
【编者按】本文是基于最近对Golang分布式ID的相关讨论,希望本文内容可以对相关技术感兴趣的开发者提供一点经验和帮助。
作者 | 陈冬,腾讯后台开发工程师
出品 | 腾讯云开发者

本地ID生成器
uuid
uuid有两种包:github.com/google/uuid ,仅支持V1和V4版本。github.com/gofrs/uuid ,支持全部五个版本。下面简单说下五种版本的区别:
Version 1,基于mac地址、时间戳。Version 2,based on timestamp,MAC address and POSIX UID/GID (DCE 1.1)Version 3,Hash获取入参并对结果进行MD5。Version 4,纯随机数。Version 5,based on SHA-1 hashing of a named value。
特点
5个版本可供选择。定长36字节,偏长。无序。package mianimport (
"github.com/gofrs/uuid"
"fmt"
)
func main {
// Version 1:时间+Mac地址
id, err := uuid.NewV1
if err != nil {
fmt.Printf("uuid NewUUID err:%+v", err)
}
// id: f0629b9a-0cee-11ed-8d44-784f435f60a4 length: 36
fmt.Println("id:", id.String, "length:", len(id.String))
// Version 4:是纯随机数,error会在内部报panic
id, err = uuid.NewV4
if err != nil {
fmt.Printf("uuid NewUUID err:%+v", err)
}
// id: 3b4d1268-9150-447c-a0b7-bbf8c271f6a7 length: 36
fmt.Println("id:", id.String, "length:", len(id.String))
}
shortuuid
初始值基于uuid Version4;第二步根据alphabet变量长度(定长57)计算id长度(定长22);第三步依次用DivMod(欧几里得除法和模)返回值与alphabet做映射,合并生成id。特点
基于uuid,但比uuid的长度短,定长22字节。package mian
import (
"github.com/lithammer/shortuuid/v4"
"fmt"
)
func main {
id := shortuuid.New
// id: iDeUtXY5JymyMSGXqsqLYX length: 22
fmt.Println("id:", id, "length:", len(id))
// V22s2vag9bQEZCWcyv5SzL 固定不变
id = shortuuid.NewWithNamespace("http://127.0.0.1.com")
// id: K7pnGHAp7WLKUSducPeCXq length: 22
fmt.Println("id:", id, "length:", len(id))
// NewWithAlphabet函数可以用于自定义的基础字符串,字符串要求不重复、定长57
str := "12345#$%^&*67890qwerty/;'~!@uiopasdfghjklzxcvbnm,._+·><"
id = shortuuid.NewWithAlphabet(str)
// id: q7!o_+y('@;_&dyhk_in9/ length: 22
fmt.Println("id:", id, "length:", len(id))
}
xid
xid是由时间戳、进程id、Mac地址、随机数组成。有序性来源于对随机数部分的原子+1。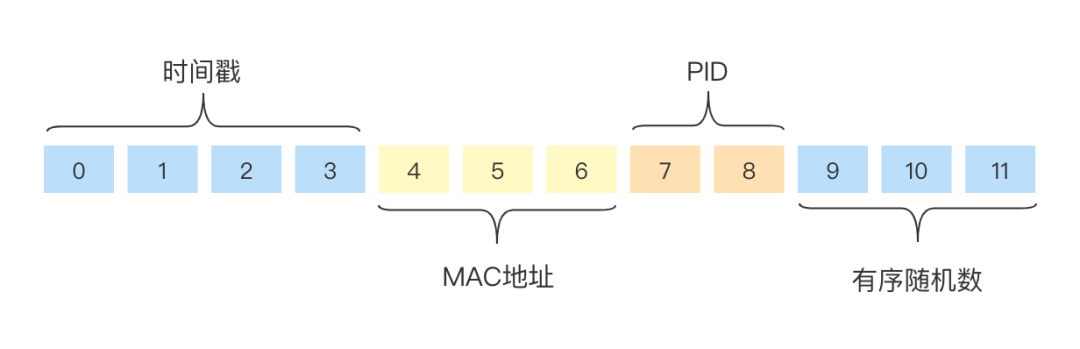
特点
长度短。有序。不重复。时间戳这个随机数原子+1操作,避免了时钟回拨的问题。下面的代码根据需求进行了魔改。package mian
import (
"github.com/rs/xid"
"fmt"
)
func main {
// hostname+pid+atomic.AddUint32
id := xid.New
containerName := "test"
// 由于xid默认使用可重复ip地址填充4 5 6位。
// 实际场景中,服务都是部署在docker中,这里把ip地址位替换成了容器名
// 这里只取了容器名MD5的前3位,验证会重复,放弃使用
containerNameID := make([]byte, 3)
hw := md5.New
hw.Write(byte(containerName))
copy(containerNameID, hw.Sum(nil))
id[4] = containerNameID[0]
id[5] = containerNameID[1]
id[6] = containerNameID[2]
// id: cbgjhf89htlrr1955d5g length: 12
fmt.Println("id:", id, "length:", len(id))}
ksuid
由随机数和时间戳组成。时间戳占前4字节,后面均为随机数:
package mia
import (
"github.com/segmentio/ksuid"
"fmt"
)
func main {
id := ksuid.New
// id: 2CWvPg766SUvezbiiV9nzrTZsgf length: 20
fmt.Println("id:", id, "length:", len(id))
id1 := ksuid.New
id2 := ksuid.New
// id1:2CTqTLRxCh48y7oUQzQHrgONT2k id2:2CTqTHf07C09CXyRMHdGKXnY5HP
fmt.Println(id1, id2)
// 支持ID对比,这个功能比较鸡肋了,目前没想到有用的地方
compareResult := ksuid.Compare(id1, id2)
fmt.Println(compareResult) // 1
// 判断顺序性
isSorted := ksuid.IsSorted([]ksuid.KSUID{id2, id1})
fmt.Println(isSorted) // true 降序
}
ulid
随机数和时间戳组成
package mianimport (
"github.com/oklog/ulid"
"fmt"
)
func main {
t := time.Now.UTC
entropy := rand.New(rand.NewSource(t.UnixNano))
id := ulid.MustNew(ulid.Timestamp(t), entropy)
// id: 01G902ZSM96WV5D5DC5WFHF8WY length: 26
fmt.Println("id:", id.String, "length:", len(id.String))
}
snowflake
大名鼎鼎的雪花算法,这里不做过多介绍了。相对于UUID来说,雪花算法不会暴露MAC地址更安全、生成的ID也不会过于冗余。雪花的一部分ID序列是基于时间戳的,那么时钟回拨的问题就来了。上面提到的xid,一定程度上避时钟回拨的影响。那么什么是时钟回拨,后面会提到。

数据库自增ID
这里常规是指数据库主键自增索引。特点如下:
架构简单容易实现;ID有序递增,IO写入连续性好;INT和BIGINT类型占用空间较小;由于有序递增,易暴露业务量;受到数据库性能限制,对高并发场景不友好。bigint最大是2^64-1,但是数据库单表肯定放不了这么多,那么就涉及到分表。如果业务量真的太大了,主键的自增id涨到头了,会发生什么?报错:主键冲突。

Redis生成ID
通过redis的原子操作INCR和INCRBY获得id。相比数据库自增ID,redis性能更好、更加灵活。不过架构强依赖redis,redis在整个架构中会产生单点问题。在流量较大的场景下,网络耗时也可能成为瓶颈。

ZooKeeper唯一ID
ZooKeeper是使用了Znode结构中的Zxid实现顺序增ID。Zookeeper类似一个文件系统,每个节点都有唯一路径名(Znode),Zxid是个全局事务计数器,每个节点发生变化都会记录响应的版本(Zxid),这个版本号是全局唯一且顺序递增的。这种架构还是出现了ZooKeeper的单点问题。

号段模式
Leaf-segment
把数据库自增主键换成了计数法。每个业务分配一个biz_tag、并记录各业务最大id(max_id)、号段跨度(step)等数据。这样每次取号只需要更新biz_tag对应的max_id,就可以拿到step个id。

优点
除了拥有自增ID的优点之外,在性能上比自增ID更好扩展灵活。使用灵活、可配置性强。缓存机制,突发状况下短时间内能保证服务正常运转。缺点
id是有序自增,容易暴露信息,不可用于订单。在leaf的缓存ID用完再去获取新号段的间隙,性能会有波动。强依赖DB。增强版Leaf-segment
增强版是对上面描述的缺点2进行的改进——双cache。在leaf的ID消耗到一定百分比时,常驻的后台进程会预先去号段服务获取新的号段并缓存。具体消耗百分比、及号段step根据业务消耗速度来定。

Tinyid
和增强版Leaf-segment类似,也是号段模式,提前加载号段。
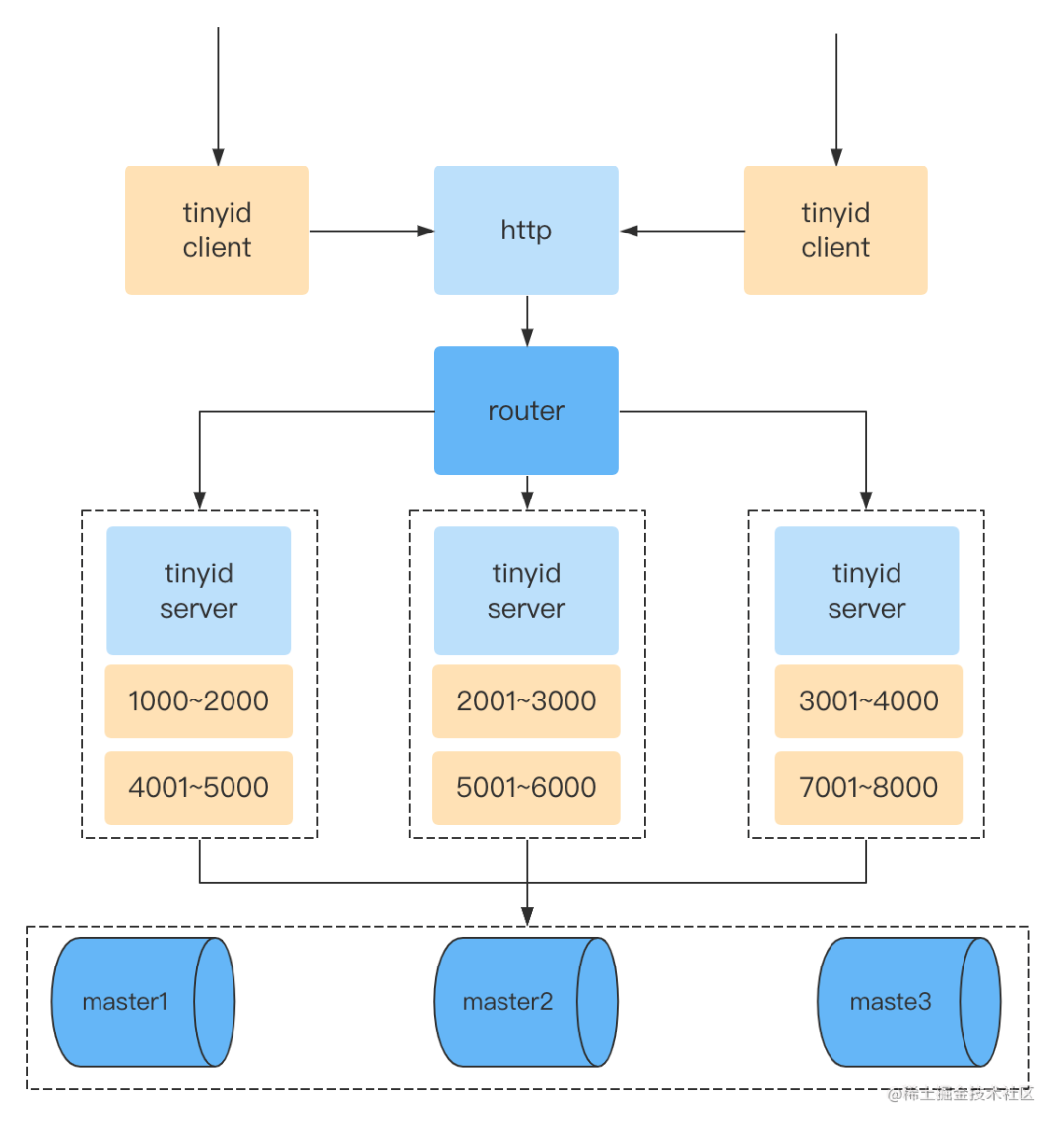
Leaf-snowflake
时钟回拨
服务器上的时间突然倒退回之前的时间。可能是人为的调整时间;也可能是服务器之间的时间校对。
实现方案
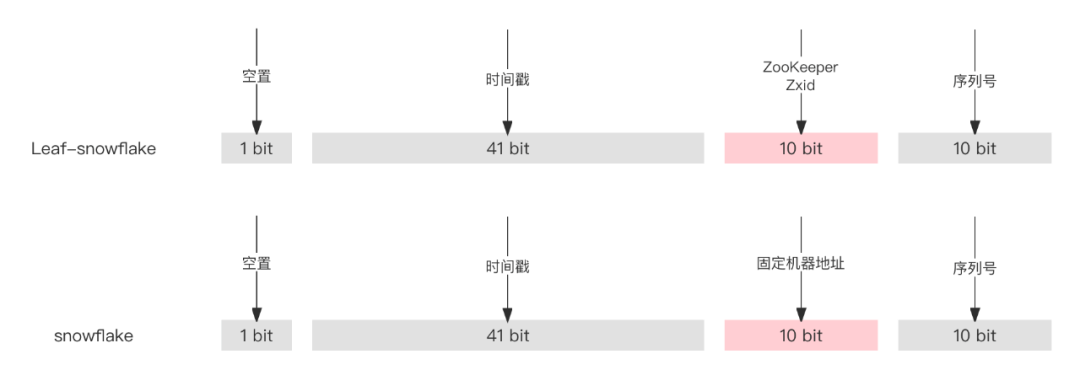
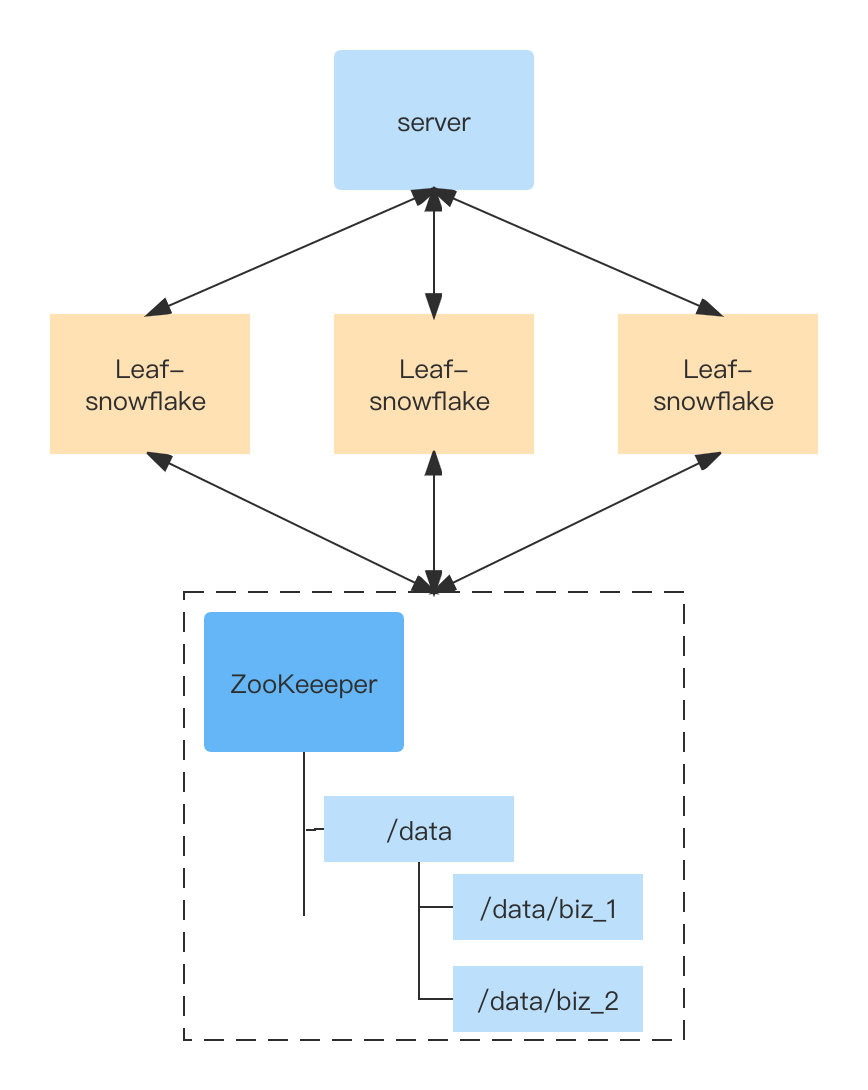
用Zookeeper顺序增、全局唯一的节点版本号,替换了原有的机器地址。解决了时钟回拨的问题。前面介绍ZooKeeper的缺点,强依赖ZooKeeper、大流量下的网络瓶颈。下图的方案在Leaf-snowflake 中通过缓存一个ZooKeeper文件夹,提高可用性。运行时运行时,时差小于5ms会等待时差两倍时间,如果时差大于5ms报警并停止启动。
原文地址:https://www.toutiao.com/article/7139729492783825449/
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。