
背景:
最近就想体验各种多集群互联(基于wireguard),然后就深感网络划分的重要性,开始网络设计的杂七乱八的。想互联了都各种问题了,网络重叠了怎么办?集群扩容IP资源不够了杂整?还有就是默认的每个node节点的subset都默认是24?我一台机器上面也跑不了那么多Pod阿......
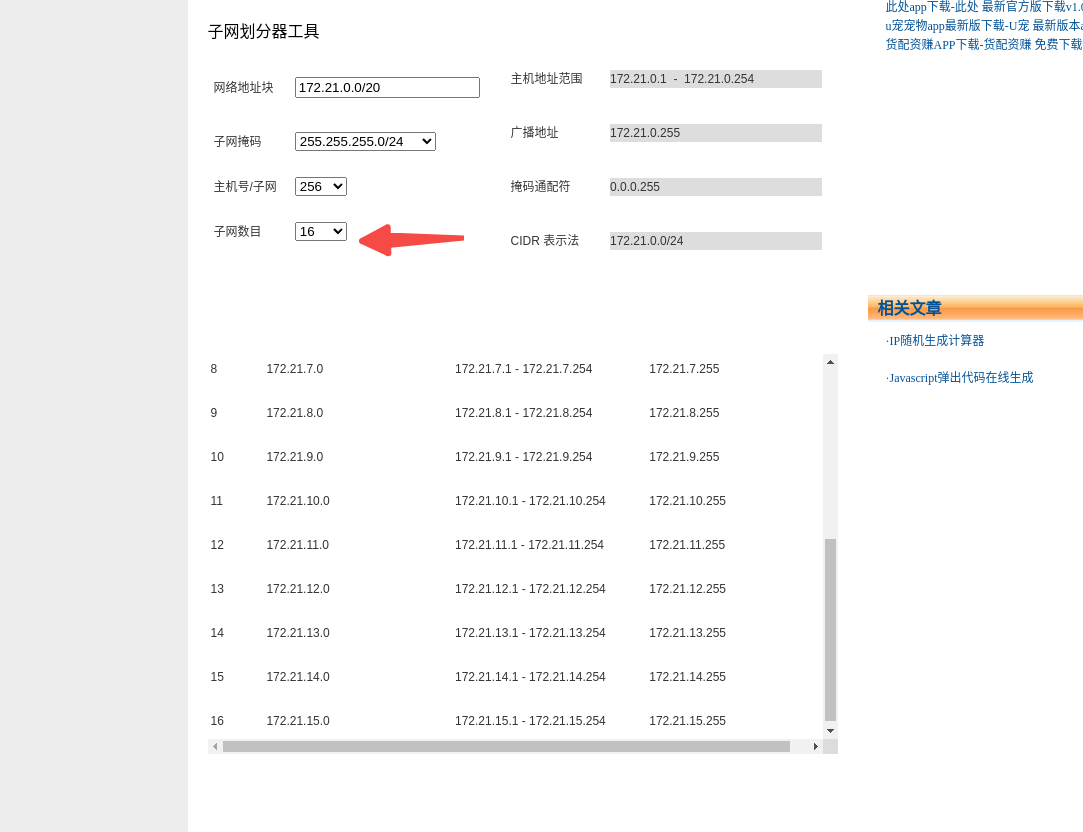
恩 默认的 SUBNET都是24,举个例子:
我的kubernetes集群初始化配置文件networking部分如下:


浪费ip 资源阿 我一台服务器跑不了那么多 200 多个pod........,而且这样算下来除去service的地址,集群只能容纳12个工作节点(包括master节点)

关于节点pod ip规划与集群容纳更多节点
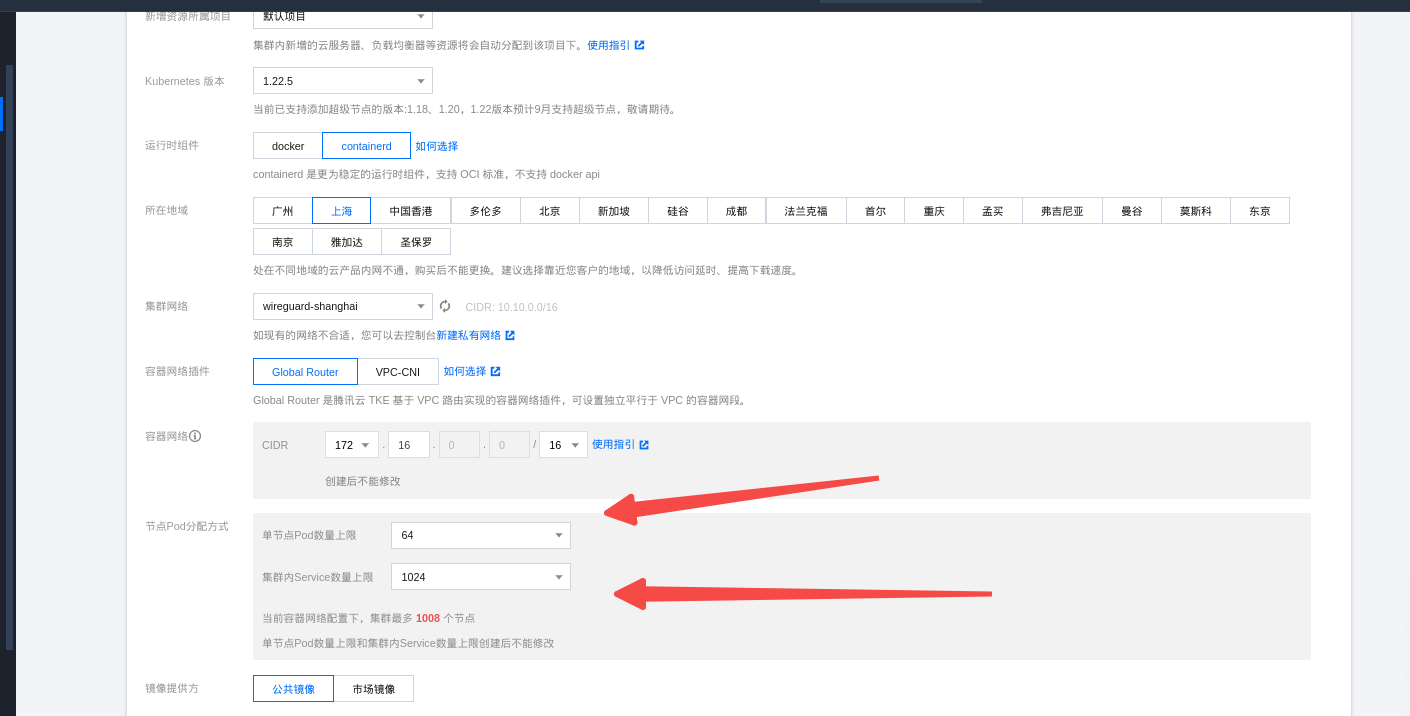
腾讯云tke的例子
正好看到腾讯云tke创建集群的时候可以看到可以限制但节点的pod数量上线和service的数量:
他们怎么搞的呢?参照:k8s-flannel网络Node上限突破255
apiVersion: kubeadm.k8s.io/v1beta2
kind: ClusterConfiguration
etcd:
local:
dataDir: "/var/lib/etcd"
networking:
serviceSubnet: "10.96.0.0/16"
podSubnet: "10.244.0.0/16"
dnsDomain: "cluster.local"
kubernetesVersion: "v1.18.0"
controlPlaneEndpoint: "11.167.124.4:6443"
controllerManager:
extraArgs:
allocate-node-cidrs: 'true'
node-cidr-mask-size: '28'
apiServer:
extraArgs:
authorization-mode: "Node,RBAC"
certSANs:
- "11.167.124.4"
timeoutForControlPlane: 4m0s
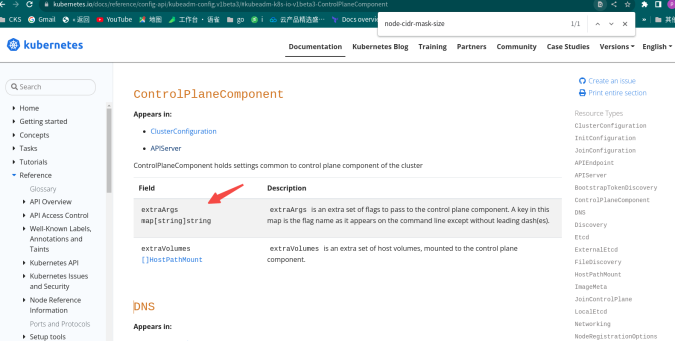
imageRepository: "registry.aliyuncs.com/google_containers"关于controllerManager extraArgs配置:
allocate-node-cidrs: 'true'
node-cidr-mask-size: '28'
我的kubernets初始化配置文件是这样的:
apiVersion: kubeadm.k8s.io/v1beta3
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 10.0.2.28
bindPort: 6443
nodeRegistration:
criSocket: unix:///var/run/containerd/containerd.sock
imagePullPolicy: IfNotPresent
name: sh-master-01
taints:
- effect: NoSchedule
key: node-role.kubernetes.io/master
---
apiServer:
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta3
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager:
extraArgs:
allocate-node-cidrs: 'true'
node-cidr-mask-size: '26'
dns: {}
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.aliyuncs.com/google_containers
kind: ClusterConfiguration
kubernetesVersion: 1.25.0
networking:
dnsDomain: cluster.local
serviceSubnet: 172.21.12.0/22
podSubnet: 172.21.0.0/20
scheduler: {}注:环境基于kubeadm搭建!
node-cidr-mask-size: '26' 可以承载多少个地址呢?2^(32-26)-1=2^6-1=63个地址满够用了(其实还应该去除一个flannel.1网卡占用的地址,还有子网地址cni0地址?应该是61个?)
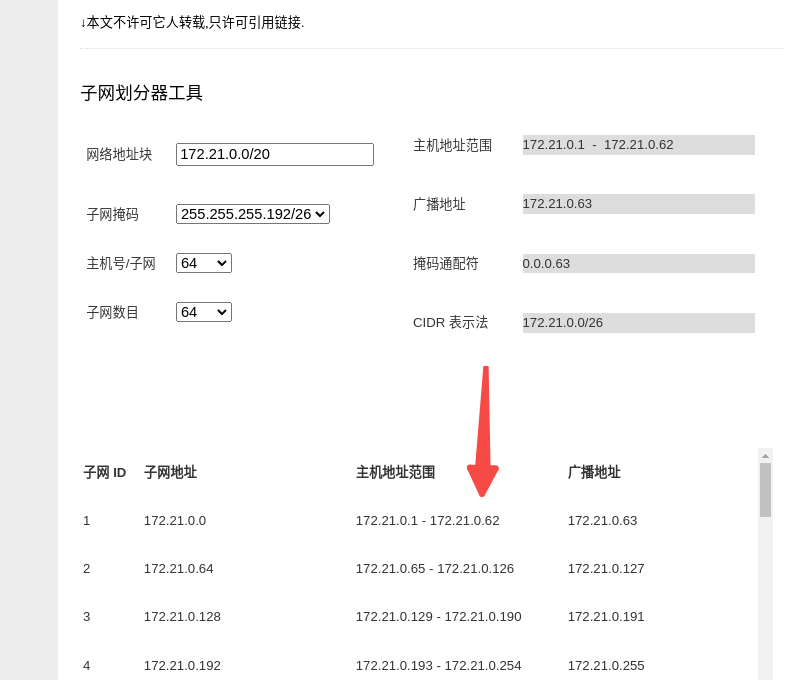
再扩展一下:我的集群可以有多少台node呢?
首先:serviceSubnet: 172.21.12.0/22 也就是我的集群可以有2^(32-22)-1=2^10-1=1023个地址
172.21.0.0/20子网数量是64 减去server网段目测应该是48台节点的集群(当然了也包括master节点)
仍然以flannel为例:
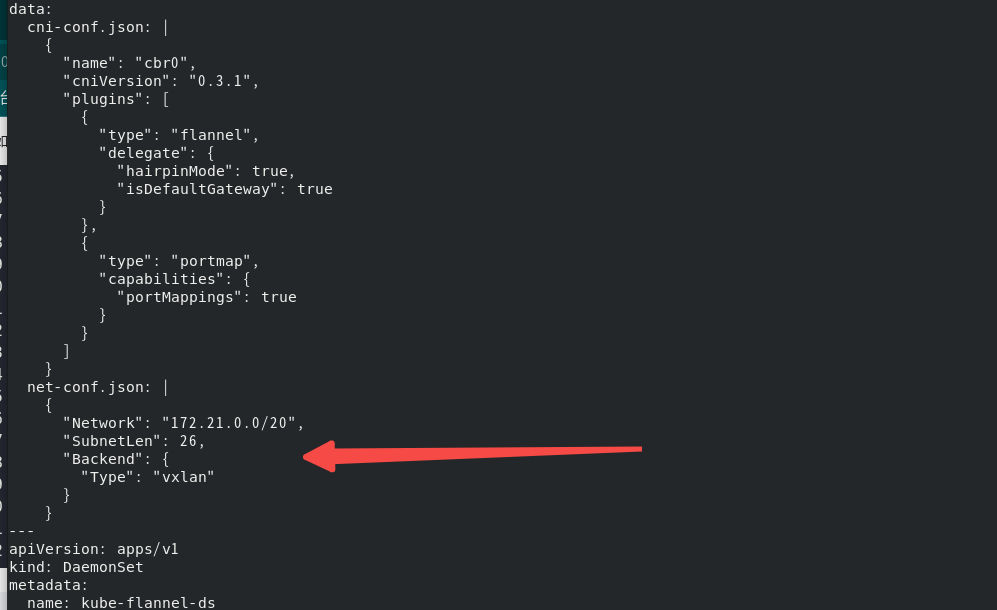
kube-flannel.yaml同样的也要修改 net-conf.json部分
net-conf.json: |
{
"Network": "172.21.0.0/20",
"SubnetLen": 26,
"Backend": {
"Type": "vxlan"
}
}
初始化集群并验证网络配置
kubeadm init --config=config.yaml
kubectl apply -f kube-flannel.ymlwork 节点加入集群 忽略 ,查看/run/flannel/subnet.env,发现FLANNEL_SUBNET的掩码变成了26

ifconfig cni0 flannel.1所属Ip地址:
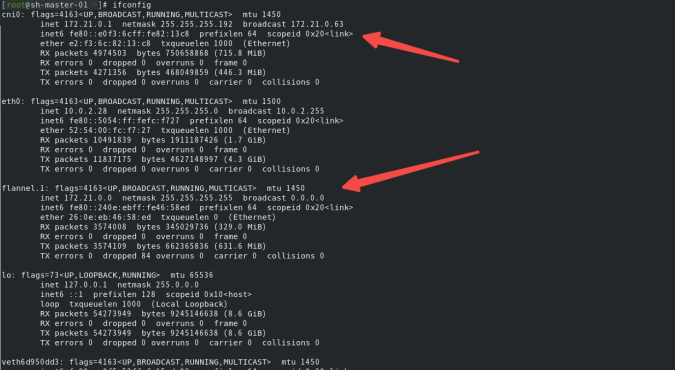
其他碰到的:
我在初始化集群的时候搞成了下面这样....没错 pod网络跟service网络写反了.....
kubeadm init --kubernetes-version=1.25.0 --image-repository=registry.aliyuncs.com/google_containers --service-cidr=171.21.0.0/20 --pod-network-cidr=172.21.12.0/22 --apiserver-advertise-address=10.0.2.28然后的结果就是四台节点可以,添加第五台就是出问题,然后还流氓了一下patch设置了 最后一台的podcidr......
kubectl patch node sh-work-05 -p '{"spec":{"podCIDR":"172.21.7.0/24"}}'但是控制平面组件就开始异常了!这里只是提醒一下有patch的方法可以用,希望大家不要跟我一样,写反了配置!由于是新的集群,我是reset集群重新初始化了!
原文地址:https://cloud.tencent.com/developer/article/2125795
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。