
N.1 协处理器的产生
| 1)HBase 和 MapReduce 有很高的集成,可以使用 MR 对存储在 HBase 中的数据进行分布式计算,但是:有些情况,例如简单的加法计算或者聚合操作(求和、计数等),如果能够将这些计算推送到 RegionServer,这将大大减少服务器和客户的的数据通信开销,从而提高 HBase 的计算性能。 2)另外,HBase 作为列式数据库,无法轻易建立“二级索引”,对于查询条件不在行健中的数据访问,效率十分低下。在这种情况下,HBase 在 0.92 之后引入了协处理器(coprocessors),它允许用户将部分逻辑在数据存放端即 HBase RegionServer 服务端进行计算,也即允许用户在 RegionServer 运行用户自定义的代码。 3)协处理器的引入,执行求和、计数、排序等操作将变得更加高效,因为 RegionServer 将处理好的数据再返回给客户端,这可以极大地降低需要传输的数据量,从而获得性能上的提升。同时协处理器也允许用户扩展实现 HBase 目前所不具备的功能,如权限校验、二级索引、完整性约束等。 4)coprocessor协处理器与数据库触发器类似:回调函数(也被称作钩子函数,hook)在一些特定事件发生时被执行,可理解为服务端的拦截器,可根据需求确定拦截点,再重写这些拦截点对应的方法,coprocessor协处理器主要是把部分计算移到数据的存放端。当然所有协处理器的类都必须实现这个Coprocessor接口。它定义了协处理器的基本约定,并使得框架本身的管理变得容易。 |
N.2 协处理器分类
| 1)coprocessor协处理器框架已经为我们提供了一些实现类,我们可以通过继承这些类来扩展自己的功能。这些类主要分为两大类: (1)Observer: 提供了一些设计好的回调函数(钩子),类似于关系数据库的触发器; (2)Endpoint: 客户端可以调用这些 Endpoint 协处理器帮客户端执行的自定义代码,最后将结果返回给客户端进一步处理 |
N.3 Observer类型
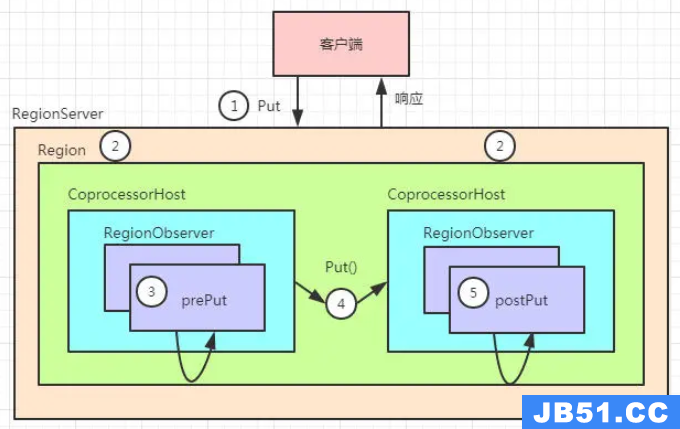
| 1)最常用的3种观察者接口: (1)WALObserver:运行于 RegionServer 中,进行 WAL 写和刷新之前或之后会触发这个钩子函数,一个 RegionServer 只有一个 WAL 的上下文; (2)MasterObserver:运行于 Master 进程中,进行诸如 DDL 的操作,如 create,delete,modify table 等之前或之后会触发这个钩子函数; (3)RegionObserver:基于表的 Region 上的 Get,Put,Delete,Scan 等操作之前或之后触发,比如可以在客户端进行 Get 操作的时候定义 RegionObserver 来校验是否具有 Get 权限等; 2)RegionObserver 为例,其执行流程大致如下图: (1)客户端发出 put 请求 (2)该请求被分派给合适的 RegionServer 和 Region (3)CoprocessorHost 拦截该请求,然后在该表的每个 RegionObserver 上调用 prePut() (4)prePut() 处理后,在 Region 执行 Put 操作 (5)Region 产生的结果再次被 CoprocessorHost 拦截,调用 postPut() (6)终结果被返回给客户端 |
————————————————————————
————————————————————————

————————————————————————
N.4 Endpoint
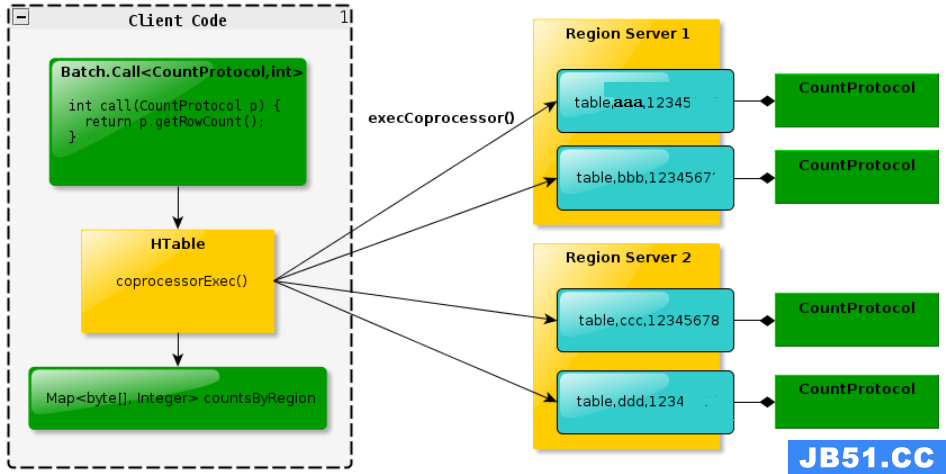
| 1)Endpoint 和传统数据库的存储过程很类似,用户提供一些自定义代码,并在 HBase 服务器端执行,结果通过 RPC 返回给客户,Endpoint 可以实现 min、 max、 avg、 sum、 distinct、 group by 等功能。以聚合为例,如果没有协处理器,当用户需要找出一张表中的最大数据,即 max 聚合操作,需要进行全表扫描,返回所以数据给客户端,然后在客户端遍历扫描结果,查找最大值。 这是一种典型的“移动数据”的计算方案,将所有数据都移动到计算一端 Client,由 Client 端统一执 行,这样无法利用底层集群的并发能力,效率低下,而利用 Coprocessor,则可以实现“移动计算”,用户可以将求最大值的代码放到 HBase Server 端,利用 HBase 集群的多个节点并发执行求最大值的操作。即在每个数据块(Region)内执行求最大值的代码,将每个数据块(Region)的最大值在RegionServer数据节点端计算出,仅仅将该max值返回给客户端。在客户端进一步将多个数据块(Region)的最大值进一步比较,进而找到其中的最大值。这样整体的执行效率就会提高很多。 |
————————————————————————
————————————————————————
原文地址:https://blog.csdn.net/weixin_43871785/article/details/130530891
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。