的包
Archive: kubernetes-1.26.4.zip
inflating: kubernetes-client-linux-amd64.tar.gz
inflating: kubernetes-node-linux-amd64.tar.gz
inflating: kubernetes-server-linux-amd64.tar.gz
[root@k8s-harbor01 1.26.4]# ll -h
总用量 975M
-rw-r--r-- 1 root root 486M 4月 23 22:37 kubernetes-1.26.4.zip
-rw-r--r-- 1 root root 32M 4月 17 16:04 kubernetes-client-linux-amd64.tar.gz
-rw-r--r-- 1 root root 125M 4月 17 16:04 kubernetes-node-linux-amd64.tar.gz
-rw-r--r-- 1 root root 333M 4月 17 16:04 kubernetes-server-linux-amd64.tar.gz
7.1.3 解压
7.1.3.1 解压client包
[root@k8s-harbor01 1.26.4]# tar xf kubernetes-client-linux-amd64.tar.gz
[root@k8s-harbor01 1.26.4]# ll -rt kubernetes
总用量 0
drwxr-xr-x 3 root root 17 4月 12 20:26 client
7.1.3.2 解压node包
[root@k8s-harbor01 1.26.4]# tar xf kubernetes-node-linux-amd64.tar.gz
[root@k8s-harbor01 1.26.4]# ll -rt kubernetes/
总用量 37328
drwxr-xr-x 3 root root 17 4月 12 20:26 client
drwxr-xr-x 3 root root 17 4月 12 20:27 node #这个
drwxr-xr-x 4 root root 68 4月 12 20:27 LICENSES #这个
-rw-r--r-- 1 root root 38221728 4月 12 20:27 kubernetes-src.tar.gz #这个
7.1.3.3 解压server包
[root@k8s-harbor01 1.26.4]# tar xf kubernetes-server-linux-amd64.tar.gz
[root@k8s-harbor01 1.26.4]# ll -rt kubernetes
总用量 37328
drwxr-xr-x 3 root root 17 4月 12 20:26 client
drwxr-xr-x 3 root root 17 4月 12 20:27 node
drwxr-xr-x 3 root root 17 4月 12 20:27 server #这个
drwxr-xr-x 2 root root 6 4月 12 20:28 addons #这个
drwxr-xr-x 4 root root 68 4月 12 20:28 LICENSES
-rw-r--r-- 1 root root 38221728 4月 12 20:28 kubernetes-src.tar.gz
[root@k8s-harbor01 1.26.4]# ll kubernetes/server/bin/
总用量 1095508
-rwxr-xr-x 1 root root 57401344 4月 12 20:28 apiextensions-apiserver
-rwxr-xr-x 1 root root 46784512 4月 12 20:28 kubeadm
-rwxr-xr-x 1 root root 55296000 4月 12 20:28 kube-aggregator
-rwxr-xr-x 1 root root 129986560 4月 12 20:28 kube-apiserver
-rw-r--r-- 1 root root 8 4月 12 20:27 kube-apiserver.docker_tag
-rw------- 1 root root 135430656 4月 12 20:27 kube-apiserver.tar
-rwxr-xr-x 1 root root 119361536 4月 12 20:28 kube-controller-manager
-rw-r--r-- 1 root root 8 4月 12 20:27 kube-controller-manager.docker_tag
-rw------- 1 root root 124805120 4月 12 20:27 kube-controller-manager.tar
-rwxr-xr-x 1 root root 48037888 4月 12 20:28 kubectl
-rwxr-xr-x 1 root root 57782856 4月 12 20:28 kubectl-convert
-rwxr-xr-x 1 root root 121273208 4月 12 20:28 kubelet
-rwxr-xr-x 1 root root 1540096 4月 12 20:28 kube-log-runner
-rwxr-xr-x 1 root root 45027328 4月 12 20:28 kube-proxy
-rw-r--r-- 1 root root 8 4月 12 20:27 kube-proxy.docker_tag
-rw------- 1 root root 67231744 4月 12 20:27 kube-proxy.tar
-rwxr-xr-x 1 root root 52457472 4月 12 20:28 kube-scheduler
-rw-r--r-- 1 root root 8 4月 12 20:27 kube-scheduler.docker_tag
-rw------- 1 root root 57901056 4月 12 20:27 kube-scheduler.tar
-rwxr-xr-x 1 root root 1458176 4月 12 20:28 mounter
7.1.4 替换二进制文件
7.1.4.1 备份1.26.1 二进制文件
[root@k8s-harbor01 1.26.4]# mkdir /etc/kubeasz/bin/1.26.1-bak/
[root@k8s-harbor01 1.26.4]# cd /etc/kubeasz/bin/
[root@k8s-harbor01 bin]# mv kube-apiserver kube-scheduler kube-controller-manager kube-proxy kubelet kubectl 1.26.1-bak/
7.1.4.2 拷贝1.26.4 二进制文件
[root@k8s-harbor01 bin]# cd /root/app/k8s/1.26.4/kubernetes/server/bin/
[root@k8s-harbor01 bin]# cp kube-apiserver kube-scheduler kube-controller-manager kube-proxy kubelet kubectl /etc/kubeasz/bin/
[root@k8s-harbor01 bin]# ll -rt /etc/kubeasz/bin/
……省略部分输出
-rwxr-xr-x 1 root root 129986560 4月 23 22:58 kube-apiserver
-rwxr-xr-x 1 root root 52457472 4月 23 22:58 kube-scheduler
-rwxr-xr-x 1 root root 119361536 4月 23 22:58 kube-controller-manager
-rwxr-xr-x 1 root root 45027328 4月 23 22:58 kube-proxy
-rwxr-xr-x 1 root root 121273208 4月 23 22:58 kubelet
-rwxr-xr-x 1 root root 48037888 4月 23 22:58 kubectl
# 验证
[root@k8s-harbor01 bin]# /etc/kubeasz/bin/kube-apiserver --version
Kubernetes v1.26.4
[root@k8s-harbor01 bin]# /etc/kubeasz/bin/kube-proxy --version
Kubernetes v1.26.4
[root@k8s-harbor01 bin]# /etc/kubeasz/bin/kube-controller-manager --version
Kubernetes v1.26.4
[root@k8s-harbor01 bin]# /etc/kubeasz/bin/kube-scheduler --version
Kubernetes v1.26.4
[root@k8s-harbor01 bin]# /etc/kubeasz/bin/kubelet --version
Kubernetes v1.26.4
7.1.5 批量升级
[root@k8s-harbor01 kubeasz]# ./ezctl upgrade k8s-cluster1
……省略部分输出PLAY RECAP ************************************************************************************************************************************************************
10.31.200.101 : ok=48 changed=35 unreachable=0 failed=0 skipped=1 rescued=0 ignored=0
10.31.200.102 : ok=48 changed=36 unreachable=0 failed=0 skipped=1 rescued=0 ignored=0
10.31.200.103 : ok=53 changed=38 unreachable=0 failed=0 skipped=2 rescued=0 ignored=0
10.31.200.110 : ok=29 changed=20 unreachable=0 failed=0 skipped=2 rescued=0 ignored=0
10.31.200.111 : ok=29 changed=20 unreachable=0 failed=0 skipped=2 rescued=0 ignored=0
10.31.200.112 : ok=29 changed=20 unreachable=0 failed=0 skipped=2 rescued=0 ignored=0
7.1.6 查看升级结果
[root@k8s-harbor01 kubeasz]# kubectl get no
NAME STATUS ROLES AGE VERSION
k8s-master01 Ready,SchedulingDisabled master 2d v1.26.4
k8s-master02 Ready,SchedulingDisabled master 2d v1.26.4
k8s-master03 Ready,SchedulingDisabled master 5h35m v1.26.4
k8s-node01 Ready node 47h v1.26.4
k8s-node02 Ready node 47h v1.26.4
k8s-node03 Ready node 6h1m v1.26.4
7.2 手动更新
不演示
大概就是先关闭被升级节点的调度,然后驱逐服务,停止相关组件的运行,替换二进制文件,启动相关组件
⽅式1:将⼆进制⽂件同步到其它路径,修改service⽂件加载新版本⼆进制:
即⽤新版本替换旧版本
⽅式2: 关闭源服务、替换⼆进制⽂件然后启动服务:
即直接替换旧版本
2.1. 升级master节点
k8s-deploy# tar xf kubernetes-v1.26.4-client-linux-amd64.tar.gz
k8s-deploy# tar xf kubernetes-v1.26.4-node-linux-amd64.tar.gz
k8s-deploy# tar xf kubernetes-v1.26.4-server-linux-amd64.tar.gz
k8s-deploy# tar xf kubernetes-v1.26.4.tar.gz
k8s-deploy# cd kubernetes/server/bin/
master1:~# systemctl stop kube-apiserver kube-scheduler kube-controller-manager kubeproxy kubelet
k8s-deploy# scp kube-apiserver kube-scheduler kube-controller-manager kube-proxy
kubelet kubectl 172.31.7.101:/usr/local/bin/
root@k8s-master1:~# systemctl start kube-apiserver kube-scheduler kube-controllermanager kube-proxy kubelet
master1:~# systemctl start kube-apiserver kube-scheduler kube-controller-manager kubeproxy kubelet
2.2. 升级node节点
node1:~# systemctl stop kubelet kube-proxy
k8s-deploy# scp kubelet kube-proxy kubectl 172.31.7.111:/usr/local/src/
node1:~# systemctl start kubelet kube-proxy
2.3.替换部署⽬录⼆进制:
kubernetes/server/bin# cp kube-apiserver kube-scheduler kube-controller-manager kubeproxy kubelet kubectl /etc/kubeasz/bin/
8. 部署dashboard(kuboard)
这东西前面已经介绍过了,这就就不再介绍。
8.1 部署nfs
kuboard是有数据需要存储的,这里用nfs来当做它的数据挂载点
[root@k8s-haproxy01 ~]# yum -y install nfs-utils rpcbind # 这里我随便找一台机器部署nfs,工作中需要提前规划好
[root@k8s-haproxy01 ~]# systemctl start rpcbind.service
[root@k8s-haproxy01 ~]# systemctl enable rpcbind.service
[root@k8s-haproxy01 ~]# systemctl start nfs
[root@k8s-haproxy01 ~]# systemctl enable nfs
Created symlink from /etc/systemd/system/multi-user.target.wants/nfs-server.service to /usr/lib/systemd/system/nfs-server.service.
# 创建数据目录
[root@k8s-haproxy01 ~]# mkdir -p /data/k8sdata/kuboard
# 授权
[root@k8s-haproxy01 ~]# vim /etc/exports
[root@k8s-haproxy01 ~]# cat /etc/exports
# kuboard 数据目录
/data/k8sdata/kuboard *(rw,no_root_squash)
[root@k8s-haproxy01 ~]# systemctl restart nfs
[root@k8s-haproxy01 ~]# showmount -e 10.31.200.108
Export list for 10.31.200.108:
/data/k8sdata/kuboard *
8.2 在k8s集群中部署kuboard
8.2.1 自定义yaml并部署
[root@k8s-harbor01 yaml]# cat kuboard-all-in-one.yaml
---
apiVersion: v1
kind: Namespace
metadata:
name: kuboard
---
apiVersion: apps/v1
kind: Deployment
metadata:
annotations: {}
labels:
k8s.kuboard.cn/name: kuboard-v3
name: kuboard-v3
namespace: kuboard
spec:
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
k8s.kuboard.cn/name: kuboard-v3
template:
metadata:
labels:
k8s.kuboard.cn/name: kuboard-v3
spec:
#affinity:
# nodeAffinity:
# preferredDuringSchedulingIgnoredDuringExecution:
# - preference:
# matchExpressions:
# - key: node-role.kubernetes.io/master
# operator: Exists
# weight: 100
# - preference:
# matchExpressions:
# - key: node-role.kubernetes.io/control-plane
# operator: Exists
# weight: 100
volumes:
- name: kuboard-data
nfs:
server: 10.31.200.108 # 修改这个地址为nfs服务器地址
path: /data/k8sdata/kuboard
containers:
- env:
- name: "KUBOARD_ENDPOINT"
value: "http://kuboard-v3:80"
- name: "KUBOARD_AGENT_SERVER_TCP_PORT"
value: "10081"
image: swr.cn-east-2.myhuaweicloud.com/kuboard/kuboard:v3
volumeMounts:
- name: kuboard-data
mountPath: /data
readOnly: false
imagePullPolicy: Always
livenessProbe:
failureThreshold: 3
httpGet:
path: /
port: 80
scheme: HTTP
initialDelaySeconds: 30
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 1
name: kuboard
ports:
- containerPort: 80
name: web
protocol: TCP
- containerPort: 443
name: https
protocol: TCP
- containerPort: 10081
name: peer
protocol: TCP
- containerPort: 10081
name: peer-u
protocol: UDP
readinessProbe:
failureThreshold: 3
httpGet:
path: /
port: 80
scheme: HTTP
initialDelaySeconds: 30
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 1
resources: {}
#dnsPolicy: ClusterFirst
#restartPolicy: Always
#serviceAccount: kuboard-boostrap
#serviceAccountName: kuboard-boostrap
#tolerations:
# - key: node-role.kubernetes.io/master
# operator: Exists
---
apiVersion: v1
kind: Service
metadata:
annotations: {}
labels:
k8s.kuboard.cn/name: kuboard-v3
name: kuboard-v3
namespace: kuboard
spec:
ports:
- name: web
nodePort: 30080
port: 80
protocol: TCP
targetPort: 80
- name: tcp
nodePort: 30081
port: 10081
protocol: TCP
targetPort: 10081
- name: udp
nodePort: 30081
port: 10081
protocol: UDP
targetPort: 10081
selector:
k8s.kuboard.cn/name: kuboard-v3
sessionAffinity: None
type: NodePort
8.2.3 部署
[root@k8s-harbor01 yaml]# kubectl apply -f kuboard-all-in-one.yaml
k8s-harbor01 yaml]# kubectl get po -n kuboard
NAME READY STATUS RESTARTS AGE
kuboard-v3-b66f67cfc-q9fhc 1/1 Running 0 2m58s
[root@k8s-harbor01 yaml]#
8.2.4 访问
用户名:admin
密码:Kuboard123
8.2.5 添加集群

8.3 基本使用
8.3.1 查看名称空间下运行的pod
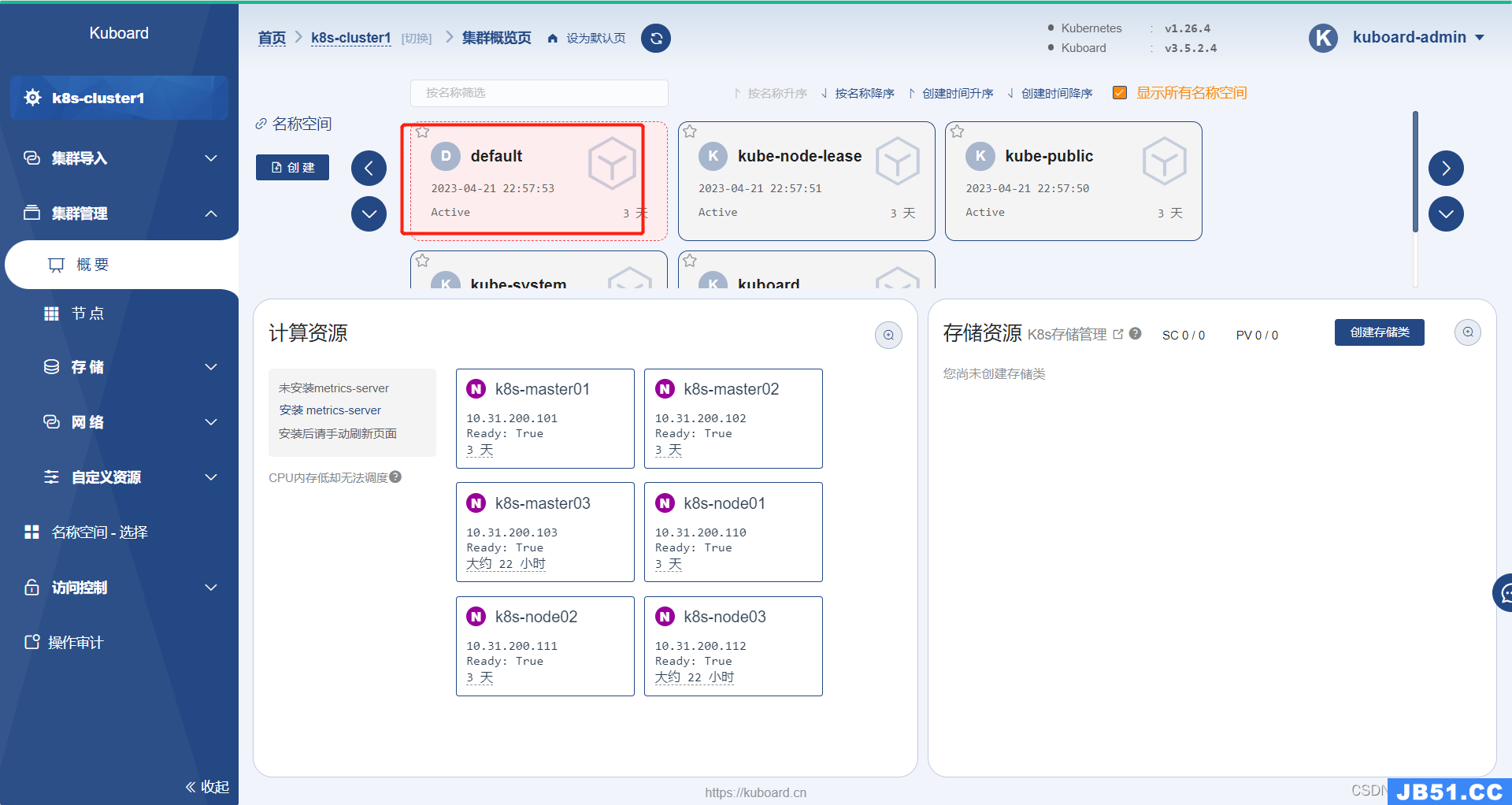

8.3.2 进入容器
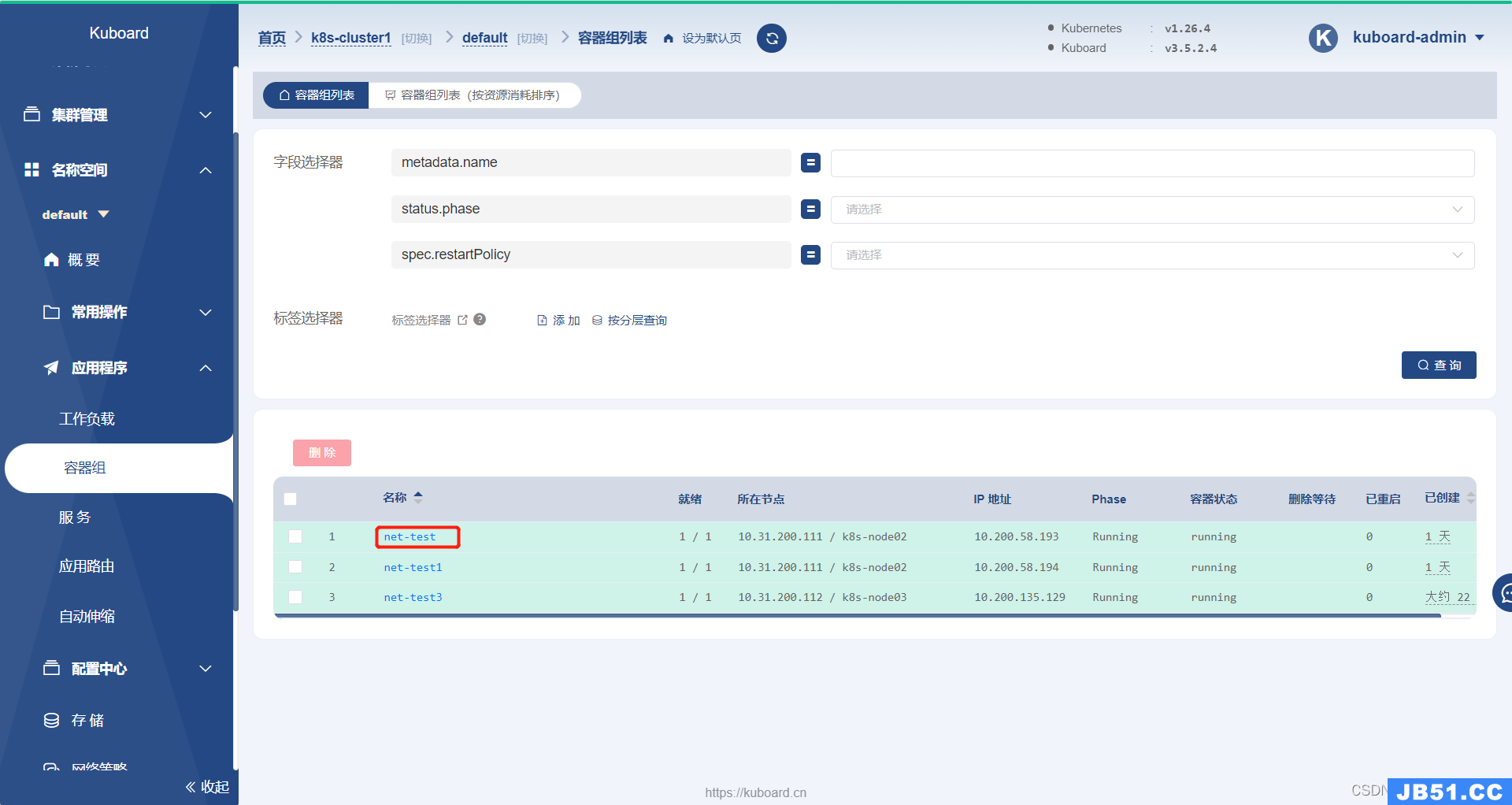
原文地址:https://blog.csdn.net/qq_42515722/article/details/130202408
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。