
安装 和 配置 HBase
一、安装 HBase
1, 下载、(解压or安装)HBase 数据库:
①(在Linux 系统下的火狐浏览器打开)官网: Index of /dist/hbase (apache.org)
② 解压安装包hbase-2.2.2-bin.tar.gz至路径 /usr/local,命令如下:
cd ~ sudo tar -zxf ~/下载/hbase-2.2.2-bin.tar.gz -C /usr/local
③ 将解压的文件名hbase-2.2.2改为hbase,以方便使用,命令如下:
cd /usr/local sudo mv ./hbase-2.2.2 ./hbase
④ 下面把hbase目录权限赋予给hadoop用户:
cd /usr/local sudo chown -R hadoop ./hbase
2, 配置环境变量(好处:启动hbase就无需到/usr/local/hbase目录下,大大的方便了hbase的使用)
■ 编辑~/.bashrc文件
vim ~/.bashrc
●编辑~/.bashrc文件时的注意事项:
① 如果没有引入过PATH请在~/.bashrc文件尾行添加如下内容:export PATH=$PATH:/usr/local/hbase/bin
② 如果已经引入过PATH请在export PATH这行追加/usr/local/hbase/bin,这里的“:”是分隔符。如下图:

■ 执行source命令使上述配置在当前终端立即生效,命令如下:
source ~/.bashrc
3,添加HBase权限:
cd /usr/local sudo chown -R hadoop ./hbase #将hbase下的所有文件的所有者改为hadoop,hadoop是当前用户的用户名。
4,查看HBase版本,确定hbase安装成功,命令如下:
/usr/local/hbase/bin/hbase version
(该过程遇到的bug请查看文章:HBase 安装之后版本的验证的bug:(错误的替换、找不到或无法加载主类、SLF4J) )
二、配置 HBase(重点讨论单机模式和伪分布式模式)
✿ 单机模式和伪分布式模式:都需要配置 jdk、ssh、hadoop
■ 单机模式配置:
- 配置/usr/local/hbase/conf/hbase-env.sh:配置JAVA环境变量,并添加配置HBASE_MANAGES_ZK为true。(进入 hbase-env.sh 文件后,添加如下:)
vim /usr/local/hbase/conf/hbase-env.sh
(进入 hbase-env.sh 文件后,添加如下:)
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_301 export HBASE_MANAGES_ZK=true
(添加完成后保存退出即可)
- 配置/usr/local/hbase/conf/hbase-site.xml:设置属性hbase.rootdir,用于指定HBase数据的存储位置
- 因为如果不设置的话,hbase.rootdir默认为/tmp/hbase-${user.name},这意味着每次重启系统都会丢失数据。咱设置为HBase安装目录下的hbase-tmp文件夹即(/usr/local/hbase/hbase-tmp)
(打开并编辑hbase-site.xml)
vim /usr/local/hbase/conf/hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>file:///usr/local/hbase/hbase-tmp</value>
</property>
</configuration>
□ 测试一下:测试运行单机模式的HBase:
cd /usr/local/hbase bin/start-hbase.sh bin/hbase shell

问题:bin/hbase shell用于打开shell命令行模式 报错:WARN [main] util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable。
解决:警告级别的错误,不重要,解决:直接忽略
| ❀ 注意:如果在操作HBase的过程中发生错误,可以通过{HBASE_HOME}目录(/usr/local/hbase)下的logs子目录中的日志文件查看错误原因。 |
■ 伪分布式模式配置:
- 配置/usr/local/hbase/conf/hbase-env.sh:配置JAVA_HOME,HBASE_CLASSPATH,HBASE_MANAGES_ZK
- (HBASE_CLASSPATH设置为本机HBase安装目录下的conf目录(即/usr/local/hbase/conf))
(用命令vi打开hbase-env.xml)
-
vim /usr/local/hbase/conf/hbase-env.sh
- (进入 hbase-env.sh 文件后,添加如下:)
-
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_301 export HBASE_CLASSPATH=/usr/local/hbase/conf export HBASE_MANAGES_ZK=true
- (HBASE_CLASSPATH设置为本机HBase安装目录下的conf目录(即/usr/local/hbase/conf))
- 配置/usr/local/hbase/conf/hbase-site.xml:hbase.rootdir指定HBase的存储目录;hbase.cluster.distributed设置集群处于分布式模式;
- hbase.unsafe.stream.capability.enforce这个属性的设置,是为了避免出现启动错误。
- (用命令vi打开hbase-site.xml)
-
vim /usr/local/hbase/conf/hbase-site.xml
- (进入 hbase-site.xml 文件后,添加如下:)
-
<configuration> <property> <name>hbase.rootdir</name> <value>hdfs://localhost:9000/hbase</value> </property> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <property> <name>hbase.unsafe.stream.capability.enforce</name> <value>false</value> </property> </configuration>
□ 测试一下:测试运行伪分布式模式的HBase:
| ❀ 注意:如果在操作HBase的过程中发生错误,可以通过{HBASE_HOME}目录(/usr/local/hbase)下的logs子目录中的日志文件查看错误原因。 |
这里启动关闭Hadoop和HBase的顺序一定是:启动Hadoop—>启动HBase—>关闭HBase—>关闭Hadoop
① 启动Hadoop:
ssh localhost cd /usr/local/hadoop ./sbin/start-dfs.sh
② 启动HBase:
cd /usr/local/hbase bin/start-hbase.sh
✿ 启动成功,输入命令jps

然后再输入命令:bin/hbase shell
看到如下图所示即成功
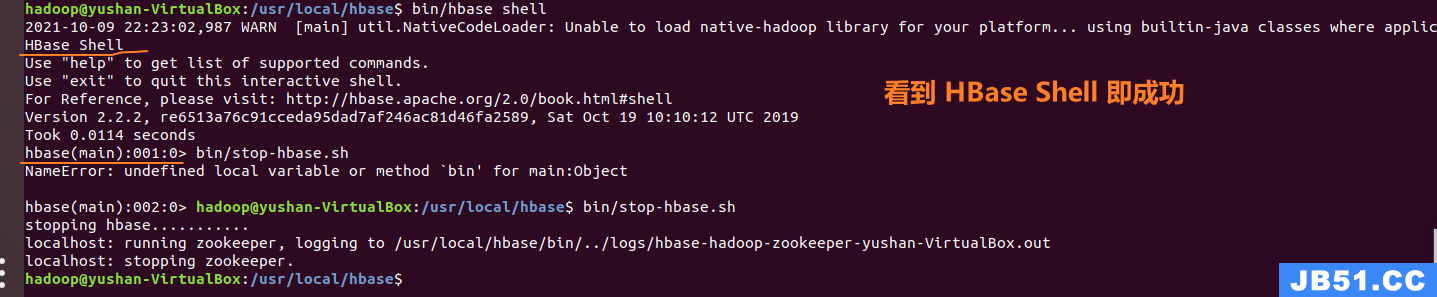
③ 关闭HBase:
bin/stop-hbase.sh
原文地址:https://blog.csdn.net/m0_66468899/article/details/132438900
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。