Apache Flink 误用的是示例分析,针对这个问题,这篇文章详细介绍了相对应的分析和解答,希望可以帮助更多想解决这个问题的小伙伴找到更简单易行的方法。
摘要: 下面根据 Flink Forward 全球在线会议 · 中文精华版整理而成, 围绕着项目的 开始、需求分析、开发, 以及测试、上线、运维整个生命周期展开,介绍了 Apache Flink 实践中的一些典型误用情况,并给出了相应的更优实践方案。 Flink 实践中最首当其冲的误用就是不按迭代开发的过程操作。 在开始开发前,我们需要选择正确的切入方式,以下几种往往是最糟糕的开始: a) 从一个具有挑战性的用例开始(端对端的 Exactly-once、大状态、复杂的业务逻辑、强实时SLA的组合)
b) 之前没有流处理经验
c) 不对团队做相关的培训
d) 不利用社区
在开发的过程中,其实要认认真真的来规划我们的切入点,首先,要从简单的任务开始循序渐进。要有一定的大数据和流处理的知识积累,尽量参加一些培训,也要利用好社区资源。基于这样的想法,我们就能很快找到切入点。怎么样去做?社区提供了很多的培训,包括 Flink Forward 和 Vererica 网站上有各种培训课程,大家可以去看。同时,可以充分利用社区。社区还建立了中文的邮件列表,大家可以充分利用中文邮件列表来解决手头的疑难杂症。另外,Stack Overflow 也是个提问的好地方,但在提问前尽量去看一看已有的提问,做到心中有数。
方案设计中的一些常见错误思维,往往是由于没有充分思考需求导致的,比如: a) 不考虑数据一致性和交付保证
b) 不考虑业务升级和应用改进
c) 不考虑业务规模问题
d) 不深入思考实际业务需求
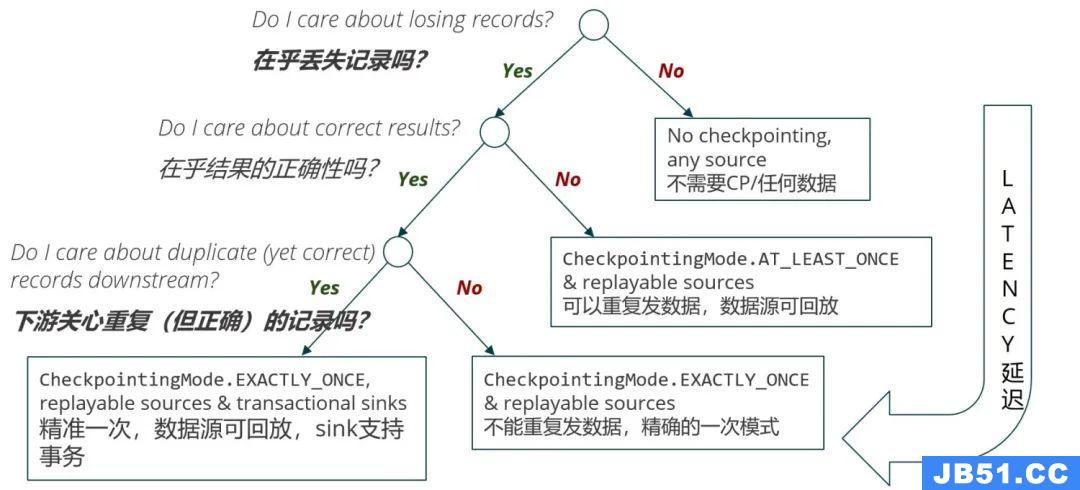
我们要认真分析需求,同时认真考虑实际交付情况。提到一致性和交付保障,其实可以通过几个问题来引导大家完成这件事,如下图所示: 在很多的场景里面,我们非常关注结果的正确性,比如金融领域,但是另外一些场景比如监控或其他简单的使用场景仅需要一个概要的数据统计。如果不在乎结果的正确性,
可以考虑用 at-least-once 的模式配置并使用可回放的数据源。相反,如果
结果的准确性十分重要,且下游不关心重复记录,那么仅需设置 exactly-once 模式并使用可回放的数据源。
如果下游要求数据不能重复,哪怕数据正确也只能发送一次,这种时候就对 sink 有更进一步的限制,在 exactly-once 的模式下,使用可回放的数据源,并且 sink 需要支持事务。带着这样的思维方式分析业务,才能非常清晰地知道,怎么去使用 Flink,进而避免一些糟糕的事情发生。完成分析之后,最终目的是什么?
我们为什么要有这种选择,而不是一上来就选一个最好的方案? 因为世界上永远没有“最好”,这里的核心因素就是延迟,要根据业务的延迟和准确性需求来均衡去做选择。当需求都分析好之后,还需要去思考应用是否需要升级。从一个正常的 Flink 作业来讲,我们有几个问题要考虑。第一个,Flink 作业一般都有状态读取,做升级时需要有 savepoint 机制来保障,将状态存储保留在远端,再恢复到新的作业上去。很多场景下都会有升级的需求,这简单列了几点:a 升级集群版本
b 业务 bug 的修复
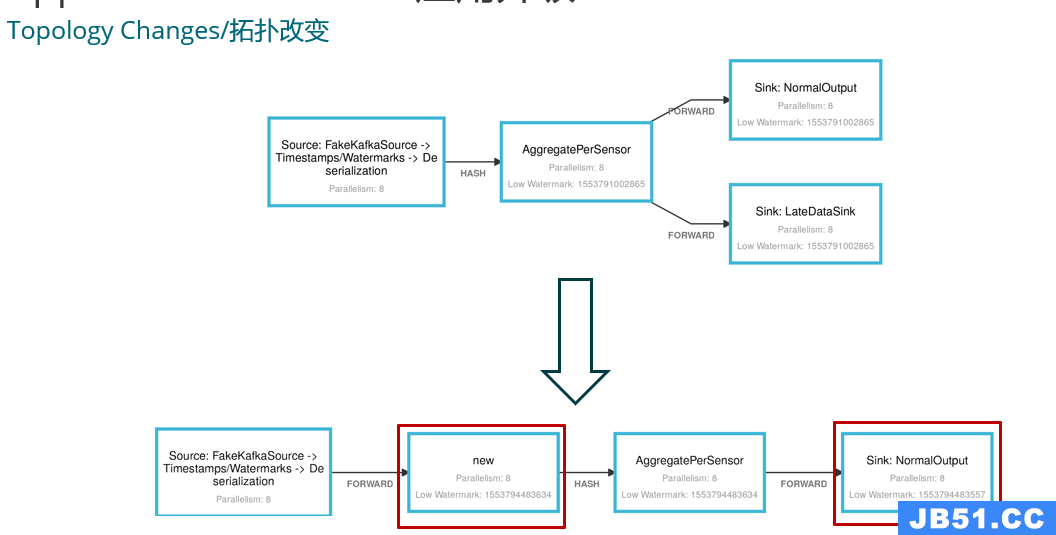
c 业务逻辑(拓扑)的变更
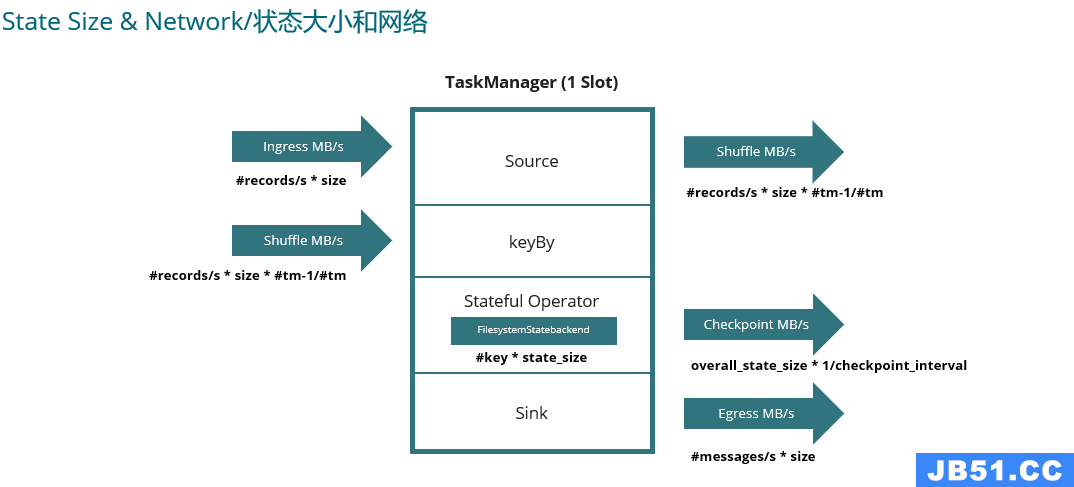
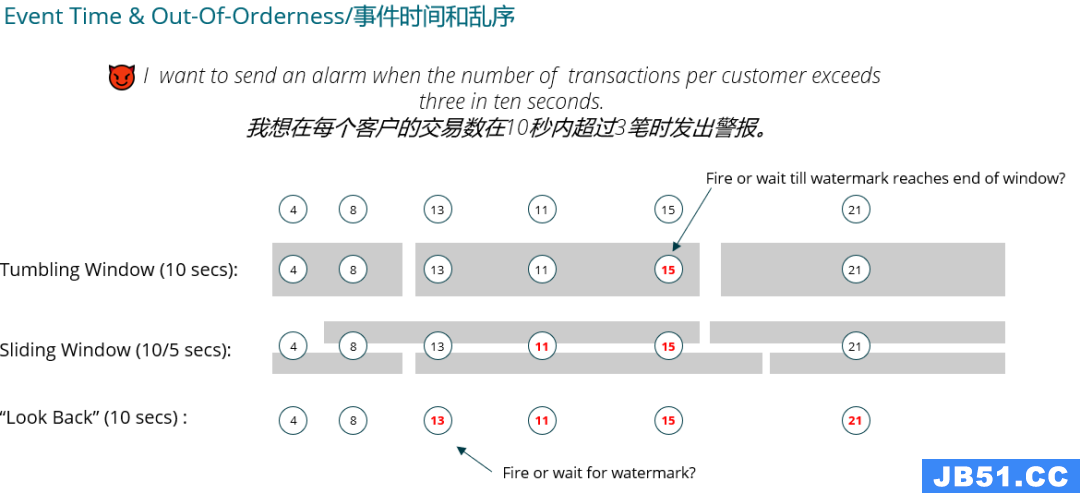
此处需要添加一个算子,去掉一个 sink 。对于这样的变化,我们要考虑状态的恢复。当 Flink 发现新作业有节点没了,对应的状态无法恢复,就会抛出异常导致升级失败。这时候可以使用参数 --allowNonRestoreState 来忽略此类问题。另外新作业中还有新建的节点,这个节点就用空状态去初始化即可。除此之外,还需要注意,为了保证作业成功启动并且状态恢复不受影响,我们应该为算子设置 StreamAPI 中的 uid 。当然,如果状态的结构发生了变化,Avro Types 和 POJO 的类型都是支持的,Kryo 是不支持的。最后建议所有 key 的类型尽量不要修改,因为这会涉及 shuffle 和 状态的正确性。资源的使用情况也是必须要考虑的因素之一,下面是一个评估内存和网络 IO 使用的思路。这里我们假设使用的是 Fs State,所有运行时状态都在内存中。不恰当的资源配置可能会造成 OOM 等严重的问题。完成资源评估后,还需要考虑事件时间和乱序问题。下面是一个具体的例子:在这个例子中选择哪种时间窗口、何时触发计算,仅凭一句话的需求是无法描述清楚的。只有根据流处理的特性结合实际的业务去认真分析需求,才能将 Flink 技术进行恰当的运用。还需要注意,Flink 是流批统一的计算引擎,不是所有的业务都能用流处理或者都能用批处理来实现,需要分析自己的场景适合用哪种方式来实现。
在 DataStream API 和 Table API/SQL 的选择上,如果有强烈的需求控制状态和每条状态到来的行为,要使用 DataStream API;如果是简单的数据提取和关系代数的运算,可以选择 Table API/SQL。在一些场景下,只能选择 DataStream API:a) 在升级过程中要改变状态
b) 不能丢失迟到的数据
c) 在运行时更改程序的行为
a) 使用深度嵌套的复杂数据类型b) KeySelector 中使用任意类型
正确的做法是选择尽可能简单的状态类型,在 KeySelector 中不使用 Flink 不能自动识别的类型。数据类型越简单越好,基于序列化成本的考虑,尽量使用 POJO 和 Avro SpecificRecords。也鼓励大家开发完使用 IDE 的工具本地调试一下,看一下性能瓶颈在哪。
图5中是一种效率较低的处理过程,我们应该先进行过滤和投影操作,防止不需要的数据进行多余的处理。
容易引起 bug;容易造成死锁和竞争问题;带来额外的同步开销。
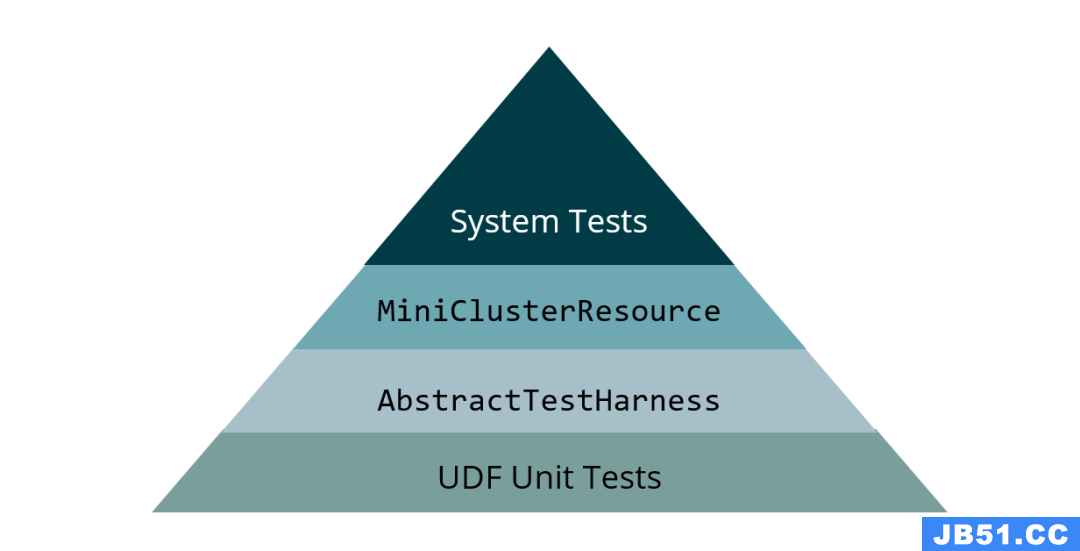
对于想用线程的情况,如果是需要加速作业,可以调整并行度和资源,使用异步IO;如果是需要一些定时任务的触发,可以使用 Flink 自带的 Timer 定时调度任务。尽量避免像图6这样自定义 Window,使用 KeyedProcessFunction 可以使得实现更加简单和稳定。另外,也要避免图7中的这种滑动窗口,在图7中每个记录被50万个窗口计算,无论是计算资源还是业务延迟都会非常糟糕。Queryable State 目前还在不断的完善中,可以用于监控和查询,但在实际投产时还是有一些问题需要注意的,比如对于线程安全访问,RocksDB 状态后端是支持的,而 FS 状态后端是不支持的,另外还有性能和一致性保障等问题需要注意。对图8这种场景,可以使用 DataStreamUtils#reinterpretAsKeyedStream 这个方法,避免面对相同的 key 进行多次 shuffle 。对图9这种场景,应该把一些初始化的逻辑写在 RichFunction 的 open 方法里。除了系统测试和 UDF 的单元测试,还应该做 Mini Cluster 测试,在本机运行一个 Mini Cluster 把端到端的业务跑起来,可以及早地发现一些问题。还有 Harness 测试,它可以精准地帮助完成有状态的任务测试。它可以精准的控制 watermark、元素的 event time 等。可以参考:
https://github.com/knaufk/flink-testing-pyramid
。很多场景会导致业务抖动,一种是实际业务本身就有抖动,其他的比如 Timer、CP 的对齐、GC 等正常现象的发生,还有追数据的场景,开始和追平的时候状态是不一样的,这种情况下也不用担心,有意识地识别这种状况,进而判断这种是正常还是非预期状况。在线上监控时要注意,metrics 过多会对 JVM 造成很大压力,上报的频率不要选择 subtask,这对资源的开销是很高的。在配置时要注意,一开始尽量不用 RocksDB 状态后端,FS 状态后端的部署成本低速度也更快。少用网络的文件系统。SlotSharingGroups 的配置尽量使用默认的,避免引发欠机制的破坏,导致资源浪费。像 Flink 这样快节奏的项目,每个版本都有很多 bug 被修复,及时升级也很重要。7.PyFlink/SQL/TableAPI 的补充
使用 TableEnvironment 还是 StreamTableEnvironment?推荐 TableEnvironment 。(分段优化)
State TTL 未设置,导致 State 无限增长,或者 State TTL 设置不结合业务需求,导致数据正确性问题。
不支持作业升级,例如增加一个 COUNT SUM 会导致作业 state 不兼容。
解析 JSON 时,重复调度 UDF,严重影响性能,建议替换成 UDTF。
多流 JOIN 的时候,先做小表 JOIN,再做大表 JOIN。目前,Flink 还没有表的 meta 信息,没法在 plan 优化时自动做 join reorder。
关于Apache Flink 误用的是示例分析问题的解答就分享到这里了,希望以上内容可以对大家有一定的帮助,如果你还有很多疑惑没有解开,可以关注编程之家行业资讯频道了解更多相关知识。
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。