
k8s发布go应用
前言
搭建了一套K8s,尝试发布一个go应用
部署
镜像打包
之前已经打包过一个go的镜像了,这次就直接跳过了,打包记录https://www.cnblogs.com/ricklz/p/12860434.html
编写yaml文件
apiVersion: apps/v1
kind: Deployment
metadata:
name: go-app
spec:
replicas: 2
selector:
matchLabels:
app: go-app
template:
metadata:
labels:
app: go-app
spec:
containers:
- name: go-app-container
image: liz2019/test-docker-go-hub
resources:
limits:
memory: "128Mi"
cpu: "500m"
ports:
- containerPort: 8000
启动
$ kubectl apply -f kube-go.yaml
NAME READY STATUS RESTARTS AGE
go-app-6498bff568-8n72g 0/1 ContainerCreating 0 62s
go-app-6498bff568-ncrmf 0/1 ContainerCreating 0 62s
暴露应用
$ kubectl expose deployment go-app --type=NodePort --name=go-app-svc --target-port=8000
查看
$ kubectl get pods -o wide|grep go-app
go-app-58c4ff7448-j9j6m 1/1 Running 0 106s 172.17.32.5 192.168.56.202 <none> <none>
go-app-58c4ff7448-p7xnj 1/1 Running 0 106s 172.17.65.4 192.168.56.203 <none> <none>
$ kubectl get svc|grep go-app
go-app-svc NodePort 10.0.0.16 <none> 8000:45366/TCP 43m
通过nodeIP加端口可以直接访问

使用ingress
什么是ingress呢
k8s 的服务(service)时说暴露了service的三种方式ClusterIP、NodePort与LoadBalance,这几种方式都是在service的维度提供的,service的作用体现在两个方面,对集群内部,它不断跟踪pod的变化,更新endpoint中对应pod的对象,提供了ip不断变化的pod的服务发现机制,对集群外部,他类似负载均衡器,可以在集群内外部对pod进行访问。但是,单独用service暴露服务的方式,在实际生产环境中不太合适:
- ClusterIP的方式只能在集群内部访问。
- NodePort方式的话,测试环境使用还行,当有几十上百的服务在集群中运行时,NodePort的端口管理是灾难。
- LoadBalance方式受限于云平台,且通常在云平台部署ELB还需要额外的费用。
ingress可以简单理解为service的service,他通过独立的ingress对象来制定请求转发的规则,把请求路由到一个或多个service中。这样就把服务与请求规则解耦了,可以从业务维度统一考虑业务的暴露,而不用为每个service单独考虑。

ingress根据不同的请求规则,会把请求发送到不同的service。
ingress与ingress-controller
- ingress对象:
指的是k8s中的一个api对象,一般用yaml配置。作用是定义请求如何转发到service的规则,可以理解为配置模板。
- ingress-controller:
具体实现反向代理及负载均衡的程序,对ingress定义的规则进行解析,根据配置的规则来实现请求转发。
简单来说,ingress-controller才是负责具体转发的组件,通过各种方式将它暴露在集群入口,外部对集群的请求流量会先到ingress-controller,而ingress对象是用来告诉ingress-controller该如何转发请求,比如哪些域名哪些path要转发到哪些服务等等。
在Kubernetes中,Ingress Controller将以Pod的形式运行,监控API Server的/ingr ess接口后端的backend services,如果Service发生变化,则Ingress Controller应自动 更新其转发规则。
ingress
ingress的部署,需要考虑两个方面:
1、ingress-controller是作为pod来运行的,以什么方式部署比较好
2、ingress解决了把如何请求路由到集群内部,那它自己怎么暴露给外部比较好
到目前为止,kubernetes主要有有三种暴露服务的方式
LoadBlancer Service
如果要把ingress部署在公有云,那用这种方式比较合适。用Deployment部署ingress-controller,创建一个type为LoadBalancer的service关联这组pod。大部分公有云,都会为LoadBalancer的service自动创建一个负载均衡器,通常还绑定了公网地址。只要把域名解析指向该地址,就实现了集群服务的对外暴露。
NodePort Service
用deployment模式部署ingress-controller,并创建对应的服务,但是type为NodePort。这样,ingress就会暴露在集群节点ip的特定端口上。由于nodeport暴露的端口是随机端口,一般会在前面再搭建一套负载均衡器来转发请求。该方式一般用于宿主机是相对固定的环境ip地址不变的场景。NodePort方式暴露ingress虽然简单方便,但是NodePort多了一层NAT,在请求量级很大时可能对性能会有一定影响。
HostNetwork Service
用DaemonSet结合nodeselector来部署ingress-controller到特定的node上,然后使用HostNetwork直接把该pod与宿主机node的网络打通,直接使用宿主机的80/433端口就能访问服务。这时,ingress-controller所在的node机器就很类似传统架构的边缘节点,比如机房入口的nginx服务器。该方式整个请求链路最简单,性能相对NodePort模式更好。缺点是由于直接利用宿主机节点的网络和端口,一个node只能部署一个ingress-controller pod。比较适合大并发的生产环境使用。
部署ingress
mandatory.yaml地址https://github.com/boilingfrog/daily-test/blob/master/k8s/ingress/mandatory.yaml
创建
$ kubectl apply -f ./mandatory.yaml
$ kubectl get pods -n ingress-nginx
$ kubectl get service -n ingress-nginx
配置ingress转发策略
首先查看service
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
go-app-svc NodePort 10.0.0.247 <none> 8000:35100/TCP 2d13h
配置ingress
$ cat ingress-go.yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: web-ingress
spec:
rules:
- host: www.liz-test.com
http:
paths:
- backend:
serviceName: go-app-svc
servicePort: 8000
添加本机的host
查看
$ kubectl get pod -n ingress-nginx -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-ingress-controller-495zq 1/1 Running 0 13m 192.168.56.202 192.168.56.202 <none> <none>
nginx-ingress-controller-6nlrb 1/1 Running 0 13m 192.168.56.203 192.168.56.203 <none> <none>
nginx-ingress-controller是在192.168.56.202上面的,所以我们下面的host就配置到这个机器中。
$ sudo vi /etc/hosts
// 根据ingress部署的iP
192.168.56.202 www.liz-test.com
访问结果
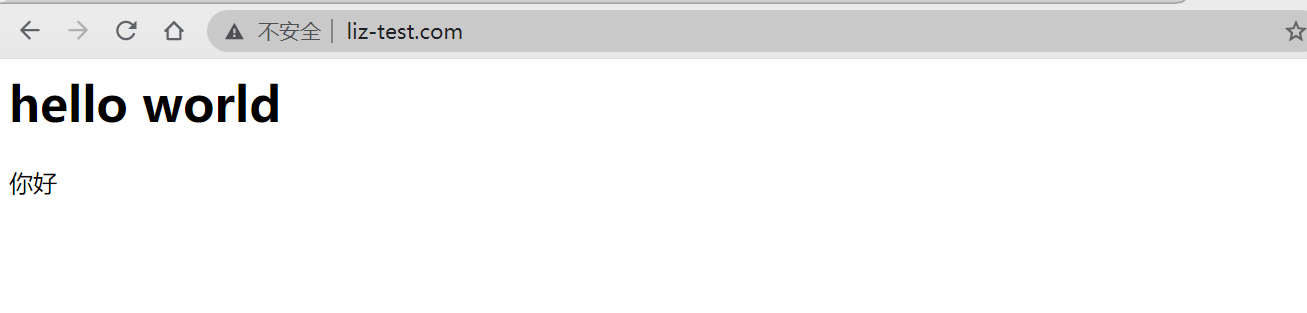
参考
【K8S 安装 Ingress】https://www.jianshu.com/p/4370c00c040a
【k8s ingress原理及ingress-nginx部署测试】https://segmentfault.com/a/1190000019908991
【Kubernetes Deployment 故障排查常见方法[译]】https://www.qikqiak.com/post/troubleshooting-deployments/
【kubernetes部署-ingress】https://blog.csdn.net/u013726175/article/details/88177110
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。