

目录
这是视觉问答论文阅读的系列笔记之一,本文有点长,请耐心阅读,定会有收货。如有不足,随时欢迎交流和探讨。
一、文献摘要介绍
In this paper, we propose a novel Question-Guided Hybrid Convolution (QGHC) network for Visual Question Answering (VQA). Most state-of-the-art VQA methods fuse the high-level textual and visual features from the neural network and abandon the visual spatial @R_275_4045@ion when learning multi-modal features. To address these problems, question-guided kernels generated from the input question are designed to convolute with visual features for capturing the textual and visual relationship in the early stage. The question-guided convolution can tightly couple the textual and visual @R_275_4045@ion but also introduce more parameters when learning kernels. We apply the group convolution, which consists of question-independent kernels and question-dependent kernels, to reduce the parameter size and alleviate over-fitting. The hybrid convolution can generate discriminative multi-modal features with fewer parameters. The proposed approach is also complementary to existing bilinear pooling fusion and attention based VQA methods. By integrating with them, our method Could further boost the performance. Experiments on VQA datasets validate the effectiveness of QGHC.
作者在本文提出了一种新的用于视觉问答(VQA)的问题引导混合卷积(QGHC)网络。目前最先进的VQA方法大多融合了神经网络的高水平文本特征和视觉特征,在学习多模态特征时放弃了视觉空间信息。为了解决这些问题,从输入问题生成的以问题为指导的内核被设计为与视觉特征进行卷积,以便在早期捕获文本和视觉关系。以问题为导向的卷积可以将文本和视觉信息紧密耦合,但在学习内核时也可以引入更多参数。我们应用由与问题无关的内核和与问题相关的内核组成的组卷积来减小参数大小并缓解过度拟合。混合卷积可以以较少的参数产生有区别的多模态特征。所提出的方法也与现有的双线性池融合和基于注意力的VQA方法相补充。通过与它们的集成,我们的方法可以进一步提高性能。在VQA数据集上的实验验证了QGHC的有效性。
二、网络框架介绍
通常,采用卷积神经网络(CNN)来学习视觉特征,而循环神经网络(RNN)(例如长短期记忆(LSTM)或门控循环单元(GRU))对输入问题进行编码,即

其中
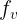
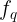
一般的视觉特征
![]()
其中,
![]()
![]()
![]()
![]()
![]()
但是,直接预测“完整”卷积内核的原始解决方案内存效率低下且耗时,为了解决这一问题,我们提出预测组卷积核的参数。组卷积将输入特征图沿通道维划分为几个组,因此每个组的卷积通道数都减少了。 然后,将每个组的卷积输出在通道维中进行级联,以生成输出特征图。另外,我们将卷积核分为动态预测的核和自由更新的核。动态核是依赖于问题的,其基于问题特征向量
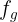
正式地,我们将等式(3)替换为VQA的提出的QGHC,
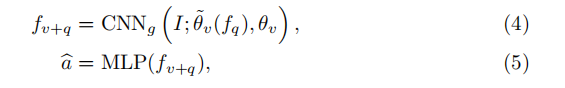
其中,
![]()
![]()
![]()
![]()
![]()
自由更新的内核可以捕获预先训练的图像模式,我们会在测试阶段对其进行修复。 动态预测的内核取决于输入的问题,并捕获问题图像之间的关系。 我们的模型通过卷积运算在模型早期融合了文本和视觉信息。 两种模态之间的空间信息得到了很好的保存,这比以前的特征级联策略可导致更准确的结果。 动态内核和自由更新的内核的组合对于保持准确性和效率至关重要,并且在我们的实验中显示出令人鼓舞的结果。
2.1QGHC module
我们堆叠多个QGHC模块,以更好地捕捉输入图像和问题之间的交互。在resnet和ResNeXt的启发下,我们的QGHC模块由1×1、3×3和1×1卷积组成。
如图2所示,该模块的设计类似于ShffuleNet 模块,具有组卷积和标识快捷方式。
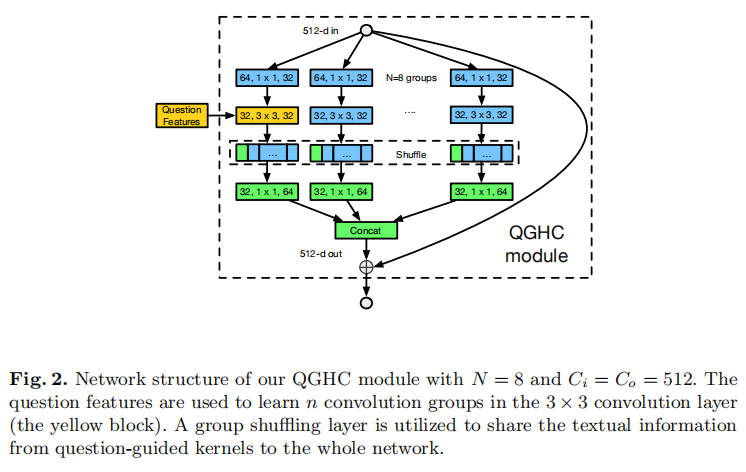
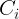
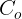
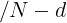
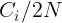
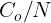
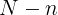
2.2. QGHC network for visual question answering
QGHC网络的网络结构如图3所示。resnet 首先在ImageNet上进行了预训练,以提取中级水平视觉特征。 问题特征由语言RNN模型生成。
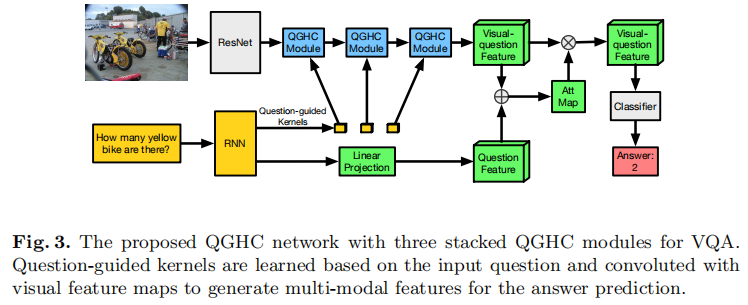
然后将视觉特征图发送到
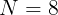
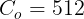
![]()
![]()
为了学习QGHC模块中的动态卷积核,问题特征
2.3. QGHC network with bilinear pooling and attention
我们提出的QGHC网络还可以与现有的双线性合并融合方法和注意力机制互补。为了与MLB融合方案结合,可以使用MLB将从全局平均池层提取的多模式特征与RNN问题特征再次融合。 融合的功能可用于预测最终答案。 文本和视觉功能的第二阶段融合在我们的实验中进一步提高了回答的准确性。
我们还应用了注意模型来更好地捕捉空间信息。因此,原来的全局平均池层被注意力图所取代。为了在感兴趣的位置上增加权重,通过注意机制学习权重图。空间softmax函数后的1×1卷积生成注意加权图。最终的多模态特征是所有位置特征的加权和。最后一个QGHC模块的输出特征图与线性变换的问题特征相加。 注意机制在图3中显示为绿色矩形。
三、实验分析
我们的模型在与最先进的方法进行比较时具有相同的设置。比较方法遵循其原始设置。对于所提出的方法,图像被调整为448×448。14×14×2048视觉特征是通过ImageNet预先训练的resnet-152来学习的,并且问题被skip-thought使用GRU编码为2400 d特征向量。 候选问题被选为训练和验证集中最常见的2,000个答案。 使用Adam优化器对模型进行训练,初始学习率为
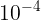
表1 我们提出的QGHC网络在VQA数据集上的消融研究。

表2在不使用注意机制的情况下,在VQA数据集上比较所提出的方法和最先进的方法的问题回答精度。
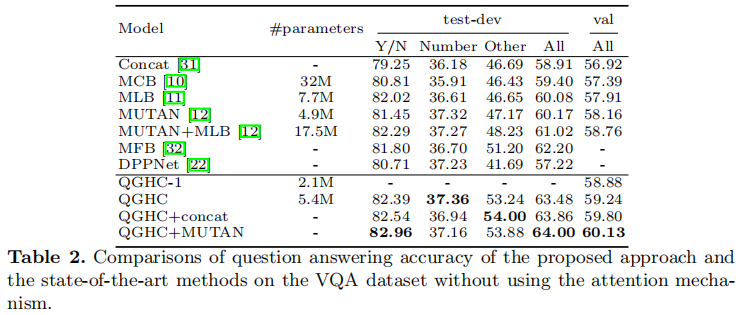
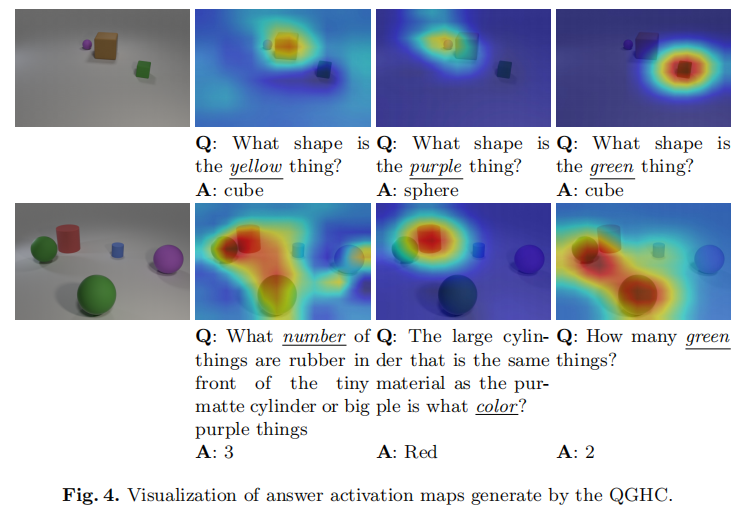
表3将所提出的方法的问题回答精度与VQA数据集上最先进的方法与注意机制进行比较。
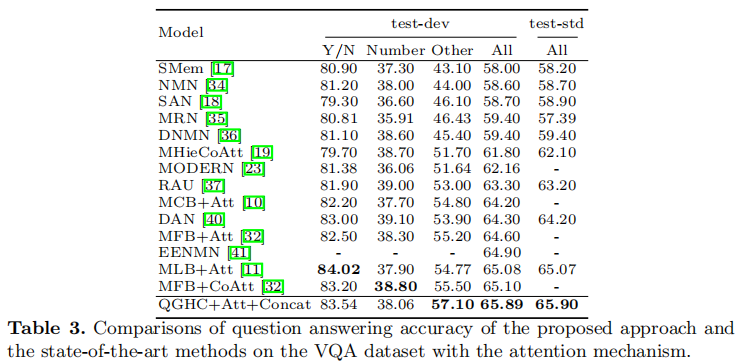
表4所提出的方法的问题回答精度与CLVER数据集上最先进的方法的比较。
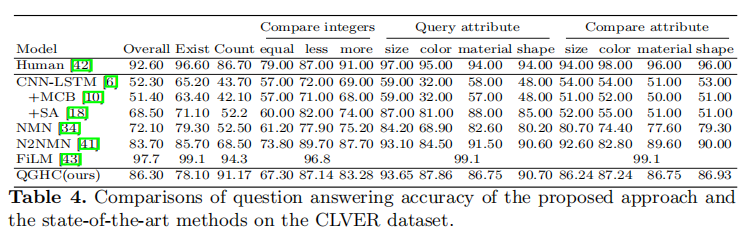
图4. QGHC生成的答案激活图的可视化。
四、结论
In this paper, we propose a question-guided hybrid convolution for learning discriminative multi-modal feature representations. Our approach fully utilizes the spatial @R_275_4045@ion and is able to capture complex relations between the image and question. By introducing the question-guided group convolution kernels with both dynamically-predicted and freely-updated kernels, the proposed QGHC network shows strong capability on solving the visual question answering problem. The proposed approach is complementary with existing feature fusion methods and attention mechanisms. Extensive experiments demonstrate the effectiveness of our QGHC network and its individual components.
在本文中,我们提出了一种用于学习判别式多模态特征表示的问题引导混合卷积。 我们的方法充分利用了空间信息,并且能够捕获图像和问题之间的复杂关系。 通过引入具有动态预测和自由更新的内核的问题引导群卷积内核,所提出的QGHC网络在解决视觉问题解答方面显示出强大的能力。 所提出的方法是对现有特征融合方法和注意力机制的补充。
此篇论文提出的利用空间信息问题,还真是之前没有考虑到的,利用卷积核操作,充分利用空间信息,得到了一点好的效果,方法还是不错的。


版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 [email protected] 举报,一经查实,本站将立刻删除。
