怎么通过准入控制驯服Apache Impala用户,很多新手对此不是很清楚,为了帮助大家解决这个难题,下面小编将为大家详细讲解,有这方面需求的人可以来学习下,希望你能有所收获。
Apache Impala遇到的一个常见问题是资源管理。每个人都想使用尽可能多的资源(即内存)来尝试提高速度和/或隐藏查询效率低下的情况。但是,这对其他人不公平,并且可能不利于支持重要业务流程的查询。我们在许多客户那里看到的是,在重新构建集群并开始使用初始用例时,会有大量资源。在继续添加更多用例,数据科学家和运行即席查询的业务部门之前,这些资源会消耗足够的资源以防止那些原始用例按时完成,因此无需担心资源。这会导致查询失败,这可能使用户感到沮丧,并给现有使用案例带来问题。为了有效地管理Apache Impala的资源,我们建议使用
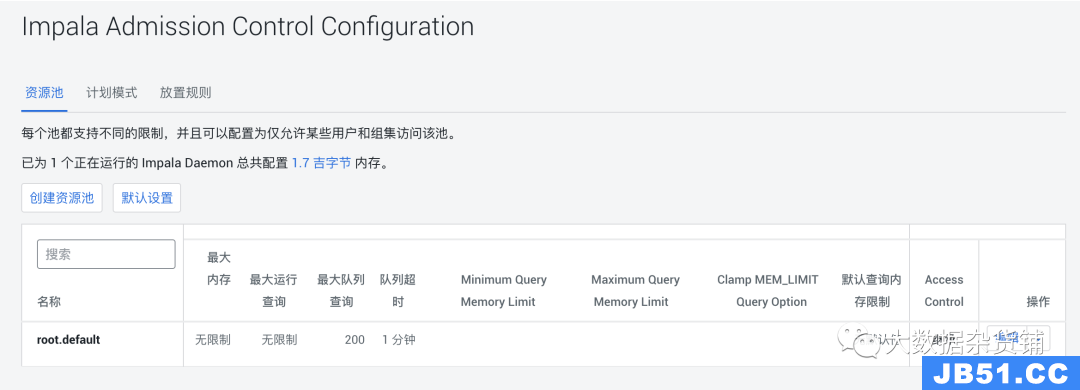
准入控制 功能。借助Admission Control,我们可以为Impala设置资源池。这意味着限制查询的数量,内存的数量,并为资源池中的每个查询强制设置。准入控制的设置很多,一开始可能令人生畏。我们将专注于内存设置,这些内存设置对于已经有数十个活动用户和应用程序运行的集群而言至关重要。准入控制的第一个挑战是手动收集有关单个用户及其运行的查询的指标,以尝试定义资源池的内存设置。
您可以在Cloudera Manager中手动使用Apache Impala查询窗口和图表构建器
来遍历每个用户的查询以收集一些统计信息,但是在以后进行重新评估非常耗时且乏味。
为了对如何为各种用户和应用程序分配资源做出明智而准确的决定,我们需要收集详细的指标。
我们已经编写了Python脚本来简化此过程。
该脚本可以在GitHub上找到:https://github.com/phdata/blog-2019-10-impala-admcontrol 该脚本会生成一个csv报告,并且不会进行任何更改。请查看Readme文件并在您的环境中运行脚本。csv报告包含以下方面的总体统计信息和每个用户的统计信息:• (queries_count_missing_stats)–不带统计信息运行的查询数• (aggregate_avg_gb)–节点间使用的平均内存• (aggregate_99th_gb)–跨节点使用的最大内存为99%• (aggregate_max_gb)–跨节点使用的最大内存• (per_node_avg_gb)–每个节点使用的平均内存• (per_node_99th_gb)–每个节点使用的最大内存为99%• (per_node_max_gb)–每个节点使用的最大内存• (duration_avg_minutes)–平均查询持续时间(以分钟为单位)• (duration_99th_minutes)– 99%的查询持续时间(以分钟为单位)• (duration_max_minutes)–最大查询持续时间(以分钟为单位)每个集群上的每个工作负载都将有所不同,并且具有广泛的要求。
在浏览报告时,有一些高优先级项需要寻找。
(
count_missing_stats
字段
)如果您看到查询在运行时没有统计信息,建议您调查哪些表缺少统计信息,并确保计算统计信息是您环境中的标准过程。在第99列中,我们尝试说明其大部分查询(占99%)。如果最大列中的任何一个比第99个高出10-20%以上,这将使我们能够解决错误或错误的查询,调查用户的最高查询以查看它们是否为错误查询,或者是否可以将这几个查询改进为更好地利用资源。• aggregate_max到aggregate_99th• per_node_max至per_node_99th• duration_max至duration_99th步骤
3
:
APACHE IMPALA
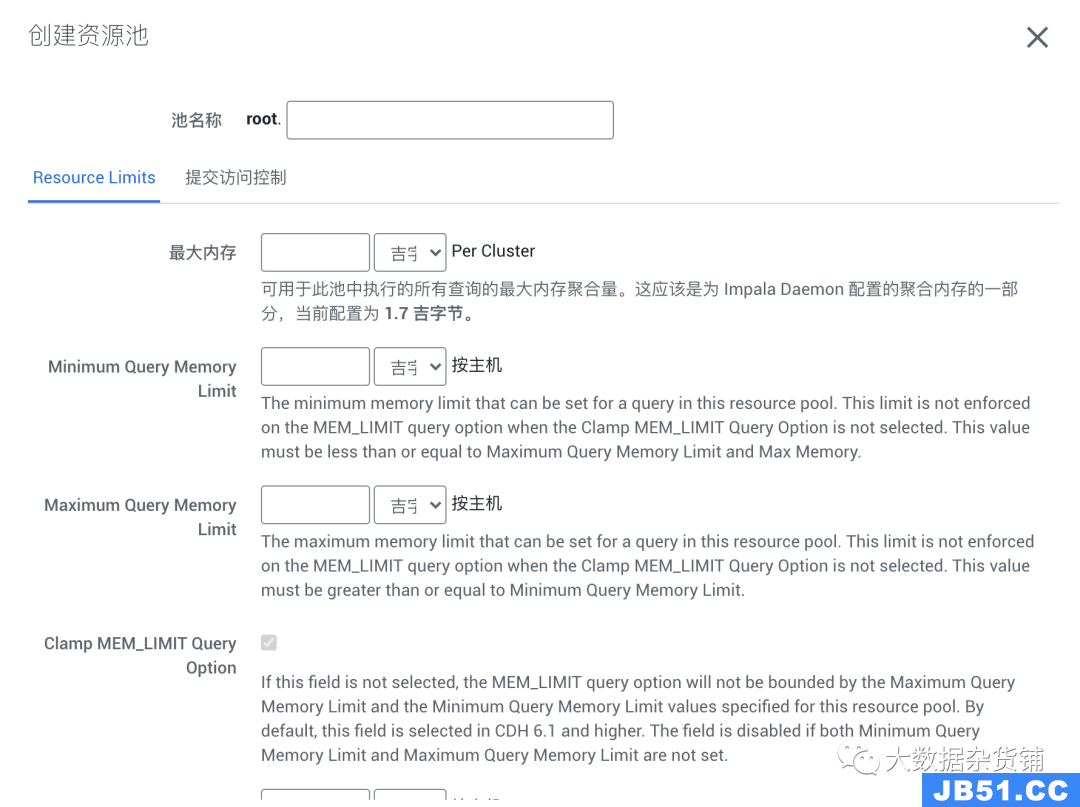
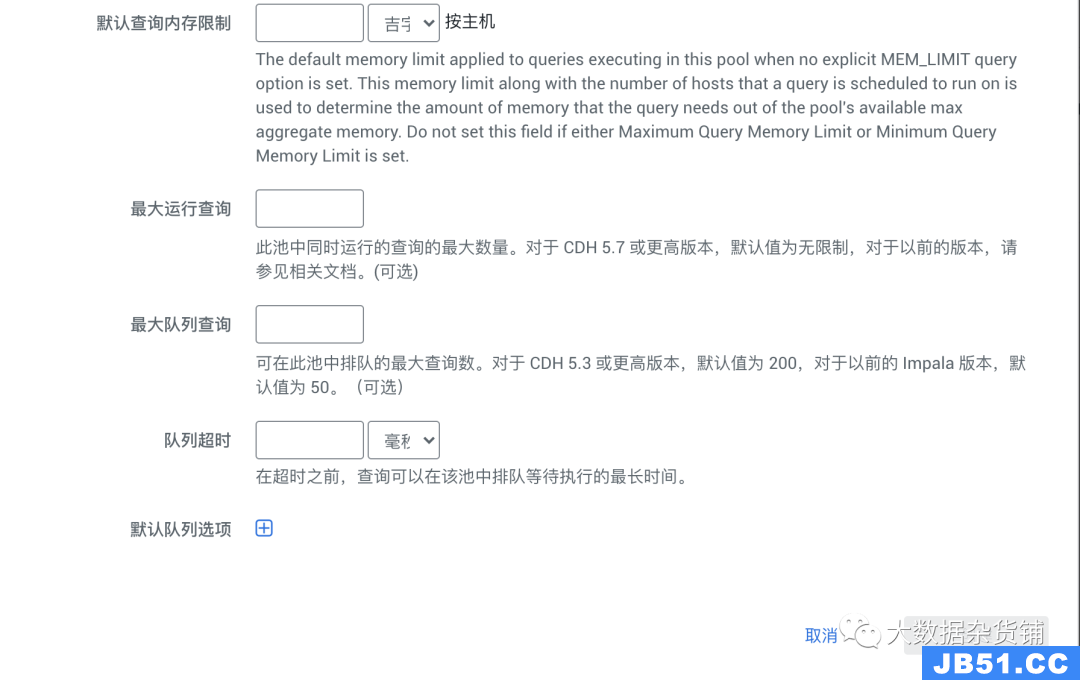
中的资源池设置我们将逐步指导您如何确定必要资源池的每个设置。确定后,我们将使用CM中的“创建资源池”向导来创建每个池,如下图所示。为了真正衡量这一点,我们需要有一个单独的报告,该报告记录了查询的开始时间和持续时间,以跟踪每个用户的平均、第99个百分位数和最大并发性。对于此设置,我们建议您根据用例将其保持在尽可能低的水平,因为它最终会影响您希望该用户或一组用户能够使用的最大内存。为简单起见,对于排队查询的数量,我们将其设置为为最大运行查询设置的数量。这是我们要为每个节点查询的最大内存量。此设置最安全的输入是我们报告中的per_node_max列。例外情况是,如果您调查了用户的最高内存使用情况查询,并发现per_node_99th可以更好地表示用户的良好查询,则请使用per_node_99th。这是根据(默认查询内存限制* 20(Impala主机数)*最大运行查询数)计算得出的。例如,如果我们希望资源池每个节点的查询限制为最大4GiB,并且一次能够运行5个查询,那么最大内存为400GiB。此设置由并发性,持续时间和查询的SLA决定。如果查询必须在30秒内运行,并且查询已调整为在20秒内运行,则查询在队列中停留的时间超过10秒,将违反SLA。针对Apache Impala运行的第三方应用程序可能会有自己的查询超时,这可能会干扰我们希望返回立即错误的情况。对于长期运行的ETL工作负载,这些工作负载可能最终导致数据偏斜增加查询持续时间,您可以延长这些超时时间以确保所有查询都已排队并运行。像Cloudera的“ 准入控制示 例 方案 ” 一样, 我们的集群有20个节点,每个节点上的Impala内存为128gb(Impala总计2560 GiB)。马上,我们可以看到需要跟进三个用户(svc_account3,user1和user4),以查看他们的内存状态是否可以通过计算状态得到改善,或者他们的几个查询编写得很差。我们还应该研究svc_account1,因为它们的_99th和_max数字相距甚远。用户的默认资源池:这是我们的通用池,适用于平台上没有合理用例的其他资源的任何人。我们预留了25%的集群资源。服务帐户的默认资源池:这是用于由应用程序或计划的进程生成的标准工作负载的常规资源池。超级用户资源池:这是需要更多资源的用户的资源池。user3可能是唯一符合Power Users资源池条件的用户。svc_account2
资源池:在服务帐户中,这是我们发现的唯一一个真正需要专用资源池的帐户。我们建议为每个服务帐户创建专用的资源池,以确保资源受到保护,不会被标准用户使用。实施准入控制的防护栏后,我们的客户在工作负载中将具有更高的可靠性和一致性。但是,需要一些照顾和喂养。在某些情况下,新的用例会经历一个过程,即需要请求并证明超出默认值之外的资源。提醒一下,每个集群上的每个工作负载都是唯一的,要完全实施准入控制,可能需要反复试验。看完上述内容是否对您有帮助呢?如果还想对相关知识有进一步的了解或阅读更多相关文章,请关注编程之家行业资讯频道,感谢您对编程之家的支持。
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。