
概念
爬虫(spider,⼜叫网络爬虫),是指向⽹站/网络发起请求,获取资源后分析并提取有用数据的程序。
通过程序模拟浏览器请求站点的行为,把站点返回的HTML代码/JSON数据/⼆进制数据(图片、
视频) 爬到本地,进而提取自己需要的数据,存放起来使用。
步骤
- 发送请求
- 请求方式:GET、POST
- 请求URL
- 请求头:User-Agent、Host、Cookies等
- 获取数据
- 响应状态
- 响应头
- 响应体:要获取的数据
- 解析数据
- 正则表达式
- lxml
- BeautifulSoup
- 存储数据
- 文本
- 数据库
- 二进制文件
安装常用包
requests包、bs4包和lxml包
cmd执行
conda info -e #查看所有环境
pip list #查看当前环境下面有哪些包
conda install requests #安装requests包
conda install lxml #安装lxml包
conda install bs4 #安装bs4包
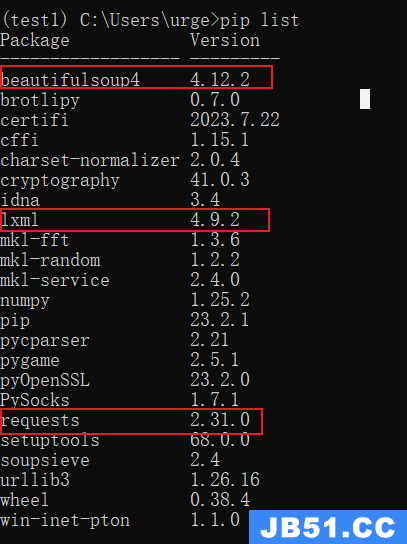
数据提取
1. 响应内容的分类
在发送请求获取响应之后,可能存在多种不同类型的响应内容;而且很多时候,我们只需要响应内容中的一部分数据
-
结构化的响应内容
-
json字符串
- 可以使用re、json等模块来提取特定数据
-
xml字符串
-
可以使用re、lxml等模块来提取特定数据
-
xml字符串的例子如下
<bookstore> <book category="COOKING"> <title lang="en">Everyday Italian</title> <author>Giada De Laurentiis</author> <year>2005</year> <price>30.00</price> </book> <book category="CHILDREN"> <title lang="en">Harry Potter</title> <author>J K. Rowling</author> <year>2005</year> <price>29.99</price> </book> <book category="WEB"> <title lang="en">Learning XML</title> <author>Erik T. Ray</author> <year>2003</year> <price>39.95</price> </book> </bookstore>
-
-
-
非结构化的响应内容
-
html字符串
- 可以使用re、lxml等模块来提取特定数据
- html字符串的例子如下图
-
2. 认识xml以及和html的区别
要搞清楚html和xml的区别,首先需要我们来认识xml
2.1 认识xml
xml是一种可扩展标记语言,样子和html很像,功能更专注于对传输和存储数据
<bookstore>
<book category="COOKING">
<title lang="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price>30.00</price>
</book>
<book category="CHILDREN">
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
<book category="WEB">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price>39.95</price>
</book>
</bookstore>
上面的xml内容可以表示为下面的树结构:
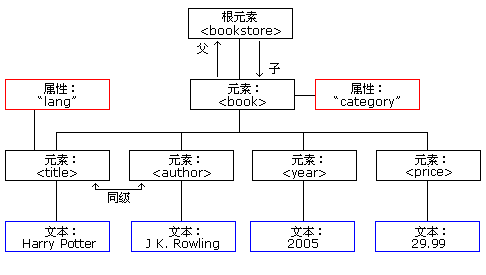
2.2 xml和html的区别
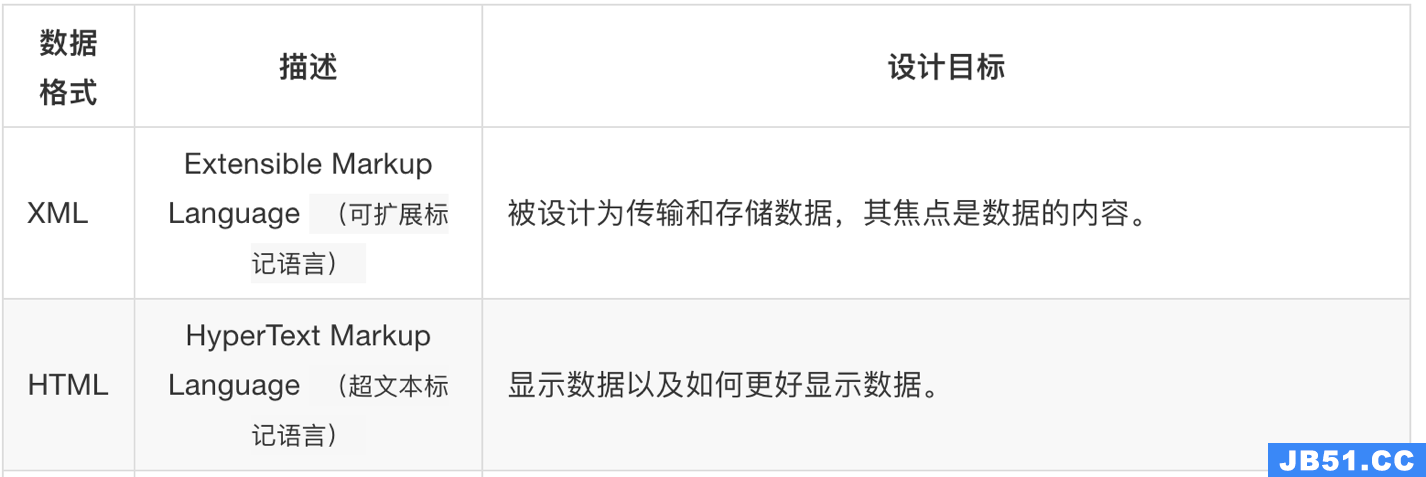
- html:
- 超文本标记语言
- 为了更好的显示数据,侧重点是为了显示
- xml:
- 可扩展标记语言
- 为了传输和存储数据,侧重点是在于数据内容本身
2.3 常用数据解析方法
JSON模块
JSON简介
JSON是⼀种存储和交换数据的语法
JSON仅仅是⽂本,它能够轻松地在服务器浏览器之间传输
JSON的数据格式其实就是python里面的字典格式
JSON语法
格式1:JSON 对象
{"name": "小周", "sex": 女}
格式2:JSON 数组
{
"student":
[
{"name": "小潇", "sex": "男"},
{"name": "小周", "sex": "女"},
{"name": "小小", "sex": "男"}
]
}
方法
import json
json.dumps()
将python数据类型转换为json格式的字符串
d = {'a':1, 'b':2}
print(d)
print(type(d))
json_d = json.dumps(d)
print(json_d)
print(type(json_d))
# 打开文件 在文件里写入转成的json串
with open('data.json', 'w', encoding='utf-8') as f:
f.write(json_d)
{'a': 1,'b': 2}
<class 'dict'>
{"a": 1,"b": 2}
<class 'str'>
json.dump()
将python数据类型转换并保存到json格式文件内
- sort_keys: 是否排序 indent: 定义缩进距离
- separators: 是一个元组,定义分隔符的类型
- skipkeys:是否允许json字串编码字典对象时 字典的key不是字符串类型
d = {'a':1,'b':2}
json.dump(d,open('data.json','w'),sort_keys=True,indent=4,separators=(',',': '))
json.loads()
将json格式的字符串转换为python的类型
d = {'a':1, 'b':2}
print(d)
print(type(d))
json_d = json.dumps(d)
print(json_d)
print(type(json_d))
dic_d = json.loads(json_d) #json.loads()
print(dic_d)
print(type(dic_d))
#文件操作
f = open('data.json', encoding='utf-8')
content = f.read() # 使用loads()方法需要先读文件
python_obj = json.loads(content)
print(python_obj)
print(type(python_obj)) #<class 'dict'>
{'a': 1,"b": 2}
<class 'str'>
{'a': 1,'b': 2}
<class 'dict'>
json.load()
从json格式的文件中读取数据并转换为python的类型
python_obj = json.load(open('data.json','r'))
print(python_obj)
print(type(python_obj)) #<class 'dict'>
jsonpath模块
jsonpath模块的使用场景
如果有一个多层嵌套的复杂字典,想要根据key和下标来批量提取value,这是比较困难的,jsonpath模块就能解决这个痛点。
jsonpath可以按照key对python字典进行批量数据提取
jsonpath模块的安装
pip install jsonpath -i https://pypi.tuna.tsinghua.edu.cn/simple
jsonpath模块使用
from jsonpath import jsonpath
jsonpath语法规则

jsonpath使用示例
book_dict = {
"store": {
"book": [
{ "category": "reference","author": "Nigel Rees","title": "Sayings of the Century","price": 8.95
},{ "category": "fiction","author": "Evelyn Waugh","title": "Sword of Honour","price": 12.99
},"author": "Herman Melville","title": "Moby Dick","isbn": "0-553-21311-3","price": 8.99
},"author": "J. R. R. Tolkien","title": "The Lord of the Rings","isbn": "0-395-19395-8","price": 22.99
}
],"bicycle": {
"color": "red","price": 19.95
}
}
}
from jsonpath import jsonpath
print(jsonpath(book_dict,'$..author')) # 如果取不到将返回False # 返回列表,如果取不到将返回False
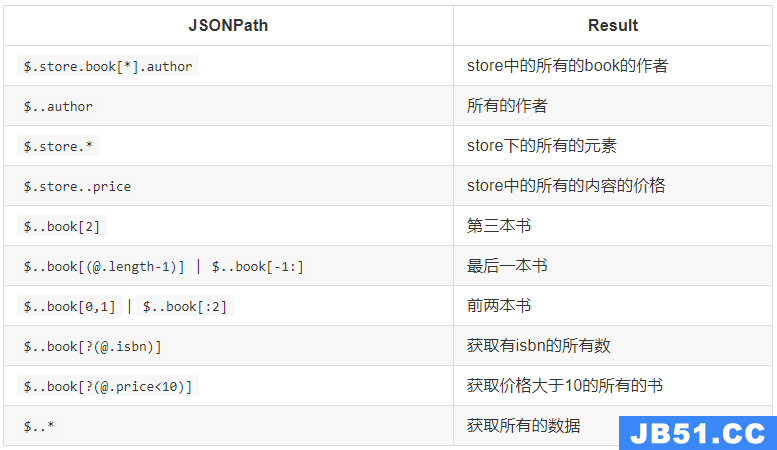
jsonpath练习
我们以拉勾网城市JSON文件 http://www.lagou.com/lbs/getAllCitySearchLabels.json 为例,获取所有城市的名字的列表,并写入文件。
参考代码:
import requests
import jsonpath
import json
# 获取拉勾网城市json字符串
url = 'http://www.lagou.com/lbs/getAllCitySearchLabels.json'
headers = {"User-Agent": "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)"}
response =requests.get(url, headers=headers)
html_str = response.content.decode()
# 把json格式字符串转换成python对象
jsonobj = json.loads(html_str)
# 从根节点开始,获取所有key为name的值
citylist = jsonpath.jsonpath(jsonobj,'$..name')
# 写入文件
with open('c','w') as f:
content = json.dumps(citylist, ensure_ascii=False)
f.write(content)
输出结果:city_name.txt
["安阳","安庆","安康","鞍山","安顺","澳门","阿拉善盟","阿坝藏族羌族自治州","阿拉尔","北京","保定","包头","滨州","蚌埠","宝鸡","北海","亳州","毕节","百色","保山","巴音郭楞","巴中","本溪","白银","巴彦淖尔","白城","白山","北屯","成都","长沙","重庆","长春","常州","沧州","郴州","赤峰","承德","常德","潮州","滁州","朝阳","楚雄","澄迈","池州","昌吉","崇左","昌都","东莞","大连","德州","德阳","大理","东营","大同","达州","大庆","丹东","德宏","儋州","定西","大兴安岭","鄂尔多斯","鄂州","恩施","佛山","福州","阜阳","抚州","阜新","抚顺","防城港","广州","贵阳","赣州","桂林","广安","贵港","甘孜藏族自治州","广元","甘南","杭州","合肥","惠州","哈尔滨","海口","呼和浩特","湖州","邯郸","菏泽","衡水","淮安","海外","衡阳","怀化","黄石","黄冈","淮南","淮北","河源","鹤壁","汉中","黑河","河池","呼伦贝尔","红河","黄山","葫芦岛","哈密","海东","贺州","黄南","济南","金华","嘉兴","江门","济宁","揭阳","九江","晋中","荆州","焦作","锦州","景德镇","吉林","佳木斯","吉安","晋城","荆门","金昌","济源","酒泉","嘉峪关","昆明","开封","喀什","克拉玛依","廊坊","兰州","洛阳","临沂","聊城","柳州","连云港","乐山","六安","丽水","临汾","泸州","漯河","龙岩","吕梁","丽江","凉山彝族自治州","拉萨","六盘水","娄底","辽阳","临沧","陵水黎族自治县","辽源","临夏","林芝","来宾","陇南","绵阳","眉山","茂名","梅州","马鞍山","牡丹江","南京","宁波","南昌","南宁","南通","南阳","宁德","南充","内江","南平","莆田","盘锦","濮阳","平顶山","萍乡","普洱","攀枝花","平凉","青岛","泉州","清远","秦皇岛","曲靖","衢州","齐齐哈尔","钦州","琼海","庆阳","七台河","黔南","黔西南","黔东南","日照","日喀则","上海","深圳","苏州","沈阳","石家庄","汕头","绍兴","宿迁","商丘","三亚","上饶","韶关","宿州","十堰","汕尾","遂宁","邵阳","绥化","随州","三门峡","三明","四平","松原","朔州","石嘴山","石河子","商洛","山南","神农架林区","天津","太原","台州","唐山","泰州","泰安","通辽","铜仁","通化","铜陵","铁岭","天水","台湾","铜川","天门","铁门关","武汉","无锡","温州","潍坊","芜湖","乌鲁木齐","威海","渭南","梧州","乌兰察布","武威","文山","万宁","文昌","乌海","五家渠","五指山","西安","厦门","徐州","新乡","襄阳","邢台","咸阳","香港","许昌","西宁","孝感","信阳","新余","湘潭","咸宁","宣城","西双版纳","仙桃","忻州","湘西土家族苗族自治州","兴安盟","锡林郭勒盟","烟台","扬州","银川","盐城","宜宾","宜昌","阳江","玉林","岳阳","宜春","运城","益阳","营口","榆林","玉溪","雅安","云浮","永州","阳泉","鹰潭","延边","伊犁","伊春","延安","郑州","珠海","中山","淄博","株洲","漳州","湛江","肇庆","镇江","遵义","周口","枣庄","驻马店","张家口","长治","舟山","张掖","资阳","昭通","自贡","张家界","中卫"]
http协议复习
http以及https的概念和区别
HTTPS比HTTP更安全,但是性能更低
- HTTP:超文本传输协议,默认端口号是80
- 超文本:是指超过文本,不仅限于文本;还包括图片、音频、视频等文件
- 传输协议:是指使用共用约定的固定格式来传递转换成字符串的超文本内容
- HTTPS:HTTP + SSL(安全套接字层),即带有安全套接字层的超本文传输协,默认端口号:443
- SSL对传输的内容(超文本,也就是请求体或响应体)进行加密
- 可以打开浏览器访问一个url,右键检查,点击net work,点选一个url,查看http协议的形式
爬虫特别关注的请求头和响应头
特别关注的请求头字段
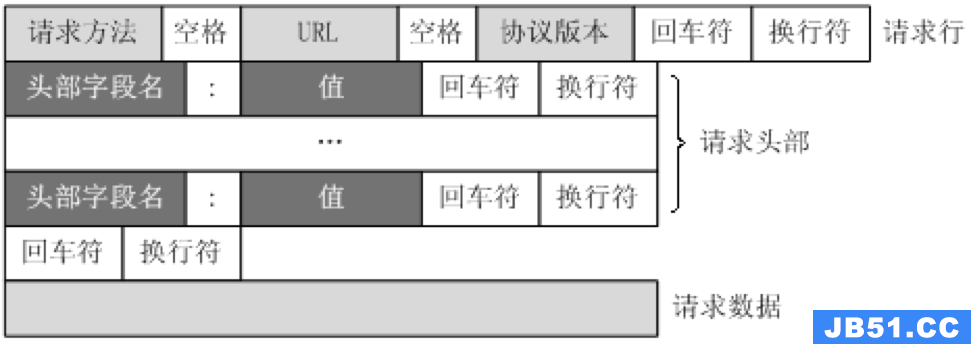
http请求的形式如上图所示,爬虫特别关注以下几个请求头字段
- Content-Type
- Host (主机和端口号)
- Connection (链接类型)
- Upgrade-Insecure-Requests (升级为HTTPS请求)
- User-Agent (浏览器名称)
- Referer (页面跳转处)
- Cookie (Cookie)
- Authorization(用于表示HTTP协议中需要认证资源的认证信息,如前边web课程中用于jwt认证)
加粗的请求头为常用请求头,在服务器被用来进行爬虫识别的频率最高,相较于其余的请求头更为重要,但是这里需要注意的是并不意味这其余的不重要,因为有的网站的运维或者开发人员可能剑走偏锋,会使用一些比较不常见的请求头来进行爬虫的甄别
特别关注的响应头字段
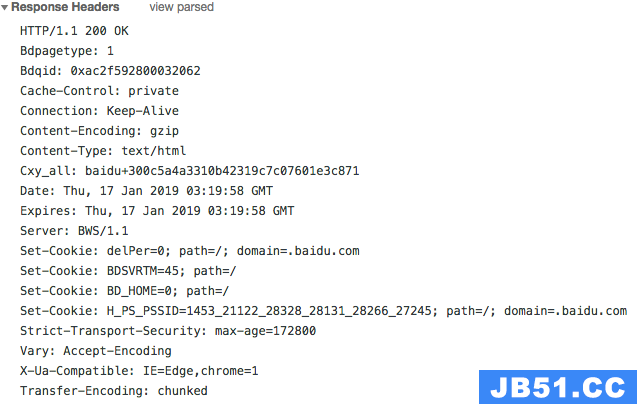
http响应的形式如上图所示,爬虫只关注一个响应头字段
- Set-Cookie (对方服务器设置cookie到用户浏览器的缓存)
常见的响应状态码
- 200:成功
- 302:跳转,新的url在响应的Location头中给出
- 303:浏览器对于POST的响应进行重定向至新的url
- 307:浏览器对于GET的响应重定向至新的url
- 403:资源不可用;服务器理解客户的请求,但拒绝处理它(没有权限)
- 404:找不到该页面
- 500:服务器内部错误
- 503:服务器由于维护或者负载过重未能应答,在响应中可能可能会携带Retry-After响应头;有可能是因为爬虫频繁访问url,使服务器忽视爬虫的请求,最终返回503响应状态码
服务器给我的相关反馈,我们在学习的时候就被教育说应该将真实情况反馈给客户端,但是在爬虫中,可能该站点的开发人员或者运维人员为了阻止数据被爬虫轻易获取,可能在状态码上做手脚,也就是说返回的状态码并不一定就是真实情况,比如:服务器已经识别出你是爬虫,但是为了让你疏忽大意,所以照样返回状态码200,但是响应体重并没有数据。
所有的状态码都不可信,一切以是否从抓包得到的响应中获取到数据为准
浏览器的运行过程
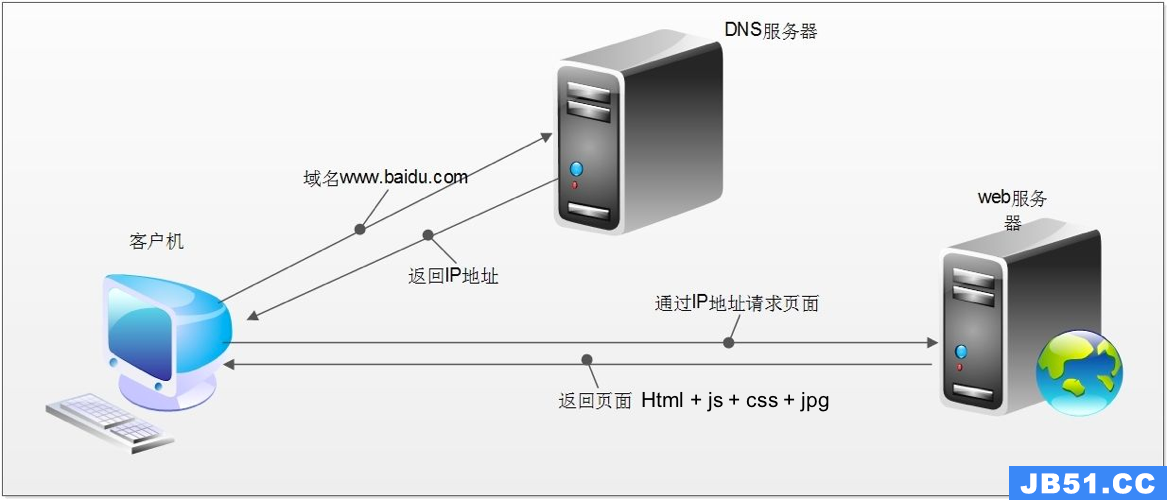
http请求的过程
- 浏览器在拿到域名对应的ip后,先向地址栏中的url发起请求,并获取响应
- 在返回的响应内容(html)中,会带有css、js、图片等url地址,以及ajax代码,浏览器按照响应内容中的顺序依次发送其他的请求,并获取相应的响应
- 浏览器每获取一个响应就对展示出的结果进行添加(加载),js,css等内容会修改页面的内容,js也可以重新发送请求,获取响应
- 从获取第一个响应并在浏览器中展示,直到最终获取全部响应,并在展示的结果中添加内容或修改————这个过程叫做浏览器的渲染
注意:
但是在爬虫中,爬虫只会请求url地址,对应的拿到url地址对应的响应(该响应的内容可以是html,css,js,图片等)
浏览器渲染出来的页面和爬虫请求的页面很多时候并不一样,是因为爬虫不具备渲染的能力(当然后续课程中我们会借助其它工具或包来帮助爬虫对响应内容进行渲染)
- 浏览器最终展示的结果是由多个url地址分别发送的多次请求对应的多次响应共同渲染的结果
- 所以在爬虫中,需要以发送请求的一个url地址对应的响应为准来进行数据的提取
requests包
import requests
常用方法
| 方法 | 描述 |
|---|---|
| requests.request(url) | 构造一个请求,支持以下各种方法 |
| requests.get() | 发送一个Get请求 |
| requests.post() | 发送一个Post请求 |
| requests.head() | 获取HTML的头部信息 |
| requests.put() | 发送Put请求 |
| requests.patch() | 提交局部修改的请求 |
| requests.delete() | 提交删除请求 |
常用属性或方法
| 属性或方法 | 描述 |
|---|---|
| .status_code | 响应状态码 |
| .content | 返回⼆进制结果 |
| .text | 返回编码解析的结果 |
| .encoding | 定义编码 |
| .cookie | 获取请求后的cookie |
| .url | 获取请求网址 |
| .json() | 返回字典,可能抛出异常 |
| .raw | 返回原始socket response,需要加参数stream=True |
content和text区别
content中间存的是字节码,而text中存的是Beautifulsoup模块根据猜测的编码方式将content内容编码成字符串后的结果。
直接输出content,会发现前面存在b’这样的标志,这是字节字符串的标志,而text是没有前面的b,对于纯ascii码,这两个可以说一模一样,对于其他的文字,需要正确编码才能正常显示。
有中文的时候,直接使用text会显示乱码,所以需要使用content对象来手动进行解码后才能正常显示。
响应状态码
| 分类 | 分类描述 |
|---|---|
| 1** | 信息,服务器收到请求,需要请求者继续执⾏操作 |
| 2** | 成功,操作被成功接收并处理 |
| 3** | 重定向,需要进⼀步的操作以完成请求 |
| 4** | 客户端错误,请求包含语法错误或⽆法完成请求 |
| 5** | 服务器错误,服务器在处理请求的过程中发⽣了错误 |
GET请求
requests.get()
不带参数的请求
#get请求
res = requests.get("http://www.baidu.com")
print(r.status_code)
print(r.text)
print(r.content)
print(r.json())
带参数的请求
#将参数name和age拼接到URL中进行请求
res = requests.get("http://httpbin.org/getname=gemey&age=22")
#输出返回对象的文本结果
print(res.text)
#将参数name和age定义到字典params中
params={
"name":"tony",
"age":20
}
#发送请求参数
res = requests.get("http://httpbin.org/get",params=params)
#输出返回对象的文本结果
print(res.text)
# 定义HTTP头信息,cookie,UA和referer
headers = {
"User-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML,like Gecko) Chrome/116.0.0.0 Safari/537.36",
"referer": "https://www.abidu.com",
"Cookies": "1234565678"
}
# 发送请求参数
res = requests.get("http://httpbin.org/get",headers = headers)
# 输出返回对象的文本结果
print(res.text)
POST请求
requests.post():POST请求一般用于提交参数,所以直接进行有参数的POST请求测试。
import requests
# 将参数name和age定义到字典params中
params = {
"name": "tony",
"age": 20
}
url = 'http://httpbin.org/post'
# 定义HTTP头信息
headers = {
"User-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML,
"Cookies": "1234565678"
}
# 发送请求参数
res = requests.post(url = url,params = params,headers = headers)
# 输出返回对象的文本结果
print(res.text)
BeautifulSoup包
Beautiful Soup是一个用于从HTML和XML文件中提取数据的Python模块。
from bs4 import BeautifulSoup
import lxml
解释器
soup=beautifulsoup(解析内容,解析器)
| 解析器 | 使用方法 | 优势 | 劣势 | |
|---|---|---|---|---|
| Python标准库 | BeautifulSoup(markup,"html.parser") |
Python的内置标准库、执行速度适中、文档容错能力强 | Python 2.7.3 or 3.2.2)前 的版本中文档容错能力差 | |
| lxml HTML 解析器 | BeautifulSoup(markup,“lxml”) |
速度快、文档容错能力强 | 需要安装C语言库 | |
| lxml XML 解析器 |
BeautifulSoup(markup,["lxml-xml"])、 BeautifulSoup(markup,"xml")
|
速度快、唯一支持XML的解析器 | 需要安装C语言库 | |
| html5lib | BeautifulSoup(markup,"html5lib") |
最好的容错性、以浏览器的方式解析文档、生成HTML5格式的文档 | 速度慢、不依赖外部扩展 |
用法
#获取Tag,通俗点就是HTML中的一个个标签
soup.title # 获取整个title标签字段
soup.title.name # 获取title标签名称
soup.title.parent.name # 获取 title 的父级标签名称
soup.p # 获取第一个p标签字段
soup.p['class'] # 获取第一个p中class属性值
soup.p.get('class') # 等价于上面
soup.a # 获取第一个a标签字段
soup.find_all('a') # 获取所有a标签字段
soup.find(id="link3") # 获取属性id值为link3的字段
soup.a['class'] = "newClass" # 可以对这些属性和内容等等进行修改
del bs.a['class'] # 还可以对这个属性进行删除
soup.find('a').get('id') # 获取class值为story的a标签中id属性的值
soup.title.string # 获取title标签的值
1、获取拥有指定属性的标签
方法一:获取单个属性
soup.find_all('div',id="even") # 获取所有id=even属性的div标签
soup.find_all('div',attrs={'id':"even"}) # 效果同上
方法二:
soup.find_all('div',id="even",class_="square") # 获取所有id=even并且class=square属性的div标签
soup.find_all('div',attrs={"id":"even","class":"square"}) # 效果同上
2、获取标签的属性值
#方法一:通过下标方式提取
for link in soup.find_all('a'):
print(link['href']) //等同于 print(link.get('href'))
#方法二:利用attrs参数提取
for link in soup.find_all('a'):
print(link.attrs['href'])
3、获取标签中的内容
divs = soup.find_all('div') # 获取所有的div标签
for div in divs: # 循环遍历div中的每一个div
a = div.find_all('a')[0] # 查找div标签中的第一个a标签
print(a.string) # 输出a标签中的内容
如果结果没有正确显示,可以转换为list列表
4、stripped_strings
divs = soup.find_all('div')
for div in divs:
infos = list(div.stripped_strings) # 去掉空格换行等
bring(infos)
5.输出
# 格式化输出
soup = BeautifulSoup(markup)
print(soup.prettify())
#get_text()输出
soup.get_text()
soup.i.get_text()
案例:爬取豆瓣电影Top250
import requests
from bs4 import BeautifulSoup
class Douban:
def __init__(self):
self.URL = 'https://movie.douban.com/top250'
self.start_num = []
for start_num in range(0, 251, 25):
self.start_num.append(start_num)
self.header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML,like Gecko) Chrome/79.0.3945.130 Safari/537.36'}
def get_top250(self):
for start in self.start_num:
start = str(start)
html = requests.get(self.URL, params={'start':start}, headers=self.header)
soup = BeautifulSoup(html.text, 'lxml')
names = soup.select('#content > div > div.article > ol > li > div > div.info > div.hd > a > span:nth-child(1)')
for name in names:
print(name.get_text())
if __name__ == "__main__":
cls = Douban()
cls.get_top250()
lxml包
from lxml import etree
初始化
text = '''
<body>
<div class="hello">这是测试的div</div>
<div>
<div class="hello,baby">
这是嵌套的div标签
<p>
这是嵌套的p标签
</p>
</div>
</div>
<p>这是测试的p</p>
</body>
'''
html = etree.HTML(text)
#text:html内容的字符串
#html:一个lxml库的对象
result = etree.tostring(html) #传入的不是完整结构,但是lxml会在一定程度上完善我们的html代码,尽量使它变为标准的结构。
语法
1.寻找节点
| 语法 | 含义 |
|---|---|
| nodename(节点名字) | 直接根据写的节点名字查找节点,如:div |
| // | 在当前节点下的子孙节点中寻找,如://div |
| / | 在当前节点下的子节点中寻找,如:/div |
| . | 代表当前节点(可省略不写,就像我们有时候写的相对路径),如:./div |
| … | 当前节点的父节点,如:…/div |
result = html.xpath('//div/text()') #使用xpath语法,一是在子孙节点中寻找,二是寻找div的标签
print(result)
result = html.xpath('/html/body/div/text()')
print(result)
2.属性筛选
| 方法名\符号 | 作用 |
|---|---|
| @ | 获取属性或者筛选属性,如:@class |
| contains | 判断属性中是否含有某个值(用于多值判断),如:contains(@class,‘hello’) |
# 筛选出class="hello"的div标签
hello_tag = html.xpath('//div[@class="hello"]') # 注意筛选的方法都是在中括号里面的
print(hello_tag) # 结果为: [<Element div at 0x19066c3a500>],即找到了一个标签,符合条件
#筛选出具有class="hello"的div标签
hello_tags = html.xpath('//div[contains(@class,"hello")]')
print(hello_tags) #结果为:[<Element div at 0x133c345a500>,<Element div at 0x133c345a840>],即找到了两个div标签,符合条件
3.按序选择
| 方法 | 作用 |
|---|---|
| last() | 获取最后一个标签 |
| 1 | 获取第一个标签 |
| position() < = > num | 筛选多个标签 |
from lxml import etree
text = '''
<ul>
<li>1</li>
<li>2</li>
<li>3</li>
<li>4</li>
<li>5</li>
<li>6</li>
<li>7</li>
<li>8</li>
</ul>
'''
#初始化
html = etree.HTML(text)
#获取第一个li标签
first_tag = html.xpath('//li[1]') #令人吃惊,lxml并没有first()方法
print(first_tag)
#获取最后一个li标签
last_tag = html.xpath('//li[last()]')
print(last_tag)
#获取前五个标签
li_tags = html.xpath('//li[position() < 6]')
print(li_tags)
#获取第一个和第二个标签,使用or
tags = html.xpath('//li[position() = 1 or position() = 2]')
print(tags)
4.获取属性和文本
| 方法 | 作用 |
|---|---|
| @ | 获取属性或者筛选属性 |
| text() | 获取文本 |
#获取第div的class属性
div_class = html.xpath('//div/@class')
print(div_class) #结果为:['hello','hello,baby']
# 获取第一个div中的p标签中的文本
content = html.xpath('//div/p/text()') # 注意使用text()的时机和位置
print(content) # 结果为:['这是嵌套的p标签'],仍然是以列表形式返回结果
# 获取拥有第二个div中的文本,注意观察下面的不同之处
content_two = html.xpath('//div[position() = 2]/text()')
print(content_two) # 结果为: ['\n ','\n ']
content_three = html.xpath('//div[position() = 2]//text()')
print(content_three) # 结果为: ['\n ','\n 这是嵌套的div标签\n ','这是嵌套的p标签','\n ','\n ']
# 两者不同之处在于:一个为//,一个为/。//获取其子孙节点中的内容,而/只获取其子节点的内容。
5.节点修饰语法
| 路径表达式 | 结果 |
|---|---|
| //title[@lang=“eng”] | 选择lang属性值为eng的所有title元素 |
| /bookstore/book[1] | 选取属于 bookstore 子元素的第一个 book 元素。 |
| /bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素。 |
| /bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
| /bookstore/book[position()>1] | 选择bookstore下面的book元素,从第二个开始选择 |
| //book/title[text()=‘Harry Potter’] | 选择所有book下的title元素,仅仅选择文本为Harry Potter的title元素 |
| /bookstore/book[price>35.00]/title | 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |
关于xpath的下标
- 在xpath中,第一个元素的位置是1
- 最后一个元素的位置是last()
- 倒数第二个是last()-1
爬虫实战——静态网页
爬取某配乐网站mp3音效
import os.path
import random
import time
import requests
import lxml.etree
page_n = int(input("请输入你想要爬取的网页数量"))
for i in range(page_n):
url = f'https://www.tuke88.com/yinxiao/zonghe_0_{i}.html'
response = requests.get(url)
#解析器:帮助修复html中的语法错误
html_parser = lxml.etree.HTMLParser()
html = lxml.etree.fromstring(response.text,parser=html_parser)
titles = html.xpath("//div[@class='lmt']//div[@class='audio-list']//a[@class='title']/text()")
mp3_urls = html.xpath("//div[@class='lmt']//div[@class='audio-list']//source/@src")
if not os.path.exists('pymp3'):
os.mkdir('pymp3')
for title,mp3_url in zip(titles,mp3_urls):
mp3_stream = requests.get(mp3_url,stream=True)
with open(os.path.join('pymp3',title+".mp3"),'wb+') as writer:
writer.write(mp3_stream.raw.read())
print(f'【INFO】{title}.mp3下载成功')
time.sleep(random.uniform(0.1,0.4))
原文地址:https://blog.csdn.net/weixin_44319595/article/details/132982810
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。