
微服务极大地改变了软件的开发和交付模式,单体应用被拆分为多个微服务,单个服务的复杂度大幅降低,库之间的依赖也转变为服务之间的依赖。由此带来的问题是部署的粒度变得越来越细,众多的微服务给运维带来巨大压力,即使有了 Docker 容器和服务编排组件 Kubernetes,这依然是个严肃的问题。
常见的追踪分布式系统调用链路的方式
在分布式系统场景中,一个请求可能需要经历多个业务单元的处理才能完成响应,如果出现了错误或异常,是很难定位的。因此,利用分析性能问题的工具以及理解系统的行为就变得很重要了。
对于早期系统或者服务来说,开发人员一般通过打日志的方式来进行埋点(常用的数据采集方式),然后再根据日志系统和性能监控定位及分析问题。采用日志打点的方式,虽然可以排查大部分的问题,但是侵入性非常大,且对于出现的紧急问题,往往并不能快速进行响应处理。对于排查性能问题,涉及更改的工作量更大,具体到调用的每个服务和服务里面的方法,得到的结果往往也是事倍功半。
除了日志打点的方式,有时甚至会出现开发人员直接连接服务器进行代码调试的情况,这种方式的优点是能够针对请求涉及的某个服务进行排查,或许也能快速解决,但其弊端是显而易见的,线上生产环境很多时候并不具备直接Debug 调试的条件,这种调试也是严重影响了线上服务的正常运行。特别是随着业务变得越来越复杂,现代互联网服务通常会使用复杂的、大规模的分布式系统来实现。
虽说传统的日志监控和服务器调试的方式也可以解决业务异常问题,但是很显然,这两种方式已经无法满足跟踪调用、排查问题等一系列需求了。
为什么需要分布式链路追踪
如上所述,随着服务数量的增多和内部调用链的复杂化,开发者仅凭借日志和性能监控,难以做到全局的监控,在进行问题排查或者性能分析时,无异于“盲人摸象”。
为了解决这个问题,业界推出了分布式链路追踪组件。Google 内部开发了 Dapper,用于收集更多的复杂分布式系统的行为信息;Twitter 开源了分布式链路追踪组件 Zipkin;同时,也有很多其他公司开发了自己的链路追踪组件。
分布式链路追踪不仅能够帮助开发者直观分析请求链路,快速定位性能瓶颈,逐渐优化服务间的依赖,而且还有助于开发者从宏观角度更好地理解整个分布式系统。
什么是分布式链路追踪
在微服务架构下,原单体服务被拆分为多个微服务独立部署,客户端的请求涉及多个微服务,从而无法知晓服务的具体位置。系统由大量服务组成,这些服务可能由不同的团队开发,可能使用不同的编程语言来实现,多实例部署,这些实例横跨多个不同的数据中心。在这种环境中,当出现错误异常或性能瓶颈时,获取请求的依赖拓扑和调用详情对于解决问题是非常有效的。
所谓分布式链路追踪,就是记录一次分布式请求的调用链路,并将分布式请求的调用情况集中展示。其中,调用详情包括各个请求的服务实例信息、服务节点的耗时、每个服务节点的请求状态等;分布式链路追踪还可以分析出请求的依赖拓扑,即这次请求涉及哪些服务、这些服务上下游的关系等,这对于排查性能瓶颈非常有帮助。
链路追踪与日志、Metrics 的关系
在上文我们提到早期通常是使用日志和监控的方式来排查系统问题的,但在工作中我发现一些开发者对链路追踪和日志、Metrics 三者之间的关系并不是很清楚,经常会混淆,因此这里我们就简要介绍下这三者。
Tracing 表示链路追踪,Logging 和 Metrics 是与之相近的两个概念。这三者的关系如下图所示:
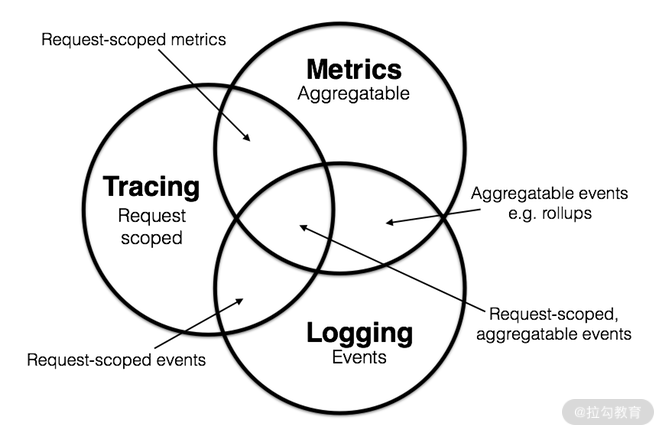
Tracing & Logging & Metrics三者的关系
-
Tracing:记录单个请求的处理流程,其中包括服务调用和处理时长等信息。
-
Logging:用于记录离散的日志事件,包含程序执行到某一点或某一阶段的详细信息。
-
Metrics:可聚合的数据,通常是固定类型的时序数据,包括 Counter、Gauge、Histogram 等。
同时,这三者相交的情况(或者说混合出现)也比较常见。
-
Logging & Metrics:可聚合的事件。例如,分析某对象存储的 Nginx 日志,统计某段时间内 GET、PUT、DELETE、OPTIONS 操作的总数。
-
Metrics & Tracing:单个请求中的可计量数据。例如,SQL 执行总时长、gRPC 调用总次数等。
-
Tracing & Logging:请求阶段的标签数据。例如,在 Tracing 的信息中标记详细的错误原因。
针对这每种分析需求,我们都有非常强大的集中式分析工具。
-
Logging:ELK(Elasticsearch、Logstash和Kibana),Elastic 公司提供的一套完整的日志收集以及展示的解决方案。
-
Metrics:Prometheus,专业的Metric 统计系统,存储的是时序数据,即按相同时序(相同名称和标签),以时间维度存储连续数据的集合。
-
Tracing:Jaeger,是 Uber 开源的一个兼容 OpenTracing 标准的分布式追踪服务。
通过以上讲解,你现在应该知道,Tracing、Logging 和 Metrics 这三者之间有一定的关系,既可以单独使用,也可以组合使用。每一个组件都有其侧重点,Tracing 用于追踪具体的请求,绘制调用的拓扑;Logging 则是主动记录的日志事件;Metrics 记录了请求相关的时序数据,通常用于性能统计。在分布式系统中,这三者通常是组合在一起使用。
分布式链路追踪的基础概念
分布式链路追踪组件涉及 Span、Trace、Annotation 等基本概念,这些概念还是比较重要的,所以下面我们就具体介绍下这些概念。
-
Span,分布式链路追踪组件的基本工作单元。一次请求,即发起的一次链路调用(可以是 RPC、DB 调用等)会创建一个 Span。通过一个64位ID标识Span,通常使用 UUID,Span 中还有其他的数据,例如描述信息、时间戳、parentID 等,其中 parentID 用来表示 Span 调用链路的层级关系。
-
Trace,Span 集合,类似树结构。表示一条完整的调用链路,存在唯一标识。Trace 代表了一个事务或者流程在系统中的执行过程,由多个 Span 组成的一个有向无环图,每一个 Span 代表 Trace 中被命名并计时的连续性的执行片段。
-
Annotation,注解。用来记录请求特定事件相关信息(例如时间),通常包含 4 种注解信息,分别包括:①CS(Client Sent),表示客户端发起请求;②SR(Server Received),表示服务端收到请求;③SS(ServerSent),表示服务端完成处理,并将结果发送给了客户端;④CR(Client Received),表示客户端获取到服务端返回信息。
链路信息的还原依赖于两种数据:一种是各个节点产生的事件,如 CS、SS,称为带外数据,这些数据可以由节点独立生成,并且需要集中上报到存储端;另一种数据是TraceID、SpanID、ParentID,用来标识 Trace、Span 以及 Span 在一个Trace中的位置,称为带内数据,这些数据需要从链路的起点一直传递到终点。
通过带内数据的传递,可以将一个链路的所有过程串起来;通过带外数据,可以在存储端分析更多链路的细节。
下图展示了 Trace 树的运行机制,通过 Trace 树我们可以了解一次请求过程中链路追踪的基本运行原理。
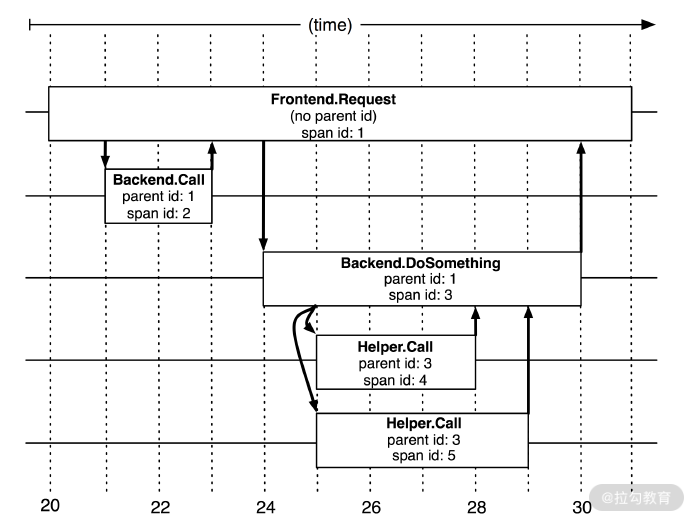
Trace 树
对于每个 Trace 树,Trace 都要定义一个全局唯一的 TraceID,在这个跟踪中的所有 Span 都将获取到这个TraceID。每个 Span 都有一个 ParentID 和它自己的 SpanID。上面图中 Frontend Request 调用的 ParentID 为空,SpanID 为 1;然后 Backend Call 的 ParentID 为 1,SpanID 为 2;Backend DoSomething 调用的 ParentID 也为 1,SpanID 为 3,其内部还有两个调用,Helper Call 的 ParentID 为 3,SpanID 为 4,以此类推。
Span 表示一个服务调用的开始和结束时间,即执行的时间段。分布式链路追踪组件记录了 Span 的名称以及每个 SpanID 的 ParentID,如果一个 Span 没有 ParentID 则被称为 Root Span,当前节点的 ParentID 即为调用链路上游的 SpanID,所有的 Span 都属于一个特定的 Trace,共用一个 TraceID。
小结
分布式链路追踪组件主要用来追踪分布式系统调用链路的问题。
本课时我们主要介绍了分布式链路追踪组件产生的背景,以及分布式链路追踪的相关概念。分布式链路追踪组件对于快速解决线上问题、发现性能瓶颈并优化分布式系统的性能、合理部署服务器资源具有重要的作用。在接下来的课时中,我们将具体介绍几种业界流行的分布式链路追踪组件,并选择其中的一款进行实践。
关于分布式链路追踪,你有什么经验和踩坑的经历呢?欢迎你在留言区和我分享。
精选评论
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。