
最近发现在宝塔的日志下看到很多垃圾支柱来爬行,这些垃圾蜘蛛爬行的日志很干扰我对于日志数据的查阅,今天查询了下关于宝塔面板下nginx屏蔽垃圾蜘蛛禁止抓取不影响火车头发布的方法,分享给大家去做下学习。希望对你服务器使用宝塔面板管理有一定的帮助;
最近查看服务器日志,发现一些垃圾蜘蛛,一直爬行很多,比如以下这些垃圾,太烦人了。
Mozilla/5.0 (compatible; SemrushBot/6~bl; +http://www.semrush.com/bot.html) Mozilla/5.0 (compatible; AhrefsBot/6.1; +http://ahrefs.com/robot/)
本人一直使用的linux系统服务器宝塔面板管理,个人感觉比较方便。网上查找方法,屏蔽这些垃圾。
网上找到的代码如下:目前为止比较好用。
#禁止Scrapy等工具的抓取
if ($http_user_agent ~* (Scrapy|Curl|HttpClient)) {
return 403;
}
#禁止指定UA及UA为空的访问
if ($http_user_agent ~* FeedDemon|Indy Library|Alexa Toolbar|AskTbFXTV|AhrefsBot|CrawlDaddy|CoolpadWebkit|Java|Feedly|UniversalFeedParser|ApacheBench|Microsoft URL Control|Swiftbot|ZmEu|oBot|jaunty|Python-urllib|lightDeckReports Bot|YYSpider|DigExt|HttpClient|MJ12bot|heritrix|Bytespider|Ezooms|Googlebot|JikeSpider|SemrushBot|^$ ) {
return 403;
}
#禁止非GET|HEAD|POST方式的抓取
if ($request_method !~ ^(GET|HEAD|POST)$) {
return 403;
}宝塔面板下使用方法如下:
1、找到文件目录/www/server/nginx/conf文件夹下面,新建一个文件
agent_deny.conf
内容就是以上代码。
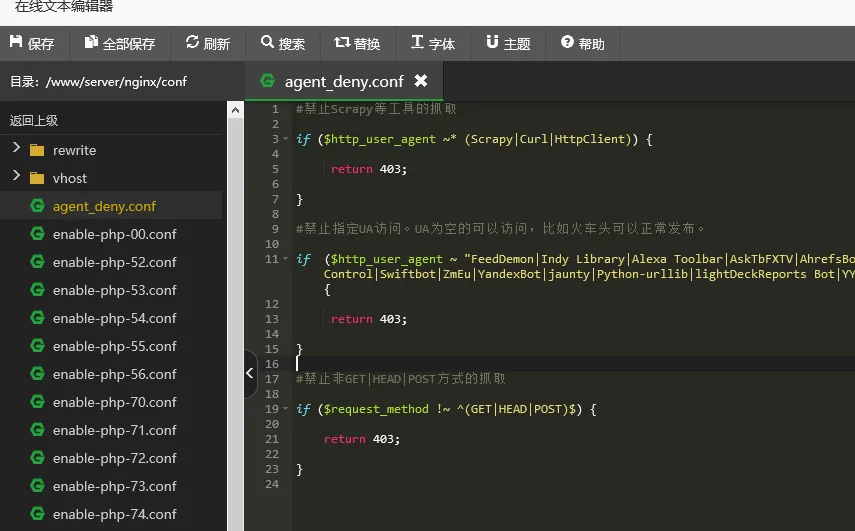
2.找到网站设置里面的第7行左右 写入代码: include agent_deny.conf;
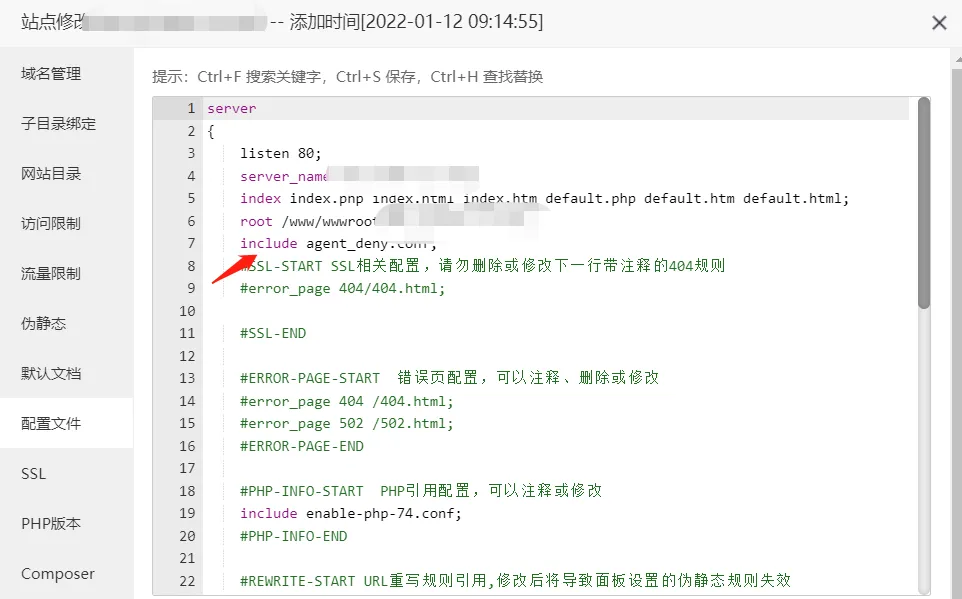
如果你网站使用火车头采集发布,使用以上代码会返回403错误,发布不了的。如果想使用火车头采集发布,请使用下面的代码
#禁止Scrapy等工具的抓取
if ($http_user_agent ~* (Scrapy|Curl|HttpClient)) {
return 403;
}
#禁止指定UA访问。UA为空的可以访问,比如火车头可以正常发布。
if ($http_user_agent ~ FeedDemon|Indy Library|Alexa Toolbar|AskTbFXTV|AhrefsBot|CrawlDaddy|CoolpadWebkit|Java|Feedly|UniversalFeedParser|ApacheBench|Microsoft URL Control|Swiftbot|ZmEu|YandexBot|jaunty|Python-urllib|lightDeckReports Bot|YYSpider|DigExt|HttpClient|MJ12bot|heritrix|Bytespider|Ezooms|Googlebot|JikeSpider|SemrushBot ) {
return 403;
}
#禁止非GET|HEAD|POST方式的抓取
if ($request_method !~ ^(GET|HEAD|POST)$) {
return 403;
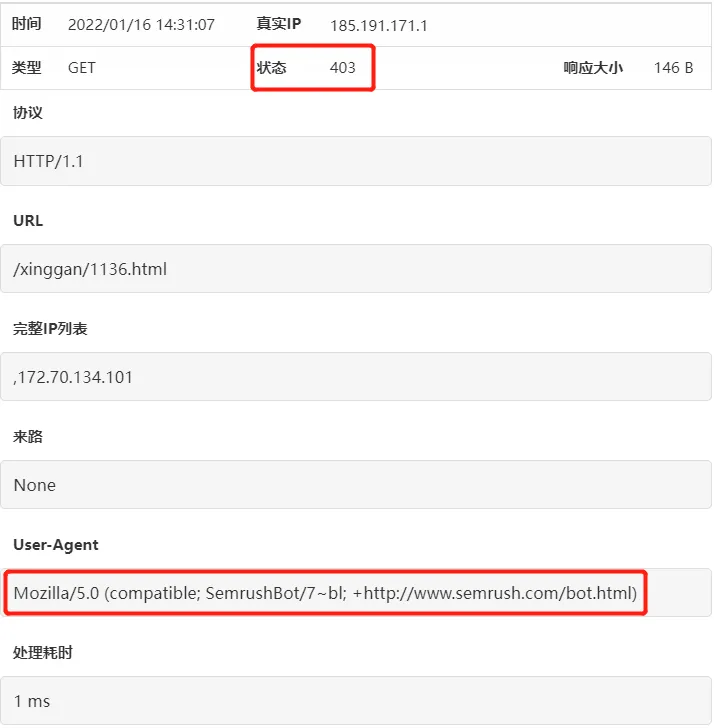
}最后重启重启nginx,就可以在网站日志里看到防御效果了。
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。