

1、如何实现 Nginx 代理的节点访问日志记录客户的 IP 而不是代理的 IP?
在nginx代理文件中怎加一行配置文件:proxy_set_header X-Real-IP $remote_addr;
2./var/log/messages 日志出现 kernel: nf_conntrack: table full, dropping packet.请问是什么原因
导致的?如何解决?
这是iptables的报错信息“连接跟踪表已满,开始丢包”,再想到网站那面将memcached的连接改为短连接,由于iptables会记录每个连接的跟踪信息,而连接关闭关闭过于频繁导致连接跟踪表满,出现丢包。
解决方法:
首先将memcached的连接方法改为长链接,然后再针对nf_conntrack进行修改,主要有以下几种方式:
1.关闭防火墙
2.加大iptables跟踪表大小,调整对应的系统参数
3.使用裸表,不添加跟踪标志
4.删除连接跟踪模块
3.linux 系统 nginx php 环境,发现 PHP-FPM 进程占用 CPU 高,请问可能的原因,以及如
何解决?
一、进程跟踪
# top //找出CPU使用率高的进程PID
# strace -p PID //跟踪进程
# ll /proc/PID/fd //查看该进程在处理哪些文件
将有可疑的PHP代码修改之,如:file_get_contents没有设置超时时间。
二、内存分配
如果进程跟踪无法找到问题所在,再从系统方面找原因,会不会有可能内存不够用?据说一个较为干净的PHP-CGI打开大概20M-30M左右的内存,决定于PHP模块开启多少。
通过pmap指令查看PHP-CGI进程的内存使用情况
# pmap $(pgrep php-cgi |head -1)
按输出的结果,结合系统的内存大小,配置PHP-CGI的进程数(max_children)。
三、监控
最后,还可以通过监控与自动恢复的脚本保证服务的正常运转。下面是我用到的一些脚本:
只要一个php-cgi进程占用的内存超过 %1 就把它kill掉
#!/bin/sh
PIDS=`ps aux|grep php-cgi|grep -v grep|awk’{if($4>=1)print $2}’`
for PID in $PIDS
do
echo `date +%F….%T`>>/data/logs/phpkill.log
echo $PID >> /data/logs/phpkill.log
kill -9 $PID
done
检测php-fpm进程
#!/bin/bash
netstat -tnlp | grep “php-cgi” >> /dev/null #2&> /data/logs/php_fasle.log
if [ "$?" -eq "1" ];then #&& [ `netstat -tnlp | grep 9000 | awk '{ print $4}' | awk -F ":" '{print $2}'` -eq "1" ];then
/usr/local/webserver/php/sbin/php-fpm start
echo `date +%F….%T` “System memory OOM.Kill php-cgi. php-fpm service start. ” >> /data/logs/php_monitor.log
fi
通过http检测php执行
#!/bin/bash
status=`curl -s –head “http://127.0.0.1:8080/chk.php” | awk ‘/HTTP/ {print $2}’`
if [ $status != "200" -a $status != "304" ]; then
/usr/local/webserver/php/sbin/php-fpm restart
echo `date +%F….%T` “php-fpm service restart” >> /data/logs/php_monitor.log
fi
4.一主多从,主库宕机,如何切换到从库,其他的从库如何处理?
1.确保所有的relay log全部更新完毕,在每个从库上执行stop slave io_thread; show processlist;直到看到Has read all relay log,则表示从库更新都执行完毕了
2.登陆所有从库,查看master.info文件,对比选择pos最大的作为新的主库。
3.登陆192.168.1.102,执行stop slave; 并进入数据库目录,删除master.info和relay-log.info文件, 配置my.cnf文件,开启log-bin,如果有log-slaves-updates和read-only则要注释掉,执行reset master
4.创建用于同步的用户并授权slave,同第五大步骤
5.登录另外一台从库,执行stop slave停止同步
6.根据第七大步骤连接到新的主库
7.执行start slave;
8.修改新的master数据,测试slave是否同步更新
5.误操作 drop 语句导致数据破坏,请给出恢复思想及实际步骤。
思想:
法1: 1、通过防火墙禁止web等应用向主库写数据或者锁表,让数据库停止更新。
##检查全备及binlog日志 ;
2、将全备恢复;
mysqlbinlog -d databasename mysql-bin.000014 > bin.sql
3、将所有binlog汇总,转成sql语句,剔除drop语句,恢复数据;
mysql -uroot -p123456 databasename < bin.sql
(注意数据的备份,不要破坏原始数据)
4、后续:(数据无法写入)所以无需恢复。
5、如果是update语句(也需要停止访问)
法2:1、如果主库持续有数据写入;
2、停止一个从库;然后在主库刷新binlog;
3、把mysql-bin.000014恢复成bin.sql(去掉drop语句);
4、把全备数据sql及操作前的增量bin.sql恢复到从库。
5、停止主库;把主库刷新后的binlog解析为sql恢复到从库;
5、切换为从库提供服务;
#法2可能会有主键冲突等其它的问题,可以通过修改id或者延迟解决,尽量使用法1停库解决;
#平时工作要注意数据库的权限管理及流程管理,防患于未然。
6.请举一个生产中实际的例子网站打开慢由于数据库慢导致的。
数 据库负载高,有慢查询,做联合索引案例
数据库负载高,有慢查询,分析web日志,可能有爬虫,封其ip
7. 通过 kill -9 野蛮粗鲁杀死数据库导致数据库启动故障,给出排除方法或者经验。
暂时没有答案:
8.IDC 机房带宽突然从平时 100M 增加到 400M,请你分析问题所在,并解决。
.真实遭受DDOS攻击(遇到过几次,造成影响的不多见,其中还有黑客勒索的案例)。
b.内部服务器中毒,大量外发流量(这个问题老男孩接警5次以上)
c.网站元素(如图片)被盗连,在门户页面被推广导致大量流量产生(接警3次以上)
d.合作公司来抓数据,如:对合作单位提供了API数据接口(有合作的公司的朋友了解这个)
e.购买了CDN业务,CDN猛抓源站(这个次数也不少)。
9.正在工作的 linux,发现文件系统只读了,你觉得导致问题的原因是什么,如何解决?
1、重启看是否可以修复(很多机器可以)
2、使用用 fsck – y /dev/hdc6 (/dev/hdc6指你需要修复的分区) 来修复文件系统
3、若,在进行修复的时候有的分区会报错,重新启动系统问题依旧
查看下分区结构
[root@localhost ~]# mount
/dev/sda3 on / type ext3 (rw)
proc on /proc type proc (rw)
sysfs on /sys type sysfs (rw)
devpts on /dev/pts type devpts (rw,gid=5,mode=620)
/dev/sda1 on /boot type ext3 (ro)
tmpfs on /dev/shm type tmpfs (rw)
none on /proc/sys/fs/binfmt_misc type binfmt_misc (rw)
sunrpc on /var/lib/nfs/rpc_pipefs type rpc_pipefs (rw)
查看ro挂载的分区,如果发现有ro,就重新mount
umount /dev/sda1
mount /dev/sda1 /boot
如果发现有提示“device is busy”,找到是什么进程使得他busy
fuser -m /boot 将会显示使用这个模块的pid
fuser -mk /boot 将会直接kill那个pid
然后重新mount即可。
4、直接remount,命令为
[root@localhost ~]# mount -o rw,remount /boot
10.磁盘报错“No space left on device”,但是 df -h 查看磁盘空间没满,请问为什么?
1.1首先查看我们的磁盘剩余情况
[root@admin /]# df -h #发现磁盘没有满 还有%47
Filesystem Size Used Avail Use% Mounted on
/dev/sda3 6.9G 3.1G 3.5G 47% /
tmpfs 491M 0 491M 0% /dev/shm
/dev/sda1 190M 33M 147M 19% /boot
1.2 创建目录测试报错
#创建目录报错文件还是正常
[root@admin/]# mkdir test
mkdir: cannot create directory `test': No space left on device
#查看磁盘inode
[root@admin/]# df -i
Filesystem Inodes IUsed IFree IUse% Mounted on
/dev/sda3 462384 462384 0 100% /
tmpfs 125517 1 125516 1% /dev/shm
/dev/sda1 51200 38 51162 1% /boot
#最后发现目录backup中inode 满了
[root@admin/]# df -i /backup/
Filesystem Inodes IUsed IFree IUse% Mounted on
/dev/sda3 462384462384 0 100% /
1.3解决方案
#删除backup目录中不常用的文件数据
#由于本文是测试inode满 所以删除所有数据,工作中要注意汇报上级。
[root@admin /]# \rm -rf /backup/
#公司解决方案
删除/backup目录中的部分文件,释放出/backup分区的一部分inode,特别要留意那些spool出来的文件,这种文件一般会占用比较多的节点,因为比较小而且零碎,同时要多留意日志文件信息等
2、用软连接将空闲分区/opt中的newcache目录连接到/data/cache,使用/opt分区的inode来缓解/backup分区inode不足的问题:
ln-s /opt/newcache /data/cache
3、更换服务器,用高配置的服务器替换低配置的服务器。很多时候用钱去解决问题比用技术更有效,堆在我办公桌上5台全新的DELL PowerEdge 1950 服务器即将运往IDC机房。一般不建议
1.4检查inode
Filesystem InodesIUsed IFree IUse% Mounted on
/dev/sda3 462384 59141403243 13% /
tmpfs 125517 1 125516 1% /dev/shm
/dev/sda1 51200 38 51162 1% /boot
11、磁盘空间满了,删除了一部分 nginx access 日志,但是,发现磁盘空间还是满的,请问
为什么?
删除的日志信息,一部分可能还是被进程调用,因此,需要重启nginx服务来释放进程;
或者实际生产环境中使用&gt;/log/access.log清空文件
12.请利用 shell 开发一个 rsync 服务的启动停止脚本并通过 chkconfig 进行开关机管理
root@sky9896 /]# chkconfig --add rsyncd
rsyncd 服务不支持 chkconfig
[root@sky9896 /]# cat /etc/init.d/rsyncd
#/bin/bash
# chkconfig: 2345 20 80 #添加该条即解决服务支持chkconfig
[root@sky9896 /]# chkconfig --add rsyncd
[root@sky9896 /]# chkconfig --list rsyncd
rsyncd 0:关闭 1:关闭 2:启用 3:启用 4:启用 5:启用 6:关闭
[root@sky9896 /]# /etc/init.d/rsyncd start
-bash: /etc/init.d/rsyncd: 权限不够
[root@sky9896 /]# chmod 777 /etc/init.d/rsyncd #授权后,即解决
[root@sky9896 /]# /etc/init.d/rsyncd start #启动服务
rsyncd is started.
[root@sky9896 /]# netstat -lnt|grep 873
tcp 0 0 0.0.0.0:873 0.0.0.0:* LISTEN
tcp 0 0 :::873
设置开机自启动的过程:
[root@sky9896 /]# chkconfig --add rsyncd #添加服务
[root@sky9896 /]# chkconfig --list rsyncd #显示服务
rsyncd 0:关闭 1:关闭 2:启用 3:启用 4:启用 5:启用 6:关闭
[root@sky9896 /]# chkconfig --del rsyncd #删除该服务
[root@sky9896 /]# chkconfig --list rsyncd
rsyncd 服务支持 chkconfig,但它在任何级别中都没有被引用(运行“chkconfig --add rsyncd”)
13.写一个 tomcat 启动脚本,手工 OK,但是放入定时任务就是不执行,请问为什么?
最近遇到了一些sh不能在crontab定时任务中自动执行的问题
期间由于不太了解,故走了一点弯路,现在总结下来可能第一次
进行设置遇到的问题。以绝后患!我所用过的操作系统为HP-unix&linux&sco-unix,均测试通过
1,首先确保sh脚本具有可执行属性
即chmod +x ***.sh
或chmod +777 ***.sh
2,确保sh脚本手工执行正常
即在当前系统内手工执行sh脚本以后能收到自己期望得到的结果
3,加载环境变量
这个问题是经常容易被忽略的问题,通常我们在第二步的时候手动执行脚本能得到自己想要的结果,可是设置好crontab之后,总不能得到自己想要的结果,总感觉脚本没有被执行。或者执行后没有得到正常的结果。很多均是由于没有加载所在用户的环境变量所引起的。因此最好在自己的脚本首两行添加环境变量的导入。如下:其中telstar是我在操作系统下所在的用户。在该目录下执行ls -a可以查看到.cshrc文件。我们在自己的sh脚本中增加source 该文件,将本用户的环境变量加载,那么以下的内容就能正常被执行了
#!/bin/csh#source /telstar/.cshrc
下面贴出我的定时重启tomcat的一个例子
#!/bin/csh#source /telstar/.cshrckill -9 `ps -ef | grep Djava.uti | grep -v tail | grep -v vi | grep -v grep | awk '{print $2}'`cd /telstar/tomcat/binsleep 15./startup.sh &
其实这里不加载环境变量的话,sh前加上绝对路径,应该也可以,这个没有测试,有兴趣的朋友可以尝试一下
#!/bin/csh
#source /telstar/.cshrc
kill -9 `ps -ef | grep Djava.uti | grep -v tail | grep -v vi | grep -v grep | awk '{print $2}'`
sleep 15
/telstar/tomcat/bin./startup.sh &
总之很多手动能正常执行的sh,crontab不能执行大多数情况是由于没有加载环境变量引起的,这里贴出来,以绝后患
#!/bin/csh
#source /telstar/.cshrc
kill -9 `ps -ef | grep Djava.uti | grep -v tail | grep -v vi | grep -v grep | awk '{print $2}'`
cd /telstar/tomcat/bin
sleep 15
./startup.sh &
14.apache 服务的常用工作模式及对应特点,企业如何选择对应模式。
apache的工作模式有:beos,event,worker,prefork,mpmt_os2。
查看:http –l
apachectl –l
beos工作模式(跟linux关系不大,或者暂时用不上)
在Beos系统上的工作模式,使用一个单独的控制线程来创建和控制处理请求的工作线程。
event工作模式(不太稳定,或者说暂时用不上)
event 模式由于把服务进程从链接中分离出来,在开启KeepAlive场合下相对worker模式能够承受的了更高的负载。event模式为 worker开发的变种模式,配置以及指令与worker完全相同。不过event模式不能很好的支持https的访问,有时还会出现一系列的问题。
worker工作模式(与php配合不好)
worker模式由于使用线程来进行处理请求,所以能够处理海量请求,而系统资源的开销要小于基于进程的服务器。同时worker模式也使用了多进程,每个进程又有着多个线程,以获得基于进程服务器的稳定性。
mpmt_os2工作模式(很少用,或者说暂时用不上)
mpmt_os2是专门针对OS/2优化过的混合多进程多线程多路处理模块(MPM) 。
重点:prefork工作模式。
1、编译的时候使用#–with-mpm=prefork对应的工作模式名称来修改工作模式。
2、prefork工作模式是linux下apache安装时候的默认工作模式,是使用最普遍的工作模式。
3、原理:有一台正在运行的apache服务器,用户A访问该apache的时候apache建立一个新的进程1处理用户A的请求。
这时又有一个用户B访问该apache,apache又建立一个新的进程2处理用户B的请求。
后来又有用户C,D,E访问该apache,apache又建立三个进程3,4,5处理他们的请求。
如果每当一个新用户访问该apache,apache再建立一个新的进程处理用户的请求,是不是太慢了呢?
所以apache的prefork模式在apache第一次启动的时候就建立5个进程,等待用户的连接请求,有一个用户访问,就有一个进程处理他的请求。
那么如果有5个用户同时访问apache,apache第一次建立的5个进程全部用光了,所以apache就再从新在建立5个进程,等待下一批用户的请求。
prefork模式会根据服务器的硬件情况,设定apache最多只能同时建立256个进程。再多的请求就只能等待前面的进程处理完毕在进行处理。
15.请描述 raid 0 1 5 10 的原理、相关特点 ,性能区别,集群中各角色如何选择 RAID。
RAID是磁盘冗余阵列(redundant array of independent disks)简称磁盘阵列。
RAID是一种把多块独立的物理磁盘按不同的raid级别组合起形成一个磁盘组,在逻辑上看是一块大的磁盘,可以提供比单个物理磁盘更大的存储容量或更高的存储性能,同时又能提供不同级别数据冗余备份的一种技术。
用RAID最直接的好处是:
提升数据安全性
提升数据读写性能
提供更大的单一逻辑磁盘数据容量存储
1.2.实现模式
软件磁盘阵列(software RAID),主要由电脑主板CPU处理数组存储作业,缺点为耗损较多CPU资源运算RAID,优点是价格低。
硬件磁盘阵列(Hardware RAID),RAID卡上内置处理器,不需要服务器的CPU运算。优点是读写性能最快,不占用服务器资源,可以用于任何操作系统,缺点是其售价很高,但在企业生产环境首选硬RAID解决方案。
DELL服务器,默认就会支持RAID0,1,如果RAID5,10就需要买raid卡了。
1.3 raid与LVM区别
LVM是在硬盘的硬盘分区上又创建一个逻辑层,以方便系统管理硬盘分区系统。
区别:
LVM:灵活的管理磁盘的容量,有一定的冗余和性能功能,但很弱。
RAID:更侧重性能和数据安全。
1.4 RAID级别间优缺点对比
运维生产环境常用RAID级别为RAID0,RAID1, RAID5 ,RAID10
RAID级别
最少磁盘要求
关键优点
关键缺点
实际应用场景
RAID0
1块
读写速度快
没有任何冗余
MySQL Slave(数据库的从库),集群的节点RS
RAID1
2块(只能)
100%冗余,镜像
读写性能一般,成本高
单独的,数据很重要,且不能宕机的业务,监控,系统盘
RAID5
3块
具有一定性能和冗余,可以坏一块盘
写入性能不高
一般的业务都可以用
RAID10
4块
读写速度很快,100%冗余
成本高
性能和冗余要求很好的业务。数据库主库和存储的主节点。
2.1 raid 0介绍
RAID 0 又称为Stripe(条带化)或striping(条带模式),它在所有RAID级别中具有最高的存储性能(磁盘容量不浪费,读写很快)。
RAID0 提高存储性能的原理是把连续的数据分散到多个磁盘上存取,这样,系统有数据请求就可以被多个磁盘并行的执行,每个磁盘执行属于它自己的那部分数据请求,这种数据上的并行操作可以充分利用总线的带宽,显著提高磁盘整体存取性能。
要制作RAID0至少要1块物理磁盘,例如DELL服务器带有RAID卡,如果不做RAID就不能使用磁盘,除非将磁盘直接接入主板,因此将一块磁盘坐RAID0使用。
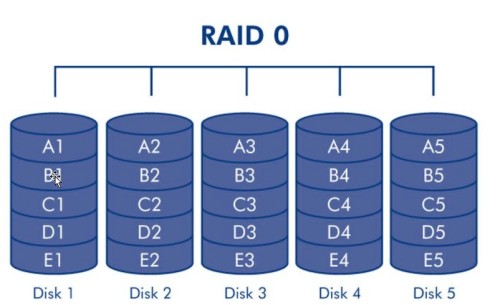
2.2 raid0 特点
关注点
描述
容量
是5块盘加在一起的容量。在所有RAID级别中具有最高的存储性能,原理是把连续的数据分散到多个磁盘上存取。
性能
理论上磁盘读写速度比单盘提升5倍,但由于总线带宽等多种因素的影响,实际的提升速率肯定会低于理论值,但是,大量数据并行传输与串行传输比较,提速效果显然毋庸置疑,磁盘越多倍数越小。
冗余
无任何冗余,坏1块盘,整个RAID就不能用了
场合
适合于大规模并发读写,但对数据安全性要求不高的情况,如mysql slave(数据块从库),集群的节点RS(服务员)
特点
速度快,无冗余,容量无损失
3.1RAID 1 介绍
RAID 1 又称为Mirror 或Mirrooring(镜像),它的宗旨是最大限度的保证用户数据的可用性和可修复性,RAID 1 的操作方式是把用户写入硬盘的数据百分之百的自动复制到另外一个硬盘上,从而实现存储双份的数据。
要制作RAID 1,只支持两块盘,整个RAID大小等于两个磁盘中最小的那块的容量,因此,最好使用同样大小的磁盘,在存储时同时写入两块磁盘,实现数据完整备份,但相对降低了写入性能,但是读取数据时可以并发,相当于两块RAID 0的读取效率。
关注点
描述
容量
损失50%的数据容量,列如2块1T的盘,做完RAID1后容量为1T
性能
Mirror不能提高存储性能,理论上写性能和单盘差不多。
冗余
在所有RAID级别中,RAID1提供最高的数据安全保障,冗余度100%
特点
100%冗余,容量损失半。
4.1 RAID 5介绍
RAID 是一种存储性能,数据安全和存储成本兼顾的存储解决方案。
RAID 5需要三块或以上的物理磁盘,可以提供热备盘实现故障恢复,采用奇偶校验,可靠性强,只有同时损坏2块盘时数据才会损坏,只损坏1块盘时,系统会根据存储的奇偶校验位重建数据,临时提供服务,此时如果有热备盘,系统还会自动在热备盘上重建故障磁盘上的数据。
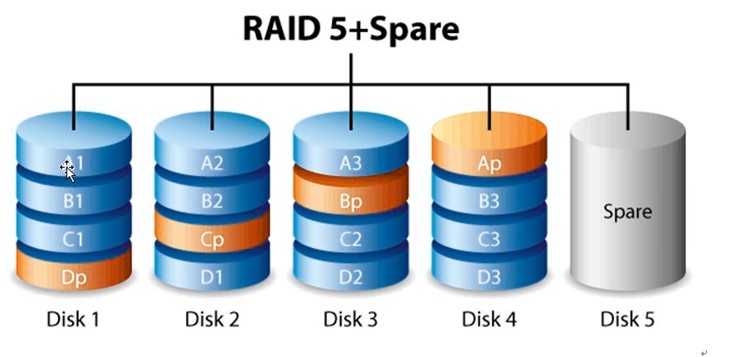
数据存储方式如图所示DP为D1,D2,D3的奇偶校验信息,其他以此类推,由图看出,RAID5 不对存储的数据进行备份,而是把数据和相对应的奇偶校验信息存储到组成的RAID5的各个磁盘上,并且奇偶校验信息和相对应的数据分布存储于不同的磁盘上,当RAID5的一个磁盘数据发生损坏后,利用剩下的数据和相应的奇偶校验信息区恢复被损坏的数据。
关注点
描述
性能
RAID 5 具有和RAID 0 相近的数据读取速度,只是多了奇偶校验信息,写入数据速度比单个磁盘写入操作稍慢。
容量
损失一块盘的数据容量10*600G 9*600G
冗余
可损失一块盘,RAID数据安全保障程度比RAID 1 低而磁盘空间利用率要比raid 1 高
场合
RAID 5 可以理解为是RAID 0 和RAID 1的折中方案,适合对性能和冗余都有一定要求,又都不是十分高的情况。
mysql的主从库都可以,存储也可以,普通的服务器为了减少维护成本,又保持一定冗余和读性能都可以做RAID 5
特点
容量损失一块盘,写数据通过奇偶校验,RAID 1和 RAID 0的折中方案。
5.1 raid10介绍
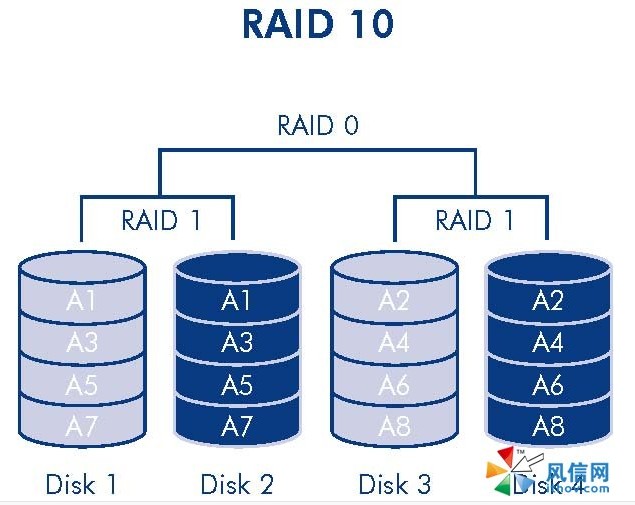
RAID 1+0 也被称为RAID 10标准,实际是将RAID 1和RAID 0标准结合的产物,在连续地以位或字节为单位分割数据并且并行读/写多个磁盘的同时,为每一块磁盘作磁盘镜像进行冗余。它的优点是同时拥有RAID 0的超凡速度和RAID 1的数据高可靠性,但是CPU占用率同样也更高,而且磁盘的利用率比较低。
极高的读写效率和较高的数据保护、恢复能力
注意一下Raid 10 和 Raid01的区别:
RAID01又称为RAID0+1,先进行条带存放(RAID0),再进行镜像(RAID1)。
RAID10又称为RAID1+0,先进行镜像(RAID1),再进行条带存放(RAID0)。
关注点
描述
性能
极高的读写效率和较高的数据保护、恢复能力
冗余
RAID10提供100%的数据冗余
应用场合
RAID 10适用于数据库存储服务器等需要高性能、高容错但对容量要求不大的场合
特点
RAID 1和RAID 0标准结合的产物
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 [email protected] 举报,一经查实,本站将立刻删除。