
Apache Tez is an extensible framework for building high performance batch and interactive data processing applications, coordinated by YARN in Apache Hadoop. Tez improves the MapReduce paradigm by dramatically improving its speed, while maintaining MapReduce’s ability to scale to petabytes of data.
Apache Tez是一个基于Apache Hadoop YARN用于构建高性能批计算和交互式数据处理应用的扩展框架。Tez显著提高MapReduce计算速度的同时也拥有其数据扩展的能力。
YARN considers all the available computing resources on each machine in the cluster. Based on the available resources, YARN negotiates resource requests from applications running in the cluster, such as MapReduce. YARN then provides processing capacity to each application by allocating containers. A container is the basic unit of processing capacity in YARN, and is an encapsulation of resource elements (for example, memory, CPU, and so on).
YARN包含了集群中每一台计算机的可用计算资源。基于可用的计算资源,YARN负责应用的资源请求,比如MapReduce。YARN然后通过分配containers来提供处理能力。container是YARN的基本处理单元,包含了像内存、CPU资源等资源。
In a Hadoop cluster, it is important to balance the memory (RAM) usage, processors (CPU cores), and disks so that processing is not constrained by any one of these cluster resources. Generally, allow for 2 containers per disk and per core for the best balance of cluster utilization.
在Hadoop集群中,均衡化内存使用、处理器以及磁盘是非常重要的,如此以至于任务处理不会被集中在集群中的某个节点。通常来说,对于集群应用来说,每个磁盘和CPU核心分配2个containers是较为合适的。
This article is meant to outline the best practices on memory management of application master and container, java heap size and memory allocation of distributed cache.
该文章指明了Application Master、container、java heap size以及分布式缓存内存分配内存管理的最佳实践。
Environment – Apache Hive 1.2.1 and Apache Tez 0.7.0
环境要求:Apache Hive 1.2.1 以及Apache Tez 0.7.0
Keywords – Hadoop, Apache Hive, Apache Tez, HDFS, YARN, Map Reduce, Application Master, Resource Manager, Node Manager, Cluster, Container, Java Heap, Apache HBase, YARN Scheduler, Distributed Cache, Map Join, Stack Memory, RAM, Disk, Output Sort Buffer
关键字:Hadoop, Apache Hive, Apache Tez, HDFS, YARN, Map Reduce, Application Master, Resource Manager, Node Manager, Cluster, Container, Java Heap, Apache HBase, YARN Scheduler, Distributed Cache, Map Join, Stack Memory, RAM, Disk, Output Sort Buffer
Few configuration parameters which are important in context of jobs running in the Container are described below -
container中运行的任务的重要的配置参数如下所示:
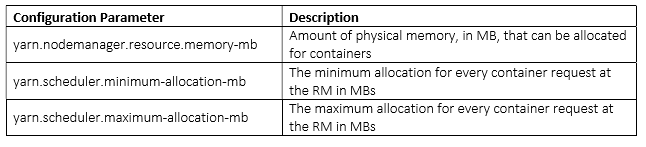
Calculating YARN and MapReduce Memory Configuration
When determining the appropriate YARN and MapReduce memory configurations for a cluster node, start with the available hardware resources. Specifically, note the following values on each node:
在计算合适的YARN和MR内存配置参数时,请从以下可用的硬件资源开始考虑:
-
RAM (Amount of memory)
-
CORES (Number of CPU cores)
-
DISKS (Number of disks)
The total available RAM for YARN and MapReduce should consider the Reserved Memory. Reserved Memory is the RAM needed by system processes and other Hadoop processes (such as HBase).
YARN和MR的总的内存资源必须考虑预留内存,该预留内存用于系统进程以及其他的Hadoop进程(比如Hbase)。
Reserved Memory = Reserved for stack memory + Reserved for HBase Memory (If HBase is on the same node).
预留内存 = stack memory预留内存 + Hbase预留内存
Use the following table to determine the Reserved Memory per node.
使用如下表格来决定每个节点的雨里内存:
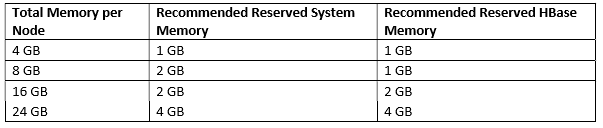

The total YARN memory on all nodes usually between 75% and 87.5% of RAM.
YARN内存大概占所有节点总内存的75% - 87.5%。
There are two methods used to determine YARN and MapReduce memory configuration settings
有两种方法来决定YARN和MR的内存配置:
-
Running the YARN Utility Script
-
运行YARN的实用脚本
-
Manually Calculating YARN and MapReduce Memory Configuration Settings
-
计算YARN和MR的内存配置设置
The HDP utility script is the recommended method for calculating HDP memory configuration settings, but information about manually calculating YARN and MapReduce memory configuration settings is also provided for reference.
HDP的实用脚本是用来计算HDP内存配置设置的推荐方式,同时计算YARN和MR内存配置设置的信息也是提供的。
Running YARN Utility script
HDP provides a utility script called hdp-configuration-utils.py script to calculate YARN, MapReduce, Hive, and Tez memory allocation settings based on the node hardware specifications.
HDP提供一个叫做hdp-configuration-utils.py的脚本,该脚本基于节点硬件资源用来计算YARN、MR、Hive以及Tez的内存分配。
To run the hdp-configuration-utils.py script, execute the following command from the folder containing the script hdp-configuration-utils.py options where options are as follows:
运行hdp-configuration-utils.py,请输入以下参数:

运行示例:
Running the following command:
python hdp-configuration-utils.py -c 16 -m 64 -d 4 -k True
The output would look like below -


In Ambari, configure the appropriate settings for YARN and MapReduce or in a non-Ambari managed cluster, manually add the first three settings in yarn-site.xml and the rest in mapred-site.xml on all nodes.
在Ambari中,或者在非Ambari集群中,为了合理配置YARN和Mapreduce,将前面三个配置加到yarn-site.xml中,其余部分加到mapred-site.xml中。
Manually Calculating YARN and MapReduce Memory Configuration
手动计算YARN和MapReduce内存配置
In yarn-site.xml, set yarn.nodemanager.resource.memory-mb to the memory that YARN uses:
在yarn-site.xml文件中,设置yarn.nodemanager.resource.memory-mb规则如下:
- For systems with 16GB of RAM or less, allocate one-quarter of the total memory for system use and the rest can be used by YARN.
比如说有16G或更少内存,那么分配1/4内存用于系统使用,其余给YARN使用。
- For systems with more than 16GB of RAM, allocate one-eighth of the total memory for system use and the rest can be used by YARN.
对于高于16G内存空间的,分配1/8内存用于系统使用,其余用于YARN使用。
yarn.scheduler.maximum-allocation-mb is the same as yarn.nodemanager.resource.memory-mb.
yarn.scheduler.maximum-allocation-mb 的配置和 yarn.nodemanager.resource.memory-mb一样。
yarn.nodemanager.resource.memory-mb is the total memory of RAM allocated for all the nodes of the cluster for YARN. Based on the number of containers, the minimum YARN memory allocation for a container is yarn.scheduler.minimum-allocation-mb. yarn.scheduler.minimum-allocation-mb will be a very important setting for Tez Application Master and Container sizes. The total YARN memory on all nodes usually between 75% and 87.5% of RAM as per the above calculation.
yarn.nodemanager.resource.memory-mb是节点分配给YARN的总内存。基于containers的数量,YARN给container分配的最小内存为:yarn.scheduler.minimum-allocation-mb。yarn.scheduler.minimum-allocation-mb对于Tez Application Master和Container sizes来说非常重要!
Calculation to determine the max number of containers per node
Configuration parameter i.e. tez.am.resource.memory.mb and hive.tez.container.size define Tez application master size and container size respectively.
配置参数,比如 tez.am.resource.memory.mb 和 hive.tez.container.size定义Tez应用master的大小和container的大小。
Set tez.am.resource.memory.mb to be the same as yarn.scheduler.minimum-allocation-mb (the YARN minimum container size)
设置tez.am.resource.memory.mb和yarn.scheduler.minimum-allocation-mb一样的大小。
Set hive.tez.container.size to be the same as or a small multiple (1 or 2 times that) of YARN container size yarn.scheduler.minimum-allocation-mb but NEVER more than yarn.scheduler.maximum-allocation-mb. You want to have headroom for multiple containers to be spun up.
hive.tez.container.size和yarn.scheduler.minimum-allocation-mb大小一样或者是其1-2倍,但是绝对不超过yarn.scheduler.maximum-allocation-mb。
The formula for determining the max number of container allowed per node is
通过如下方式计算单节点container的最大数量:
of containers = min (2CORES, 1.8DISKS, (Total available RAM) / MIN_CONTAINER_SIZE)
Here DISKS is the value for dfs.data.dirs (number of data disks) per machine and MIN_CONTAINER_SIZE is the minimum container size (in RAM). This value is dependent on the amount of RAM available. In smaller memory nodes, the minimum container size should also be smaller. The following table outlines the recommended values.
其中DISKS表示dfs.data.dir,MIN_CONTAINER_SIZE表示最小的container大小。该大小由节点总内存决定,大概可以参考如下表格:

Calculation to determine the amount of RAM per container
The formula for calculating the amount of RAM per container is
通过如下方式计算每个container的大小:
RAM per container = max(MIN_CONTAINER_SIZE, (Total Available RAM) / containers))
With these calculations, the YARN and MapReduce configurations can be set.
基于上述计算方式,YARN和MapReduce配置如下:

Note: please refer output section of #running YARN utility script, to get the exact value of these configuration parameter for a cluster having cores=16, memory=64GB and disks=4.
Calculation to determine Java heap memory of Application Master and Container
Configuration parameter tez.am.launch.cmd-opts and hive.tez.java.ops define java heap memory of Application master and Container respectively.
tez.am.launch.cmd-opts和hive.tez.java.ops定义了Application Master和Container的java堆内存大小。该堆内存大小可设置为container大小的80%。
The heap memory size would be 80% of the container sizes, tez.am.resource.memory.mb and hive.tez.container.size respectfully.

Calculation to determine Hive Memory Map Join Settings parameters
A map-side join is a special type of join where a smaller table is loaded in memory (distributed cache) and join is performed in map phase of MapReduce job. Since there is no reducer involved in the map-side join, it is much faster when compared to regular join.
map端join是一种特殊类型的连接,其中较小的表被加载到内存中(分布式缓存),连接在MapReduce作业的map阶段执行。 因为在映射端连接中不涉及reducer,所以它比常规join快得多。
hive.auto.convert.join.noconditionaltask.size is the configuration parameter to size memory to perform Map Joins.
hive.auto.convert.join.noconditionaltask.size参数用于设置Map Join的内存大小
By default hive.auto.convert.join.noconditionaltask = true
通常我们设置:hive.auto.convert.join.noconditionaltask = true并且设置hive.auto.convert.join.noconditionaltask.size为hive.tez.container.size的1/3
Formula to set the size of the map join is 33% of container size.
i.e.
SET hive.auto.convert.join.noconditionaltask.size to 1/3 of hive.tez.container.size
Calculation to determine the size of the sort buffer
tez.runtime.io.sort.mb is the configuration parameter which defines the size of the soft buffer when output is sorted.
Formula to calculate the soft buffer size is 40% of the container size.
SET tez.runtime.io.sort.mb to be 40% of hive.tez.container.size.
tez.runtime.unordered.output.buffer.size-mb is the memory when the output does not need to be sorted. Its value is 10% of container size
SET tez.runtime.unordered.output.buffer.size-mb to 10% of hive.tez.container.size
A quick summary
小结
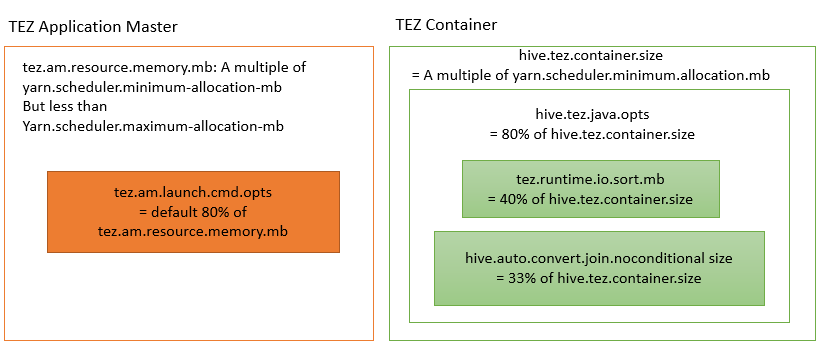
(Fig to understand the properties with their calculated values)
Example
实例:
Considering a Cluster nodes having 16 CPU cores, 64 GB RAM, and 4 disks.
假如说我们有一个集群,拥有16个CPU核心,64G内存以及4个硬盘。
Reserved Memory = 8 GB reserved for system memory + 8 GB for HBase = 16 GB
我们保留8G用于系统运行,以及8G用于Hbase运行。
If there is no HBase:
如果没有安装Hbase的话,我们通过以下方式计算containers
of containers = min (216, 1.8* 16, (64-8)/2) = min (32, 28.8, 28) = 28
RAM per container = max (2, (64-8)/28) = max (2, 2) = 2

If HBase is included:
如果安装Hbase的话,我们通过以下方式计算containers:
of containers = min (216, 1.8 16, (64-8-8)/2) = min (32, 28.8, 24) = 24
RAM-per-container = max (2, (64-8-8)/24) = max (2, 2) = 2

Note – As container size is multiply of yarn.scheduler.minimum-allocation-mb, 2 multiple of yarn.scheduler.minimum-allocation-mb (i.e. 2048 * 2 = 4096 MB is the recommended configuration)
注意事项:container通常事yarn.scheduler.minimum-allocation-mb的好几倍,一般我们设置为2倍。
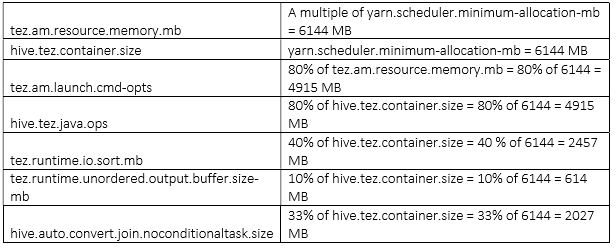
Conclusion
结论
The minimum allocation for every container request at the RM is 1024 MB. Memory requests lower than this won’t take effect, and the specified value will get allocated at minimum. The maximum allocation for every container request at the RM is 8192 MB. Memory requests higher than this won’t take effect, and will get capped to this value.
RM上每个容器请求的最小分配是1024 MB。低于这个值的内存请求将不会生效,指定的值将以最小值分配。 RM上每个容器请求的最大分配是8192 MB。高于这个值的内存请求将不会生效,并且会被限制到这个值。
The RM can only allocate memory to containers in increments of yarn.scheduler.minimum-allocation-mb and not exceed yarn.scheduler.maximum-allocation-mb
RM只会给containers分配介于yarn.scheduler.minimum-allocation-mb和yarn.scheduler.maximum-allocation-mb之间的内存。
If one job is asking for 1030 MB memory per map container (set mapreduce.map.memory.mb=1030), RM will give it one 2048 MB (2*yarn.scheduler.minimum-allocation-mb) container because each job will get the memory it asks for rounded up to the next slot size. If the minimum is 4GB and the application asks for 5 GB, it will get 8GB. If we want less rounding, we must make the minimum allocation size smaller.
加如一个任务请求1030MB内存用于map container(set mapreduce.map.memory.mb = 1030),RM会给每个container分配2048MB内存(2*yarn.scheduler.minimum-allocation-mb),这是因为每个人物请求的内存会是上述设置值的倍数。当然,假如你设置的最小值为4G,而你请求5G,那么机会分配8G。所以说,为了更合理配置内存,我们建议将最小分配的内存设置为一个较小的值。
The HEAP memory configuration is 80% of container size and its not 100% because the JVM has some off heap overhead that still counts into the memory consumption of the Linux process.
堆内存的配置通常设置为container的80%,而不是100%。这是因为JVM在使用过程中有一些非堆开销,这些开销仍然会计入Linux进程的消耗。
原文地址:https://blog.csdn.net/weixin_39636364/article/details/120424837
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。