
目录
2、将下载好的datax-web-2.1.2.tar.gz放到服务器并解压
第一章:datax概述
DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。

Reader:Reader为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
Writer: Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
第二章:核心模块介绍
- DataX完成单个数据同步的作业,我们称之为Job,DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。DataX Job模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能。
- DataXJob启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作。
- 切分多个Task之后,DataX Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)。每一个TaskGroup负责以一定的并发运行完毕分配好的所有Task,默认单个任务组的并发数量为5。
- 每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader—>Channel—>Writer的线程来完成任务同步工作。
- DataX作业运行起来之后, Job监控并等待多个TaskGroup模块任务完成,等待所有TaskGroup任务完成后Job成功退出。否则,异常退出,进程退出值非0 DataX调度流程:
- 举例来说,用户提交了一个DataX作业,并且配置了20个并发,目的是将一个100张分表的mysql数据同步到odps里面。 DataX的调度决策思路是:DataXJob根据分库分表切分成了100个Task。 根据20个并发,DataX计算共需要分配4个TaskGroup。 4个TaskGroup平分切分好的100个Task,每一个TaskGroup负责以5个并发共计运行25个Task。
第三章:安装datax
1、datax下载地址
http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
源码地址: https://github.com/alibaba/DataX
2、将datax.tar.gz放到服务器,并解压
tar -zxvf datax.tar.gz #解压到当前目录
tar -zxvf datax.tar.gz -C /usr/local/ #解压到指导目录-C 后面的参数为想要解压到的目录
3、运行自检脚本
cd bin
./datax.py ../job/job.json
4、报错处理
[main] WARN ConfigParser - 插件[streamreader,streamwriter]加载失败,1s后重试... Exception:Code:[Common-00],Describe:[您提供的配置文件存在错误信息,请检查您的作业配置 .]
如果需要这个错误,请进入plugin/reader 和 plugin/writer,使用ls -al 命令查看目录,删除里面所有以点开头的文件
rm -rf ./._*
再次执行步骤3)中的命令
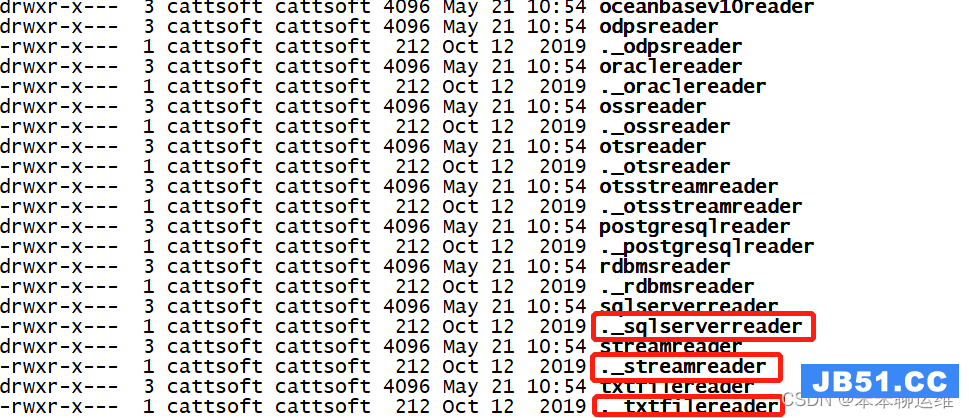
5、出现下图结果,则表示datax安装成功

第四章 datax-web的安装
1、下载datax-web
下载官方提供的版本tar版本包
https://pan.baidu.com/s/13yoqhGpD00I82K4lOYtQhg
提取码:cpsk
2、将下载好的datax-web-2.1.2.tar.gz放到服务器并解压
tar -zxvf datax-web-2.1.2.tar.gz
3、进入解压后的目录,进行安装
进入解压后的目录,找到bin目录下面的install.sh文件,如果选择交互式的安装,则直接执行
./bin/install.sh
在交互过程中,如果服务器上存在MySQL则会出现填写MySQL信息的交互语句;如果服务器上没有安装MySQL则不显示。
在交互模式下,对各个模块的package压缩包的解压以及configure配置脚本的调用,都会请求用户确认,可根据提示查看是否安装成功,如果没有安装成功,可以重复尝试; 如果不想使用交互模式,跳过确认过程,则执行以下命令安装
./bin/install.sh --force4、修改控制器datax-admin配置文件
首先修改./datax-web-2.1.2/modules/datax-admin/conf/application.yml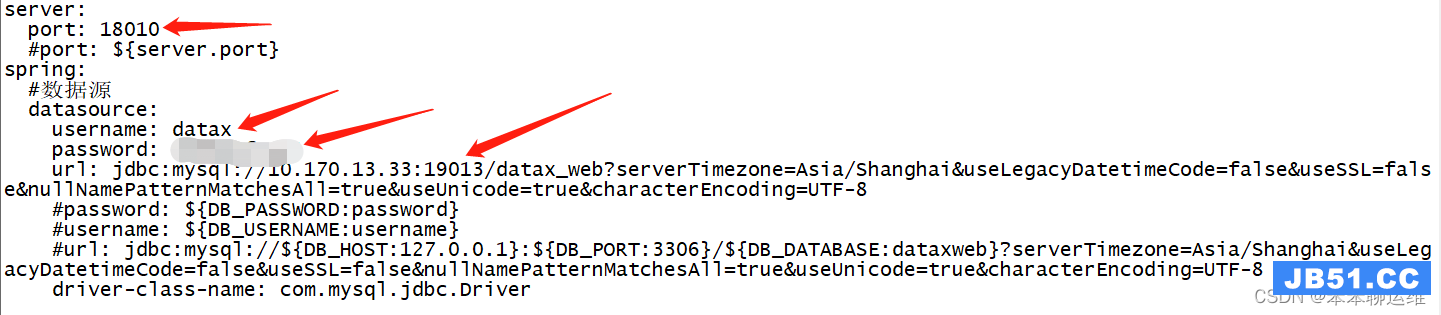
cd ./datax-web-master/datax-admin/src/main/resources
vi application.yml
server:
port: 18010
#port: ${server.port}
spring:
#数据源
datasource:
username: datax
password: 111111
url: jdbc:mysql://127.0.0.1:19013/datax_web?serverTimezone=Asia/Shanghai&useLegacyDatetimeCode=false&useSSL=false&nullNamePatternMatchesAll=true&useUnicode=true&characterEncoding=UTF-8
再修改./datax-web-2.1.2/modules/datax-admin/bin/env.properties
修改SERVER_PORT=端口,和application.yml中的保持一致即可5、修改执行器配置文件
首先修改./datax-web-2.1.2/modules/datax-executor/conf/application.yml
执行器配置文件原文:
cd ./datax-web-master/datax-executor/src/main/resources
vi application.yml
# web port
server:
#port: ${server.port}
port: 18011
# log config
logging:
config: classpath:logback.xml
path: ${data.path}/applogs/executor/jobhandler
#path: ./data/applogs/executor/jobhandler
datax:
job:
admin:
### datax admin address list,such as "http://address" or "http://address01,http://address02"
addresses: http://127.0.0.1:18010
#addresses: http://127.0.0.1:${datax.admin.port}
executor:
appname: datax-executor
ip:
#port: 9999
port: ${executor.port:9999}
### job log path
logpath: ./data/applogs/executor/jobhandler
#logpath: ${data.path}/applogs/executor/jobhandler
### job log retention days
logretentiondays: 30
### job,access token
accessToken:
executor:
jsonpath: /data/datax/script
#jsonpath: ${json.path}
pypath: /data/datax/bin/datax.py
#pypath: ${python.path}
再修改./datax-web-2.1.2/modules/datax-executor/bin/env.properties
## 保持和datax-admin端口一致
DATAX_ADMIN_PORT=端口号
## PYTHON脚本执行位置
PYTHON_PATH=/data/datax/bin/datax.py6、导入datax-web.sql进MySQL
在datax-web.sql文件所在目录执行
mysql -u用户名 -p密码 数据库<./datax_web.sql
如果安装数据库后还没有创建数据库和授权可以使用下面的方法
MySQL8.0及以上版本创建数据库并分配用户授权
1)create database `datax-web` character set utf8mb4;
2)CREATE USER 'datax'@'%' IDENTIFIED BY '111111';
3)flush privileges;
4)grant all privileges on *.* to datax@'%' with grant option;
5)ALTER USER 'datax'@'%' IDENTIFIED WITH mysql_native_password BY '111111';
6)flush privileges;7、启动datax-web
cd ./datax-web-2.1.2/bin
./start-all.sh #同时启动控制器和执行器,如果想单独启动,则使用命令 ./start.sh -m datax-admin 或 ./start.sh -m datax-executor

启动后使用jps命令查看,是否存在DataXAdminApplication和DataXExecutorApplication进程,存在则表示启动成功
如果存在启动失败的情况,可以进入./datax-web-2.1.2/modules/对应的目录中查看log,有详细的报错信息
8、登录界面
部署完成后,在浏览器中输入 http://ip:port/index.html 就可以访问对应的主界面
(ip为datax-admin部署所在服务器ip,port为为datax-admin 指定的运行端口)
输入用户名 admin 密码 123456 就可以直接访问系统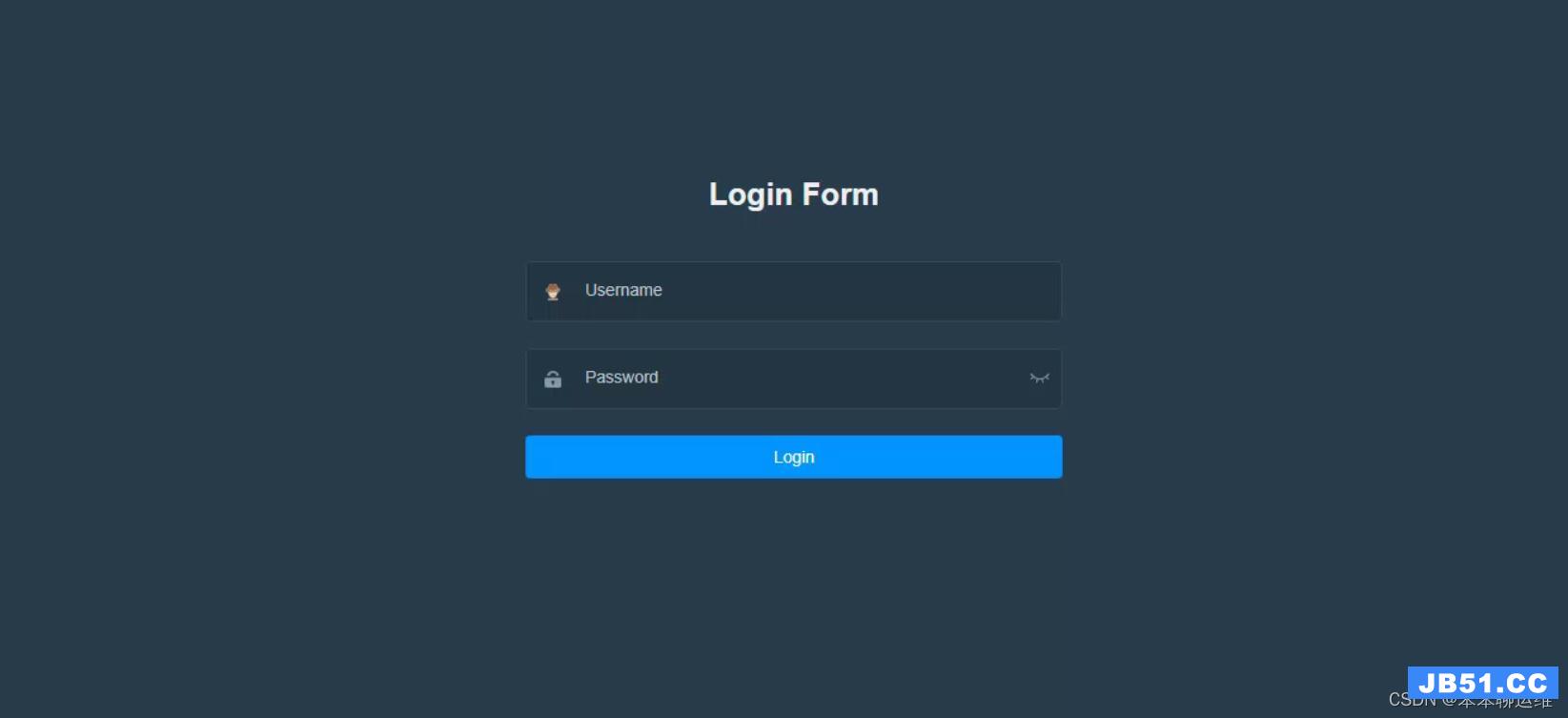
原文地址:https://blog.csdn.net/m0_71142057
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。