

在面试当中,有时候会问到你在项目中用过多线程么?
对于普通的应届生或者工作时间不长的初级开发 ???—— crud仔流下了没有技术的眼泪。

博主这里整理了项目中用到了多线程的一个简单的实例,希望能对你有所启发。
多线程开发实例
应用背景
应用的背景非常简单,博主做的项目是一个审核类的项目,审核的数据需要推送给第三方监管系统,这只是一个很简单的对接,但是存在一个问题。
我们需要推送的数据大概三十万条,但是第三方监管提供的接口只支持单条推送(别问为什么不支持批量,问就是没讨撕论比好过)。可以估算一下,三十万条数据,一条数据按3秒算,大概需要250(为什么恰好会是这个数)个小时。
所以就考虑到引入多线程来进行并发操作,降低数据推送的时间,提高数据推送的实时性。
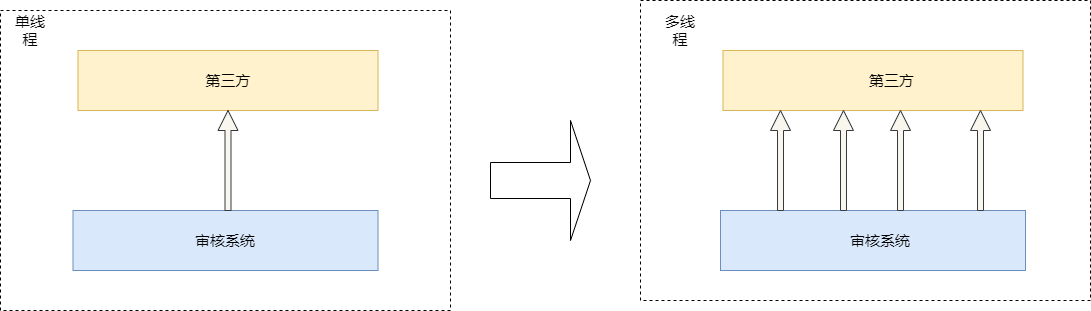
设计要点
防止重复
我们推送给第三方的数据肯定是不能重复推送的,必须要有一个机制保证各个线程推送数据的隔离。
这里有两个思路:
-
- 将所有数据取到集合(内存)中,然后进行切割,每个线程推送不同段的数据
-
- 利用 数据库分页的方式,每个线程取 [start,limit] 区间的数据推送,我们需要保证start的一致性
这里采用了第二种方式,因为考虑到可能数据量后续会继续增加,把所有数据都加载到内存中,可能会有比较大的内存占用。
失败机制
我们还得考虑到线程推送数据失败的情况。
如果是自己的系统,我们可以把多线程调用的方法抽出来加一个事务,一个线程异常,整体回滚。
但是是和第三方的对接,我们都没法做事务的,所以,我们采用了直接在数据库记录失败状态的方法,可以在后面用其它方式处理失败的数据。
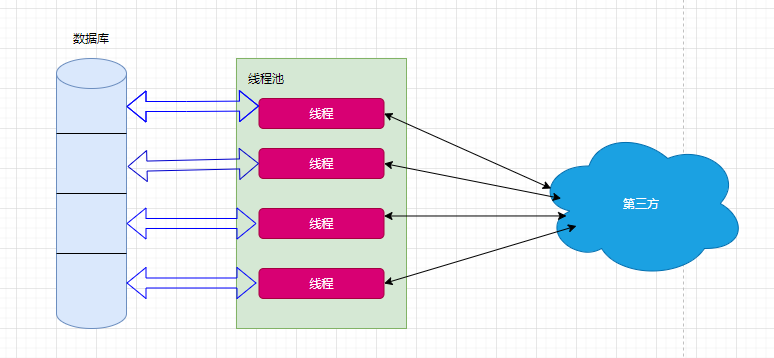
线程池选择
在实际使用中,我们肯定是要用到线程池来管理线程,关于线程池,我们常用 ThreadPoolExecutor提供的线程池服务,SpringBoot中同样也提供了线程池异步的方式,虽然SprignBoot异步可能更方便一点,但是使用ThreadPoolExecutor更加直观地控制线程池,所以我们直接使用ThreadPoolExecutor构造方法创建线程池。
大概的技术设计示意图:
核心代码
上面叭叭了一堆,到了show you code的环节了。我将项目里的代码抽取出来,简化出了一个示例。
核心代码如下:
/**
* @Author 三分恶
* @Date 2021/3/5
* @Description
*/
@Service
public class PushProcessServiceImpl implements PushProcessService {
@Autowired
private PushUtil pushUtil;
@Autowired
private PushProcessMapper pushProcessMapper;
private final static Logger logger = LoggerFactory.getLogger(PushProcessServiceImpl.class);
//每个线程每次查询的条数
private static final Integer LIMIT = 5000;
//起的线程数
private static final Integer THREAD_NUM = 5;
//创建线程池
ThreadPoolExecutor pool = new ThreadPoolExecutor(THREAD_NUM,THREAD_NUM * 2,TimeUnit.SECONDS,new LinkedBlockingQueue<>(100));
@Override
public void pushData() throws ExecutionException,InterruptedException {
//计数器,需要保证线程安全
int count = 0;
//未推送数据总数
Integer total = pushProcessMapper.countPushRecordsByState(0);
logger.info("未推送数据条数:{}",total);
//计算需要多少轮
int num = total / (LIMIT * THREAD_NUM) + 1;
logger.info("要经过的轮数:{}",num);
//统计总共推送成功的数据条数
int totalSuccessCount = 0;
for (int i = 0; i < num; i++) {
//接收线程返回结果
List<Future<Integer>> futureList = new ArrayList<>(32);
//起THREAD_NUM个线程并行查询更新库,加锁
for (int j = 0; j < THREAD_NUM; j++) {
synchronized (PushProcessServiceImpl.class) {
int start = count * LIMIT;
count++;
//提交线程,用数据起始位置标识线程
Future<Integer> future = pool.submit(new PushDataTask(start,LIMIT,start));
//先不取值,防止阻塞,放进集合
futureList.add(future);
}
}
//统计本轮推送成功数据
for (Future f : futureList) {
totalSuccessCount = totalSuccessCount + (int) f.get();
}
}
//更新推送标志
pushProcessMapper.updateAllState(1);
logger.info("推送数据完成,需推送数据:{},推送成功:{}",total,totalSuccessCount);
}
/**
* 推送数据线程类
*/
class PushDataTask implements Callable<Integer> {
int start;
int limit;
int threadNo; //线程编号
PushDataTask(int start,int limit,int threadNo) {
this.start = start;
this.limit = limit;
this.threadNo = threadNo;
}
@Override
public Integer call() throws Exception {
int count = 0;
//推送的数据
List<PushProcess> pushProcessList = pushProcessMapper.findPushRecordsByStateLimit(0,start,limit);
if (CollectionUtils.isEmpty(pushProcessList)) {
return count;
}
logger.info("线程{}开始推送数据",threadNo);
for (PushProcess process : pushProcessList) {
boolean isSuccess = pushUtil.sendRecord(process);
if (isSuccess) { //推送成功
//更新推送标识
pushProcessMapper.updateFlagById(process.getId(),1);
count++;
} else { //推送失败
pushProcessMapper.updateFlagById(process.getId(),2);
}
}
logger.info("线程{}推送成功{}条",threadNo,count);
return count;
}
}
}
代码很长,我们简单说一下关键的地方:
- 线程创建:线程内部类选择了实现Callable接口,这样方便获取线程任务执行的结果,在示例里用于统计线程推送成功的数量
class PushDataTask implements Callable<Integer> {
- 使用 ThreadPoolExecutor 创建线程池,
//创建线程池
ThreadPoolExecutor pool = new ThreadPoolExecutor(THREAD_NUM,new LinkedBlockingQueue<>(100));
主要构造参数如下:
- corePoolSize:线程核心参数选择了5
- maximumPoolSize:最大线程数选择了核心线程数2倍数
- keepAliveTime:非核心闲置线程存活时间直接置为0
- unit:非核心线程保持存活的时间选择了 TimeUnit.SECONDS 秒
- workQueue:线程池等待队列,使用 容量初始为100的 LinkedBlockingQueue阻塞队列
这里还有没写出来的线程池拒绝策略,采用了默认AbortPolicy:直接丢弃任务,抛出异常。
- 使用 synchronized 来保证线程安全,保证计数器的增加是有序的
synchronized (PushProcessServiceImpl.class) {
- 使用集合来接收线程的运行结果,防止阻塞
List<Future<Integer>> futureList = new ArrayList<>(32);
好了,主要的代码和简单的解析就到这里了。
关于这个简单的demo,这里只是简单地做推送数据处理。考虑一下,这个实例是不是可以用在你项目的某些地方。例如监管系统的数据校验、审计系统的数据统计、电商系统的数据分析等等,只要是有大量数据处理的地方,都可以把这个例子结合到你的项目里,这样你就有了多线程开发的经验。
完整代码仓库地址在文章底部
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 [email protected] 举报,一经查实,本站将立刻删除。