
本篇内容介绍了“Apache Spark的Lambda架构示例分析”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
Apache Hadoop简史

Apache Hadoop由 Apache Software Foundation 公司于 2005 年秋天作为Lucene的子项目Nutch的一部分正式引入。它受到***由 Google Lab 开发的 Map/Reduce 和 Google File System(GFS) 的启发。它成为一个独立项目的时间已有10年。
目前已经有很多客户实施了基于Hadoop的M / R管道,并成功运行到现在:
Oozie的工作流每日运行处理150TB以上的数据并生成分析报告
Bash的工作流每日运行处理8TB以上的数据并生成分析报告
2016年来了!
2016年商业现实发生了变化,越快做出决策往往价值就会越大。另外,技术本身也在发展,Kafka,Storm,Trident,Samza,Spark,Flink,Parquet,Avro,云提供商等都成为了工程师们的流行语。
因此,现代基于Hadoop的M / R管道可能会是下图所示的这样:
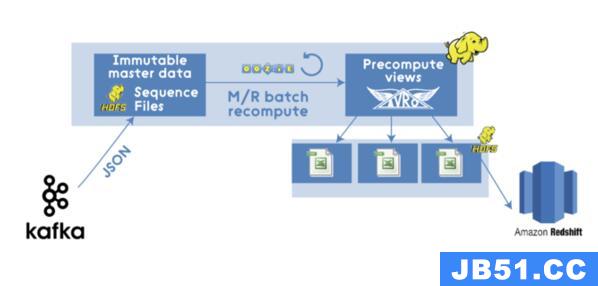
图上的M/R通道看起来不错,但其实它本质上还是一个传统的批处理,有着传统批处理的缺点,当新的数据源源不断的进入系统中时,还是需要大量的时间来处理。
Lambda 架构
针对上面的问题,Nathan Marz提出了一个通用、可扩展和容错性强的数据处理架构即Lambda架构,它是通过利用批处理和流处理方法来处理大量数据的。Nathan Marz的书对从源码的角度对Lambda架构进行了详尽的介绍。
层结构
这是Lambda架构自上而下的层结构:
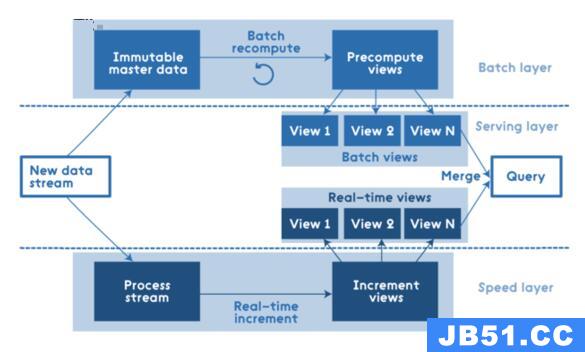
所有数据进入系统后都分派到批处理层和速度层进行处理。批处理层管理主数据集(一个不可变的,只可增加的原始数据集),并预先计算批处理视图。 服务层对批视图进行索引,以便可以进行低延迟的临时查询。 速度层仅处理最近的数据。所有的查询结果都必须合并批处理视图和实时视图的查询结果。
要点
许多工程师认为Lambda架构就只包含层结构和定义数据流程,但是Nathan Marz的书中为我们介绍了其它几个比较重要的点:
分布式思想
避免增量结构
数据的不变性
创建重新计算算法
数据的相关性
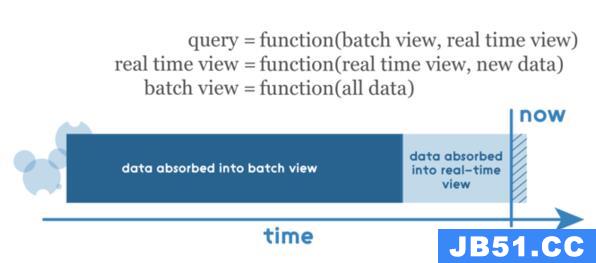
如前所述,任何查询结果都必须通过合并来自批处理视图和实时视图的结果,因此这些视图必须是可合并的。在这里要注意的一点是,实时视图是前一个实时视图和新数据增量的函数,因此这里使用增量算法,批处理视图是所有数据的函数,因此应该使用重新计算算法。
权衡
世间万物都是在不断妥协和权衡中发展的,Lambda结构也不例外。通常,我们需要解决几个主要的权衡:
完全重新计算 vs.部分重新计算
在有些情况下,可以使用Bloom过滤器来避免完全重新计算
重计算算法 vs. 增量算法
增量算法其实很具吸引力,但是有时根据指南,我们必须使用重计算算法,即便它很难得到相同的结果
加法算法 vs. 近似算法
虽然Lambda架构能够与加法算法很好地协同工作,但是在有些情况下更适合使用近似算法,例如使用HyperLogLog处理count-distinct问题。
实现
实现Lambda架构的方法有很多,因为每个层的底层解决方案是独立的。每个层需要底层实现的特定功能,有助于做出更好的选择并避免过度决策:
批量层:一次写入,批量读取多次
服务层:支持随机读取但不支持随机写入; 批量计算和批量写入
速度层:随机读写; 增量计算
例如,其中一个实现(使用Kafka,Apache Hadoop,Voldemort,Twitter Storm,Cassandra)可能如下所示:

Apache Spark
Apache Spark被视为在所有Lambda架构层上进行处理的集成解决方案。 其中Spark Core包含了高级API和支持常规执行图的优化引擎,SparkSQL用于SQL和结构化数据处理,Spark Streaming支持实时数据流的可扩展,高吞吐量,容错流处理。 当然,使用Spark进行批处理的价格可能比较高,而且也不是所有的场景和数据都适合。但是,总体来说Apache Spark是对Lambda架构的合理实现。
示例应用
我们创建一个示例应用程序来演示Lambda架构。这个示例的主要目的统计从某个时刻到现在此刻的#morningatlohika tweets哈希标签。
批处理视图
为了简单起见,假设我们的主数据集包含自时间开始以来的所有tweets。 此外,我们实现了一个批处理,创建了我们的业务目标所需的批处理视图,因此我们有一个预计算的批处理视图,其中包含与#morningatlohika一起使用的所有主题标记的统计信息:

因为数字方便记忆,所以我使用对应标签的英文单词的字母数目作为编号。
实时视图
当应用程序启动并运行时,有人发出了如下的tweet:

在这种情况下,正确的实时视图应包含以下标签及其统计信息(在我们的示例中为1,因为相应的hash标签只使用了一次):

查询
当终端用户查询hash标签的统计结果时,我们只需要将批量视图与实时视图合并起来。 所以输出应该如下所示:

场景
示例场景的简化步骤如下:
通过Apache Spark创建批处理视图(.parquet)
在Apache Spark中缓存批处理视图
流应用程序连接到Twitter
实时监控#morningatlohika tweets
构建增量实时视图
查询,即合并批处理视图和实时视图
技术细节
源代码基于Apache Spark 1.6.x,(在引入结构化流之前)。 Spark Streaming架构是纯微型批处理架构:
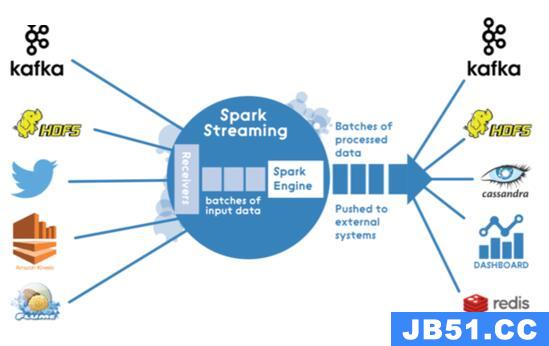
所以处理流应用程序时,我使用DStream连接使用TwitterUtils的Twitter:

在每个微批次(使用可配置的批处理间隔),对新的tweets中hashtags的统计信息的计算,并使用updateStateByKey()状态转换函数更新实时视图的状态。 为了简单起见,使用临时表将实时视图存储在存储器中。
查询服务反映批处理和实时视图的合并:

输出
文章开头提到的基于Hadoop的M/R管道使用Apache Spark来优化:

后记:
正如之前提到的Lambda Architecture有其优点和缺点,所以支持者和反对者都有。 有些人说批处理视图和实时视图有很多重复的逻辑,因为最终他们需要从查询角度创建可合并的视图。 所以他们创建了一个Kappa架构,并称其为Lambda架构的简化版。 Kappa架构系统是删除了批处理系统,取而代之的是通过流系统快速提供数据:
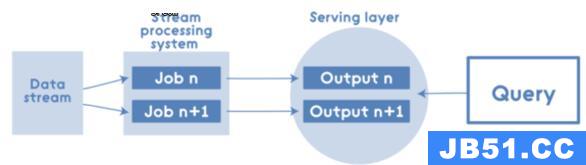
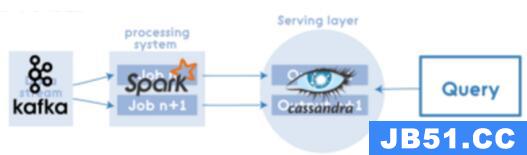
但即使在这种情况下,Kappa Architecture中也可以应用Apache Spark,例如流处理系统:
“Apache Spark的Lambda架构示例分析”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注编程之家网站,小编将为大家输出更多高质量的实用文章!
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。