

嘉宾 | 胡启明
出品 | CSDN云原生
2022年6月30日,中国信通院、腾讯云、Finops产业标准工作组联合发起的《原动力x云原生正发声 降本增效大讲堂》系列直播活动第2讲如期举行,腾讯云容器技术专家胡启明分享了Kubernetes云上资源的分析与优化。
胡启明是开源项目Crane的Founder和负责人,专注Kubernetes云原生领域8年,负责专有云容器产品、云原生应用平台的研发和管理,是Kubernetes、Dapr、KubeEdge等多个开源项目的Contributor。本文整理自胡启明的分享。

Kubernetes云上资源管理
Kubernetes资源模型:Request和Limit
Request代表Kubernetes应用声明它希望获得的最小的资源使用量。
Limit代表Kubernetes应用声明它希望获得的最大的资源使用量。
Kubernetes的调度器,会根据Request的申请量去调度应用到Kubernetes的节点上。

资源预留带来的资源浪费
关于Request的模型,用户设置时存在一个问题:用户的开发者不一定对业务线上运行情况完全感知。例如:不知道业务在线上运行时需要多少cpu和内存,以及业务洪峰的场景下资源使用量会上涨的维度。因此,基于这些问题,在业务开发、运维在配置Request时,开发者会选择保守策略,常把配置设高。
同时,也带来另一个问题:资源浪费比较显著。如下图所示,应用的Request声明了4个核,但实际使用不超过2个核。这都是由于保守、业务运行不了解带来的资源浪费。

资源紧缺带来的资源浪费
cpu是可压缩资源。当cpu紧缺时,实际用量可以超过cpu总量,此时会出现资源的争抢,导致应用处理程序速度变慢。

内存是不可压缩资源,如果业务运行中超过了上限,就会呈现下图的情况。

如上图所示,Kubernetes中的节点上部署了两个容器,它们在处理业务都有规律:
在晚上,业务的使用量会降低,白天高峰期业务容量就会偏高;
昼夜规律比较相似,相似的业务部署在了同一个节点上;
业务高峰期,容器的内存用量会达到它的Limit值,但由于调度应用是根据Request完成的,会导致在业务高峰期节点上内存被耗尽。
资源被耗尽时候,会发生什么事?
如果节点的内存耗尽,Kubernetes会按顺序驱逐容器,排序规则是容器实际内存使用超出Request的用量。如果去驱逐用量大于Request的东西,业务就会发生损伤,因为它的容器被Kill,并且这时候往往是处在于业务的高峰期,使业务受到损伤。
如果容器内所有的进程分配的内存超过了内存Limit,节点上的OOM Killer会立刻Kill这些进程。这种场景下,业务的使用也会受到损伤,用户也会感知。这导致了应用开发者或者SRE去配置资源时会采取保守策略,以保证业务稳定性和正确性,这加剧了云上资源浪费。
大量资源无法使用导致资源浪费
当业务上了Kubernetes等云原生平台后,它的资源的用量和与使用率会偏低。下图显示资源总量很大,但实际使用量却很低,导致大量资源的使用浪费。


Kubernetes弹性伸缩
HPA工作原理
HPA工作原理如下图所示。

在云上,用户通过Service+Load Balance,请求到一个Deployment,Deployment里有几个Pod。为了让Deployment+Pod在用户流量增大时自动扩容,在流量减少时自动缩容,达到按需计费,于是创建了HPA。
HPA会让用户设置最小的副本数和最大的副本数,并且用户设置目标的cpu使用率。根据目标使用率,在最小副本数和最大副本数之间做自动弹性伸缩。
HPA在社区发展了已有3~4年,版本目前达到v2,功能比较完善。社区的HPA不但支持基于K8s内置的cpu和Memory指标,还提供了丰富的扩展能力customer metric、External metric的外部指标,让用户可以通过外部的监控指标来对业务做弹性。
最常见的基于Prometheus的adapter,让用户基于Prometheus的metric自动做弹性。社区有一个开源产品叫KEDA,它专注于通过Event Driven的方式让业务做弹性。本质是使用了HPA,把一些基于Kafka、MQ数据的event去做弹性的输入,通过external metric的方式让HPA去做水平弹性。
HPA原生能力不足
社区的HPA也有局限性,主要在两个方面。
在业务流量的洪峰来临时来不及扩容。例如:用户MQ的connection会提升,随着message数量会增加,cpu的用量会提升,但如果资源洪峰已经来临时,再去扩就常常会发现来不及。一方面原因是Event Driven,洪峰来临再去弹,另外一方面的原因是容器化的业务启动速度赶不上流量来的速度。由于业务系统慢,导致很多业务没办法使用社区的HPA。
流量抖动。在下图的“深V”时间点内,如果使用HPA将导致HPA的副本剧烈抖动。虽然HPA里有个behavior的功能可以减少抖动,但调大behavior减少抖动时,HPA的弹性会变得迟钝,导致弹性效果不理想。

VPA工作原理和局限性
VPA工作原理如下。
首先,用户会创建一个VPA的对象,它会有VPA的Recommend,便于定期获取VPA里面的弹性配置。同时,Recommend也会去从ApiServer拿到整个集群中的状态信息。通过VPA的算法,根据这两个信息计算出用户应用推荐配置cpu和memory的数量。最后,根据资源配置推荐信息更新到VPA上去。
还有一个组件叫做VPA Updater,它会去获取弹性配置,并且感知到配置后,需要把Pod重建,配置它才能生效。因此,VPA Updater会对Pod做eviction。众所周知,当Pod做eviction时,它会自动创建新的Pod来替代它,新的Pod的创建请求会被VPA Admission plugin给拦截,拦截之后它会把VPA上面的弹性配置更新到Pod Spec,新建的Pod就会使用VPA推荐的资源配置。

在现实中,VPA的落地场景其实不多,因为VPA有其局限性:业务很难接受随时重建的Pod。
例如一个业务正在接受一个用户的数据处理,这时Pod重建了,用户的业务使用就会受损, Pod 重建无法通知到业务,并且一定会对业务造成影响,导致很多时候在生产环境很难使用VPA。

基于Crane的Kubernetes的资源分析与优化
Crane是腾讯的一个基于Kubernetes的开源项目,全称是Cloud Resource Analytics and Economics,译为“云上资源的分析和降本”。

Crane是基于Finops的理论来去编排设计的能力模型,从下往上看分为五层:
Understand Fully Loaded Costs:多维度业务成本分摊表、标签管理、分期账单、预算和配额管理等。
Enable Real Time Decision Making:资源利用率报表、异常识别、识别资源浪费等。
Benchmark Performance:趋势和变化分析、评分和PKI、内部评比、跨供应商评分对比等。
Optimize Usage:支持的资源优化的能力,比如资源回收再分配、Request推荐、基于预测的智能弹性、机型推荐等。
Optimize Rate:提供计费方面的能力,比如计费方式推荐、抵用券支持等。
云上资源的分析和优化
下图展示的是Kubernetes云上资源的分析和优化的能力。

Kubernetes里有个重要的概念,叫做Infrastructure as Code。Kubernetes上所有资源都是可以通过YAML配置的方式来去声明,例如Deployment、Job、PV、SVC、node、cpu,都可以用通过一段YAML配置来去声明。Crane提供了一套分析推荐的插件能力,去分析Kubernetes中的云资源。
同时,输入的一方面是云资源,另一方面是Kubernetes的观测数据,例如Deployment对应cpu的使用率,内存的使用率,都是观测数据。
“云资源+观测数据+分析算法”作为一个输入,再加上资源推荐的插件,能给用户推荐优化的建议。比如,资源推荐的插件会根据用户的应用配置、实际使用量、推荐算法,得到建议资源cpu和memory的配置值。
在分析结果之后,还可以利用一些工具包,比如Kubernetes的插件,把资源优化的分析结果汇总给用户,让用户能够观测到优化结果。优化结果通过API去计算云端费用的节省,帮助用户在云上做成本决策。
云上资源的分析与优化,还提供了一个插件系统。用户可以自定义推荐的插件,使用推荐的framework插到分析的推荐系统中去,实现自定义分析和推荐的逻辑。
资源推荐
下图展示的是资源推荐中的诉求、方案以及成效。

从“让应用的资源配置更简单”的诉求出发。
Crane方案是根据应用的历史用量推荐,支持按照机型规格做调整,基于VPA的算法进行资源推荐。很多业务都跑在Serverless构上,Serverless架构上的资源规格、机型规格都会做规整,例如1.5Core/3G的资源就会向上规整到2Core/4G上,Crane的推荐结果会根据规则做规整,同样是基于VPA算法。
成效如上图右侧所示,没有使用资源推荐之前,很多业务的机型是偏大的,经过资源推荐优化之后,用户采纳推荐配置并且重建了容器。资源推荐是使用推荐建议的方式,让用户去选择时间和是否采纳建议。在用户采纳之后,才会去批量的rolling更新,避免VPA随时更新应用的配置,导致应用被重启的问题。
副本/弹性推荐
下图展示的是副本/弹性推荐中的诉求、方案以及成效。

从“让应用副本配置更简单”的诉求出发。
Crane方案会去扫描集群中的应用,根据它的应用历史用量,基于HPA的算法计算未来副本数。其中,部分应用用量有昼夜规律波动,这类业务则可以推荐它的副本配置,实现降本。对于能够支持动态扩缩、有规律性的业务,可以配智能弹性Effective HPA,用户进行降本增效。
成效如上图右侧所示,大部分业务配了很多副本数,但经过计算发现降到三个副本也可以满足业务诉求。
内部大规模落地实践

腾讯的智能推荐的能力在腾讯内部和自研业务上大规模落地,部署到数百个Kubernetes的集群,管控了数百万个cpu的核,在全面上线一个月之内,大盘的总和数缩减了25%。
腾讯把集群中资源推荐的建议展现到控制台里,让用户看到工作负载、当前的核数、推荐的资源量、推荐副本数。
该页面还能帮用户整理出工作环境中的应用数字、可以被优化的数字以及用户采纳优化建议后能降低多少cpu和内存的使用,通过图形的方式展现出来,方便用户去决策。我们还支持基于kubectl插件去分析整个集群中的状态。
智能弹性—Effective HPA
HPA落地有两个问题:弹性时间滞后、弹性毛刺。

上图展示的是智能弹性的功能,Effective HPA。Effective HPA是基于时间预测的算法,通过预测未来的metric使用量去解决问题,它有以下能力。
第一个能力:提前扩容,保证服务质量。采取时间序列算法(Fast Fourier Trans former),可以根据过去7天或者14天的metric,预测未来7天metric变化轨迹。通过预测窗口里面metric的最大值做提前扩容,还会采取metric兜底保护策略。
第二个能力:减少无效缩容。能够预测未来的一个资源用量,当曲线发生抖动时,因为取的预测窗口中的最大值,所以整个曲线的抖动毛刺程度明显降低。
第三个能力:支持Cron配置。应对大促、节假日等有规律的流量洪峰。
第四个能力:易于使用。Effective HPA完全兼容社区HPA的功能,还支持Dryrun观测,指标支持Prometheus Metric。
下图展示的是Effective HPA的架构。

用户创建Effective HPA的对象后会生成两个资源对象:
一个是TimeSeries Prediction;
另一个是社区原生的HPA。
TimeSeries Prediction是时间序列预测的Controller的对象。创建后有一个组件叫Predictor开始从Prometheus中拿取应用历史数据,并且通过预测算法得到未来持续预测,把预测结果更新到TimeSeriesPredicton中。
社区HPA在创建后,HPA的Controller就会工作。定义中的metric的配置向Kubernetes的ApiServer请求。一方面,它会去向Metric server去请求它的cpu的用量。另一方面,它向Crane metric adapter去请求预测数据。
最后,Metric-adapter会从TSP中获取它的预测数据,并且把结果返回给HPA Controller。HPA Controller将两个源头数据通过HPA算法,计算得到较高的副本数,并且用副本数更新到真实的应用中,这就是Effective HPA智能弹性的工作过程。
CronHPA 、KEDA、Effective HPA有什么差异点呢?如下图所示。
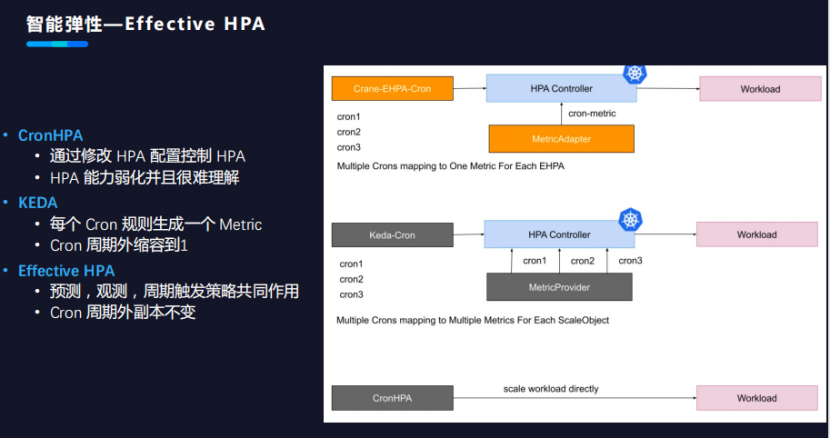
CronHPA是通过修改HPA的配置去控制底层的HPA,并且控制应用的弹性伸缩。由于它是自动修改HPA的配置,这就会导致用户的HPA配置能力遭到弱化。
KEDA实现原理是为每一个框配置生成metric。但它的问题是在Cron的周期之外,KEDA的Cron配置会自动把用户的应用缩容到一个副本,原因是它把每一个Cron都定义成了metric。由于metric定义互相不感知,就导致metric返回的默认值只能设置为1,因为它不能够去影响别的metric配置。
Effective HPA的Cron配置解决了前两个问题。通过预测、观测和周期性触发策略共同作用、计算和考虑,最后取中间的较大值。Cron的问题也解决了,在用户配置的Cron周期之内,副本数能够保持跟当前的配置不变,不会自动缩溶。
智能弹性落地成效
下图展示的是智能弹性的落地成效。

腾讯内部的安全部门WAP和腾讯的容器服务,在生产环境已经使用了Effective HPA做弹性伸缩器。作为一个开源产品,很多公司对Effective HPA感兴趣,并且正在使用。
酷乐家生产环境全量使用。酷乐家原本在生产环境中已经全量使用了HPA,由于没有办法提前扩容,导致它的配置相当保守。酷乐家看到Cron的Effective HPA后,将HPA存量切换到了Effective HPA,在生产环境全量使用后,解决了弹性问题,提升了平均使用率。
目前Effective HPA在生产环境已经管控了数千个应用。
平均利用率的提升达到10%。如上图右下方所示,蓝线是预测的metric,绿线是cpu实时的metric容量,黄线是使用Effective HPA后的提前扩容能力。

END
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 [email protected] 举报,一经查实,本站将立刻删除。
