
参考视频教程:
**基于Storm构建实时热力分布项目实战 **
教程目录
- 0x00 教程内容
- 0x01 下载Storm
*
*
*
* - 0x02 安装与配置Storm
*
*
*
* - 0x03 启动并校验Storm
*
*
*
* - 0xFF 总结
0x00 教程内容
- 下载Storm
- 安装与配置Storm
- 启动并校验Storm
前提:
先安装好Zookeeper,请查看教程:
D003 复制粘贴玩大数据之安装与配置Zookeeper集群
0x01 下载Storm
1. 下载Storm
a. 为了统一,此处下载apache-storm-1.2.2.tar.gz版本:
http://storm.apache.org/downloads.html
2. 上传安装包到节点
a. 上传到master的/home/hadoop-sny/software上,没有目录则创建:
mkdir ~/software
0x02 安装与配置Storm
1. 解压Storm
a. 解压Storm
tar -zxvf apache-storm-1.2.2.tar.gz -C ~/bigdata/
2. 配置Storm
a. 新建Storm数据文件夹,在每台机器上创建文件目录:
mkdir /home/hadoop-sny/bigdata/storm-data
b. 修改Storm配置
cd ~/bigdata/apache-storm-1.2.2/conf
vi storm.yaml
配置一:配置ZK存储Storm的状态信息(协调Storm的每一个组件)
登录后复制
storm.zookeeper.servers:
- "master"
- "slave1"
- "slave2"
配置二:配置Nimbus和Supervisor在本地磁盘上存储小量的数据(如jars,配置等)
storm.local.dir: "/home/hadoop-sny/bigdata/storm-data"
配置三:配置Nimbus所在的机器名
nimbus.seeds: ["master"]
配置四:配置每个Supervisor节点最多可以启动多少个workers,(一个worker对应一个端口用于接收数据)默认是4个
登录后复制
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
如图所示:

scp -r /home/hadoop-sny/bigdata/apache-storm-1.2.2 hadoop-sny@slave1:~/bigdata/scp -r /home/hadoop-sny/bigdata/apache-storm-1.2.2 hadoop-sny@slave2:~/bigdata/0x03 启动并校验Storm
1. 启动Storm
前提:
先启动Zookeeper(三个节点都要启动):
zkServer.sh start

cd ~/bigdata/apache-storm-1.2.2nohup bin/storm nimbus 2>&1 &然后回车,切换终端2,执行:
nohup bin/storm ui 2>&1 &然后回车
b. 在slave1和slave2上启动Supervisor
cd ~/bigdata/apache-storm-1.2.2nohup bin/storm supervisor 2>&1 &
2. 校验Storm
a. 查看各节点进程
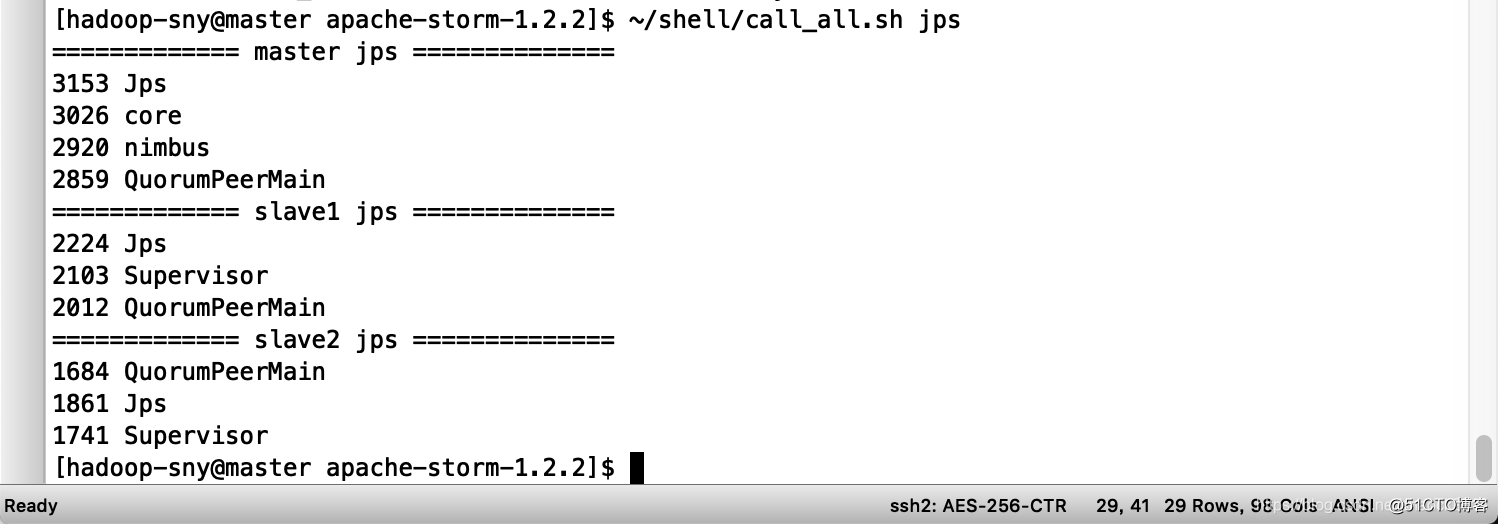
打开端口:
http://master:8080,看到下面的界面表示成功: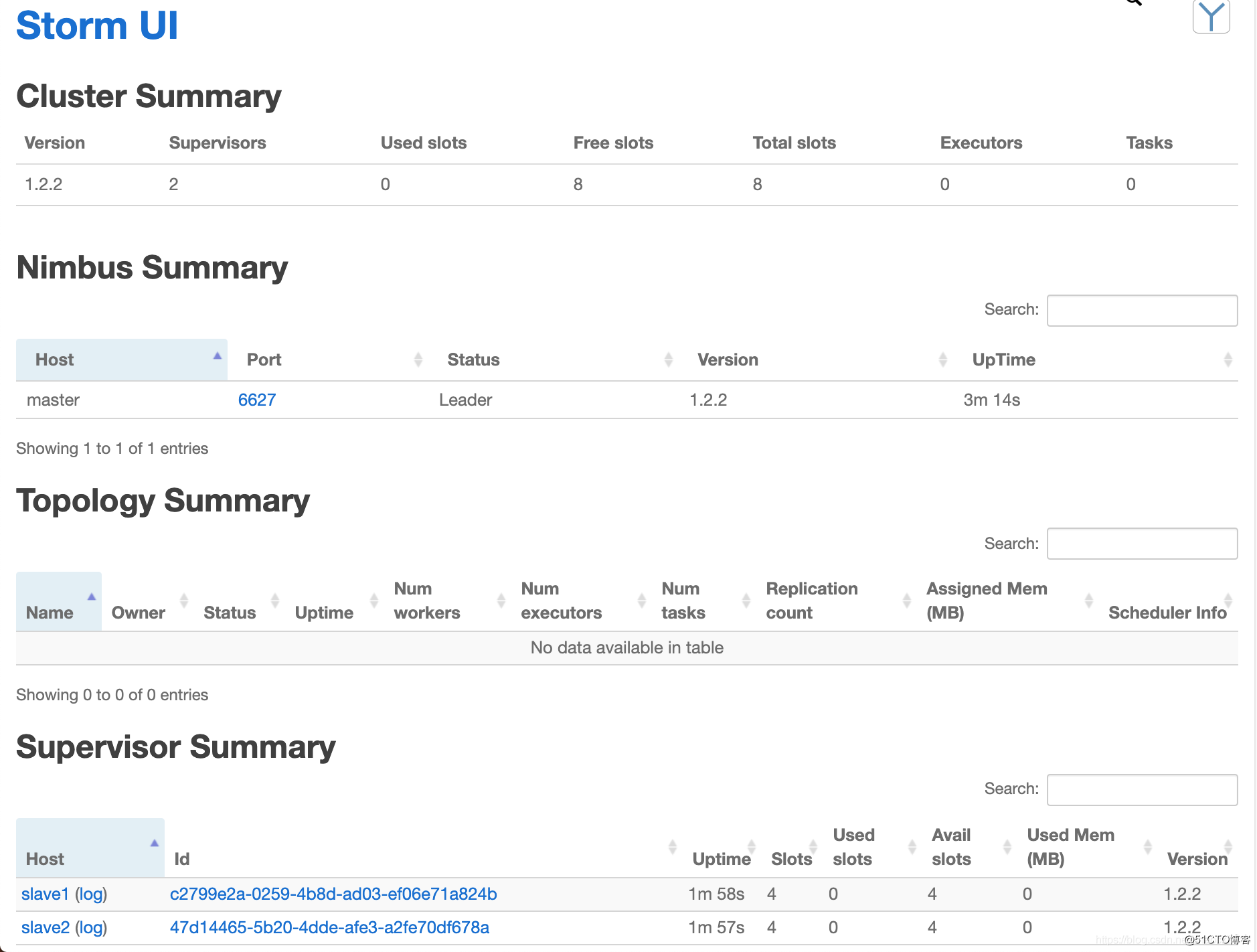
- Flume、Kafka、Storm的综合小案例,请留意后期教程
- 后期教程还会加上Kafka、Storm、Kafka的piplines的实现教程
原文地址:https://blog.csdn.net/u013328649/article/details/120581340
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。