
Prometheus-operator集群监控
github地址:https://github.com/prometheus-operator/kube-prometheus
具体的Prometheus是什么,为什么要用,什么时候用,还请移步本人其他随笔详细查看:https://www.cnblogs.com/v-fan/p/14057366.html
Prometheus-operator又是什么呢?
Prometheus-operator是专门用来监控k8s集群,并实现了一些自身特有的的自动化配置及管理,总得来说,就是使监控k8s集群更简单,更方便,由CoreOS率先引入其概念。
如下所示,是Prometheus Operator的架构示意图:
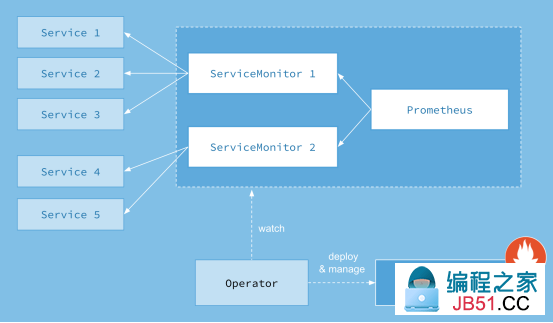
Prometheus Operator能做什么?
要了解Prometheus Operator能做什么,其实就是要了解Prometheus Operator为我们提供了哪些自定义的Kubernetes资源,列出了Prometheus Operator目前提供的️4类资源:
- Prometheus:声明式创建和管理Prometheus Server实例;
- ServiceMonitor:负责声明式的管理监控配置;
- PrometheusRule:负责声明式的管理告警配置;
- Alertmanager:声明式的创建和管理Alertmanager实例。
简单说,Prometheus Operator能够帮助用户自动化的创建以及管理Prometheus Server以及其相应的配置。
一、克隆项目到本地,进行服务构建
1、克隆
注意版本问题!!!页面明确指出分支所支持的kubernetes版本!!!
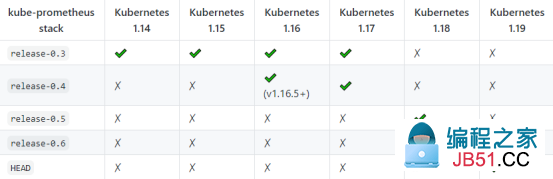
[root@Centos8 prome-git]# git clone https://github.com/prometheus-operator/kube-prometheus/tree/release-0.3
正克隆到 'kube-prometheus'...
remote: Enumerating objects: 9291,done.
remote: Total 9291 (delta 0),reused 0 (delta 9291
接收对象中: 100% (9291/9291),5.09 MiB | 1.04 MiB/s,完成.
处理 delta 中: 5692/5692),完成.
克隆到本地后,可以使用tree命令查看当前目录的树状结构
2、主要配置进行修改
cd kube-prometheus/manifests
## 主要的服务构建yaml文件全部在这里了
## 需要注意的是,要将:
Grafana-service.yaml
prometheus-service.yaml
alertmanager-service.yaml
## 三个svc的访问方式修改为NodePort模式,方便集群外的服务访问
vim grafana-service.yaml
apiVersion: v1
kind: Service
metadata:
labels:
app: grafana
name: grafana
namespace: monitoring
spec:
type: NodePort
ports:
- name: http
port: 3000
nodePort: 30201
targetPort: http
selector:
app: grafana
以下两个配置文件同样是修改此处,不再详细打印配置
vim prometheus-service.yaml
...
vim alertmanager-service.yaml
...
3、可以提前将要使用的镜像pull下来,使启动时更快
cd kube-prometheus/manifests
for i in `awk -F :' /image:/{print $2":"$3}' *.yaml`;do docker pull ${i} ;done
4、开始创建yaml
## 先创建setup目录下的所有yaml,因为这是manifests/下yaml的基础
## setup中的yaml主要创建了自定义的namespace和crd(CustomResourceDefinition;自定义kind类型及api组和版本)
kubectl create -f manifests/setup
## 上一步执行成功后,可以查看自定义crd是否创建成功
[root@Centos8 manifests]# kubectl get crd
NAME CREATED AT
alertmanagers.monitoring.coreos.com 2020-11-10T08:19:16Z
podmonitors.monitoring.coreos.com :17Z
prometheuses.monitoring.coreos.com :17Z
prometheusrules.monitoring.coreos.com :18Z
servicemonitors.monitoring.coreos.com :18Z
## 查看自定义的kind:servicemonitors 创建是否成功
until kubectl get servicemonitors --all-namespaces ; do date; sleep 1; echo "";
## 开始创建Prometheus-operator资源
kubectl create -f manifests/
如果过程报错想删除,可以执行:kubectl delete --ignore-not-found=true -f manifests/ -f manifests/setup
5、检查是否启动完毕
kubectl get all -n monitoring
Pod全部Running正常后,通过svc开始访问grafana和prome即可
二、以上服务构建完成,通过grafana访问prome
1、访问prome:http://hub.vfancloud.com:30202

2、访问grafana:http://hub.vfancloud.com:30201
默认账号密码:admin/admin
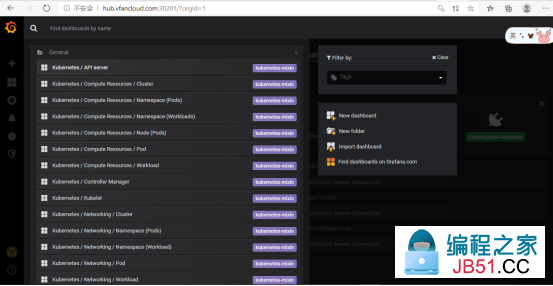
具体资源的使用情况可以点进模板自行查看:
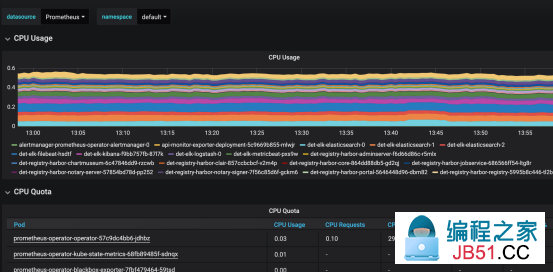
需要注意:此搭建全部是引用了Prometheus-operator的默认监控配置,如果有自定义需求,完全可以自己修改yaml文件中的values等信息;设置告警途径等。
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。