

黄劲 分布式实验室

云原生技术生态近几年狂飙猛进,现已成为互联网公司的主流服务端技术栈。公司要快速响应市场变化和需求变更,就离不开自动化流水线进行编译、打包和部署,如何基于Kubernetes落地CI/CD就是DevOps团队需要解决的首要问题之一,同时也是衡量公司DevOps能力成熟度的重要指标之一。本文主要分享iHerb在Kubernetes技术栈中CI/CD落地的情况和实施过程中的一些经验总结。背景

本人目前就职于一家全球电商公司,公司总部设在美国, 自1997年开办公司发展到现在,已经面向包括中国在内全球170多个国家和地区开放了线上购物电商业务。
对于这样的业务体量,在国内云应用才刚起步的时候公司早以开始使用一些大型云平台诸如AWS和GCP等来部署生产环境了。
而当Kubernetes问世之后,公司就开始尝试着使用Kubernetes来部署应用,并在这几年将一些原本用VM部署的应用迁移到了Kubernetes上,以适应更快的市场变化,以及以更快的速度开辟新的市场。
对于Kubernetes的特性、优点和优势在此就不做赘述了,本文着重论要论述的是我们在Kubernetes环境上的CI/CD落地和实践。
持续集成与持续交付
首先我们来温习一下CI/CD的理念。
持续集成是一种编码理念和一系列实践,可以促使开发团队实施小的更新并经常将代码检入版本控制存储库。由于大多数现代应用程序需要在不同平台和工具中开发代码,因此团队需要一种机制来集成和验证其更改。
CI的技术目标是建立一致的自动化方法来构建,打包和测试应用程序。通过集成流程的一致性,团队更有可能更频繁地提交代码更改, 更频繁、更早的集成意味着更早的发现问题。通过持续集成,可以及时发现和解决代码故障,提高代码质量,减少故障处理成本等等,从而实现更好的协作,提高软件交付质量。
CD则是在从持续集成结束的地方开始处理制品的持续交付,负责自动将应用程序交付到选定的基础架构环境。大多数团队都会使用多个非生产环境(例如开发和测试环境),所以需要CD流水线确保有一种自动化的方式将制品包推送到目标环境上。然后,CD自动化脚本可能需要重新启动Web服务器,数据库或其他服务,并执行一些必要的服务调用,或者在部署应用程序时遵循其他过程。
持续集成/持续交付(CI/CD)是一种软件开发实践。在流水线中若再加上如自动回归、性能测试等自动化测试环节,则可以帮助团队成员频繁、快速得集成代码,以测试他们的工作成果,从而尽快发现集成后产生的错误,最终为用户提供高质量的应用程序和代码。
持续集成(CI)和持续交付(CD)体现了一种文化,一系列操作原则和实践集合,使应用程序开发团队能够更频繁,更可靠地交付代码更新。所以CI/CD流水线是DevOps团队实施的最佳实践之一,也是衡量公司DevOps技术成熟度最重要的指标之一。
虽然大部分公司在使用Kubernetes之前就已经搭建了CI/CD流水线,而在业务迁移到Kubernetes环境上后,如何在Kubernetes上搭建CI/CD流水线就成了必须尽快解决的一个重要问题。
公司的Infra架构
首先给各位看下图:
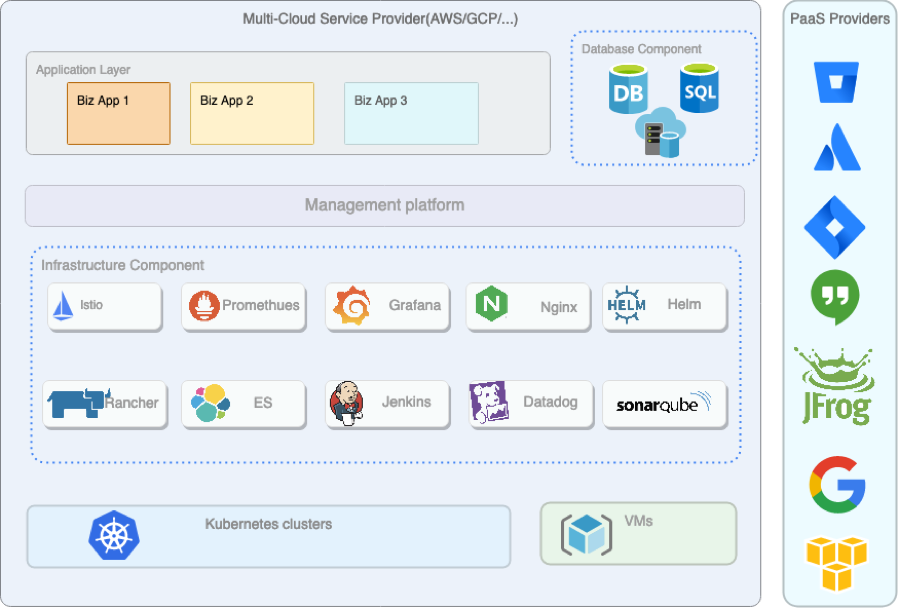
Infra架构图
如上图所示是当前公司Infrastructure架构,最底层是多云平台,这样可以节省机房的运维成本。在云平台上同时在使用VM机和云厂商的Kuberneters集群,通过***将办公网络与云平台网络连接起来。
在每个Kubernetes集群之内,搭建了一些公用基础设施和应用比如nginx-ingress、Istio、Datadog、Promethues等等,再上面一层就是按照业务逻辑拆分成了各个namespace,以实现业务层的相互隔离。
CI
在看完了Infra架构后,我们现在来看下怎样搭建CI流程。
CI架构
目前我们在CI流程中用到的平台和工具包括:
Bitbucket:用来管理源码和yaml配置
Jenkins:CI Pipeline引擎
JFrog:中间制品仓库,以节省自建和维护制品仓库的成本
SonarQube:存储和管理Unit test和Code analysis的报表(现已换成SonarCloud)
Allure report:另一个使用比较多的测试工具
Helm:打Helm包用
架构图如下所示:

CI架构图
CI流程
我们在编写CI流程的时候,给开发提供了一份yaml文件(build.yaml),用来让开发人员可以按照不同项目的需求来配置流水线,以实现高度定制的需求。具体流程可参考下图,其中开发可自行删减和调整任一节点。
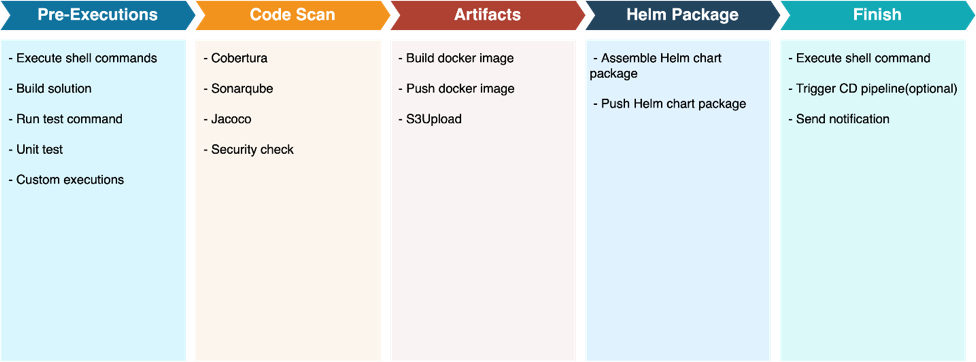
CI流程图
首先我们看下CI任务里面包含了Pre-Executions、Code Scan、Artifacts、Helm Pacakge、Finish Executions五大节点,在大的步骤节点内可由开发人员自由配置组合需要执行的任务和需要调用的组件。
Pre-Executions主要内容为拉源码包,执行shell脚本,执行编译脚本,执行unit test 或其它test 脚本。
Code Scan环节主要执行些第三方的代码扫描工具并提交报告到相关平台上。
Artifacts环节以打docker image为主,将编译的结果打包到镜像里然后提交到如JFrog这样的制品仓库上。
Helm Package环节则是通过之前生成好的docker image自动填入Helm包并将打好的helm package提交到JFrog上。
Finish是CI的最后一个阶段,用于在流水线结束前执行些自定义命令,或是发送消息给Chat、Email或其它相关平台。如果用户需要自动发布到测试环境,也是从该节点发出请求转到CD 环节。
总之,在走完CI pipeline后所有的产出都会统一保存到JFrog上。与CD交互也是靠制品仓库做连接,这样可以保证CI与CD之间的隔离。
CD
公司早期是使用Harness来进行CD部署的,但因后来发现有些部署问题以及安全漏洞,不太适合公司环境,所以打算用另外的方案来代替Harness。
我们在做CD选型方案的时候团队以及几位领导希望在资源和人手有限的情况下能快速、安全、稳定地搭建CD Pipeline,所以多方比较之下还是选择了用Jenkins + Helm的方案来做CD。
CD架构
我们在CD流程中用到的工具及作用如下:
JFrog:用于分发helm chart和docker image
Bitbucket:用来管理helm values config配置信息
Helm:部署helm chart用
Jenkins:CD Pipeline引擎,以及用来存储Kubernetes clusters的Token。我们公司在CD搭建的过程中将Jenkins拆分成了两个,一个专供CI之用,另一个只用来处理CD操作,这样实现了CI/CD相互隔离,互不影响。
CD流程
CD的核心就是通过输入各种参数最终自动生成所需要的Helm指令,其间还需要拿到各个cluster的config values yaml文件,以便根据不同的cluster来配置不同的程序运行环境设置。具体流程图可以参考下图:
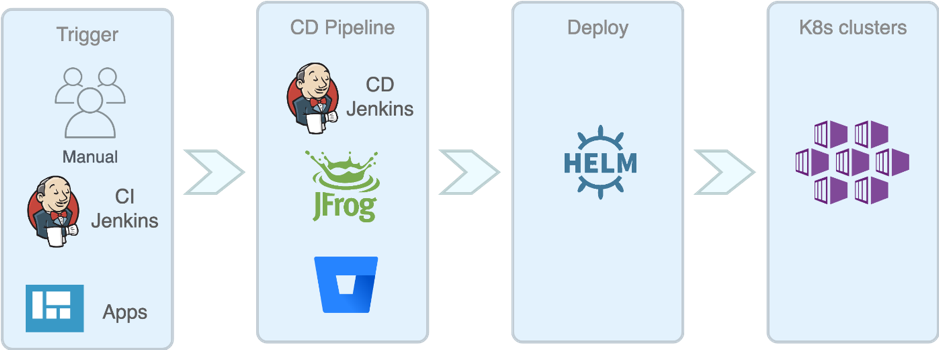
CD流程图
在CD中我们就没有再用yaml来控制流水线,因为CD的Pipeline相对来说会简单些,不过另外有用到config file mangement来管理CD的一些app相关配置项。
经验总结
实施中的一些经验之谈
在Kubernetes上的CI/CD与以前在VM servers上的发布有了本质的区别,抽象出来的配置项多了很多,不仅要学习Kubernetes的yaml配置,也要学习Helm的配置,甚至还得看Istio的一些配置,所以对于开发来说也有个学习的过程,并且会占用他们一部分时间去适应和调整这些配置。
虽然DevOps team可以通过自动化脚本及UI界面将这些yaml配置封装起来,提升Pipeline的易用性,但这样做不仅会大量占用DevOps团队的人力成本和时间,同时也剥夺了开发接触Kubernetes和Helm的机会,所以就算有些开发对于Kubernetes或Helm完全是0基础但还是允许他们可以自行配置helm chart,并在不断试错中成长,毕竟helm chart只有在配置正确的情况下才会发布成功,虽然这会占用开发的一些时间。
Troubleshooting
另外关于CI/CD的Troubleshooting问题,因为Jenkins的console log功能比较强大,能把很多过程和日志输出来让用户直接在浏览器中就可以查看,在加上我们在Pipeline中埋入的很多输出点,开发完全可以全程自行Troubleshooting查找问题,同时这样也可以帮助开发理解和掌握Kubernetes及Helm的相关知识。
安全问题
在搭建Pipeline的时候在安全方面需要注意一下,不能将credential信息以明文方式输出到console log,且也不能在source code和config仓库中出现明文的账密信息,如若需要配置账密,我们的做法是将密码保存在config repo的secrets.yaml文件中,并用helm secret + aws key的方案对其进行加密操作,以弥补Kubernetes secret机制本身的一些不足。
后记
虽然目前在业界CI/CD方案中Jenkins的热度一直很高,不仅系统稳定,功能强大,插件资源丰富,而且社区支持较好,相关资料也比较多;但是考虑到其单点master部署以及JVM的执行效率问题,我们还是希望将来能使用云原生基于Golang开发的CI CD解决方案。
我们拿了目前云原生开源CI/CD多个产品进行了横向比较,结论是目前CI这块还是Jenkins做得最好,不过CD阶段可以考虑用其它云原生的开源软件比如Spinnaker、Tekton以及Knative等来代替。但万变不离其宗的一点是我们不仅要把系统搭建起来,还得让它变得适合给开发人员使用,同时即要保证稳定性也要提供扩展性,以应对复杂多变的需求。
所以我们也在开始尝试自主开发公司的CD Portal,并逐步把一些功能往上面迁移,希望将来能用CD Portal将所有的开源软件都封装起来,从而提升公司所有开发人员编译部署以及管理线上系统配置和版本发布的效率。
Q&A
Q:deploy阶段是如何保证线上服务稳定性的?A:因为是用的Helm在Kubernetes cluster上进行安装,所以通过Helm 的版本管理机制+ Kubernetes自带的滚动升级机制,再加上cluster可切换流量的机制,通过多重保护机制来保证服务的稳定性。另外就是要通过监控的手段如大家耳熟能的Prometheus、ELK、Grafana等来监控服务的稳定性。
Q:API版本管理是如何做的?如果出现不向后兼容的API改动,Rolling Update应该不好用了,如果要保证服务的可获得性(无down time),这种情况应该如何发布?A:1. 对开发团队来说需要在代码层面处理好API的兼容性问题,并通过各种测试手段来做确保API的可用性。2. 对Infra team来说,会通过如Istio这样的Service Mesh平台,通过与Istio结合实现Canary发布,再加上监控系统来确保服务的可用性。
Q:Jenkins是跑在Kubernetes上吗?Jenkins X?A:是的,我们是将Jenkins用Helm安装到Kubernetes上,并给到每个Jenkins独立的Node资源,因为Jenkins在执行job的时候大多会起slave pod,再加上Jenkins master本身也比较吃内存,所以对资源的要求会比较高。Jenkins X以前有做过调研,问题1是很难将现在在Jenkins上已建好的项目迁移到Jenkins X;2是有安全问题;3是不符合我们公司的情况,因为Jenkins X是将CI/CD整条线都放在一套系统内,而我们公司实际的需求是希望CI/CD分开,并且需要方便在中间插入安检与测试环节。所以就没有选择JenkinsX 方案。
Q:Helm Chart是跟服务垂直打包发布吗(单独项目)?A:如果你指的是通过Helm umbrella模式发布的话,目前我们实际应用中几乎没有这样的案例。目前是每个team自行发布application的Helm包,不做依赖发布。这样好处是实现了互相解耦,况且现在用到umbrella的情况也不多。如果真有需要依赖发布的话我们也是支持的。
Q:DevOps的发布过程你们运行哪些自动化测试?A:CI阶段支持各种语言自带的unit test,然后是第三方的如Cobertura、SonarQube、JaCoCo等,而且我们也开发了功能支持在CI过程中的mock test。CD之后,主要是在test环境,可支持allure + pytest、kubejob test、Selenium/Zalenium、performance test等,这部分主要由QA团队来主导,我们负责在Pipeline中加入对test的支持。
Q:docker image的tag管理是如何进行的?如何和代码commit hash以及部署环境对应起来?Kubernetes的service/deployments/pods都会打哪些tags和annotations?A:一般tag我们是在CI Pipeline中自动打上去的,tag里会加上commit hash前7位字符,在image上打完tag后,会由程序自动填入到helm package里。Kubernetes的service/deployments/pods的 tags和annotations一般由开发团队按需求自行配置,一般开发最关心的deployment的配置还是在于namespace、replicas、resources、Liveness 和Readiness。我们自行写了一些helm template给开发用,这样也算是简化了Helm的使用
Q:为何又有Prometheus之后,架构图里还有Datadog,能讲讲两者区别么,什么场景下,两者都用了。什么原因呢?A:Prometheus是Kubernetes技术栈必用的监控方案,后续的Kibana和Grafana都要用到Prometheus的数据,开发人员在Helm包里也会加上很多Prometheus rules用于监控服务。Datadog则是买的第三方服务,是给审计、安全和NOC团队用的,对于这些专业团队会在Prometheus的基础上结合两边的数据一起看。Datadog目前提供的是数据聚合和监控功能,算是相对来说比较便宜的APM,如要实现数据分析则需另寻它物。
Q:GitLab CI/CD不是很好用更适合程序员吗?为啥一定要用Jenkins?A:GitLab CI/CD比较适合小团队来使用,如果要涉及到多种Plugins的支持以及多平台的接入,和面向公司级别的CI/CD系统,目前来说还是Jenkins做得比较好。
Q:开发人员如果想要登陆Kubernetes集群debug,这一块针对Kubernetes的权限控制是什么样的?A:我们是用Rancher来实现Kubernetes权限管理和控制的,开发可以通过Rancher登录上去看Pod的log或做Debug, 不过大部分问题都可以在CD Job的console log直接看到,这样也省去了登录的麻烦。
Q:可以分享一下贵公司CI/CD的Git流以及环境流转吗?A:Git流看业务team需求,有用标准git flow的,也有用Feature分支工作流的。环境流转就是test -> preprod -> prd流转,都是用的云上的Kubernetes cluster。
Q;您这一块把CI/CD分开主要是基于什么考虑,CD是由CI自动触发然后自动部署的吗?跨Jenkins的调用是如何实现的呢?A:之所以要分开,1是因为希望资源互不干扰,另外还有安全上的考虑;2是因为团队需要,因为他们并不希望CI后就直接CD,而且也希望将两边的job分开,这样也好排查问题。3是因为CD的时候需要对config进行调整和试错,这样就不用把Pipeline拉得太长还得从CI开始走。4是希望将来方便在CD这块不用Jenkins而是改用别的系统。CD 是手动或webhook触发的。跨Jenkins调用也可以通过webhook互相调用,在这里我们选用的是“Generic Webhook Trigger”插件。
Q:可以谈谈分支管理,以及中间件变更的管理吗?A:关于分支管理如果是指代码层的,建议走git flow ,如果您指的是分支环境的部署,建议是Canary方案部署,然后用Istio导流,并通过API参数来判断调用哪个分支。中间件变更如果是如npm包或是nuget package这样的包管理的话,CI是支持自动build和提交的,对于开发来说只要配好包的仓库(我们是用的JFrog来管的),配置好包的version就可以了。
Q:a. 当系统有多个子系统,每个子系统都有一套自己的charts和value时,在贵CI系统中是如何将各子系统集成来做整体测试的呢?b. 想了解下贵集群的扩容和缩容机制,在既加快新增部署又减少浪费方面有什么好的实践可以分享么?c. CI中部署系统成功后,是如何进行测试的呢?A:a. 在CI中要通过docker-compose.yaml来mock出这套环境,因为安全问题所以CI环境是无法连到DB以及cluster的。或者在UT中开发由开发做mock 测试,相对来说会简单点。b. 直接买云上的Kubernetes,AWS/GKE等大厂云都早已解决了这个问题,里面有关于弹性伸缩的配置。c. 部署成功后会由QA编写和执行测试脚本来进行测试,我们在CD的配置项里做了这个功能,就是CD之后自动触发QA job并开始执行测试代码。
Q:生产环境如何使用的CI/CD?这套CI/CD 有没有快速搭建的脚本?A:我们这套不是开箱即用的,只能一点点搭上去,而且还有开发和推广的工作在里面。如果想要开箱即用的可以试下Jenkins X。
Q:配置文件管理是怎么做的?不同环境的构建参数不同,如何在CI中体现,CD之前要重新构建吗,还是复用CI的image?A:1. 配置数据都在helm values.yaml里,然后我们把config repo里的values.yaml拉下来到jenkins job workspace,再通过Helm整合进行发布;2. CD的时候是复用CI的image 的。
Q:测试多环境如何在CI/CD中复用配置,比如有四套测试环境,不会每个环境否配置套新的CI/CD吧?A:只要在config repo中跟据cluster配置不同的values.yaml,比如values.cluster1.yaml,values.cluster2.yaml,这样就可以了,然后只要执行CD即可。
Q:如何工程化调试项目,比如有500个应用,每个都有4套以上环境,量很大,怎么快速调试?A:关于您说的这个需求在我们公司还没有尝试过。但要如果要实现这样的场景,从理论上来说,首先Kubernetes cluster可以自动生成出来,其次在部署之前config repo也要按cluster环境配好,然后可以用helm umbrella来实现整个集群应用的自动化搭建部署,最后test script覆盖率要达到一个很高的百分比才行。在这里自动化测试是个关键因素,不过我不是QA专家,所以还是得请教QA的人看是否能实现这样的测试量级。
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 [email protected] 举报,一经查实,本站将立刻删除。