
flume简介
概念
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
工作方式
Flume-og采用了多Master的方式。为了保证配置数据的一致性,Flume引入了ZooKeeper,用于保存配置数据,ZooKeeper本身可保证配置数据的一致性和高可用,另外,在配置数据发生变化时,ZooKeeper可以通知Flume Master节点。Flume Master间使用gossip协议同步数据。
Flume-ng最明显的改动就是取消了集中管理配置的 Master 和 Zookeeper,变为一个纯粹的传输工具。Flume-ng另一个主要的不同点是读入数据和写出数据由不同的工作线程处理(称为 Runner)。 在 Flume-og 中,读入线程同样做写出工作(除了故障重试)。如果写出慢的话(不是完全失败),它将阻塞 Flume 接收数据的能力。这种异步的设计使读入线程可以顺畅的工作而无需关注下游的任何问题
优势
-
Flume可以将应用产生的数据存储到任何集中存储器中,比如HDFS,HBase
-
当收集数据的速度超过将写入数据的时候,也就是当收集信息遇到峰值时,这时候收集的信息非常大,甚至超过了系统的写入数据能力,这时候,Flume会在数据生产者和数据收容器间做出调整,保证其能够在两者之间提供平稳的数据.
-
提供上下文路由特征
-
Flume的管道是基于事务,保证了数据在传送和接收时的一致性.
-
Flume是可靠的,容错性高的,可升级的,易管理的,并且可定制的。
特征
-
Flume可以高效率的将多个网站服务器中收集的日志信息存入HDFS/HBase中
-
使用Flume,我们可以将从多个服务器中获取的数据迅速的移交给Hadoop中
-
除了日志信息,Flume同时也可以用来接入收集规模宏大的社交网络节点事件数据,比如facebook,twitter,电商网站如亚马逊,flipkart等
-
支持各种接入资源数据的类型以及接出数据类型
-
支持多路径流量,多管道接入流量,多管道接出流量,上下文路由等
-
可以被水平扩展
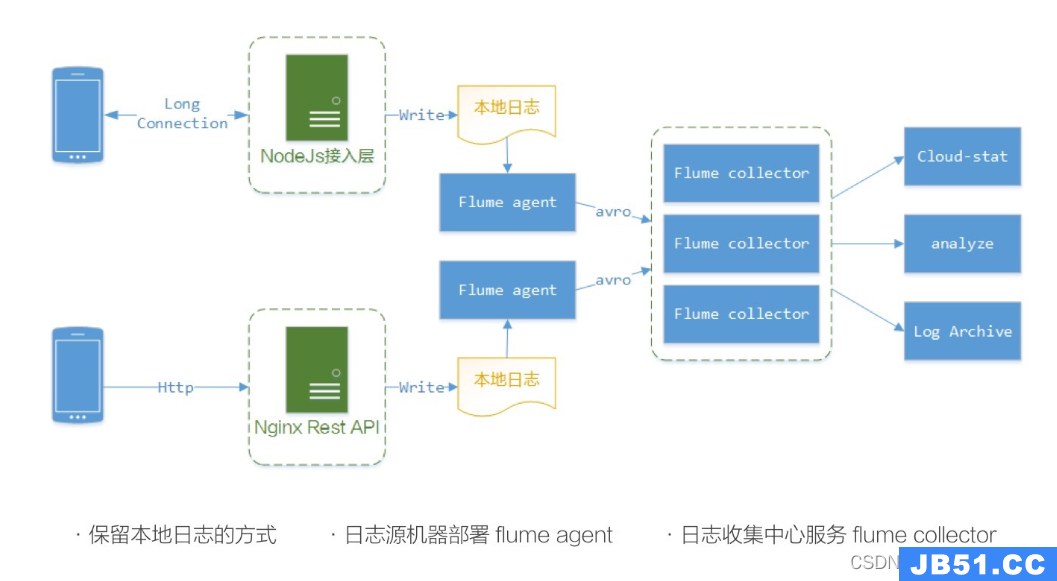
结构
Agent主要由:source,channel,sink三个组件组成.
Source:
从数据发生器接收数据,并将接收的数据以Flume的event格式传递给一个或者多个通道channel,Flume提供多种数据接收的方式,比如Avro,Thrift,twitter1%等
Channel:
channel是一种短暂的存储容器,它将从source处接收到的event格式的数据缓存起来,直到它们被sinks消费掉,它在source和sink间起着桥梁的作用,channel是一个完整的事务,这一点保证了数据在收发的时候的一致性. 并且它可以和任意数量的source和sink链接. 支持的类型有: JDBC channel,File System channel,Memory channel等.
sink:
sink将数据存储到集中存储器比如Hbase和HDFS,它从channels消费数据(events)并将其传递给目标地. 目标地可能是另一个sink,也可能HDFS,HBase.
解压flume安装包
[root@xsqone20 install]# tar -zxf ./apache-flume-1.9.0-bin.tar.gz -C ../soft/
改名为flume190
[root@xsqone20 soft]# mv apache-flume-1.9.0-bin/ flume190
将临时配置文件拷贝为配置文件
[root@xsqone20 conf]# cp flume-env.sh.template flume-env.sh
配置flume-env.sh文件
[root@xsqone20 conf]# vim flume-env.sh
export JAVA_HOME=/opt/soft/jdk180
export JAVA_OPTS="-Xms2000m -Xmx2000m -Dcom.sun.management.jmxremote"
新建netcat-logger.conf文件
[root@xsqone20 conf]# vim ./netcat-logger.conf
a1.sources=r1
a1.sinks=k1
a1.channels=c1
a1.sources.r1.type=netcat
a1.sources.r1.bind=192.168.136.20
a1.sources.r1.port=8888
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
a1.sinks.k1.type=logger
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
安装nc
[root@xsqone20 conf]# yum install -y nc
[root@xsqone20 conf]# nc -lk 8888

安装telnet协议
[root@xsqone20 ~]# yum list telnet*
[root@xsqone20 ~]# yum install telnet-server
[root@xsqone20 ~]# yum install telnet.*
[root@xsqone20 ~]# telnet localhost 8888


flume telnet
输入aa测试
[root@xsqone20 flume190]# ./bin/flume-ng agent --name a1 --conf ./conf/ --conf-file ./conf/netcat-logger.conf -Dflume.root.logger=INFO,console
[root@xsqone20 ~]# telnet 192.168.136.20 8888
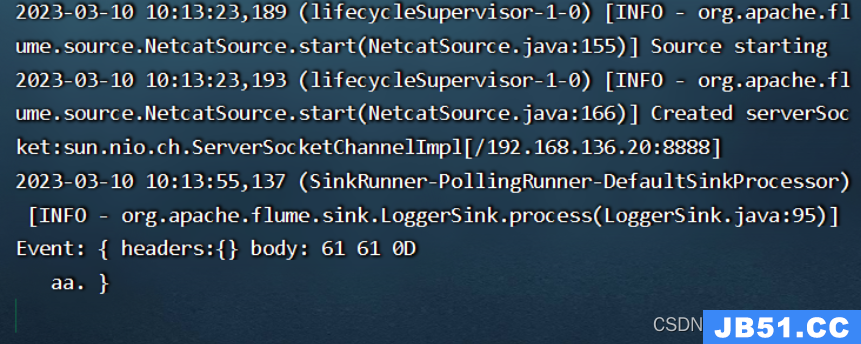
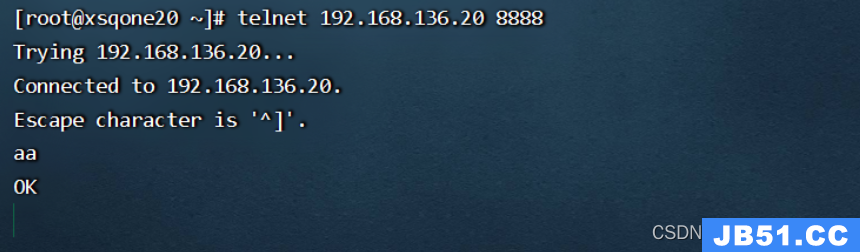
flumedemo.log中追加数据
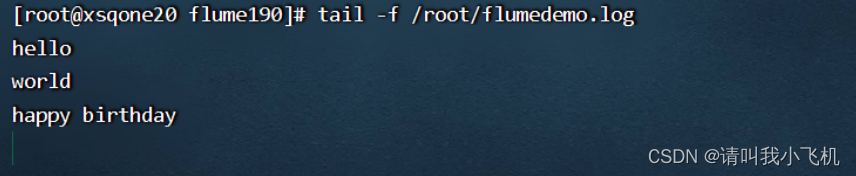
[root@xsqone20 ~]# echo 'hello'>./flumedemo.log
[root@xsqone20 ~]# echo 'world' >> ./flumedemo.log
[root@xsqone20 ~]# echo 'happy birthday' >> ./flumedemo.log
tail显示内容变动
[root@xsqone20 flume190]# tail -f /root/flumedemo.log
将指定文件中的内容输出到控制台1
编辑conf文件
[root@xsqone20 flume190]# vim ./conf/file-flume-logger.conf
#将指定文件中的内容输出到控制台
a2.sources=r1
a2.sinks=k1
a2.channels=c1
a2.sources.r1.type=exec
a2.sources.r1.command=tail -f /root/flumedemo.log
a2.channels.c1.type=memory
a2.channels.c1.capacity=1000
a2.channels.c1.transactionCapacity=100
a2.sinks.k1.type=logger
a2.sources.r1.channels=c1
a2.sinks.k1.channel=c1
启动flume
[root@xsqone20 flume190]# ./bin/flume-ng agent --name a2 --conf ./conf/ --conf-file ./conf/file-flume-logger.conf -Dflume.root.logger=INFO,console
插入数据进入flumedemo.log文件
[root@xsqone20 ~]# echo 'kb21 very nice' >> ./flumedemo.log

将指定文件中的内容输出到控制台2
导入数据csv文件
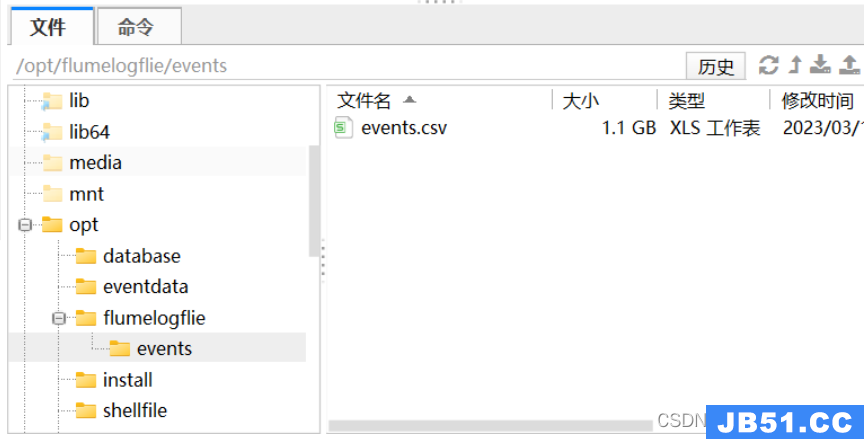
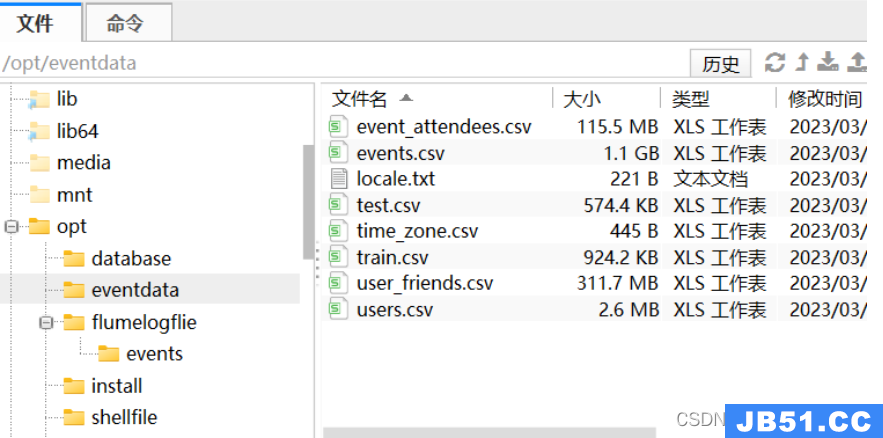
编辑conf文件
[root@xsqone20 flume190]# vim ./conf/events-flume-logger.conf
events.sources=eventsSource
events.channels=eventsChannel
events.sinks=eventsSink
events.sources.eventsSource.type=spooldir
events.sources.eventsSource.spoolDir=/opt/flumelogfile/events
events.sources.eventsSource.deserializer=LINE
events.sources.eventsSource.deserializer.maxLineLength=32000
events.sources.eventsSource.includePattern=events_[0-9]{4}-[0-9]{2}-[0-9]{2}.csv
events.channels.eventsChannel.type=file
events.channels.eventsChannel.checkpointDir=/opt/flumelogfile/checkpoint/events
events.channels.eventsChannel.dataDir=/opt/flumelogfile/data/events
events.sinks.eventsSink.type=logger
events.sources.eventsSource.channels=eventsChannel
events.sinks.eventsSink.channel=eventsChannel
修改文件名符合规则
[root@xsqone20 flume190] mv /opt/flumelogfile/events/events.csv /opt/flumelogfile/events/events_2023-03-08.csv
启动flume
[root@xsqone20 flume190] ./bin/flume-ng agent --name events --conf ./conf/ --conf-file ./conf/events-flume-logger.conf -Dflume.root.logger=INFO,console
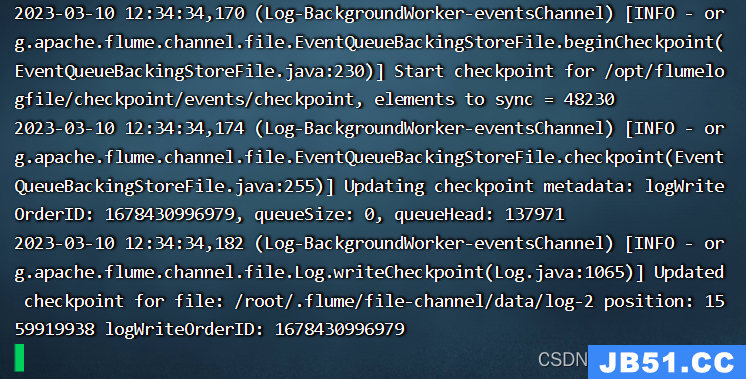
修改文件名符合规则
[root@xsqone20 flume190] cp /opt/flumelogfile/events/events_2023-03-08.csv COMPLETEd /opt/flumelogfile/events/events_2023-01-01.csv
再次启动flume
[root@xsqone20 flume190] ./bin/flume-ng agent --name events --conf ./conf/ --conf-file ./conf/events-flume-logger.conf -Dflume.root.logger=INFO,console
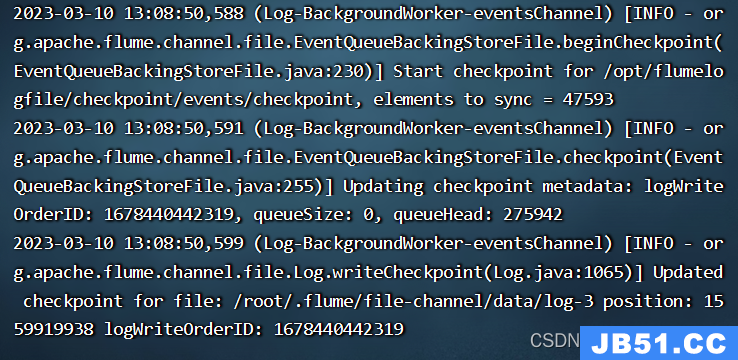
原文地址:https://blog.csdn.net/wohewo79/article/details/129440325
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。