

SyntaxNet 介绍
SyntaxNet
是一个框架,即学术圈所指的SyntacticParser,他是许多NLU系统中的关键组件。在这个系统中输入一个句子,他会自动给句子中的每一个单词
打上POS(part-of-Speech)标签,用来描述这些词的句法功能,并在依存句法树中呈现。这些句法关系直接涉及句子的潜在含义。
举一个很简单的例子,看下面这个句子“Alice saw Bob”的依存句法树:

在这个结构中,Alice和Bob被编码为名词,Saw是动词。只要的动词saw
是句子的根,Alice是saw的主语,Bob是直接宾语(dobj)。和期待的一样,Paesey
McParseface能正确地分析这一句子,也能理解下面这个更加复杂的例子:
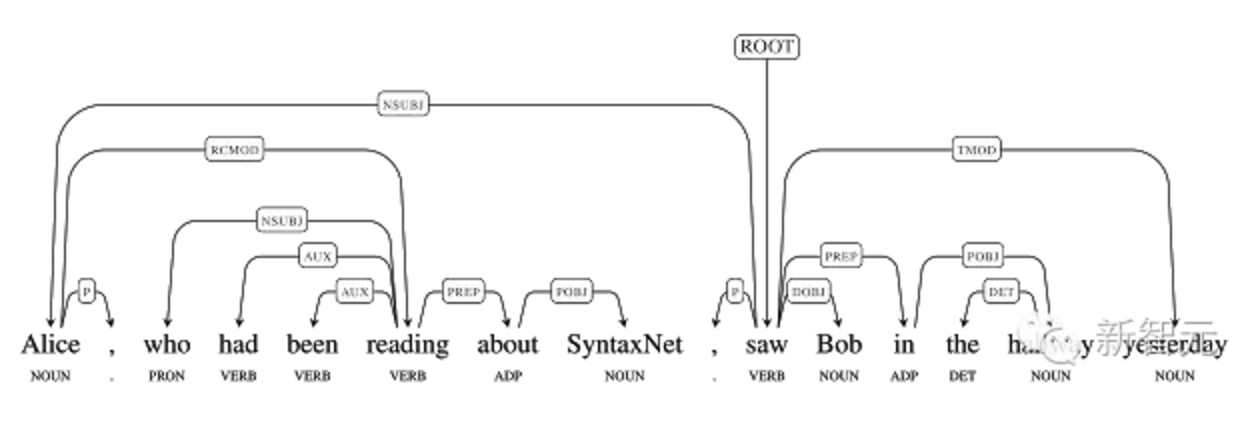
句子:Alice, who had been reading about SynataxNet, saw Bob in the
hallwayyesterday
在 这个句子的编码中,Alice 和
Bob的分别是saw的主语和宾语,Alice由一个带动词“reading”的关系从句来修饰,而saw则由时态“yesterday”来修饰。依存句
法树中的语法关系让我们可以轻易地找到不同问题的答案,比如,Alice看见了谁?谁看到了Bob?Alice正在读的是什么?或者Alice是在什么时
候看到Bob的。
为什么让计算机正确处理句法分析如此困难?
句 法分析如此困难的一个主要问题是,人类语言具有显著的歧义性。包含 20 到 30
个单词的中等长度的句子会具有数百、数千甚至数万种可能的句法结构,这样的情况并不少见。一个自然语言句法分析器必须能够搜索所有这些结构选择,并找到给
定语境下最合理的那个结构。作为一个非常简单的例子,“Alice drove down the streetin her
car”这个句子就具有至少两种可能的依存分析:
第 一种分析是对应这句话的(正确)解释,按照这种解释,爱丽丝在汽车里进行驾驶,而汽车位于街道上;第二种分析对应于一种对这句话的(荒诞但仍然可能的)解
释,按照这种解释,爱丽丝在街道上驾驶,而街道位于汽车之内。之所以会产生这种歧义,是因为“in”这个介词既可以用来修饰“drove(驾驶)”也可以
用来修饰“street(街道)”。上面这个例子是所谓的“介词短语附着歧义”的一个实例。
人 类在处理歧义方面有超强的能力,以至于人们甚至注意不到句子有歧义。而这里的挑战是,如何能让计算机做到同样好。长句中的多重歧义会共同造成句子的可能结
构数量的组合爆炸。通常,这些结构中的绝大多数都极其不合理,但它们仍然是可能的,句法分析器必须以某种方式来丢弃它们。
SyntaxNet
将神经网络运用于歧义问题。一个输入句子被从左到右地处理。当句子中的每个词被处理时,词与词之间的依存关系也会被逐步地添加进来。由于歧义的存在,在处
理过程的每个时间点上都存在多种可能的决策,而神经网络会基于这些决策的合理性向这些彼此竞争的决策分配分数。出于这一原因,在该模型中使用 Beam Search
(集束搜索)就变得十分重要。不是直接取每个时间点上的最优决定,而是在每一步都保留多个部分性假设。只有当存在多个得分更高的假设的时候,一个假设才会
被抛弃。下图将展示的,是“I booked a ticket to Google”这句话经过从左到右的决策过程而产生的简单句法分析。
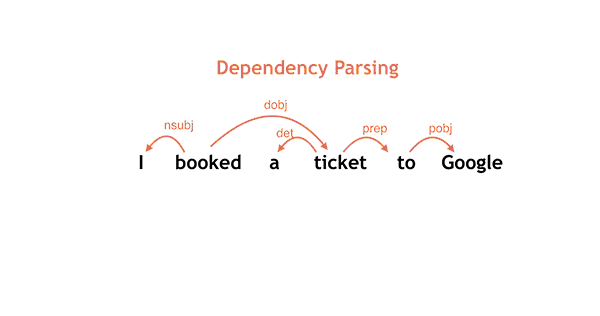
而 且,正如我们在论文中所描述的,十分重要的一点是,要把学习和搜索紧密整合起来才能取得最高的预测准确度。Parsey McParseface 和其他
SyntaxNet 模型是我们用谷歌的 TensorFlow 框架训练过的最复杂的网络结构。通过利用谷歌支持的 Universal Treebanks
项目中的数据,你也可以在自己的机器上训练句法分析模型。
SyntaxNet 官网
https://github.com/tensorflow/models
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 [email protected] 举报,一经查实,本站将立刻删除。