

涉及的内容情况参看下面的目录:
文章目录
操作系统的发展史
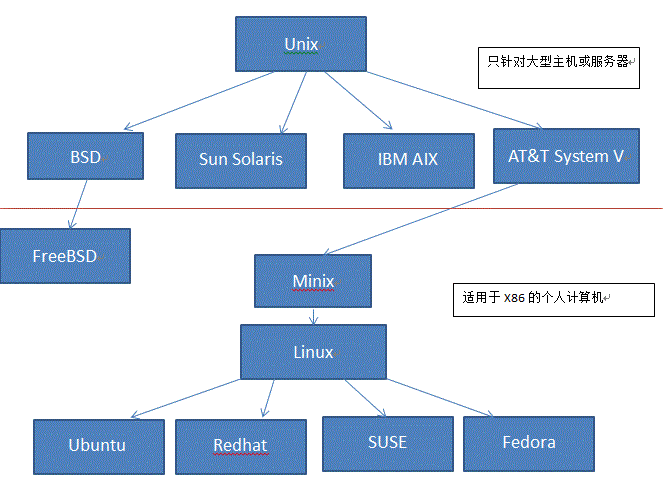
Unix
- 1965年之前,电脑只有军事或者学院的研究机构碰的起,当时大型主机至多能提供30台终端(30个键盘、显示器)的连接。
- 1965年左后由贝尔实验室、麻省理工学院 以及 通用电气共同发起了Multics项目,想让大型主机支持300台终端
- 1969年前后这个项目进度缓慢,资金短缺,贝尔实验室退出了研究
- 1969年从这个项目中退出的Ken Thompson当时在实验室无聊时,为了让一台空闲的电脑上能够运行“星际旅行”游行,在8月份左右趁着其妻子探亲的时间,用了1个月的时间编写出了 Unix操作系统的原型
- 1970年,美国贝尔实验室的 Ken Thompson,以 BCPL语言 为基础,设计出很简单且很接近硬件的 B语言(取BCPL的首字母),并且他用B语言写了第一个UNIX操作系统。
因为B语言的跨平台性较差,为了能够在其他的电脑上也能够运行这个非常棒的Unix操作系统,Dennis Ritchie和Ken Thompson 从B语言的基础上准备研究一个更好的语言 - 1972年,美国贝尔实验室的 Dennis Ritchie在B语言的基础上最终设计出了一种新的语言,他取了BCPL的第二个字母作为这种语言的名字,这就是C语言
- 1973年初,C语言的主体完成。Thompson和Ritchie迫不及待地开始用它完全重写了现在大名鼎鼎的Unix操作系统
Minix
因为AT&T(通用电气)的政策改变,在Version 7 Unix推出之后,发布新的使用条款,将UNIX源代码私有化,在大学中不再能使用UNIX源代码。Andrew S. Tanenbaum(塔能鲍姆)教授为了能在课堂上教授学生操作系统运作的实务细节,决定在不使用任何AT&T的源代码前提下,自行开发与UNIX兼容的操作系统,以避免版权上的争议。他以小型UNIX(mini-UNIX)之意,将它称为MINIX。
Linux
因为Minix只是教学使用,因此功能并不强,因此Torvalds利用GNU的bash当做开发环境,gcc当做编译工具,编写了Linux内核-v0.02,但是一开始Linux并不能兼容Unix,即Unix上跑的应用程序不能在Linux上跑,即应用程序与内核之间的接口不一致,因为Unix是遵循POSIX规范的,因此Torvalds修改了Linux,并遵循POSIX(Portable Operating System Interface,他规范了应用程序与内核的接口规范); 一开始Linux只适用于386,后来经过全世界的网友的帮助,最终能够兼容多种硬件
操作系统的发展
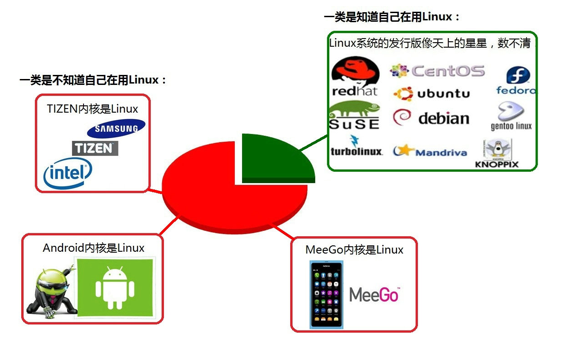
Minix没有火起来的原因
Minix的创始人说,MINIX 3没有统治世界是源于他在1992年犯下的一个错误,当时他认为BSD必然会一统天下,因为它是一个更稳定和更成熟的系统,其它操作系统难以与之竞争。因此他的MINIX的重心集中在教育上。四名BSD开发者已经成立了一家公司销售BSD系统,他们甚至还有一个有趣的电话号码1-800-ITS-UNIX。然而他们正因为这个电话号码而惹火上身。美国电话电报公司因电话号码而提起诉讼。官司打了三年才解决。在此期间,BSD陷于停滞,而Linux则借此一飞冲天。他的错误在于没有意识官司竟然持续了如此长的时间,以及BSD会因此受到削弱。如果美国电话电报公司没有起诉,Linux永远不会流行起来,BSD将统治世界。
Linux介绍
Linux内核&发行版
Linux内核版本
内核(kernel)是系统的心脏,是运行程序和管理像磁盘和打印机等硬件设备的核心程序,它提供了一个在裸设备与应用程序间的抽象层。
Linux内核版本又分为稳定版和开发版,两种版本是相互关联,相互循环:
- 稳定版:具有工业级强度,可以广泛地应用和部署。新的稳定版相对于较旧的只是修正一些bug或加入一些新的驱动程序。
- 开发版:由于要试验各种解决方案,所以变化很快。
内核源码网址:http://www.kernel.org 所有来自全世界的对Linux源码的修改最终都会汇总到这个网站,由Linus领导的开源社区对其进行甄别和修改最终决定是否进入到Linux主线内核源码中。
Linux发行版本
Linux发行版 (也被叫做 GNU/Linux 发行版) 通常包含了包括桌面环境、办公套件、媒体播放器、数据库等应用软件。
目前市面上较知名的发行版有:Ubuntu、RedHat、CentOS、Debian、Fedora、SuSE、OpenSUSE、Arch Linux、SolusOS 等。

类Unix系统目录结构
Unix没有盘符这个概念,只有一个根目录/,所有文件都在它下面
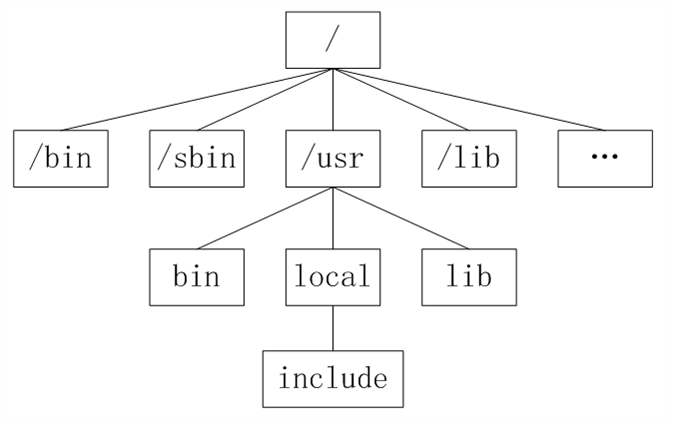
Linux目录
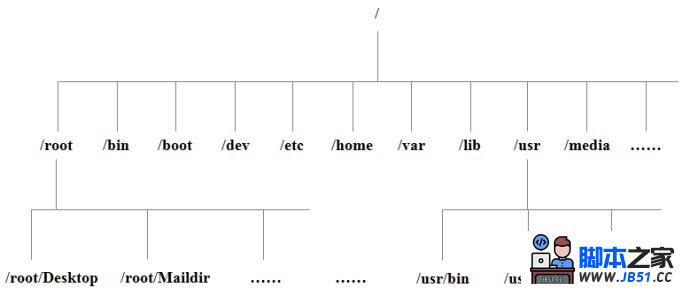
- /:根目录,一般根目录下只存放目录,在Linux下有且只有一个根目录。所有的东西都是从这里开始。当你在终端里输入“/home”,你其实是在告诉电脑,先从/(根目录)开始,再进入到home目录。
- /bin: /usr/bin: 可执行二进制文件的目录,如常用的命令ls、tar、mv、cat等。
- /boot:放置linux系统启动时用到的一些文件,如Linux的内核文件:/boot/vmlinuz,系统引导管理器:/boot/grub。
- /dev:存放linux系统下的设备文件,访问该目录下某个文件,相当于访问某个设备,常用的是挂载光驱 mount /dev/cdrom /mnt。
- /etc:系统配置文件存放的目录,不建议在此目录下存放可执行文件,重要的配置文件有 /etc/inittab、/etc/fstab、/etc/init.d、/etc/X11、/etc/sysconfig、/etc/xinetd.d。
- /home:系统默认的用户家目录,新增用户账号时,用户的家目录都存放在此目录下,表示当前用户的家目录,edu 表示用户 edu 的家目录。
- /lib: /usr/lib: /usr/local/lib:系统使用的函数库的目录,程序在执行过程中,需要调用一些额外的参数时需要函数库的协助。
- /lost+fount:系统异常产生错误时,会将一些遗失的片段放置于此目录下。
- /mnt: /media:光盘默认挂载点,通常光盘挂载于 /mnt/cdrom 下,也不一定,可以选择任意位置进行挂载。
- /opt:给主机额外安装软件所摆放的目录。
- /proc:此目录的数据都在内存中,如系统核心,外部设备,网络状态,由于数据都存放于内存中,所以不占用磁盘空间,比较重要的目录有 /proc/cpuinfo、/proc/interrupts、/proc/dma、/proc/ioports、/proc/net/* 等。
- /root:系统管理员root的家目录。
- /sbin: /usr/sbin: /usr/local/sbin:放置系统管理员使用的可执行命令,如fdisk、shutdown、mount 等。与 /bin 不同的是,这几个目录是给系统管理员 root使用的命令,一般用户只能"查看"而不能设置和使用。
- /tmp:一般用户或正在执行的程序临时存放文件的目录,任何人都可以访问,重要数据不可放置在此目录下。
- /srv:服务启动之后需要访问的数据目录,如 www 服务需要访问的网页数据存放在 /srv/www 内。
- /usr:应用程序存放目录,/usr/bin 存放应用程序,/usr/share 存放共享数据,/usr/lib 存放不能直接运行的,却是许多程序运行所必需的一些函数库文件。/usr/local: 存放软件升级包。/usr/share/doc: 系统说明文件存放目录。/usr/share/man: 程序说明文件存放目录。
- /var:放置系统执行过程中经常变化的文件,如随时更改的日志文件 /var/log,/var/log/message:所有的登录文件存放目录,/var/spool/mail:邮件存放的目录,/var/run:程序或服务启动后,其PID存放在该目录下。
用户目录
位于/home/user,称之为用户工作目录或家目录,表示方式:
/home/user
~
从/目录开始描述的路径为绝对路径,如:
cd /home
ls /usr
从当前位置开始描述的路径为相对路径,如:
cd ../../
ls abc/def
每个目录下都有**.和…**
. 表示当前目录
… 表示上一级目录,即父目录
根目录下的.和…都表示当前目录
| 文件的颜色 | 含义 |
|---|---|
| 蓝色 | 目录 |
| 绿色 | 可执行文件 |
| 红色 | 压缩文件 |
| 浅蓝色 | 链接文件 |
| 灰色 | 其他文件 |
命令行基本操作
命令使用方法
Linux命令格式:
command [-options] [parameter1] …
command: 命令名; [-options]:选项,可用来对命令进行控制,也可以省略,[]代表可选 parameter1 …:传给命令的参数:可以是零个一个或多个
查看帮助文档
help
一般是linux命令自带的帮助信息
如:ls --help
man(manual)
man是linux提供的一个手册,包含了绝大部分的命令、函数使用说明
该手册分成很多章节(section),使用man时可以指定不同的章节来浏览。
例:man ls ; man 2 printf
man中各个section意义如下:
- Standard commands(标准命令)
- System calls(系统调用,如open,write)
- Library functions(库函数,如printf,fopen)
- Special devices(设备文件的说明,/dev下各种设备)
- File formats(文件格式,如passwd)
- Games and toys(游戏和娱乐)
- Miscellaneous(杂项、惯例与协定等,例如Linux档案系统、网络协定、ASCII 码;environ全局变量)
- Administrative Commands(管理员命令,如ifconfig)
man是按照手册的章节号的顺序进行搜索的。
man设置了如下的功能键:
| 功能键 | 功能 |
|---|---|
| 空格键 | 显示手册页的下一屏 |
| Enter键 | 一次滚动手册页的一行 |
| b | 回滚一屏 |
| f | 前滚一屏 |
| q | 退出man命令 |
| h | 列出所有功能键 |
| /word | 搜索word字符串 |

注意:实际上,我们不用指定第几个章节也用查看,如,man ls
tab键自动补全
在敲出命令的前几个字母的同时,按下tab键,系统会自动帮我们补全命令
history游览历史
当系统执行过一些命令后,可按上下键翻看以前的命令,history将执行过的命令列举出来
history保留了最近执行的命令记录,默认可以保留1000。
历史清单从0开始编号到最大值。
常见用法:
history N 显示最近N条命令
history -c 清除所有的历史记录
history -w xxx.txt 保存历史记录到文本xxx.txt
命令行中的ctrl组合键
-
Ctrl+c 结束正在运行的程序
-
Ctrl+d 结束输入或退出shell
-
Ctrl+s 暂停屏幕输出【锁住终端】
-
Ctrl+q 恢复屏幕输出【解锁终端】
-
Ctrl+l 清屏,【是字母L的小写】等同于Clear
-
当前光标到行首:ctrl+a
-
当前光标到行尾:ctrl+e
-
删除当前光标到行首:ctrl+u
-
删除当前光标到行尾:ctrl+k
-
Ctrl+y 在光标处粘贴剪切的内容
-
Ctrl+r 查找历史命令【输入关键字,就能调出以前执行过的命令】
-
Ctrl+t 调换光标所在处与其之前字符位置,并把光标移到下个字符
-
Ctrl+x+u 撤销操作
-
Ctrl+z 转入后台运行
Linux命令
权限管理
列出目录的内容:ls
Linux文件或者目录名称最长可以有265个字符,“.”代表当前目录,“…”代表上一级目录,以“.”开头的文件为隐藏文件,需要用 -a 参数才能显示。
ls常用参数:
| 参数 | 含义 |
|---|---|
| -a | 显示指定目录下所有子目录与文件,包括隐藏文件 |
| -l | 以列表方式显示文件的详细信息 |
| -h | 配合 -l 以人性化的方式显示文件大小 |
[root@VM_0_9_centos ~]# ll -h
total 24K
-rw-r--r-- 1 root root 1.6K Dec 1 2016 CentOS7-Base-163.repo.1
-rw-r--r-- 1 root root 6.0K Nov 12 2015 mysql-community-release-el7-5.noarch.rpm
-rw-r--r-- 1 root root 90 Nov 23 10:26 passwd
drwxr-xr-t 2 root root 4.0K Nov 22 21:15 test
-rw-r--r-- 1 root root 276 Nov 24 10:01 user
lrwxrwxrwx 1 root root 14 Nov 6 19:18 web -> /var/www/html/
列出的信息的含义:

ls支持通配符:
| 通配符 | 含义 |
|---|---|
| * | 文件代表文件名中所有字符 |
| ls te* | 查找以te开头的文件 |
| ls *html | 查找结尾为html的文件 |
| ? | 代表文件名中任意一个字符 |
| ls ?.c | 只找第一个字符任意,后缀为.c的文件 |
| ls a.? | 只找只有3个字符,前2字符为a.,最后一个字符任意的文件 |
| [] | [”和“]”将字符组括起来,表示可以匹配字符组中的任意一个。“-”用于表示字符范围。 |
| [abc] | 匹配a、b、c中的任意一个 |
| [a-f] | 匹配从a到f范围内的的任意一个字符 |
| ls [a-f]* | 找到从a到f范围内的的任意一个字符开头的文件 |
| ls a-f | 查找文件名为a-f的文件,当“-”处于方括号之外失去通配符的作用 |
| \ | 如果要使通配符作为普通字符使用,可以在其前面加上转义字符。“?”和“*”处于方括号内时不用使用转义字符就失去通配符的作用。 |
| ls \*a | 查找文件名为*a的文件 |
显示inode的内容:stat
stat [文件或目录]
查看 testfile 文件的inode内容内容,可以用以下命令:
[root@VM_0_9_centos ~]# stat mysql-community-release-el7-5.noarch.rpm
File: ‘mysql-community-release-el7-5.noarch.rpm’
Size: 6140 Blocks: 16 IO Block: 4096 regular file
Device: fd01h/64769d Inode: 394398 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2019-11-23 13:30:42.000000000 +0800
Modify: 2015-11-12 15:58:42.000000000 +0800
Change: 2019-11-23 13:30:42.400300171 +0800
Birth: -
python@ubuntu:~/txt$ stat find我的Mr.Right.txt
文件:'find我的Mr.Right.txt'
大小:64768 块:128 IO 块:4096 普通文件
设备:801h/2049d Inode:655501 硬链接:1
权限:(0664/-rw-rw-r--) Uid:( 1000/ python) Gid:( 1000/ python)
最近访问:2019-11-22 22:43:17.565105155 +0800
最近更改:2019-11-22 22:42:42.000000000 +0800
最近改动:2019-11-22 22:43:08.797116491 +0800
创建时间:-
文件访问权限
用户能够控制一个给定的文件或目录的访问程度,一个文件或目录可能有读、写及执行权限:
- 读权限(r) :对于文件,具有读取文件内容的权限;对于目录,具有浏览目录的权限。
- 写权限(w) :对于文件,具有修改文件内容的权限;对于目录,具有删除、移动目录内文件的权限。
- 可执行权限(x): 对于文件,具有执行文件的权限;对于目录,该用户具有进入目录的权限。
通常,Unix/Linux系统只允许文件的属主(所有者)或超级用户改变文件的读写权限。
示例:

第1个字母代表文件的类型:
- “d” 代表文件夹
- “-” 代表普通文件
- “c” 代表硬件字符设备
- “b” 代表硬件块设备
- “s”表示管道文件
- “l” 代表软链接文件。
后9个字母分别代表三组权限:文件所有者、用户组、其他用户拥有的权限。
修改文件权限:chmod
chmod 修改文件权限有两种使用格式:字母法与数字法。
字母法:chmod u/g/o/a +/-/= rwx 文件
| [ u/g/o/a ] | 含义 |
|---|---|
| u | user 表示该文件的所有者 |
| g | group 表示与该文件的所有者属于同一组( group )者,即用户组 |
| o | other 表示其他以外的人 |
| a | all 表示这三者皆是 |
| [ ±= ] | 含义 |
|---|---|
| + | 增加权限 |
| - | 撤销权限 |
| = | 设定权限 |
| rwx | 含义 |
|---|---|
| r | read 表示可读取,对于一个目录,如果没有r权限,那么就意味着不能通过ls查看这个目录的内容。 |
| w | write 表示可写入,对于一个目录,如果没有w权限,那么就意味着不能在目录下创建新的文件。 |
| x | excute 表示可执行,对于一个目录,如果没有x权限,那么就意味着不能通过cd进入这个目录。 |
数字法:“rwx” 这些权限也可以用数字来代替
| 字母 | 说明 |
|---|---|
| r | 读取权限,数字代号为 “4” |
| w | 写入权限,数字代号为 “2” |
| x | 执行权限,数字代号为 “1” |
| - | 不具任何权限,数字代号为 “0” |
如执行:chmod u=rwx,g=rx,o=r filename 就等同于:chmod u=7,g=5,o=4 filename
chmod 751 file:
- 文件所有者:读、写、执行权限
- 同组用户:读、执行的权限
- 其它用户:执行的权限
chmod 777 file:所有用户拥有读、写、执行权限
注意:如果想递归所有目录加上相同权限,需要加上参数“ -R ”。 如:chmod 777 test/ -R 递归 test 目录下所有文件加 777 权限
修改文件所有者:chown
python@ubuntu:~/test$ ll h.txt
-rw------- 1 python python 4 11月 22 22:35 h.txt
python@ubuntu:~/test$ chown mike h.txt
chown: 正在更改'h.txt' 的所有者: 不允许的操作
python@ubuntu:~/test$ sudo chown mike h.txt
python@ubuntu:~/test$ ll h.txt
-rw------- 1 mike python 4 11月 22 22:35 h.txt
修改文件所属组:chgrp
python@ubuntu:~/test$ ll h.txt
-rw------- 1 mike python 4 11月 22 22:35 h.txt
python@ubuntu:~/test$ sudo chgrp mike h.txt
python@ubuntu:~/test$ ll h.txt
-rw------- 1 mike mike 4 11月 22 22:35 h.txt
文件内容查看
Linux系统中使用以下命令来查看文件的内容:
- cat 由第一行开始显示文件内容
- tac 从最后一行开始显示
- nl 显示的时候,顺道输出行号
- more 一页一页的显示文件内容
- less与more 类似,但可以往前翻页
- head 只看头几行
- tail 只看尾巴几行
基本显示:cat、tac
语法:
cat [-AbEnTv]
选项与参数:
- -A :相当于 -vET 的整合选项,可列出一些特殊字符而不是空白而已;
- -v :列出一些看不出来的特殊字符
- -E :将结尾的断行字节 $ 显示出来;
- -T :将 [tab] 按键以 ^I 显示出来;
- -b :列出行号,空白行不标行号
- -n :列出行号,连同空白行也会有行号
[root@VM_0_9_centos ~]# cat -b /etc/issue
1 \S
2 Kernel \r on an \m
[root@VM_0_9_centos ~]# cat -n /etc/issue
1 \S
2 Kernel \r on an \m
3
[root@VM_0_9_centos ~]#
tac与cat命令刚好相反,文件内容从最后一行开始显示,可以看出 tac 是 cat 的倒着写!如:
[root@VM_0_9_centos ~]# tac /etc/issue
Kernel \r on an \m
\S
显示行号:nl
语法:
nl [-bnw] 文件
选项与参数:
- -b :指定行号指定的方式,主要有两种:
-b a :表示不论是否为空行,也同样列出行号(类似 cat -n);
-b t :如果有空行,空的那一行不要列出行号(默认值); - -n :列出行号表示的方法,主要有三种:
-n ln :行号在荧幕的最左方显示;
-n rn :行号在自己栏位的最右方显示,且不加 0 ;
-n rz :行号在自己栏位的最右方显示,且加 0 ; - -w :行号栏位的占用的位数。
[root@www ~]# nl /etc/issue
1 CentOS release 6.4 (Final)
2 Kernel \r on an \m
分屏显示:more、less
[root@www ~]# more /etc/man_db.config
#
# Generated automatically from man.conf.in by the
# configure script.
#
# man.conf from man-1.6d
....(中间省略)....
--More--(28%) <== 光标在这里等待命令
more运行时可以输入的命令有:
- 空白键 (space):代表向下翻一页;
- Enter :代表向下翻『一行』;
- /字串 :代表在这个显示的内容当中,向下搜寻『字串』这个关键字;
- :f :立刻显示出档名以及目前显示的行数;
- q :代表立刻离开 more ,不再显示该文件内容。
- b 或 [ctrl]-b :代表往回翻页,不过这动作只对文件有用,对管线无用。
[root@www ~]# less /etc/man.config
#
# Generated automatically from man.conf.in by the
# configure script.
#
# man.conf from man-1.6d
....(中间省略)....
: <== 这里可以等待你输入命令!
less运行时可以输入的命令有:
- 空白键 :向下翻动一页;
- [pagedown]:向下翻动一页;
- [pageup] :向上翻动一页;
- /字串 :向下搜寻『字串』的功能;
- ?字串 :向上搜寻『字串』的功能;
- n :重复前一个搜寻 (与 / 或 ? 有关!)
- N :反向的重复前一个搜寻 (与 / 或 ? 有关!)
- q :离开 less 这个程序;
取首尾n行:head、tail
head取出文件前面几行
语法:
head [-n number] 文件
选项与参数:
- -n :后面接数字,代表显示几行的意思
[root@www ~]# head /etc/man.config
默认的情况中,显示前面 10 行!若要显示前 20 行,就得要这样:
[root@www ~]# head -n 20 /etc/man.config
tail取出文件后面几行
语法:
tail [-n number] 文件
选项与参数:
- -n :后面接数字,代表显示几行的意思
- -f :表示持续侦测后面所接的档名,要等到按下[ctrl]-c才会结束tail的侦测
[root@www ~]# tail /etc/man.config
# 默认的情况中,显示最后的十行!若要显示最后的 20 行,就得要这样:
[root@www ~]# tail -n 20 /etc/man.config
文件管理
输出重定向:>
可将本应显示在终端上的内容保存到指定文件中。
如:ls > test.txt ( test.txt 如果不存在,则创建,存在则覆盖其内容 )
注意: >输出重定向会覆盖原来的内容,>>输出重定向则会追加到文件的尾部。
管道:|
管道:一个命令的输出可以通过管道做为另一个命令的输入。
“ | ”的左右分为两端,从左端写入到右端。
python@ubuntu:/bin$ ll -h |more
总用量 13M
drwxr-xr-x 2 root root 4.0K 8月 4 2016 ./
drwxr-xr-x 26 root root 4.0K 7月 30 2016 ../
-rwxr-xr-x 1 root root 1014K 6月 24 2016 bash*
-rwxr-xr-x 1 root root 31K 5月 20 2015 bunzip2*
-rwxr-xr-x 1 root root 1.9M 8月 19 2015 busybox*
-rwxr-xr-x 1 root root 31K 5月 20 2015 bzcat*
lrwxrwxrwx 1 root root 6 5月 16 2016 bzcmp -> bzdiff*
-rwxr-xr-x 1 root root 2.1K 5月 20 2015 bzdiff*
lrwxrwxrwx 1 root root 6 5月 16 2016 bzegrep -> bzgrep*
--更多--
清屏:clear
clear作用为清除终端上的显示(类似于DOS的cls清屏功能),快捷键:Ctrl + l ( “l” 为字母 )。
切换工作目录: cd
Linux所有的目录和文件名大小写敏感
cd后面可跟绝对路径,也可以跟相对路径。如果省略目录,则默认切换到当前用户的主目录。
| 命令 | 含义 |
|---|---|
| cd | 相当于cd ~ |
| cd ~ | 切换到当前用户的主目录(/home/用户目录) |
| cd . | 切换到当前目录 |
| cd … | 切换到上级目录 |
| cd - | 进入上次所在的目录 |
显示当前路径:pwd
python@ubuntu:~$ pwd
/home/python
选项与参数:
- -P :显示出确实的路径,而非使用连结 (link) 路径。
[root@VM_0_9_centos ~]# cd /var/mail/
[root@VM_0_9_centos mail]# pwd
/var/mail
[root@VM_0_9_centos mail]# pwd -P
/var/spool/mail
创建目录:mkdir
mkdir可以创建一个新的目录。
注意:新建目录的名称不能与当前目录中已有的目录或文件同名,并且目录创建者必须对当前目录具有写权限。
语法:
mkdir [-mp] 目录名称
选项与参数:
- -m :指定被创建目录的权限,而不是根据默认权限 (umask) 设定
- -p :递归创建所需要的目录
实例:-p递归创建目录:
[root@www ~]# cd /tmp
[root@www tmp]# mkdir test <==创建一名为 test 的新目录
[root@www tmp]# mkdir test1/test2/test3/test4
mkdir: cannot create directory `test1/test2/test3/test4':
No such file or directory <== 没办法直接创建此目录啊!
[root@www tmp]# mkdir -p test1/test2/test3/test4
mkdir创建的目录权限默认根据umask得到,而-m参数可以指定被创建目录的权限:
[root@VM_0_9_centos ~]# mkdir t1
[root@VM_0_9_centos ~]# ll
drwxr-xr-x 2 root root 4096 Nov 22 18:54 t1
[root@VM_0_9_centos ~]# mkdir t2 -m 711
[root@VM_0_9_centos ~]# ll
drwxr-xr-x 2 root root 4096 Nov 22 18:54 t1
drwx--x--x 2 root root 4096 Nov 22 18:54 t2
删除文件:rm
可通过rm删除文件或目录。使用rm命令要小心,因为文件删除后不能恢复。为了防止文件误删,可以在rm后使用-i参数以逐个确认要删除的文件。
常用参数及含义如下表所示:
| 参数 | 含义 |
|---|---|
| -i | 以进行交互式方式执行 |
| -f | 强制删除,忽略不存在的文件,无需提示 |
| -r | 递归地删除目录下的内容,删除文件夹时必须加此参数 |
建立链接文件:ln
软链接:ln -s 源文件 链接文件
硬链接:ln 源文件 链接文件
软链接类似于Windows下的快捷方式,如果软链接文件和源文件不在同一个目录,源文件要使用绝对路径,不能使用相对路径。
硬链接只能链接普通文件不能链接目录。 两个文件占用相同大小的硬盘空间,即使删除了源文件,链接文件还是存在,所以-s选项是更常见的形式。
文本搜索:grep
Linux系统中grep命令是一种强大的文本搜索工具,grep允许对文本文件进行模式查找。如果找到匹配模式, grep打印包含模式的所有行。
grep一般格式为:
grep [-选项] '搜索内容串' 文件名
在grep命令中输入字符串参数时,最好引号或双引号括起来。例如:grep 'a' 1.txt。
在当前目录中,查找前缀有test字样的文件中包含 test 字符串的文件,并打印出该字符串的行。此时,可以使用如下命令:
$ grep test test* #查找前缀有test的文件包含test字符串的文件
testfile1:This a Linux testfile! #列出testfile1 文件中包含test字符的行
testfile_2:This is a linux testfile! #列出testfile_2 文件中包含test字符的行
testfile_2:Linux test #列出testfile_2 文件中包含test字符的行
以递归的方式查找符合条件的文件。例如,查找指定目录/etc/acpi 及其子目录(如果存在子目录的话)下所有文件中包含字符串"update"的文件,并打印出该字符串所在行的内容,使用的命令为:
$ grep -r update /etc/acpi #以递归的方式查找“etc/acpi”
#下包含“update”的文件
/etc/acpi/ac.d/85-anacron.sh:# (Things like the slocate updatedb cause a lot of IO.)
Rather than
/etc/acpi/resume.d/85-anacron.sh:# (Things like the slocate updatedb cause a lot of
IO.) Rather than
/etc/acpi/events/thinkpad-cmos:action=/usr/sbin/thinkpad-keys--update
反向查找。前面各个例子是查找并打印出符合条件的行,通过"-v"参数可以打印出不符合条件行的内容。
查找文件名中包含 test 的文件中不包含test 的行,此时,使用的命令为:
$ grep -v test* #查找文件名中包含test 的文件中不包含test 的行
testfile1:helLinux!
testfile1:Linis a free Unix-type operating system.
testfile1:Lin
testfile_1:HELLO LINUX!
testfile_1:LINUX IS A FREE UNIX-TYPE OPTERATING SYSTEM.
testfile_1:THIS IS A LINUX TESTFILE!
testfile_2:HELLO LINUX!
testfile_2:Linux is a free unix-type opterating system.
查找文件:find
常用用法:
| 命令 | 含义 |
|---|---|
| find ./ -name test.sh | 查找当前目录下所有名为test.sh的文件 |
| find ./ -name ‘*.sh’ | 查找当前目录下所有后缀为.sh的文件 |
| find ./ -name “[A-Z]*” | 查找当前目录下所有以大写字母开头的文件 |
| find /tmp -size 2M | 查找在/tmp 目录下等于2M的文件 |
| find /tmp -size +2M | 查找在/tmp 目录下大于2M的文件 |
| find /tmp -size -2M | 查找在/tmp 目录下小于2M的文件 |
| find ./ -size +4k -size -5M | 查找当前目录下大于4k,小于5M的文件 |
| find ./ -perm 0777 | 查找当前目录下权限为 777 的文件或目录 |
Linux find命令用来在指定目录下查找文件。任何位于参数之前的字符串都将被视为欲查找的目录名。如果使用该命令时,不设置任何参数,则find命令将在当前目录下查找子目录与文件。并且将查找到的子目录和文件全部进行显示。
语法:
find path -option [ -print ] [ -exec -ok command ] {} \;
常用参数说明 :
- -perm xxxx:权限为 xxxx的文件或目录
- -user: 按照文件属主来查找文件。
- -size n : n单位,b:512位元组的区块,c:字元数,k:kilo bytes,w:二个位元组
- -mount,-xdev : 只检查和指定目录在同一个文件系统下的文件,避免列出其它文件系统中的文件
- -amin n : 在过去 n 分钟内被读取过
- -anewer file : 比文件 file 更晚被读取过的文件
- -atime n : 在过去n天内被读取过的文件
- -cmin n : 在过去 n 分钟内被修改过
- -cnewer file :比文件 file 更新的文件
- -ctime n : 在过去n天内被修改过的文件
- -empty : 空的文件
- -gid n or -group name : gid 是 n 或是 group 名称是 name
- -ipath p,-path p : 路径名称符合 p 的文件,ipath 会忽略大小写
- -name name,-iname name : 文件名称符合 name 的文件。iname 会忽略大小写
- -type 查找某一类型的文件:
- b - 块设备文件
- d - 目录
- c - 字符设备文件
- p - 管道文件
- l - 符号链接文件
- f - 普通文件
- -exec 命令名{} \ (注意:“}”和“\”之间有空格)
find实例:
显示当前目录中大于20字节并以.c结尾的文件名
find . -name "*.c" -size +20c
将目前目录其其下子目录中所有一般文件列出
find . -type f
将目前目录及其子目录下所有最近 20 天内更新过的文件列出
find . -ctime -20
查找/var/log目录中更改时间在7日以前的普通文件,并在删除之前询问它们:
find /var/log -type f -mtime +7 -ok rm {} \;
查找前目录中文件属主具有读、写权限,并且文件所属组的用户和其他用户具有读权限的文件:
find . -type f -perm 644 -exec ls -l {} \;
查找系统中所有文件长度为0的普通文件,并列出它们的完整路径:
find / -type f -size 0 -exec ls -l {} \;
从根目录查找类型为符号链接的文件,并将其删除:
find / -type l -exec rm -rf {} \
从当前目录查找用户tom的所有文件并显示在屏幕上
find . -user tom
在当前目录中查找所有文件以.doc结尾,且更改时间在3天以上的文件,找到后删除,并且给出删除提示
find . -name *.doc -mtime +3 -ok rm {} \;
在当前目录下查找所有链接文件,并且以长格式显示文件的基本信息
find . -type l -exec ls -l {} \;
在当前目录下查找文件名有一个小写字母、一个大写字母、两个数字组成,且扩展名为.doc的文件
find . -name '[a-z][A-Z][0-9][0-9].doc'
拷贝文件:cp
cp命令的功能是将给出的文件或目录复制到另一个文件或目录中,相当于DOS下的copy命令。
常用选项说明:
| 选项 | 含义 |
|---|---|
| -a | 该选项通常在复制目录时使用,它保留链接、文件属性,并递归地复制目录,简单而言,保持文件原有属性。 |
| -f | 已经存在的目标文件而不提示 |
| -i | 交互式复制,在覆盖目标文件之前将给出提示要求用户确认 |
| -r | 若给出的源文件是目录文件,则cp将递归复制该目录下的所有子目录和文件,目标文件必须为一个目录名。 |
| -v | 显示拷贝进度 |
| -l | 创建硬链接(hard link),而非复制文件本身 |
| -s | 复制成为符号链接 (symbolic link),相当于批量创建快捷方式 |
| -u | 若 destination 比 source 旧才升级 destination ! |
cp vim_configure/ code/ -ivr 把文件夹 vim_configure 拷贝到 code 目录里。
移动文件:mv
mv命令用来移动文件或目录,也可以给文件或目录重命名。
常用选项说明:
| 选项 | 含义 |
|---|---|
| -f | 禁止交互式操作,如有覆盖也不会给出提示 |
| -i | 确认交互方式操作,如果mv操作将导致对已存在的目标文件的覆盖,系统会询问是否重写,要求用户回答以避免误覆盖文件 |
| -v | 显示移动进度 |
归档管理:tar
此命令可以把一系列文件归档到一个大文件中,也可以把档案文件解开以恢复数据。
tar使用格式 tar [参数] 打包文件名 文件
tar命令参数很特殊,其参数前面可以使用“-”,也可以不使用。
常用参数:
| 参数 | 含义 |
|---|---|
| -c | 生成档案文件,创建打包文件 |
| -v | 列出归档解档的详细过程,显示进度 |
| -f | 指定档案文件名称,f后面一定是.tar文件,所以必须放选项最后 |
| -t | 列出档案中包含的文件 |
| -x | 解开档案文件 |
注意:除了f需要放在参数的最后,其它参数的顺序任意。
python@ubuntu:~/test$ tar -cvf test.tar 1.txt 2.txt 3.txt
1.txt
2.txt
3.txt
python@ubuntu:~/test$ ll
总用量 32
drwxrwxr-x 2 python python 4096 11月 21 14:02 ./
drwxr-xr-x 31 python python 4096 11月 21 13:34 ../
-rw-rw-r-- 1 python python 51 1月 20 2017 1.txt
-rw-rw-r-- 1 python python 55 1月 20 2017 2.txt
-rw-rw-r-- 1 python python 51 1月 20 2017 3.txt
-rw-rw-r-- 1 python python 10240 11月 21 14:02 test.tar
python@ubuntu:~/test$ rm -rf *.txt
python@ubuntu:~/test$ ll
总用量 20
drwxrwxr-x 2 python python 4096 11月 21 14:03 ./
drwxr-xr-x 31 python python 4096 11月 21 13:34 ../
-rw-rw-r-- 1 python python 10240 11月 21 14:02 test.tar
python@ubuntu:~/test$ tar -xvf test.tar
1.txt
2.txt
3.txt
python@ubuntu:~/test$ ls *.txt
1.txt 2.txt 3.txt
文件压缩解压:gzip、bzip2
tar与gzip命令结合使用实现文件打包、压缩。 tar只负责打包文件,但不压缩,用gzip压缩tar打包后的文件,其扩展名一般用xxxx.tar.gz。
gzip使用格式如下:
gzip [选项] 被压缩文件
常用选项:
| 选项 | 含义 |
|---|---|
| -d | 解压文件 |
| -r | 压缩文件 |
python@ubuntu:~/test$ ll *.tar*
-rw-rw-r-- 1 python python 10240 11月 25 07:39 test.tar
python@ubuntu:~/test$ gzip -r test.tar test.tar.gz ==>或者:gzip test.tar
python@ubuntu:~/test$ ll *.tar*
-rw-rw-r-- 1 python python 139 11月 25 07:39 test.tar.gz
python@ubuntu:~/test$ gzip -d test.tar.gz
python@ubuntu:~/test$ ll *.tar*
-rw-rw-r-- 1 python python 10240 11月 25 07:39 test.tar
tar命令中-z选项可以调用gzip实现了一个压缩的功能,实行一个先打包后压缩的过程。
压缩用法:tar zcvf 压缩包包名 文件1 文件2 …
例如: tar zcvf test.tar.gz 1.c 2.c 3.c 4.c把 1.c 2.c 3.c 4.c 压缩成 test.tar.gz
python@ubuntu:~/test/code$ ls
1.c 2.c 3.c 4.c
python@ubuntu:~/test/code$ tar zcvf test.tar.gz 1.c 2.c 3.c 4.c
python@ubuntu:~/test/code$ ls
1.c 2.c 3.c 4.c test.tar.gz
python@ubuntu:~/test/code$ tar -zcvf new.tar.gz 1.c 2.c 3.c 4.c
python@ubuntu:~/test/code$ ls
1.c 2.c 3.c 4.c new.tar.gz test.tar.gz
解压用法: tar zxvf 压缩包包名
例如:
python@ubuntu:~/test/code$ ls
new.tar.gz test.tar.gz
python@ubuntu:~/test/code$ tar zxvf new.tar.gz
1.c
2.c
3.c
4.c
python@ubuntu:~/test/code$ ls
1.c 2.c 3.c 4.c new.tar.gz test.tar.gz
解压到指定目录:-C (解压时可以不指定-z选项)
python@ubuntu:~/test/code$ ls number/
python@ubuntu:~/test/code$ tar xvf test.tar.gz -C number/
python@ubuntu:~/test/code$ ls number/
1.c 2.c 3.c 4.c
bzip2命令跟gzip用法类似
压缩用法:tar jcvf 压缩包包名 文件…(tar jcvf bk.tar.bz2 *.c)
解压用法:tar jxvf 压缩包包名 (tar jxvf bk.tar.bz2)
文件压缩解压:zip、unzip
通过zip压缩文件的目标文件不需要指定扩展名,默认扩展名为zip。
压缩文件:zip [-r] 目标文件(没有扩展名) 源文件
解压文件:unzip -d 解压后目录文件 压缩文件
python@ubuntu:~/test$ ls
1.txt 2.txt 3.txt test.tar
python@ubuntu:~/test$ zip myzip *.txt
adding: 1.txt (stored 0%)
adding: 2.txt (stored 0%)
adding: 3.txt (stored 0%)
python@ubuntu:~/test$ ls
1.txt 2.txt 3.txt myzip.zip test.tar
python@ubuntu:~/test$ rm -f *.txt *.tar
python@ubuntu:~/test$ ls
myzip.zip
python@ubuntu:~/test$ unzip myzip.zip
Archive: myzip.zip
extracting: 1.txt
extracting: 2.txt
extracting: 3.txt
python@ubuntu:~/test$ ls
1.txt 2.txt 3.txt myzip.zip
python@ubuntu:~/test$ unzip -d dir myzip.zip
Archive: myzip.zip
extracting: dir/1.txt
extracting: dir/2.txt
extracting: dir/3.txt
python@ubuntu:~/test$ ls
1.txt 2.txt 3.txt dir myzip.zip
查看命令位置:which
python@ubuntu:~$ which ls
/bin/ls
python@ubuntu:~$ which sudo
/usr/bin/sudo
用户和用户组管理
用户管理包括用户与组账号的管理。
在Unix/Linux系统中,不论是由本机或是远程登录系统,每个系统都必须拥有一个账号,并且对于不同的系统资源拥有不同的使用权限。
Unix/Linux系统中的root账号通常用于系统的维护和管理,它对Unix/Linux操作系统的所有部分具有不受限制的访问权限。
在Unix/Linux安装的过程中,系统会自动创建许多用户账号,而这些默认的用户就称为“标准用户”。
在大多数版本的Unix/Linux中,都不推荐直接使用root账号登录系统。
查看当前用户:whoami
查看当前系统当前账号的用户名。可通过cat /etc/passwd查看系统用户信息。
python@ubuntu:~/test$ whoami
python
查看登录用户:who
who命令用于查看当前所有登录系统的用户信息。
常用选项:
| 选项 | 含义 |
|---|---|
| -m或am I | 只显示运行who命令的用户名、登录终端和登录时间 |
| -q或–count | 只显示用户的登录账号和登录用户的数量 |
| -u | 在登录时间后显示该用户最后一次操作到当前的时间间隔 |
| -u或–heading | 显示列标题 |
退出登录账户: exit
如果是图形界面,退出当前终端;
如果是使用ssh远程登录,退出登陆账户;
如果是切换后的登陆用户,退出则返回上一个登陆账号。
添加用户账号:useradd
在Unix/Linux中添加用户账号可以使用adduser或useradd命令,因为adduser命令是指向useradd命令的一个链接,因此,这两个命令的使用格式完全一样。
useradd命令的使用格式如下: useradd [参数] 新建用户账号
| 参数 | 含义 |
|---|---|
| -d | 指定用户登录系统时的主目录 |
| -m | 自动建立目录,未指定-d参数时会在/home/{当前用户}目录下建立主目录 |
| -g | 指定组名称 |
相关说明:
- Linux每个用户都要有一个主目录,主目录就是第一次登陆系统,用户的默认当前目录(/home/用户);
- 每一个用户必须有一个主目录,所以用useradd创建用户的时候,一定给用户指定一个主目录;
- 如果创建用户的时候,不指定组名,那么系统会自动创建一个和用户名一样的组名。
若创建用户时未指定家目录,后期可通过usermod -d /home/abc abc指定
| 命令 | 含义 |
|---|---|
| useradd -d /home/abc abc -m | 创建abc用户,如果/home/abc目录不存在,就自动创建这个目录,同时用户属于abc组 |
| useradd -d /home/a a -g test -m | 创建一个用户名字叫a,主目录在/home/a,如果主目录不存在,就自动创建主目录,同时用户属于test组 |
| cat /etc/passwd | 查看系统当前用户名 |
修改用户:usermod
常用的选项包括-c,-d,-m,-g,-G,-s,-u以及-o等,这些选项的意义与useradd命令中的选项一样,可以为用户指定新的资源值 。
修改用户所在组:usermod -g 用户组 用户名
usermod -g test abc
改abc用户的家目录位置:usermod -d 家目录 用户名
usermod -d /home/abc abc
选项-l 新用户名指定一个新的账号,可修改用户名:
python@ubuntu:~/txt$ tail /etc/passwd -n 1
aaa:x:1001:1001::/home/aaa:
python@ubuntu:~/txt$ sudo usermod -l bbb -d /home/bbb aaa
python@ubuntu:~/txt$ tail /etc/passwd -n 1
bbb:x:1001:1001::/home/bbb:
设置用户密码:passwd
超级用户可以为自己和其他用户指定口令,普通用户只能用它修改自己的口令。命令的格式为:
passwd 选项 用户名
可使用的选项:
- -l 锁定口令,即禁用账号。
- -u 口令解锁。
- -d 使账号无口令。
- -f 强迫用户下次登录时修改口令。
假设当前用户是sam,则下面的命令修改该用户自己的口令:
$ passwd
Old password:******
New password:*******
Re-enter new password:*******
如果是超级用户,可以用下列形式指定任何用户的口令:
# passwd sam
New password:*******
Re-enter new password:*******
普通用户修改自己的口令时,passwd命令会先询问原口令,验证后再要求用户输入两遍新口令,如果两次输入的口令一致,则将这个口令指定给用户;而超级用户为用户指定口令时,就不需要知道原口令。
为用户指定空口令时,执行下列形式的命令:
passwd -d sam
此命令将用户 sam 的口令删除,这样用户 sam 下一次登录时,系统就不再允许该用户登录了。
passwd 命令还可以用 -l(lock) 选项锁定某一用户,使其不能登录,例如:
passwd -l sam
删除用户:userdel
| 命令 | 含义 |
|---|---|
| userdel abc(用户名) | 删除abc用户,但不会自动删除用户的主目录 |
| userdel -r abc(用户名) | 删除用户,同时删除用户的主目录 |
切换用户:su
su后面可以加“-”会将当前的工作目录自动转换到切换后的用户主目录.
| 命令 | 含义 |
|---|---|
| su | 切换到root用户 |
| su root | 切换到root用户 |
| su - | 切换到root用户,同时切换目录到/root |
| su - root | 切换到root用户,同时切换目录到/root |
| su 普通用户 | 切换到普通用户 |
| su - 普通用户 | 切换到普通用户,同时切换普通用户所在的目录 |
注意:对于ubuntu平台,只能通过sudo su进入root账号。
sudo允许系统管理员让普通用户执行一些或者全部的root命令的一个工具。
以root身份执行指令:sudo
sudo命令可以临时获取root权限
使用权限:在 /etc/sudoers 中有出现的使用者。
显示出自己(执行 sudo 的使用者)的权限
sudo -l
以root权限执行上一条命令
sudo !!
sudoers文件配置语法
user MACHINE=COMMANDS
用户 登录的主机=(可以变换的身份) 可以执行的命令
例子:
允许root用户执行任意路径下的任意命令
root ALL=(ALL) ALL
允许wheel用户组中的用户执行所有命令
%wheel ALL=(ALL) ALL
允许wheel用户组中的用户在不输入该用户的密码的情况下使用所有命令
%wheel ALL=(ALL) NOPASSWD: ALL
允许support用户在EPG的机器上不输入密码的情况下使用SQUID中的命令
Cmnd_Alias SQUID = /opt/vtbin/squid_refresh,/sbin/service,/bin/rm
Host_Alias EPG = 192.168.1.1,192.168.1.2
support EPG=(ALL) NOPASSWD: SQUID
添加、删除组账号:groupadd、groupdel
groupadd 新建组账号 groupdel 组账号 cat /etc/group 查看用户组
python@ubuntu:~/test$ sudo groupadd abc
python@ubuntu:~/test$ sudo groupdel abc
python@ubuntu:~/test$ sudo groupdel abc
groupdel:“abc”组不存在
用户组管理:groupmod
修改用户组的属性使用groupmod命令。其语法如下:
groupmod 选项 用户组
常用的选项有:
- -g GID 为用户组指定新的组标识号。
- -o 与-g选项同时使用,用户组的新GID可以与系统已有用户组的GID相同。
- -n新用户组 将用户组的名字改为新名字
将组group2的组标识号修改为102:
groupmod -g 102 group2
将组group2的标识号改为10000,组名修改为group3:
groupmod –g 10000 -n group3 group2
如果一个用户同时属于多个用户组,那么用户可以在用户组之间切换,以便具有其他用户组的权限。
用户可以在登录后,使用命令newgrp切换到其他用户组,这个命令的参数就是目的用户组。例如:
$ newgrp root
这条命令将当前用户切换到root用户组,前提条件是root用户组确实是该用户的主组或附加组。类似于用户账号的管理,用户组的管理也可以通过集成的系统管理工具来完成。
系统管理
查看当前日历:cal
cal命令用于查看当前日历,-y显示整年日历:
python@ubuntu:~$ cal
十一月 2019
日 一 二 三 四 五 六
1 2
3 4 5 6 7 8 9
10 11 12 13 14 15 16
17 18 19 20 21 22 23
24 25 26 27 28 29 30
显示或设置时间:date
设置时间格式(需要管理员权限):
date [MMDDhhmm[[CC]YY][.ss]] +format
MM为月,DD为天,hh为小时,mm为分钟;CC为年前两位,YY为年的后两位,ss为秒。
如: date 010203042016.55。
显示时间格式(date ‘+%y,%m,%d,%H,%M,%S’):
| format格式 | 含义 |
|---|---|
| %Y,%y | 年 |
| %m | 月 |
| %d | 日 |
| %H | 时 |
| %M | 分 |
| %S | 秒 |
查看网络状态:netstat
netstat命令用于显示网络状态。
利用netstat指令可让你得知整个Linux系统的网络情况。
语法:
netstat [-acCeFghilMnNoprstuvVwx][-A<网络类型>][--ip]
参数说明:
- -a或–all 显示所有连线中的Socket。
- -A<网络类型>或–<网络类型> 列出该网络类型连线中的相关地址。
- -c或–continuous 持续列出网络状态。
- -C或–cache 显示路由器配置的快取信息。
- -e或–extend 显示网络其他相关信息。
- -F或–fib 显示FIB。
- -g或–groups 显示多重广播功能群组组员名单。
- -h或–help 在线帮助。
- -i或–interfaces 显示网络界面信息表单。
- -l或–listening 显示监控中的服务器的Socket。
- -M或–masquerade 显示伪装的网络连线。
- -n或–numeric 直接使用IP地址,而不通过域名服务器。
- -N或–netlink或–symbolic 显示网络硬件外围设备的符号连接名称。
- -o或–timers 显示计时器。
- -p或–programs 显示正在使用Socket的程序识别码和程序名称。
- -r或–route 显示Routing Table。
- -s或–statistice 显示网络工作信息统计表。
- -t或–tcp 显示TCP传输协议的连线状况。
- -u或–udp 显示UDP传输协议的连线状况。
- -v或–verbose 显示指令执行过程。
- -V或–version 显示版本信息。
- -w或–raw 显示RAW传输协议的连线状况。
- -x或–unix 此参数的效果和指定"-A unix"参数相同。
- –ip或–inet 此参数的效果和指定"-A inet"参数相同。
常用:
[root@VM_0_9_centos ~]# netstat -nltp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 3308/sshd
tcp6 0 0 :::80 :::* LISTEN 4624/httpd
查看进程信息:ps
进程是一个具有一定独立功能的程序,它是操作系统动态执行的基本单元。
ps命令选项:
- ps a 显示现行终端机下的所有程序,包括其他用户的程序。
- ps -A 显示所有程序。
- ps c 列出程序时,显示每个程序真正的指令名称,而不包含路 径,参数或常驻服务的标示。
- ps -e 此参数的效果和指定"A"参数相同。
- ps e 列出程序时,显示每个程序所使用的环境变量。
- ps f 用ASCII字符显示树状结构,表达程序间的相互关系。
- ps -H 显示树状结构,表示程序间的相互关系。
- ps -N 显示所有的程序,除了执行ps指令终端机下的程序之外。
- ps s 采用程序信号的格式显示程序状况。
- ps u 以用户为主的格式来显示程序状况。
- ps x 显示所有程序,不以终端机来区分。
| 选项 | 含义 |
|---|---|
| -a | 显示终端上的所有进程,包括其他用户的进程 |
| -u | 显示进程的详细状态 |
| -x | 显示没有控制终端的进程 |
| -w | 显示加宽,以便显示更多的信息 |
| -r | 只显示正在运行的进程 |
常见用法:
- ps -e 查看所有进程信息(瞬时的)
- ps -u root -N 查看所有不是root运行的进程
- ps ax 显示所有进程状态状态
- ps -ef |grep xxx 显示含有xxx的进程
实例:
# ps -A 显示进程信息
PID TTY TIME CMD
1 ? 00:00:02 init
2 ? 00:00:00 kthreadd
……省略部分结果
30749 pts/0 00:00:15 gedit
30886 ? 00:01:10 qtcreator.bin
30894 ? 00:00:00 qtcreator.bin
显示指定用户信息:
# ps -u root //显示root进程用户信息
PID TTY TIME CMD
1 ? 00:00:02 init
2 ? 00:00:00 kthreadd
3 ? 00:00:00 migration/0
……省略部分结果
30487 ? 00:00:06 gnome-terminal
30488 ? 00:00:00 gnome-pty-helpe
30489 pts/0 00:00:00 bash
显示所有进程信息,连同命令行
# ps -ef //显示所有命令,连带命令行
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 10:22 ? 00:00:02 /sbin/init
root 2 0 0 10:22 ? 00:00:00 [kthreadd]
root 3 2 0 10:22 ? 00:00:00 [migration/0]
root 4 2 0 10:22 ? 00:00:00 [ksoftirqd/0]
root 5 2 0 10:22 ? 00:00:00 [watchdog/0]
root 6 2 0 10:22 ? /usr/lib/NetworkManager
……省略部分结果
root 31302 2095 0 17:42 ? 00:00:00 sshd: root@pts/2
root 31374 31302 0 17:42 pts/2 00:00:00 -bash
root 31400 1 0 17:46 ? 00:00:00 /usr/bin/python /usr/sbin/aptd
root 31407 31374 0 17:48 pts/2 00:00:00 ps -ef
以树状图显示进程关系:pstree
显示进程的关系
pstree
init-+-amd
|-apmd
|-atd
|-httpd---10*[httpd]
%pstree -p
init(1)-+-amd(447)
|-apmd(105)
|-atd(339)
%pstree -c
init-+-amd
|-apmd
|-atd
|-httpd-+-httpd
| |-httpd
| |-httpd
| |-httpd
....
特别表明在运行的进程:
# pstree -apnh //显示进程间的关系
同时显示用户名称:
# pstree -u //显示用户名称
动态显示进程:top
top命令用来动态显示运行中的进程。top命令能够在运行后,在指定的时间间隔更新显示信息。-d参数可以指定显示信息更新的时间间隔。
在top命令执行后,可以按下按键得到对显示的结果进行排序:
| 按键 | 含义 |
|---|---|
| M | 根据内存使用量来排序 |
| P | 根据CPU占有率来排序 |
| T | 根据进程运行时间的长短来排序 |
| U | 可以根据后面输入的用户名来筛选进程 |
| K | 可以根据后面输入的PID来杀死进程。 |
| q | 退出 |
| h | 获得帮助 |
python@ubuntu:~$ top
top - 08:31:54 up 2 min,1 user,load average: 0.25,0.37,0.17
Tasks: 271 total,1 running,270 sleeping,0 stopped,0 zombie
%Cpu(s): 0.2 us,0.0 sy,0.0 ni,99.8 id,0.0 wa,0.0 hi,0.0 si,0.0 st
KiB Mem : 4028880 total,3210104 free,331668 used,487108 buff/cache
KiB Swap: 4192252 total,4192252 free,0 used. 3414856 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
4827 redis 20 0 47204 6632 2300 S 0.3 0.2 0:00.21 redis-ser+
6371 python 20 0 49000 3896 3176 R 0.3 0.1 0:00.12 top
1 root 20 0 119940 6112 4004 S 0.0 0.2 0:02.77 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.02 kthreadd
3 root 20 0 0 0 0 S 0.0 0.0 0:00.11 ksoftirqd+
更高级的命令是htop,但需要安装:
[root@VM_0_9_centos ~]# htop
CPU[|| 1.3%] Tasks: 55,29 thr; 1 running
Mem[||||||||||||||||||||||||||||||||||||||||||||||||||||||||||184M/1.80G] Load average: 0.00 0.01 0.05
Swp[ 0K/0K] Uptime: 42 days,03:29:48
PID USER PRI NI VIRT RES SHR S CPU% MEM% TIME+ Command
2609 root 20 0 156M 9132 1784 S 0.7 0.5 39:01.13 barad_agent
2610 root 20 0 660M 14168 1976 S 0.7 0.8 3h35:20 barad_agent
1158 root 20 0 120M 2576 1492 R 0.0 0.1 0:00.01 htop
终止进程:kill
kill命令指定进程号的进程,需要配合 ps 使用。
使用格式:
kill [-signal] pid
信号值从0到15,其中9为绝对终止,可以处理一般信号无法终止的进程。
关机重启:reboot、shutdown、init
| 命令 | 含义 |
|---|---|
| reboot | 重新启动操作系统 |
| shutdown –r now | 重新启动操作系统,shutdown会给别的用户提示 |
| shutdown -h now | 立刻关机,其中now相当于时间为0的状态 |
| shutdown -h 20:25 | 系统在今天的20:25 会关机 |
| shutdown -h +10 | 系统再过十分钟后自动关机 |
| init 0 | 关机 |
| init 6 | 重启 |
检测磁盘空间:df
df命令用于检测文件系统的磁盘空间占用和空余情况,可以显示所有文件系统对节点和磁盘块的使用情况。
| 选项 | 含义 |
|---|---|
| -a | 显示所有文件系统的磁盘使用情况 |
| -m | 以1024字节为单位显示 |
| -t | 显示各指定文件系统的磁盘空间使用情况 |
| -T | 显示文件系统 |
python@ubuntu:~/test$ df -Th
文件系统 类型 容量 已用 可用 已用% 挂载点
udev devtmpfs 2.0G 0 2.0G 0% /dev
tmpfs tmpfs 394M 6.4M 388M 2% /run
/dev/sda1 ext4 21G 8.7G 11G 45% /
tmpfs tmpfs 2.0G 256K 2.0G 1% /dev/shm
tmpfs tmpfs 5.0M 4.0K 5.0M 1% /run/lock
tmpfs tmpfs 2.0G 0 2.0G 0% /sys/fs/cgroup
tmpfs tmpfs 394M 44K 394M 1% /run/user/1000
[root@VM_0_9_centos ~]# df -Th
Filesystem Type Size Used Avail Use% Mounted on
/dev/vda1 ext4 50G 4.8G 42G 11% /
devtmpfs devtmpfs 909M 0 909M 0% /dev
tmpfs tmpfs 920M 24K 920M 1% /dev/shm
tmpfs tmpfs 920M 472K 919M 1% /run
tmpfs tmpfs 920M 0 920M 0% /sys/fs/cgroup
tmpfs tmpfs 184M 0 184M 0% /run/user/0
检测目录所占磁盘空间:du
du命令用于统计目录或文件所占磁盘空间的大小,该命令的执行结果与df类似,du更侧重于磁盘的使用状况。
du命令的使用格式如下: du [选项] 目录或文件名
| 选项 | 含义 |
|---|---|
| -a | 递归显示指定目录中各文件和子目录中文件占用的数据块 |
| -s | 显示指定文件或目录占用的数据块 |
| -b | 以字节为单位显示磁盘占用情况 |
| -l | 计算所有文件大小,对硬链接文件计算多次 |
python@ubuntu:~$ du -sh /home/
1.4G /home/
python@ubuntu:~$ du -h
4.0K ./.gnome2/accels
8.0K ./.gnome2
32K ./.pki/nssdb
36K ./.pki
8.0K ./.dbus/session-bus
12K ./.dbus
4.0K ./.gnome2_private
4.0K ./Music
查看或配置网卡信息:ifconfig
ifconfig显示所有网卡的信息:
python@ubuntu:~$ ifconfig
ens33 Link encap:以太网 硬件地址 00:0c:29:59:65:f2
inet 地址:192.168.40.11 广播:192.168.40.255 掩码:255.255.255.0
inet6 地址: fe80::432f:6c4a:f47d:5f6b/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 跃点数:1
接收数据包:422794 错误:0 丢弃:0 过载:0 帧数:0
发送数据包:208666 错误:0 丢弃:0 过载:0 载波:0
碰撞:0 发送队列长度:1000
接收字节:603741383 (603.7 MB) 发送字节:12819550 (12.8 MB)
lo Link encap:本地环回
inet 地址:127.0.0.1 掩码:255.0.0.0
inet6 地址: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:65536 跃点数:1
接收数据包:2248 错误:0 丢弃:0 过载:0 帧数:0
发送数据包:2248 错误:0 丢弃:0 过载:0 载波:0
碰撞:0 发送队列长度:1
接收字节:497588 (497.5 KB) 发送字节:497588 (497.5 KB)
修改ip:
python@ubuntu:~$ sudo ifconfig ens33 192.168.40.10
python@ubuntu:~$ ifconfig ens33
ens33 Link encap:以太网 硬件地址 00:0c:29:59:65:f2
inet 地址:192.168.40.10 广播:192.168.40.255 掩码:255.255.255.0
inet6 地址: fe80::432f:6c4a:f47d:5f6b/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 跃点数:1
接收数据包:422818 错误:0 丢弃:0 过载:0 帧数:0
发送数据包:208692 错误:0 丢弃:0 过载:0 载波:0
碰撞:0 发送队列长度:1000
接收字节:603745130 (603.7 MB) 发送字节:12822615 (12.8 MB)
测试远程主机连通性:ping
python@ubuntu:~$ ping 192.168.40.1
PING 192.168.40.1 (192.168.40.1) 56(84) bytes of data.
64 bytes from 192.168.40.1: icmp_seq=1 ttl=64 time=0.699 ms
64 bytes from 192.168.40.1: icmp_seq=2 ttl=64 time=0.372 ms
^C
--- 192.168.40.1 ping statistics ---
2 packets transmitted,2 received,0% packet loss,time 1001ms
rtt min/avg/max/mdev = 0.372/0.535/0.699/0.165 ms
python@ubuntu:~$ ping 192.168.40.1 -c 3
PING 192.168.40.1 (192.168.40.1) 56(84) bytes of data.
64 bytes from 192.168.40.1: icmp_seq=1 ttl=64 time=0.409 ms
64 bytes from 192.168.40.1: icmp_seq=2 ttl=64 time=0.367 ms
64 bytes from 192.168.40.1: icmp_seq=3 ttl=64 time=0.373 ms
--- 192.168.40.1 ping statistics ---
3 packets transmitted,3 received,time 2000ms
rtt min/avg/max/mdev = 0.367/0.383/0.409/0.018 ms
python@ubuntu:~$
Linux 磁盘管理
Linux磁盘管理常用三个命令为df、du和fdisk。
- df:列出文件系统的整体磁盘使用量
- du:检查磁盘空间使用量
- fdisk:用于磁盘分区
df
获取硬盘被占用了多少空间,目前还剩下多少空间等信息。
语法:
df [-ahikHTm] [目录或文件名]
选项与参数:
- -a :列出所有的文件系统,包括系统特有的 /proc 等文件系统;
- -k :以 KBytes 的容量显示各文件系统;
- -m :以 MBytes 的容量显示各文件系统;
- -h :以人们较易阅读的 GBytes,MBytes,KBytes 等格式自行显示;
- -H :以 M=1000K 取代 M=1024K 的进位方式;
- -T :显示文件系统类型,连同该 partition 的 filesystem 名称 (例如 ext3) 也列出;
- -i :不用硬盘容量,而以 inode 的数量来显示
[root@VM_0_9_centos ~]# df -hT
Filesystem Type Size Used Avail Use% Mounted on
/dev/vda1 ext4 50G 4.9G 42G 11% /
devtmpfs devtmpfs 909M 0 909M 0% /dev
tmpfs tmpfs 920M 24K 920M 1% /dev/shm
tmpfs tmpfs 920M 496K 919M 1% /run
tmpfs tmpfs 920M 0 920M 0% /sys/fs/cgroup
tmpfs tmpfs 184M 0 184M 0% /run/user/0
将系统内的所有特殊文件格式及名称都列出来
[root@www ~]# df -aT
Filesystem Type 1K-blocks Used Available Use% Mounted on
/dev/hdc2 ext3 9920624 3823112 5585444 41% /
proc proc 0 0 0 - /proc
sysfs sysfs 0 0 0 - /sys
devpts devpts 0 0 0 - /dev/pts
/dev/hdc3 ext3 4956316 141376 4559108 4% /home
/dev/hdc1 ext3 101086 11126 84741 12% /boot
tmpfs tmpfs 371332 0 371332 0% /dev/shm
none binfmt_misc 0 0 0 - /proc/sys/fs/binfmt_misc
sunrpc rpc_pipefs 0 0 0 - /var/lib/nfs/rpc_pipefs
du
du命令是对文件和目录磁盘使用的空间的查看.
语法:
du [-ahskm] 文件或目录名称
选项与参数:
- -a :列出所有的文件与目录容量,因为默认仅统计目录底下的文件量而已。
- -h :以人们较易读的容量格式 (G/M) 显示;
- -s :列出总量而已,而不列出每个各别的目录占用容量;
- -S :不包括子目录下的总计,与 -s 有点差别。
- -k :以 KBytes 列出容量显示;
- -m :以 MBytes 列出容量显示;
du没有加任何选项时,只列出当前目录下的所有文件夹容量(包括隐藏文件夹):
[root@www ~]# du
8 ./test4 <==每个目录都会列出来
8 ./test2
....中间省略....
12 ./.gconfd <==包括隐藏文件的目录
220 . <==这个目录(.)所占用的总量
直接输入 du 没有加任何选项时,则 du 会分析当前所在目录的文件与目录所占用的硬盘空间。
加-a选项才显示文件的容量:
[root@www ~]# du -a
12 ./install.log.syslog <==有文件的列表了
8 ./.bash_logout
8 ./test4
8 ./test2
....中间省略....
12 ./.gconfd
220 .
检查根目录底下每个目录所占用的容量
[root@www ~]# du -sh /*
0 /bin
108M /boot
4.0K /data
.....中间省略....
0 /proc
.....中间省略....
40K /tmp
2.4G /usr
2.4G /var
fdisk
fdisk 是 Linux 的磁盘分区表操作工具。
语法:
fdisk [-l] 装置名称
选项与参数:
- -l :输出后面接的装置所有的分区内容。若仅有 fdisk -l 时, 则系统将会把整个系统内能够搜寻到的装置的分区均列出来。
列出所有分区信息:
[root@AY120919111755c246621 tmp]# fdisk -l
Disk /dev/xvda: 21.5 GB,21474836480 bytes
255 heads,63 sectors/track,2610 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x00000000
Device Boot Start End Blocks Id System
/dev/xvda1 * 1 2550 20480000 83 Linux
/dev/xvda2 2550 2611 490496 82 Linux swap / Solaris
Disk /dev/xvdb: 21.5 GB,2610 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x56f40944
Device Boot Start End Blocks Id System
/dev/xvdb2 1 2610 20964793+ 83 Linux
查看根目录所在磁盘,并查阅该硬盘内的相关信息:
[root@www ~]# df / <==注意:重点在找出磁盘文件名而已
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/hdc2 9920624 3823168 5585388 41% /
[root@www ~]# fdisk /dev/hdc <==不要加上数字!
The number of cylinders for this disk is set to 5005.
There is nothing wrong with that,but this is larger than 1024,and could in certain setups cause problems with:
1) software that runs at boot time (e.g.,old versions of LILO)
2) booting and partitioning software from other OSs
(e.g.,DOS FDISK,OS/2 FDISK)
Command (m for help): <==等待你的输入!
输入 m 后,就会看到底下这些命令介绍
Command (m for help): m <== 输入 m 后,就会看到底下这些命令介绍
Command action
a toggle a bootable flag
b edit bsd disklabel
c toggle the dos compatibility flag
d delete a partition <==删除一个partition
l list known partition types
m print this menu
n add a new partition <==新增一个partition
o create a new empty DOS partition table
p print the partition table <==在屏幕上显示分割表
q quit without saving changes <==不储存离开fdisk程序
s create a new empty Sun disklabel
t change a partition's system id
u change display/entry units
v verify the partition table
w write table to disk and exit <==将刚刚的动作写入分割表
x extra functionality (experts only)
离开 fdisk 时按下 q,那么所有的动作都不会生效!相反的, 按下w就是动作生效的意思。
Command (m for help): p <== 这里可以输出目前磁盘的状态
Disk /dev/hdc: 41.1 GB,41174138880 bytes <==这个磁盘的文件名与容量
255 heads,5005 cylinders <==磁头、扇区与磁柱大小
Units = cylinders of 16065 * 512 = 8225280 bytes <==每个磁柱的大小
Device Boot Start End Blocks Id System
/dev/hdc1 * 1 13 104391 83 Linux
/dev/hdc2 14 1288 10241437+ 83 Linux
/dev/hdc3 1289 1925 5116702+ 83 Linux
/dev/hdc4 1926 5005 24740100 5 Extended
/dev/hdc5 1926 2052 1020096 82 Linux swap / Solaris
# 装置文件名 启动区否 开始磁柱 结束磁柱 1K大小容量 磁盘分区槽内的系统
Command (m for help): q
使用 p 可以列出目前这颗磁盘的分割表信息,这个信息的上半部在显示整体磁盘的状态。
磁盘格式化
磁盘分割完毕后自然就是要进行文件系统的格式化,格式化的命令非常的简单,使用 mkfs(make filesystem) 命令。
语法:
mkfs [-t 文件系统格式] 装置文件名
选项与参数:
- -t :可以接文件系统格式,例如 ext3,ext2,vfat 等(系统有支持才会生效)
查看 mkfs 支持的文件格式:
[root@VM_0_9_centos web]# mkfs[tab]
mkfs mkfs.cramfs mkfs.ext3 mkfs.minix
mkfs.btrfs mkfs.ext2 mkfs.ext4 mkfs.xfs
按下两个[tab],会发现 mkfs 支持的文件格式如上所示。
将分区 /dev/hdc6(可指定其他分区) 格式化为ext3文件系统:
[root@www ~]# mkfs -t ext3 /dev/hdc6
mke2fs 1.39 (29-May-2006)
Filesystem label= <==这里指的是分割槽的名称(label)
OS type: Linux
Block size=4096 (log=2) <==block 的大小配置为 4K
Fragment size=4096 (log=2)
251392 inodes,502023 blocks <==由此配置决定的inode/block数量
25101 blocks (5.00%) reserved for the super user
First data block=0
Maximum filesystem blocks=515899392
16 block groups
32768 blocks per group,32768 fragments per group
15712 inodes per group
Superblock backups stored on blocks:
32768,98304,163840,229376,294912
Writing inode tables: done
Creating journal (8192 blocks): done <==有日志记录
Writing superblocks and filesystem accounting information: done
This filesystem will be automatically checked every 34 mounts or
180 days,whichever comes first. Use tune2fs -c or -i to override.
# 这样就创建起来我们所需要的 Ext3 文件系统了!简单明了!
磁盘检验
fsck(file system check)用来检查和维护不一致的文件系统。
若系统掉电或磁盘发生问题,可利用fsck命令对文件系统进行检查。
语法:
fsck [-t 文件系统] [-ACay] 装置名称
选项与参数:
- -t : 给定档案系统的型式,若在 /etc/fstab 中已有定义或 kernel 本身已支援的则不需加上此参数
- -s : 依序一个一个地执行 fsck 的指令来检查
- -A : 对/etc/fstab 中所有列出来的 分区(partition)做检查
- -C : 显示完整的检查进度
- -d : 打印出 e2fsck 的 debug 结果
- -p : 同时有 -A 条件时,同时有多个 fsck 的检查一起执行
- -R : 同时有 -A 条件时,省略 / 不检查
- -V : 详细显示模式
- -a : 如果检查有错则自动修复
- -r : 如果检查有错则由使用者回答是否修复
- -y : 选项指定检测每个文件是自动输入yes,在不确定那些是不正常的时候,可以执行 # fsck -y 全部检查修复。
查看系统有多少文件系统支持的 fsck 命令:
[root@www ~]# fsck[tab][tab]
fsck fsck.cramfs fsck.ext2 fsck.ext3 fsck.msdos fsck.vfat
强制检测 /dev/hdc6 分区:
[root@www ~]# fsck -C -f -t ext3 /dev/hdc6
fsck 1.39 (29-May-2006)
e2fsck 1.39 (29-May-2006)
Pass 1: Checking inodes,blocks,and sizes
Pass 2: Checking directory structure
Pass 3: Checking directory connectivity
Pass 4: Checking reference counts
Pass 5: Checking group summary information
vbird_logical: 11/251968 files (9.1% non-contiguous),36926/1004046 blocks
如果没有加上 -f 的选项,则由于这个文件系统不曾出现问题,检查的经过非常快速!若加上 -f 强制检查,才会一项一项的显示过程。
磁盘挂载与卸除
Linux 的磁盘挂载使用 mount 命令,卸载使用 umount 命令。
磁盘挂载语法:
mount [-t 文件系统] [-L Label名] [-o 额外选项] [-n] 装置文件名 挂载点
用默认的方式,将刚刚创建的 /dev/hdc6 挂载到 /mnt/hdc6 上面!
[root@www ~]# mkdir /mnt/hdc6
[root@www ~]# mount /dev/hdc6 /mnt/hdc6
[root@www ~]# df
Filesystem 1K-blocks Used Available Use% Mounted on
.....中间省略.....
/dev/hdc6 1976312 42072 1833836 3% /mnt/hdc6
磁盘卸载命令 umount 语法:
umount [-fn] 装置文件名或挂载点
选项与参数:
- -f :强制卸除!可用在类似网络文件系统 (NFS) 无法读取到的情况下;
- -n :不升级 /etc/mtab 情况下卸除。
卸载/dev/hdc6
[root@www ~]# umount /dev/hdc6
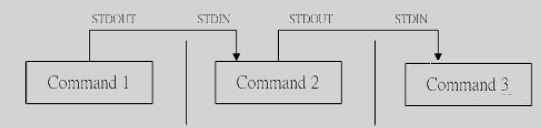
Linux管道命令
Linux的管道命令是’|’,通过它可以对数据进行连续处理,其示意图如下:
注意:
1)管道命令仅处理标准输出,对于标准错误输出,将忽略
2)管道命令右边命令,必须能够接收标准输入流命令才行,否则传递过程中数据会抛弃。
常用来作为接收数据管道命令有: less,more,head,tail,而ls,cp,mv就不行。
wc - 统计字数
可以计算文件的Byte数、字数、或是列数,若不指定文件名称、或是所给予的文件名为"-",则wc指令会从标准输入设备读取数据。
wc [-lwm] [filename]
-l: 统计行数
-w:统计英文单词
-m:统计字符数
python@xxx:~$ wc -l /etc/passwd
49 /etc/passwd
python@xxx:~$ wc -w /etc/passwd
81 /etc/passwd
python@xxx:~$ wc -m /etc/passwd
2696 /etc/passwd
在默认的情况下,wc将计算指定文件的行数、字数,以及字节数。使用的命令为:
$ wc testfile # testfile文件的统计信息
3 92 598 testfile # testfile文件的行数为3、单词数92、字节数598
其中,3 个数字分别表示testfile文件的行数、单词数,以及该文件的字节数。
如果想同时统计多个文件的信息,例如同时统计testfile、testfile_1、testfile_2,可使用如下命令:
$ wc testfile testfile_1 testfile_2 #统计三个文件的信息
3 92 598 testfile #第一个文件行数为3、单词数92、字节数598
9 18 78 testfile_1 #第二个文件的行数为9、单词数18、字节数78
3 6 32 testfile_2 #第三个文件的行数为3、单词数6、字节数32
15 116 708 总用量 #三个文件总共的行数为15、单词数116、字节数708
cut - 列选取命令
选项与参数:
-d :后面接分隔字符。与 -f 一起使用;
-f :依据 -d 的分隔字符将一段信息分割成为数段,用 -f 取出第几段的意思;
-c :以字符 (characters) 的单位取出固定字符区间;
cut以行为单位,根据分隔符把行分成若干列,这样就可以指定选取哪些列了。
cut -d '分隔字符' -f 选取的列数
echo $PATH|cut -d ':' -f 2 --选取第2列
echo $PATH|cut -d ':' -f 3,5 --选取第3列和第5列
echo $PATH|cut -d ':' -f 3-5 --选取第3列到第5列
echo $PATH|cut -d ':' -f 3- --选取第3列到最后1列
echo $PATH|cut -d ':' -f 1-3,5 --选取第1到第3列还有第5列
只显示/etc/passwd的用户和shell:
#cat /etc/passwd | cut -d ':' -f 1,7
root:/bin/bash
daemon:/bin/sh
bin:/bin/sh
grep - 行选取命令
grep一般格式为:
grep [-cinv] '查找的字符串' filename
在grep命令中输入字符串参数时,最好引号或双引号括起来。例如:grep 'a' 1.txt。
常用选项说明:
| 选项 | 含义 |
|---|---|
| -v | 显示不包含匹配文本的所有行(相当于求反) |
| -n | 显示匹配行及行号 |
| -i | 忽略大小写 |
| -c | 计算找到的行数 |
grep搜索内容串可以是正则表达式,常用正则表达式:
| 参数 | 含义 |
|---|---|
| ^a | 行首,搜寻以 m 开头的行;grep -n ‘^a’ 1.txt |
| ke$ | 行尾,搜寻以 ke 结束的行;grep -n ‘ke$’ 1.txt |
| [Ss]igna[Ll] | 匹配 [] 里中一系列字符中的一个;搜寻匹配单词signal、signaL、Signal、SignaL的行;grep -n ‘[Ss]igna[Ll]’ 1.txt |
| . | .匹配一个非换行符的字符;grep -n ‘e.e’ 1.txt可以匹配 eee,eae,eve,但是不匹配 ee,eaae; |
| * | 匹配零个或多个先前字符 |
| [^] | 匹配一个不在指定范围内的字符 |
\(..\) |
标记匹配字符 |
| \ | 锚定单词的开始 |
\< |
锚定单词的开头 |
\> |
锚定单词的结束 |
x\{m\} |
重复字符x,m次 |
x\{m,\} |
重复字符x,至少m次 |
x\{m,n\} |
重复字符x,至少m次,不多于n次 |
| \w | 匹配文字和数字字符,也就是[A-Za-z0-9] |
| \b | 单词锁定符 |
实例:
显示所有以“h”结尾的行
grep h$
匹配所有以“a”开头且以“e”结尾的,中间包含2个字符的单词
grep ‘<a…e>’
显示所有包含一个”y”或”h”字符的行
grep [yh]
显示不包含字母a~k 且后紧跟“pple”的单词
grep [^a-k]pple
从系统词典中选择所有以“c”开头且以“o”结尾的单词grep '\<c.*o\>'
找出一个文件中或者输出中找到包含*的行grep '\*'
显示所有包含每个字符串至少有20个连续字母的单词的行grep [a-Z]\{20,\}
sort - 排序
语法:
sort [-fbMnrtuk] [file or stdin]
参数说明:
- -f :忽略大小写的差异,例如 A 与 a 视为编码相同;
- -b :忽略最前面的空格符部分;
- -M :以月份的名字来排序,例如 JAN,DEC 等等的排序方法;
- -n :使用『纯数字』进行排序(默认是以文字型态来排序的);
- -r :反向排序;
- -u :就是 uniq ,相同的数据中,仅出现一行代表;
- -t :分隔符,默认是用 [tab] 键来分隔;
- -k :以哪个区间 (field) 来进行排序
默认是以第一个字符升序排序:
# cat /etc/passwd | sort
adm:x:3:4:adm:/var/adm:/sbin/nologin
avahi-autoipd:x:100:156:avahi-autoipd:/var/lib/avahi-autoipd:/sbin/nologin
avahi:x:70:70:Avahi daemon:/:/sbin/nologin
bin:x:1:1:bin:/bin:/sbin/nologin
......
以第3列排序:
[root@www ~]# cat /etc/passwd | sort -t ':' -k 3
root:x:0:0:root:/root:/bin/bash
uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
bin:x:1:1:bin:/bin:/sbin/nologin
games:x:12:100:games:/usr/games:/sbin/nologin
使用数字排序:
cat /etc/passwd | sort -t ':' -k 3n
root:x:0:0:root:/root:/bin/bash
daemon:x:1:1:daemon:/usr/sbin:/bin/sh
bin:x:2:2:bin:/bin:/bin/sh
倒序排序:
cat /etc/passwd | sort -t ':' -k 3nr
nobody:x:65534:65534:nobody:/nonexistent:/bin/sh
ntp:x:106:113::/home/ntp:/bin/false
messagebus:x:105:109::/var/run/dbus:/bin/false
sshd:x:104:65534::/var/run/sshd:/usr/sbin/nologin
或者
cat /etc/passwd | sort -t ':' -k 3 -nr
先以第六个域的第2个字符到第4个字符进行正向排序,再基于第一个域进行反向排序:
cat /etc/passwd | sort -t ':' -k 6.2,6.4 -k 1r
sync:x:4:65534:sync:/bin:/bin/sync
proxy:x:13:13:proxy:/bin:/bin/sh
bin:x:2:2:bin:/bin:/bin/sh
sys:x:3:3:sys:/dev:/bin/sh
查看/etc/passwd有多少个shell:
方法对/etc/passwd的第七个域排序并去重,然后统计行数:
[root@VM_0_9_centos ~]# cat /etc/passwd | sort -t':' -k 7 -u
root:x:0:0:root:/root:/bin/bash
syslog:x:996:994::/home/syslog:/bin/false
sync:x:5:0:sync:/sbin:/bin/sync
halt:x:7:0:halt:/sbin:/sbin/halt
bin:x:1:1:bin:/bin:/sbin/nologin
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
[root@VM_0_9_centos ~]# cat /etc/passwd | sort -t':' -k 7 -u|wc -l
6
uniq - 去重
选项与参数:
-i :忽略大小写字符的不同;
-c :进行计数
-u :只显示唯一的行
该命令用于排完序之后,对排序结果进行去重
python@xxx:~$ last | cut -d ' ' -f 1 | sort | uniq
haha
python
reboot
wtmp
python@xxx:~$ last | cut -d ' ' -f 1 | sort | uniq -c
1
2 haha
22 python
7 reboot
1 wtmp
排序文件,默认是去重:
#cat words | sort |uniq
friend
hello
world
排序之后删除了重复行,同时在行首位置输出该行重复的次数:
#sort testfile | uniq -c
1 friend
3 hello
2 world
仅显示存在重复的行,并在行首显示该行重复的次数:
#sort testfile | uniq -dc
3 hello
2 world
仅显示不重复的行:
sort testfile | uniq -u
friend
tee - 同时输出多个文件
从标准输入设备读取数据,将其内容输出到标准输出设备,同时保存成文件。
一般情况下用重定向实现,需要同时输出多个文件时可以使用该命令。
参数:
- -a或–append 附加到既有文件的后面,而非覆盖它.
将输出同时保存到多个文件中,同时将输出内容显示到控制台:
python@xxx:~/test$ echo "hello world"|tee f1 f2
hello world
python@xxx:~/test$ cat f1
hello world
python@xxx:~/test$ echo "hello world"|tee f1 f2 -a
hello world
python@xxx:~/test$ cat f1
hello world
hello world
tr - 替换指定的字符
不指定参数时,即表示替换指定的字符为另一个字符,支持指定的字符集合。
参数说明:
- -d,--delete:删除指定的字符
- -s,--squeeze-repeats:缩减连续重复的字符成指定的单个字符
字符集合的范围:
- \NNN 八进制值的字符 NNN (1 to 3 为八进制值的字符)
- \ 反斜杠
- \a Ctrl-G 铃声
- \b Ctrl-H 退格符
- \f Ctrl-L 走行换页
- \n Ctrl-J 新行
- \r Ctrl-M 回车
- \t Ctrl-I tab键
- \v Ctrl-X 水平制表符
- CHAR1-CHAR2 :字符范围从 CHAR1 到 CHAR2 的指定,范围的指定以 ASCII 码的次序为基础,只能由小到大,不能由大到小。
- [CHAR*] :这是 SET2 专用的设定,功能是重复指定的字符到与 SET1 相同长度为止
- [CHAR*REPEAT] :这也是 SET2 专用的设定,功能是重复指定的字符到设定的 REPEAT 次数为止(REPEAT 的数字采 8 进位制计算,以 0 为开始)
- [:alnum:] :所有字母字符与数字
- [:alpha:] :所有字母字符
- [:blank:] :所有水平空格
- [:cntrl:] :所有控制字符
- [:digit:] :所有数字
- [:graph:] :所有可打印的字符(不包含空格符)
- [:lower:] :所有小写字母
- [:print:] :所有可打印的字符(包含空格符)
- [:punct:] :所有标点字符
- [:space:] :所有水平与垂直空格符
- [:upper:] :所有大写字母
- [:xdigit:] :所有 16 进位制的数字
- [=CHAR=] :所有符合指定的字符(等号里的 CHAR,代表你可自订的字符)
将文件testfile中的小写字母全部转换成大写字母:
cat testfile |tr a-z A-Z
或
cat testfile |tr [:lower:] [:upper:]
缩减连续重复的字符成指定的单个字符:
python@xxx:~/test$ cat t
dddddddsssssdd
eeeeeeeeee
aaaaaaaaaaaaaa
vvvvvvvvvvvvvv
python@xxx:~/test$ cat t|tr -s 'se'
dddddddsdd
e
aaaaaaaaaaaaaa
vvvvvvvvvvvvvv
python@xxx:~/test$ cat t|tr -s 'sdeav'
dsd
e
a
v
删除指定的字符:
python@xxx:~/test$ cat t|tr -d 'dv'
sssss
eeeeeeeeee
aaaaaaaaaaaaaa
join - 文件按行连接
将两个文件中指定栏位相同的行连接起来。即按照两个文件中共同拥有的某一列,将对应的行拼接成一行。
注意:在使用join之前所处理的文件要事先经过排序。
$ cat testfile_1
Hello 95 #例如,本例中第一列为姓名,第二列为数额
Linux 85
test 30
cmd@hdd-desktop:~$ cat testfile_2
Hello 2005 #例如,本例中第一列为姓名,第二列为年份
Linux 2009
test 2006
使用join命令,将两个文件连接:
$ join testfile_1 testfile_2 #连接testfile_1、testfile_2中的内容
Hello 95 2005 #连接后显示的内容
Linux 85 2009
test 30 2006
两个文件互换,输出结果的变化:
$ join testfile_2 testfile_1 #改变文件顺序连接两个文件
Hello 2005 95 #连接后显示的内容
Linux 2009 85
test 2006 30
参数:
- -a<1或2> 除了显示原来的输出内容之外,还显示指令文件中没有相同栏位的行。
- -e<字符串> 若[文件1]与[文件2]中找不到指定的栏位,则在输出中填入选项中的字符串。
- -i或–igore-case 比较栏位内容时,忽略大小写的差异。
- -o<格式> 按照指定的格式来显示结果。
- -t<字符> 使用栏位的分隔字符。
- -v<1或2> 跟-a相同,但是只显示文件中没有相同栏位的行。
- -1<栏位> 连接[文件1]指定的栏位。
- -2<栏位> 连接[文件2]指定的栏位。
paste-将多个文件对应行链接在一起
paste 指令会把每个文件以列对列的方式,一列列地加以合并。
语法:
paste [-s][-d <间隔字符>][文件...]
参数:
- -d<间隔字符>或–delimiters=<间隔字符> 用指定的间隔字符取代跳格字符。
- -s或–serial 串列进行而非平行处理。
- [文件…] 指定操作的文件路径
使用paste指令将文件"file"、“testfile”、"testfile1"进行合并,输入如下命令:
$ cat file #file文件的内容
xiongdan 200
lihaihui 233
lymlrl 231
$ cat testfile #testfile文件的内容
liangyuanm ss
$ cat testfile1 #testfile1文件的内容
huanggai 56
zhixi 73
$ paste file testfile testfile1
xiongdan 200 liangyuanm ss huanggai 56
lihaihui 233 zhixi 73
lymlrl 231
$ paste -d ':' file testfile testfile1
xiongdan 200:liangyuanm ss:huanggai 56
lihaihui 233::zhixi 73
lymlrl 231::
参数"-s"可以将一个文件中的多行数据合并为一行进行显示:
$ paste -s file #合并指定文件的多行数据
xiongdan 200 lihaihui 233 lymlrl 231
如果将文件位置改为-,表示接收标准输入:
$ cat file |paste testfile1 -
huanggai 56 xiongdan 200
zhixi 73 lihaihui 233
lymlrl 231
split - 文件切割
split命令用于将一个文件分割成数个。
该指令将大文件分割成较小的文件,在默认情况下将按照每1000行切割成一个小文件。
语法:
split [-bl] file prefix
-b: 以大小切割
-l:以行数切割
prefix:切割后文件的前缀
参数说明:
- -<行数> : 指定每多少行切成一个小文件
- -b<字节> : 指定每多少字节切成一个小文件
- -C<字节> : 与参数"-b"相似,但是在切 割时将尽量维持每行的完整性
- [输出文件名] : 设置切割后文件的前置文件名, split会自动在前置文件名后再加上编号
使用指令"split"将文件"README"每6行切割成一个文件,输入如下命令:
$ split -6 README #将README文件每六行分割成一个文件
$ ls #执行ls指令
#获得当前目录结构
README xaa xad xag xab xae xah xac xaf xai
以上命令执行后,指令"split"会将原来的大文件"README"切割成多个以"x"开头的小文件。而在这些小文件中,每个文件都只有6行内容。
以大小切割:
$ ls -lh disease.dmp
-rwxr-xr-x 1 root root 122M Jul 4 2013 disease.dmp
$ split -b 50m disease.dmp disease.dmp
$ ls -lh disease.dmp*
-rwxr-xr-x 1 root root 122M Jul 4 2013 disease.dmp
-rw-r--r-- 1 root root 50M Jan 9 16:10 disease.dmpaa
-rw-r--r-- 1 root root 50M Jan 9 16:10 disease.dmpab
-rw-r--r-- 1 root root 22M Jan 9 16:10 disease.dmpac
xargs - 参数代换
不是所有的命令都支持管道,如ls,对于不支持管道的命令,可以通过xargs让其有管道命令的效果,如下所示:
# find /sbin -perm +7000 | xargs ls -l
-rwsr-x--- 1 root ecryptfs 19896 Feb 23 2012 /sbin/mount.ecryptfs_private
-rwsr-xr-x 1 root root 75496 Jan 9 2013 /sbin/mount.nfs
-rwsr-xr-x 1 root root 75504 Jan 9 2013 /sbin/mount.nfs4
-rwxr-sr-x 1 root root 8544 Feb 22 2012 /sbin/netreport
-rwsr-xr-x 1 root root 14112 Nov 2 2010 /sbin/pam_timestamp_check
-rwsr-xr-x 1 root root 75504 Jan 9 2013 /sbin/umount.nfs
-rwsr-xr-x 1 root root 75504 Jan 9 2013 /sbin/umount.nfs4
-rwsr-xr-x 1 root root 19768 Nov 2 2010 /sbin/unix_chkpwd
如果没有xargs,ls -l的结果将不是前面find的标准输出,因为ls不支持管道命令。
xargs 用作替换工具,读取输入数据重新格式化后输出。
定义一个测试文件,内有多行文本数据:
# cat test.txt
a b c d e f g
h i j k l m n
o p q
r s t
u v w x y z
多行输入单行输出:
# cat test.txt | xargs
a b c d e f g h i j k l m n o p q r s t u v w x y z
-n 选项多行输出:
# cat test.txt | xargs -n3
a b c
d e f
g h i
j k l
m n o
p q r
s t u
v w x
y z
-d 选项可以自定义一个定界符:
# echo "nameXnameXnameXname" | xargs -dX
name name name name
结合 -n 选项使用:
# echo "nameXnameXnameXname" | xargs -dX -n2
name name
name name
读取 stdin,将格式化后的参数传递给命令:
# cat sk.sh
#!/bin/bash
#sk.sh命令内容,打印出所有参数。
echo $*
# cat arg.txt
aaa
bbb
ccc
# cat arg.txt | xargs -I {} ./sk.sh -p {} -l
-p aaa -l
-p bbb -l
-p ccc -l
选项-I指定一个替换字符串 {},这个字符串在 xargs 扩展时会被替换掉。
复制所有图片文件到 /data/images 目录下:
ls *.jpg | xargs -n1 -I {} cp {} /data/images
选项-n 后面加次数,表示命令在执行的时候一次用的argument的个数,默认是用所有的。
xargs 结合 find 使用
用 rm 删除太多的文件时候,可能得到一个错误信息:/bin/rm Argument list too long. 用 xargs 去避免这个问题:
find . -type f -name "*.log" -print0 | xargs -0 rm -f
xargs -0 将 \0 作为定界符。
统计一个源代码目录中所有 php 文件的行数:
find . -type f -name "*.php" -print0 | xargs -0 wc -l
查找所有的 jpg 文件,并且压缩它们:
find . -type f -name "*.jpg" -print | xargs tar -czvf images.tar.gz
批量下载:
# cat url-list.txt | xargs wget -c
wget的-c选项表示断点续传。
linux命令练习
常用命令
1.进入到用户根目录
cd ~ 或 cd
2.查看当前所在目录
pwd
3.进入到hadoop用户根目录
cd ~hadoop
4.返回到原来目录
cd -
5.返回到上一级目录
cd ..
6.查看hadoop用户根目录下的所有文件
ls -la
7.在根目录下创建一个hadoop的文件夹
mkdir /hadoop
8.在/hadoop目录下创建src和WebRoot两个文件夹
分别创建:mkdir /hadoop/src
mkdir /hadoop/WebRoot
同时创建:mkdir /hadoop/{src,WebRoot}
进入到/hadoop目录,在该目录下创建.classpath和README文件
分别创建:touch .classpath
touch README
同时创建:touch {.classpath,README}
查看/hadoop目录下面的所有文件
ls -la
在/hadoop目录下面创建一个test.txt文件,同时写入内容"this is test"
echo "this is test" > test.txt
查看一下test.txt的内容
cat test.txt
more test.txt
less test.txt
向README文件追加写入"please read me first"
echo "please read me first" >> README
将test.txt的内容追加到README文件中
cat test.txt >> README
拷贝/hadoop目录下的所有文件到/hadoop-bak
cp -r /hadoop /hadoop-bak
进入到/hadoop-bak目录,将test.txt移动到src目录下,并修改文件名为Student.java
mv test.txt src/Student.java
在src目录下创建一个struts.xml
> struts.xml
删除所有的xml类型的文件
rm -rf *.xml
删除/hadoop-bak目录和下面的所有文件
rm -rf /hadoop-bak
返回到/hadoop目录,查看一下README文件有多单词,多少个少行
wc -w README
wc -l README
返回到根目录,将/hadoop目录先打包,再用gzip压缩
分步完成:tar -cvf hadoop.tar hadoop
gzip hadoop.tar
一步完成:tar -zcvf hadoop.tar.gz hadoop
将其解压缩,再取消打包
分步完成:gzip -d hadoop.tar.gz 或 gunzip hadoop.tar.gz
一步完成:tar -zxvf hadoop.tar.gz
将/hadoop目录先打包,同时用bzip2压缩,并保存到/tmp目录下
tar -jcvf /tmp/hadoop.tar.bz2 hadoop
将/tmp/hadoop.tar.bz2解压到/usr目录下面
tar -jxvf hadoop.tar.bz2 -C /usr/
系统命令
1.查看主机名
hostname
2.修改主机名(重启后无效)
hostname hadoop
3.修改主机名(重启后永久生效)
vi /ect/sysconfig/network
4.修改IP(重启后无效)
ifconfig eth0 192.168.12.22
5.修改IP(重启后永久生效)
vi /etc/sysconfig/network-scripts/ifcfg-eth0
6.查看系统信息
uname -a
uname -r
7.查看ID命令
id -u
id -g
8.日期
date
date +%Y-%m-%d
date +%T
date +%Y-%m-%d" "%T
9.日历
cal 2012
10.查看文件信息
file filename
11.挂载硬盘
mount
umount
加载windows共享
mount -t cifs //192.168.1.100/tools /mnt
12.查看文件大小
du -h
du -ah
13.查看分区
df -h
14.ssh
ssh hadoop@192.168.1.1
15.关机
shutdown -h now /init 0
shutdown -r now /reboot
用户和组
添加一个tom用户,设置它属于users组,并添加注释信息
分步完成:useradd tom
usermod -g users tom
usermod -c "hr tom" tom
一步完成:useradd -g users -c "hr tom" tom
设置tom用户的密码
passwd tom
修改tom用户的登陆名为tomcat
usermod -l tomcat tom
将tomcat添加到sys和root组中
usermod -G sys,root tomcat
查看tomcat的组信息
groups tomcat
添加一个jerry用户并设置密码
useradd jerry
passwd jerry
添加一个交america的组
groupadd america
将jerry添加到america组中
usermod -g america jerry
将tomcat用户从root组和sys组删除
gpasswd -d tomcat root
gpasswd -d tomcat sys
将america组名修改为am
groupmod -n am america
权限
创建a.txt和b.txt文件,将他们设为其拥有者和所在组可写入,但其他以外的人则不可写入:
chmod ug+w,o-w a.txt b.txt
创建c.txt文件所有人都可以写和执行
chmod a=wx c.txt 或chmod 666 c.txt
将/hadoop目录下的所有文件与子目录皆设为任何人可读取
chmod -R a+r /hadoop
将/hadoop目录下的所有文件与子目录的拥有者设为root,用户拥有组为users
chown -R root:users /hadoop
将当前目录下的所有文件与子目录的用户皆设为hadoop,组设为users
chown -R hadoop:users *
帮助文档
1.内部命令:echo
查看内部命令帮助:help echo 或者 man echo
2.外部命令:ls
查看外部命令帮助:ls --help 或者 man ls 或者 info ls
3.man文档的类型(1~9)
man 7 man
man 5 passwd
4.快捷键:
ctrl + c:停止进程
ctrl + l:清屏
ctrl + r:搜索历史命令
ctrl + q:退出
5.善于用tab键
文件相关命令
1.进入到用户根目录
cd ~ 或者 cd
cd ~hadoop
回到原来路径
cd -
2.查看文件详情
stat a.txt
3.移动
mv a.txt /ect/
改名
mv b.txt a.txt
移动并改名
mv a.txt ../b.txt
4拷贝并改名
cp a.txt /etc/b.txt
5.vi撤销修改
ctrl + u (undo)
恢复
ctrl + r (redo)
6.名令设置别名(重启后无效)
alias ll="ls -l"
取消
unalias ll
7.如果想让别名重启后仍然有效需要修改
vi ~/.bashrc
8.添加用户
useradd hadoop
passwd hadoop
9创建多个文件
touch a.txt b.txt
touch /home/{a.txt,b.txt}
10.将一个文件的内容复制到里另一个文件中
cat a.txt > b.txt
追加内容
cat a.txt >> b.txt
11.将a.txt 与b.txt设为其拥有者和其所属同一个组者可写入,但其他以外的人则不可写入:
chmod ug+w,o-w a.txt b.txt
chmod a=wx c.txt
12.将当前目录下的所有文件与子目录皆设为任何人可读取:
chmod -R a+r *
13.将a.txt的用户拥有者设为users,组的拥有者设为jessie:
chown users:jessie a.txt
14.将当前目录下的所有文件与子目录的用户的使用者为lamport,组拥有者皆设为users,
chown -R lamport:users *
15.将所有的java语言程式拷贝至finished子目录中:
cp *.java finished
16.将目前目录及其子目录下所有扩展名是java的文件列出来。
find -name "*.java"
查找当前目录下扩展名是java 的文件
find -name *.java
17.删除当前目录下扩展名是java的文件
rm -f *.java
VIM
i
a/A
o/O
r + ?替换
0:文件当前行的开头
$:文件当前行的末尾
G:文件的最后一行开头
1 + G到第一行
9 + G到第九行 = :9
dd:删除一行
3dd:删除3行
yy:复制一行
3yy:复制3行
p:粘贴
u:undo
ctrl + r:redo
"a剪切板a
"b剪切板b
"ap粘贴剪切板a的内容
每次进入vi就有行号
vi ~/.vimrc
set nu
:w a.txt另存为
:w >> a.txt内容追加到a.txt
:e!恢复到最初状态
:1,$s/hadoop/root/g 将第一行到追后一行的hadoop替换为root
:1,$s/hadoop/root/c 将第一行到追后一行的hadoop替换为root(有提示)
查找
1.查找可执行的命令:
which ls
2.查找可执行的命令和帮助的位置:
whereis ls
3.查找文件(需要更新库:updatedb)
locate hadoop.txt
4.从某个文件夹开始查找
find / -name "hadooop*"
find / -name "hadooop*" -ls
5.查找并删除
find / -name "hadooop*" -ok rm {} \;
find / -name "hadooop*" -exec rm {} \;
6.查找用户为hadoop的文件
find /usr -user hadoop -ls
7.查找用户为hadoop并且(-a)拥有组为root的文件
find /usr -user hadoop -a -group root -ls
8.查找用户为hadoop或者(-o)拥有组为root并且是文件夹类型的文件
find /usr -user hadoop -o -group root -a -type d
9.查找权限为777的文件
find / -perm -777 -type d -ls
10.显示命令历史
history
11.grep
grep hadoop /etc/password
打包与压缩
1.gzip压缩
gzip a.txt
2.解压
gunzip a.txt.gz
gzip -d a.txt.gz
3.bzip2压缩
bzip2 a
4.解压
bunzip2 a.bz2
bzip2 -d a.bz2
5.将当前目录的文件打包
tar -cvf bak.tar .
将/etc/password追加文件到bak.tar中(r)
tar -rvf bak.tar /etc/password
6.解压
tar -xvf bak.tar
7.打包并压缩gzip
tar -zcvf a.tar.gz
8.解压缩
tar -zxvf a.tar.gz
解压到/usr/下
tar -zxvf a.tar.gz -C /usr
9.查看压缩包内容
tar -ztvf a.tar.gz
zip/unzip
10.打包并压缩成bz2
tar -jcvf a.tar.bz2
11.解压bz2
tar -jxvf a.tar.bz2
正则表达式
规则:
. : 任意一个字符
a* : 任意多个a(零个或多个a)
a? : 零个或一个a
a+ : 一个或多个a
.* : 任意多个任意字符
\. : 转义.
\<h.*p\> :以h开头,p结尾的一个单词
o\{2\} : o重复两次
grep '^i.\{18\}n$' /usr/share/dict/words
查找不是以#开头的行
grep -v '^#' a.txt | grep -v '^$'
以h或r开头的
grep '^[hr]' /etc/passwd
不是以h和r开头的
grep '^[^hr]' /etc/passwd
不是以h到r开头的
grep '^[^h-r]' /etc/passwd
输入输出重定向
1.新建一个文件
touch a.txt
> b.txt
2.错误重定向:2>
find /etc -name zhaoxing.txt 2> error.txt
3.将正确或错误的信息都输入到log.txt中
find /etc -name passwd > /tmp/log.txt 2>&1
find /etc -name passwd &> /tmp/log.txt
4.追加>>
5.将小写转为大写(输入重定向)
tr "a-z" "A-Z" < /etc/passwd
6.自动创建文件
cat > log.txt << EXIT
> ccc
> ddd
> EXI
7.查看/etc下的文件有多少个?
ls -l /etc/ | grep '^d' | wc -l
8.查看/etc下的文件有多少个,并将文件详情输入到result.txt中
ls -l /etc/ | grep '^d' | tee result.txt | wc -l
进程控制
1.查看用户最近登录情况
last
lastlog
2.查看硬盘使用情况
df
3.查看文件大小
du
4.查看内存使用情况
free
5.查看文件系统
/proc
6.查看日志
ls /var/log/
7.查看系统报错日志
tail /var/log/messages
8.查看进程
top
9.结束进程
kill 1234
kill -9 4333
其他命令
远程文件复制:scp
scp 命令用于 Linux 之间复制文件和目录,scp是 secure copy 的缩写是linux系统下基于ssh登陆进行安全的远程文件拷贝命令。
scp 是加密的,rcp 是不加密的,scp 是 rcp 的加强版。
使用scp命令要确保使用的用户具有可读取远程服务器相应文件的权限,否则scp命令是无法起作用的。
从本地复制到远程命令格式:
复制文件
scp local_file remote_username@remote_ip:remote_folder
或者
scp local_file remote_username@remote_ip:remote_file
或者
scp local_file remote_ip:remote_folder
或者
scp local_file remote_ip:remote_file
复制文件夹
scp -r local_folder remote_username@remote_ip:remote_folder
或者
scp -r local_folder remote_ip:remote_folder
实例:
scp /home/space/music/1.mp3 root@xiaoxiaoming.xyz:/home/root/others/music
scp /home/space/music/1.mp3 root@xiaoxiaoming.xyz:/home/root/others/music/001.mp3
scp /home/space/music/1.mp3 xiaoxiaoming.xyz:/home/root/others/music
scp /home/space/music/1.mp3 xiaoxiaoming.xyz:/home/root/others/music/001.mp3
scp -r /home/space/music/ root@xiaoxiaoming.xyz:/home/root/others/
scp -r /home/space/music/ xiaoxiaoming.xyz:/home/root/others/
从远程复制到本地:
scp root@xiaoxiaoming.xyz:/home/root/others/music /home/space/music/1.mp3
scp -r xiaoxiaoming.xyz:/home/root/others/ /home/space/music/
-P 参数来设置命令的端口号:
#scp 命令使用端口号 4588
scp -P 4588 remote@xiaoxiaoming.xyz:/usr/local/sin.sh /home/administrator
locate查找
locate命令会去保存文档和目录名称的数据库内,查找文件或目录。
一般情况我们只需要输入locate your_file_name 即可查找指定文件。
参数:
- -d或–database= 配置locate指令使用的数据库。locate指令预设的数据库位于/var/lib/mlocate目录里,文档名为mlocate.db。
查找passwd文件,输入以下命令:
locate passwd
locate与find的区别: find 是去硬盘找,locate 只在/var/lib/slocate资料库中找。
locate的速度比find快,它并不是真的查找,而是查数据库,一般文件数据库在/var/lib/mlocate/mlocate.db中,所以locate的查找并不是实时的,而是以数据库的更新为准,一般是系统自己维护,也可以手工升级数据库 ,命令为:
updatedb
which命令
which查找$PATH中设置命令及安装文件目录所在位置
python@ubuntu:/var/lib/mlocate$ which locate
/usr/bin/locate
echo
常见用法:
python@ubuntu:~$ echo -e "hello\t\t world!" 解析转义字符
hello world!
python@ubuntu:~$ echo -E "hello\t\t world!" 不解析转义字符
hello\t\t world!
python@ubuntu:~$ echo $a 输出环境变量
b
设置或显示环境变量:export
在 shell 中执行程序时,shell 会提供一组环境变量。export 可新增,修改或删除环境变量,供后续执行的程序使用。export 的效力仅限于该次登陆操作。
export [-fnp][变量名称]=[变量设置值]
参数说明:
- -f 代表[变量名称]中为函数名称。
- -n 删除指定的变量。变量实际上并未删除,只是不会输出到后续指令的执行环境中。
- -p 列出所有的shell赋予程序的环境变量。
# export MYENV=7 //定义环境变量并赋值
# export -p //列出当前的环境变量
修改主机名&ip地址
显示主机名:hostname
临时修改:hostname xxx
永久修改
对于Ubuntu 系统
vim /etc/hostname
对于centos系统
vim /etc/sysconfig/network
在此配置文件中添加一条HOSTNAME=node1
针对centos7系统,可以使用如下命令
hostnamectl set-hostname xxx
一般需要重开shell甚至重启操作系统才能生效。
修改IP地址
ifconfig eth0 192.168.12.22(重启后无效)
vim /etc/sysconfig/network-scripts/ifcfg-eth0
mount挂载
mount 挂载外部存储设备到文件系统中
mkdir /mnt/cdrom 创建一个目录,用来挂载
mount -t iso9660 -o ro /dev/cdrom /mnt/cdrom/
将设备/dev/cdrom挂载到 挂载点 : /mnt/cdrom中
umount /mnt/cdrom
ssh免密登陆
假如 A 要登陆 B
在A上操作:
首先生成密钥对
ssh-keygen (提示时,直接回车即可)
再将A自己的公钥拷贝并追加到B的授权列表文件authorized_keys中
ssh-copy-id B
批量添加用户
与用户账号有关的系统文件
完成用户管理的工作本质都是对有关的系统文件进行修改,这些系统文件包括/etc/passwd,/etc/shadow,/etc/group等。
/etc/passwd记录用户的基本属性
它的内容类似下面的例子:
# cat /etc/passwd
root:x:0:0:Superuser:/:
daemon:x:1:1:System daemons:/etc:
bin:x:2:2:Owner of system commands:/bin:
sys:x:3:3:Owner of system files:/usr/sys:
adm:x:4:4:System accounting:/usr/adm:
uucp:x:5:5:UUCP administrator:/usr/lib/uucp:
auth:x:7:21:Authentication administrator:/tcb/files/auth:
cron:x:9:16:Cron daemon:/usr/spool/cron:
listen:x:37:4:Network daemon:/usr/net/nls:
lp:x:71:18:Printer administrator:/usr/spool/lp:
sam:x:200:50:Sam san:/home/sam:/bin/sh
/etc/passwd中一行记录对应着一个用户,每行记录又被冒号(:)分隔为7个字段,其格式和具体含义如下:
用户名:口令:用户标识号:组标识号:注释性描述:主目录:登录Shell
用户名:
通常长度不超过8个字符,由大小写字母和/或数字组成,不能有冒号(
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。