
本文为博客园作者所写: 一寸HUI,个人博客地址:https://www.cnblogs.com/zsql/
简单的一个类就直接说了。LinkedList 的底层结构是一个带头/尾指针的双向链表,可以快速的对头/尾节点 进行操作,它允许插 入所有元素,包括 null。 相比数组(这里可以对比ArrayList源码分析进行查看),链表的特点就是在指定位置插入和删除元素的效率较高,但是查找的 效率就不如数组那么高了。如果熟悉双向链表这个数据结构,其实就很简单了,无非就是实现一些数据的添加,删除,查询,遍历等功能,双向链表的结构图如下:
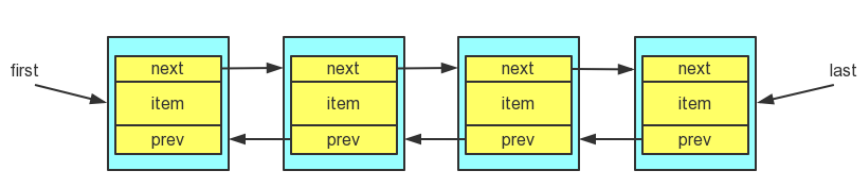
每一个数据(节点)都包含3个部分,一个是数据本身item,一个是指向下一个节点的next指针,还有就是指向上一个节点的prev指针,另外,双向链表还有一个 first 指针,指向头节点,和 last 指针,指向尾节点。,在LinkedList类中通过私有的静态内部类Node作为每一个数据的封装。具体实现如下:
private static class Node<E> { //这个类就是用来封装双向链表中的每一个数据,也是上图中的每一个框
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev,E element,Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
接下看看LinkList类的定义:
public class LinkedList<E>
extends AbstractSequentialList<E> //继承的类
implements List<E>,Deque<E>,Cloneable,java.io.Serializable //实现的各种接口
{}
接下来看看LinkedList这个类的一些属性:就三个属性,一个用来记录双向链表的大小,一个是first节点用来指向链表的头,last用来指向链表的尾
transient int size = 0;
/**
* Pointer to first node.
* Invariant: (first == null && last == null) ||
* (first.prev == null && first.item != null)
*/
transient Node<E> first;
* Pointer to last node.
* Invariant: (first == null && last == null) ||
* (last.next == null && last.item != null)
transient Node<E> last;
在看看构造方法:
* Constructs an empty list.
public LinkedList() { //空参构造
}
* Constructs a list containing the elements of the specified
* collection,in the order they are returned by the collection's
* iterator.
*
* @param c the collection whose elements are to be placed into this list
* @throws NullPointerException if the specified collection is null
public LinkedList(Collection<? extends E> c) { //通过已有的集合进行构造
this();
addAll(c); //使用addAll()方法把集合中的数据生产LinkedList
}
boolean addAll(Collection<? c) {
return addAll(size,c);
}
boolean addAll(int index,Collection<? c) {
checkPositionIndex(index);
Object[] a = c.toArray(); //把集合转为数组
int numNew = a.length;
if (numNew == 0)
return false;
Node<E> pred,succ;
if (index == size) {
succ = null;
pred = last;
} else {
succ = node(index);
pred = succ.prev;
}
for (Object o : a) { //对数组进行遍历,对每一个元素都封装成Node并添加到LinkedList中
@SuppressWarnings("unchecked") E e = (E) o;
Node<E> newNode = new Node<>(pred,e,);
if (pred == )
first = newNode;
pred.next = newNode;
pred = newNode;
}
if (succ == ) {
last = pred;
} {
pred.next = succ;
succ.prev = pred;
}
size += numNew;
modCount++;
true;
}
接下来看看LinkedList的基本操作,添加,删除,遍历,查询等
先看添加,从双向链表的结构来看,添加元素可以在链表的头、尾、以及中间的任意位置添加新的元素。因为 LinkedList 有头指针和尾指针,所以在表头或表尾进 行插入元素只需要 O(1) 的时间,而在指定位置插入元素则需要先遍历一下链表, 所以复杂度为 O(n)。首先看看在头部添加元素:

看图可以看出,只要把first指向新的node,新的node的next指向原先firt指向的node,再把原先first指向的node的prev指向新的node就可以了。
* Links e as first element.
void linkFirst(E e) {
final Node<E> f = first; //使用临时node
final Node<E> newNode = new Node<>( newNode;
if (f == ) //判断first是否为空
last =
f.prev = newNode; //把f的prev指向新的node
size++; //链表长度加1
modCount++; //记录链表被修改的次数
}
在看看在尾部添加,其实和在头部添加一样,只是把first换成了last,逻辑一样
* Links e as last element. linkLast(E e) { final Node<E> l = last; new Node<>(l,1)">); last =if (l == ) first = l.next = newNode; size++; modCount++; }
再看看在中间的任意位置添加:
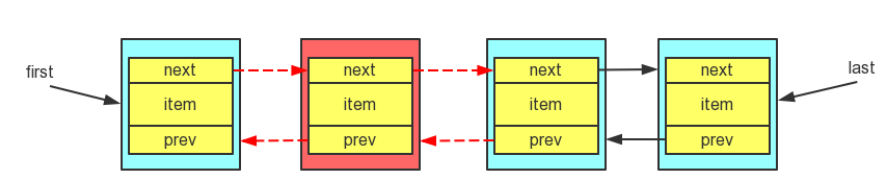
这个相对来说复杂点点,修改添加前后node的next和prev的指向,修改的相对来说多点点
* Inserts element e before non-null Node succ. void linkBefore(E e,1)"> succ) { //表示在在succ节点前面添加e元素 // assert succ != null; final Node<E> pred = succ.prev; //获取succ的前面节点 new Node<>(pred,succ); //把e封装成节点,并把prev指向succ前面节点,把next指向succ节点 succ.prev = newNode; //然后把succ的prev指向新的节点 pred.next = newNode; //把succ的前节点的next只想新的节点 size++; //链表长度+1 modCount++; //修改次数+1 }
添加说完了,就说说删除,其实也很简单
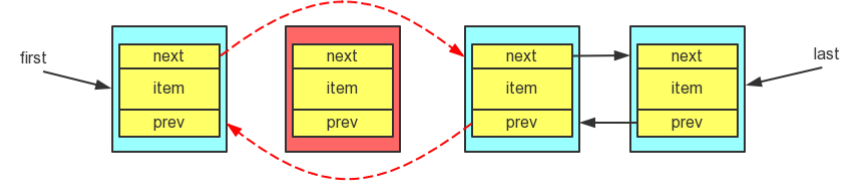
删除也是分为从头部、尾部、中间位置删除
先看看从first位置删除
* Unlinks non-null first node f.
private E unlinkFirst(Node<E> f) {
assert f == first && f != null;
final E element = f.item; //获取first中间的元素,用于后面的返回
final Node<E> next = f.next; //获取f的next节点
f.item = ;
f.next = null; help GC 清除
first = next; //把first指向f的next
if (next == )
last =
next.prev = ; //清除
size--; //链表长度-1
modCount++; //修改次数+1
element;
}
看了从头部删除,其实尾部删除也差不多
* Unlinks non-null last node l.
private E unlinkLast(Node<E> l) {
assert l == last && l != null;
l.item;
final Node<E> prev = l.prev;
l.item = ;
l.prev = help GC
last = prev;
if (prev == )
first =
prev.next = ;
size-- element;
}
在看看从指定位置删除吧
* Unlinks non-null node x.
*/
E unlink(Node<E> x) {
assert x != null;
x.item; //获取该节点的值
x.next; //获取该节点的next节点
x.prev; //获取该节点的prev节点
) { //把该节点的前节点的next指向该节点的next节点,并清除该节点的prev指向
first = next;
} {
prev.next = next;
x.prev = ;
}
) { //把该节点的next节点的prev指向该节点的prev节点,并清除该节点的next指向
last = prev;
} {
next.prev = prev;
x.next = ;
}
x.item = ; //清除
size-- element;
}
看完增删,那就继续看查相关的方法,也有从头,尾相关的查询方法,都很简单,做判断,然后查询
* Returns the first element in this list.
*
* @return the first element in this list
* NoSuchElementException if this list is empty
E getFirst() {
first;
throw new NoSuchElementException();
f.item;
}
* Returns the last element in this list.
*
* the last element in this list
* E getLast() {
l.item;
}
当然还有指定index查询的
* Returns the (non-null) Node at the specified element index.
Node<E> node(int index) {
assert isElementIndex(index);
//判断index是在链表的前半段还是在后半段,如果在前半段就从first向后遍历,否则使用last向前遍历
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
x;
} {
Node<E> x = last;
int i = size - 1; i > index; i-- x.prev;
x;
}
}
其实基本知道了上面的方法基本对双向链表有了一定的熟悉,当然LinkedList还有很多其他的方法,不过很多都是基于上面这些方法的一些封装,例如:
* Inserts the specified element at the beginning of this list.
*
* e the element to add
addFirst(E e) {
linkFirst(e);
}
* Appends the specified element to the end of this list.
*
* <p>This method is equivalent to {@link #add}.
*
* addLast(E e) {
linkLast(e);
}
* Removes and returns the first element from this list.
*
* the first element from this list
* E removeFirst() {
unlinkFirst(f);
}
* Removes and returns the last element from this list.
*
* the last element from this list
* E removeLast() {
unlinkLast(l);
}
#addLast}.
*
* e element to be appended to this list
* {@code true} (as specified by { Collection#add})
boolean add(E e) {
linkLast(e);
;
}
* Removes the first occurrence of the specified element from this list,* if it is present. If this list does not contain the element,it is
* unchanged. More formally,removes the element with the lowest index
* { i} such that
* <tt>(o==null ? get(i)==null : o.equals(get(i)))</tt>
* (if such an element exists). Returns { true} if this list
* contained the specified element (or equivalently,if this list
* changed as a result of the call).
*
* o element to be removed from this list,if present
* true} if this list contained the specified element
remove(Object o) {
if (o == ) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == ) {
unlink(x);
;
}
}
} {
if (o.equals(x.item)) {
unlink(x);
;
}
}
}
* Removes all of the elements from this list.
* The list will be empty after this call returns.
clear() {
Clearing all of the links between nodes is "unnecessary",but:
- helps a generational GC if the discarded nodes inhabit
more than one generation
- is sure to free memory even if there is a reachable Iterator
; ) {
Node<E> next = x.next;
x.item = ;
x.next = ;
x.prev = ;
x = next;
}
first = last = ;
size = 0
* Removes the element at the specified position in this list. Shifts any
* subsequent elements to the left (subtracts one from their indices).
* Returns the element that was removed from the list.
*
* index the index of the element to be removed
* the element previously at the specified position
* IndexOutOfBoundsException {@inheritDoc}
public E remove( index) {
checkElementIndex(index);
unlink(node(index));
}
* Returns the index of the first occurrence of the specified element
* in this list,or -1 if this list does not contain the element.
* More formally,returns the lowest index { i} such that
* <tt>(o==null ? get(i)==null : o.equals(get(i)))</tt>,* or -1 if there is no such index.
*
* o element to search for
* the index of the first occurrence of the specified element in
* this list,or -1 if this list does not contain the element
indexOf(Object o) { //查找元素o是否在链表中,并返回index,没找到返回-1
int index = 0)
index;
index++;
}
} (o.equals(x.item))
;
}
}
return -1;
}
到这里本文就结束了了,如果想知道LinkedList的更多方法,建议去看源码
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。