
今天分享的这道题来自于蔚来的真实面试题。
Java 面试不可能不问 Redis,问到 Redis 不可能不问 Redis 的常用数据类型,问到 Redis 的常用数据类型,不可能不问跳跃表,当问到跳跃表经常会被问到跳跃表的查询和添加流程,所以接下来我们一起来看这道题的答案吧。
Redis 有序集合 ZSet 是由 ziplist (压缩列表) 或 skiplist (跳跃表) 组成的。
- 压缩列表 ziplist 本质上就是一个字节数组,是 Redis 为了节约内存而设计的一种线性数据结构,可以包含多个元素,每个元素可以是一个字节数组或一个整数。
- 跳跃表 skiplist 是一种有序数据结构,它通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的。跳跃表支持平均 O(logN)、最坏 O(N) 复杂度的节点查找,还可以通过顺序性操作来批量处理节点。
跳跃表介绍
跳跃表 Skip List,也称之为跳表,是一种数据结构,用于在有序元素的集合中进行高效的查找操作。它通过添加多层链表的方式,提供了一种以空间换时间的方式来加速查找。
跳跃表由一个带有多层节点的链表组成,每一层都是原始链表的一个子集。最底层是一个完整的有序链表,包含所有元素。每个更高层级都是下层级的子集,通过添加额外的指针来跳过一些元素。这些额外的指针称为“跳跃指针”,它们允许快速访问更远的节点,从而减少了查找所需的比较次数。
跳跃表的平均查找时间复杂度为 O(log n),其中 n 是元素的数量。这使得它比普通的有序链表具有更快的查找性能,并且与平衡二叉搜索树(如红黑树)相比,实现起来更为简单。
简单的跳跃表如下图所示:
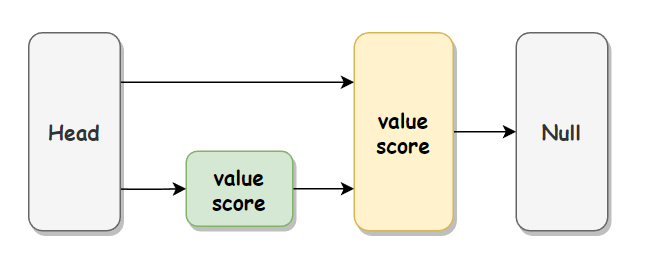
跳跃表添加流程
前置知识:节点随机层数
在开始讲跳跃表的添加流程之前,必须先搞懂一个概念:节点的随机层数。
所谓的随机层数指的是每次添加节点之前,会先生成当前节点的随机层数,根据生成的随机层数来决定将当前节点存在几层链表中。
为什么要这样设计呢?
这样设计的目的是为了保证 Redis 的执行效率。
为什么要生成随机层数,而不是制定一个固定的规则,比如上层节点是下层跨越两个节点的链表组成,如下图所示:
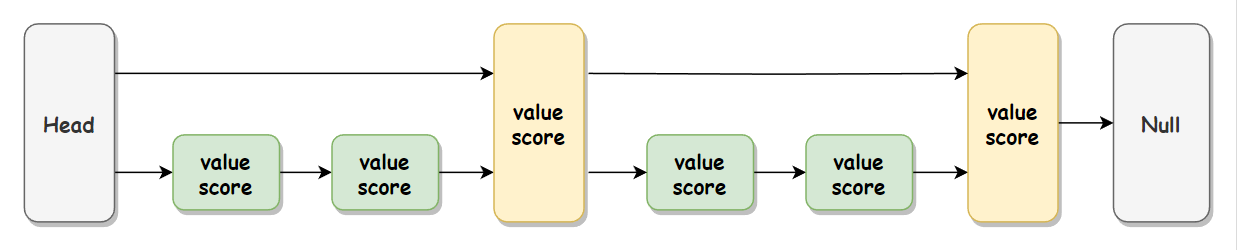
如果制定了规则,那么就需要在添加或删除时,为了满足其规则,做额外的处理,比如添加了一个新节点,如下图所示:

这样就不满足制定的上层节点跨越下层两个节点的规则了,就需要额外的调整上层中的所有节点,这样程序的效率就降低了,所以使用随机层数,不强制制定规则,这样就不需要进行额外的操作,从而也就不会占用服务执行的时间了。
添加流程
Redis 中跳跃表的添加流程如下图所示:
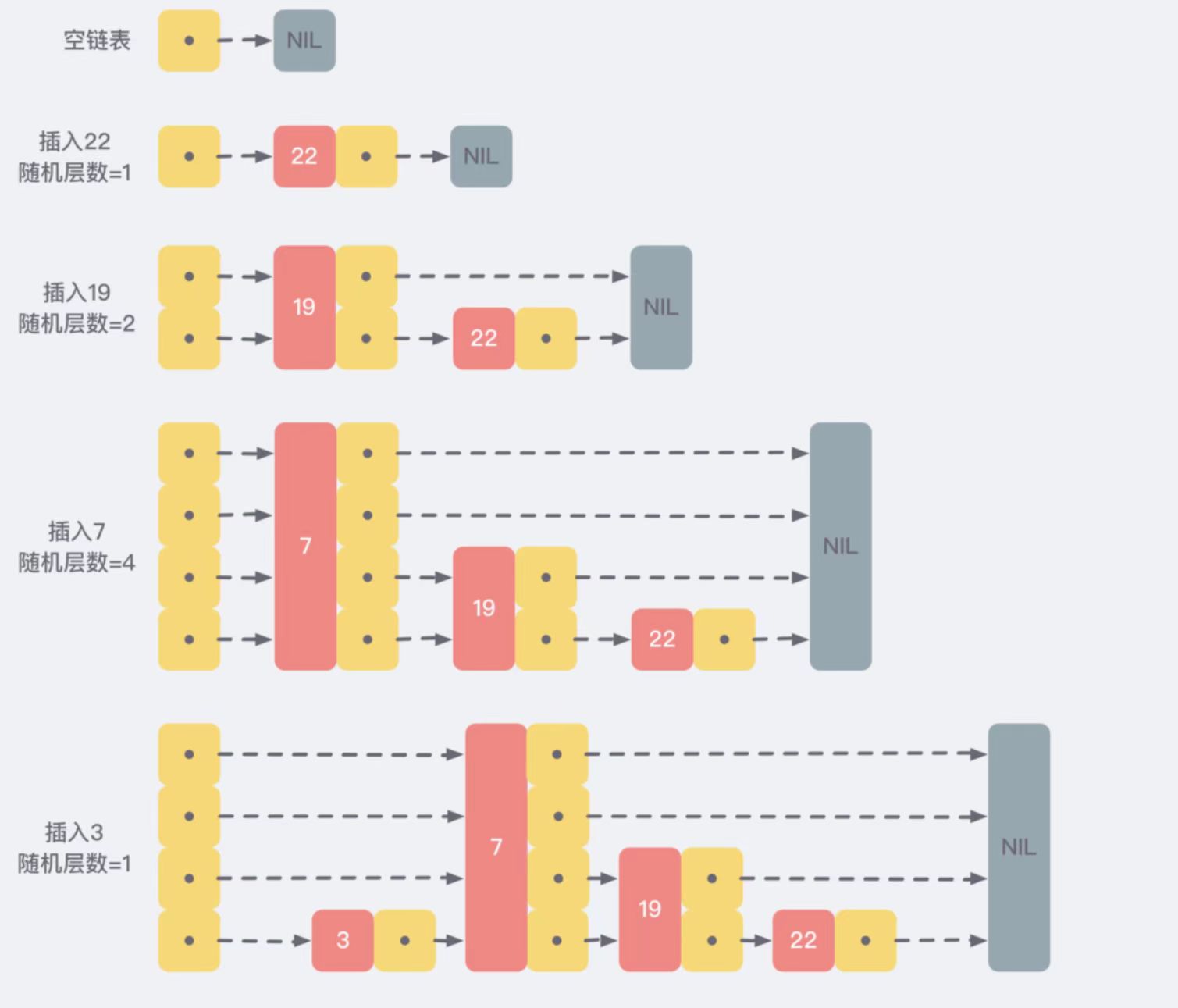
- 第一个元素添加到最底层的有序链表中(最底层存储了所有元素数据)。
- 第二个元素生成的随机层数是 2,所以再增加 1 层,并将此元素存储在第 1 层和最低层。
- 第三个元素生成的随机层数是 4,所以再增加 2 层,整个跳跃表变成了 4 层,将此元素保存到所有层中。
- 第四个元素生成的随机层数是 1,所以把它按顺序保存到最后一层中即可。
其他新增节点以此类推。
随机层数源码分析
随机层数的源码在 t_zset.c/zslRandomLevel(void) 中,如下所示:
int zslRandomLevel(void) {
int level = 1;
while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
level += 1;
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}
从源码可知,随机层数有 50% 的概率被分配到 Level 1,25% 的概率被分配到 Level 2,12.5% 的概率被分配到 Level 3,以此类推。
Redis 跳跃表默认允许最大的层数是 32,此值在 ZSKIPLIST_MAXLEVEL 源码中被定义。
小结
跳跃表是由多个有序的链表组成的,最底层存储了所有元素的数据,这样存储让它的查询效率更高,查询复杂度从 O(n) 变为了 O(log n)。跳跃表的添加流程是根据节点生成的随机层数,将它插入到最底层节点和上层的 N-1 层节点中,描述添加流程的关键就是理解随机层数以及其背后的原理。
参考 & 鸣谢
https://segmentfault.com/a/1190000022028505
本文已收录到我的面试小站 www.javacn.site,其中包含的内容有:Redis、JVM、并发、并发、MySQL、Spring、Spring MVC、Spring Boot、Spring Cloud、MyBatis、设计模式、消息队列等模块。
原文地址:https://www.cnblogs.com/vipstone/p/17509314.html
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。