

前言:
这两天做了一个故障检测的小项目,从一开始的数据处理,到最后的训练模型等等,一趟下来,发现其实基本就体现了机器学习怎么处理数据的大概流程,为此这里记录一下!供大家学习交流。
本次实践结合了传统机器学习的随机森林和深度学习的LSTM两大模型
关于LSTM的实践网上基本都是利用了Mnist数据集,但是其他方面的很少,这里我们就来看一下其在本问题的分类效果
依次从如下六部分介绍,程序运行顺序也是如此:
1)数据集
2)预处理
3)模型训练
4)模型测试
5)可视化
6)总结感悟
代码部分:本篇仅仅截取部分主要的关键步骤来辅助讲解,关于全部代码的细节:
python-Machine-learning/tensorflow/LSTM at master · Mryangkaitong/python-Machine-learning · GitHub
同时因为数据集较大,github上传不便,所以这里使用了百度网盘:
链接:https://pan.baidu.com/s/1S82igOQpU80uv7kqHPwABQ
密码:ibim
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
数据集:
下载好数据集解压后为dataSet
dataSet中 "原始数据集" 目录下就是本次实践要用到的数据集:

其中2MWFeatureList.xlsx中是特征具体含义说明:
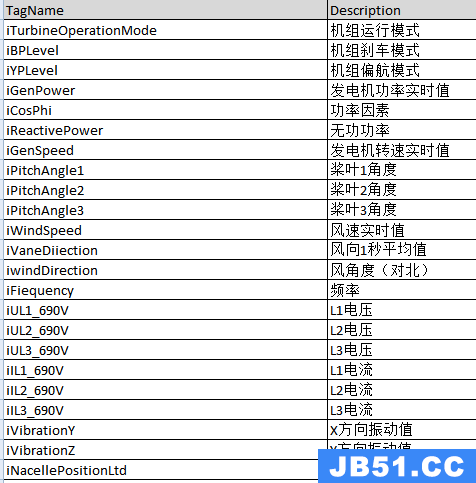
这里只截取了部分
WT_Faultcode字段是故障编号,就是我们要预测的结果即label,一共有12种编号,即这是一个12种分类问题,后面会详细看到。
20003001#2017-03.csv中就是具体的一个个样本。
------------------------------------------------------------------------------------------------------------------------------------------------------------------
预处理:
一 code中Preprocess下的normalization部分:
准确来说这部分主要做了如下事情:
1)初识数据集
2)去除重复项
3)初步筛选必要特征
4)提取label
5)归一化
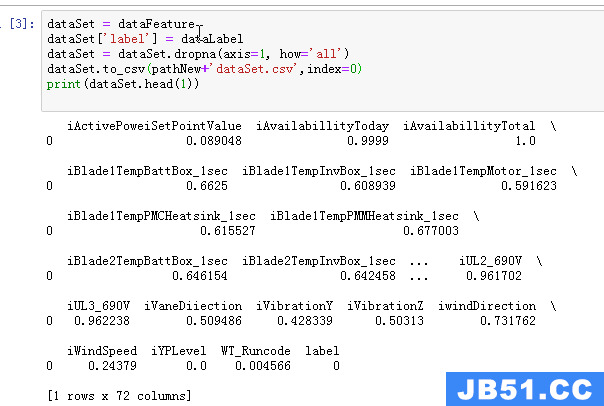
首先加载数据集,然后读取一个样本来看看其具体形式:

可以看到其一共有138列,除去label字段,还有137个字段,其一共有137个特征可以利用。
具体特征名字呢?

再来看一下label的具体形式:

可以看到其所有的故障编号,一共12种。
从上面也可以看出有些特征是缺省值,其实用office 的excel打开20003001#2017-03.csv来看会更加直观,你会发现有些特征是没有值的,所以我们完全可以抛弃它,例如:
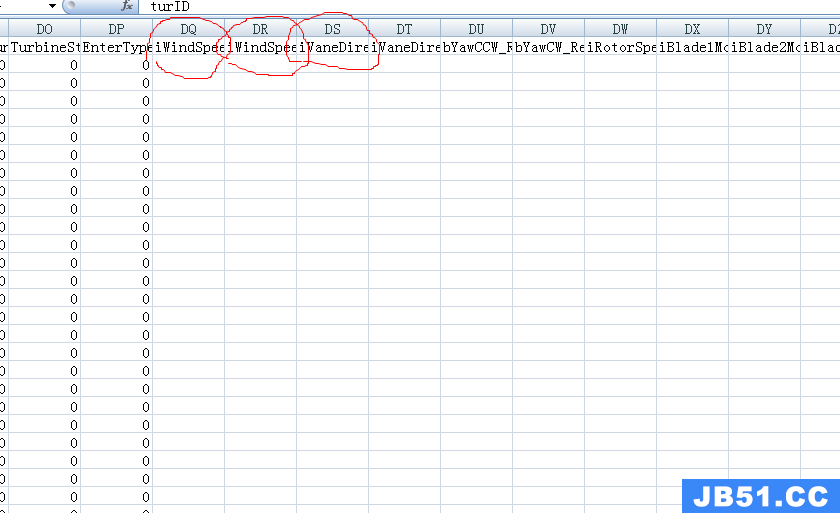
可以采用drop来去掉这些特征,笔者这里是选择提取有值的特征:

接下来就是转化label为更常见的0,1,2,3,,,11,同时将特征进行归一化,最后保存为两个csv文件:即“Preprocess”目录下的特征predataFeature.csv和标签dataLabel.csv:
二 code中Preprocess下的LabelGroup部分:
该部分做了两件事:
1)二次筛选特征 后保存为 dataSet.csv
2)根据每个类别下样本数量的多少分成了丰富集合稀缺集两组。
在经过了上述第一部分归一化后,有的特征虽然有值,但是我们进行了归一化,归一化的公式大家在上面也可以清晰看到,分母是最大值减最小值,倘若某个特征下的所有样本值都一样呢?即分母为0,那归一化后是不是就是NaN啦,事实上也可以这样想,该特征下所有类别的值都一样,那么其对分类来说没有提供任何有用的信息,所以可以也可以去掉该特征,即二次筛选特征:
然后在上述基础上来看一下每个每个故障编号下有多少个样本:

可以看到,这里样本可以说极其不均衡,有的类别样本多达百万,有的只有4个,所以这里就涉及到怎么均衡采样,这是一个大的讨论问题,大家可以各抒己见,但通常就是过采样和欠采样,笔者这里采用的是结合两种方式,即经过采样最后将所有类别的样本数都定位1566,所以这里分为两组group1是0,4,6,7,9,11 gropu2是3,5,8,10.分别保存为两个csv即“LabelGroup”部分的group1.csv和group2.csv,在接下来的部分便可在group1上面欠采样,在group2上面过采样。

三 code中的Sampler部分:
该部分很简单,正如上述所说,就是做了欠采样和过采用两件事:
这里使用SMOTE进行了过采样,使用了RandomUnderSampler进行了欠采样:
经过上述过程后每个类别样本数就是1566,最后将其保存为“Sampler”部分的dataSetSampler.csv:

注意:在使用SMOTE进行过采样的时候,可能会报以下错误:

原因就是SMOTE本质是采用的KNN算法,这里的K它设置成了6,即算法要用到最近的6个样本来计算,而我们的类别3只有4个样本,要求是n_neighbors<=n_samples,6明显不小于等于4所以报错,怎么办?有很多方法具体可以看:
笔者这里的做法就是将类别3扩充一倍即变为8个:

四 code中Preprocess下的ExtractionFeatures部分:
通过上面我们可以看到特征树多达100多个,所以我们有必要筛选出其中比较重要的特征,以此来训练神经网络,关于机器学习中可以用来筛选特征的模型有很多,比如Xgboost等等,笔者这里采用的是随机森林,关于Xgboost也是目前被认为最具泛化的机器学习模型之一,在很多比赛和实际问题中大放异彩,有兴趣的同学,这里推荐笔者的两篇博客,分别为其理论篇和实践篇,另外推荐一篇关于随机森林实践篇,该篇横向对比了随机森林的优势,分别介绍了其在分类和回归上面的应用,可视化较好。
Xgboost理论:https://blog.csdn.net/weixin_42001089/article/details/84965333
Xgboost实践:Xgboost实践+第一名天池o2o优惠券的使用预测思路完整版_爱吃火锅的博客-CSDN博客_o2o优惠券使用预测第一名
随机森林实践:https://blog.csdn.net/weixin_42001089/article/details/79952619
好了,安利之后,我们言归正传,哈哈
我们将上述dataSetSampler的数据集先划分为训练集和测试集(测试集比例是0.3),以此来训练随机森林,训练好后,便可以看到特征的重要程度:

从这里的排行榜可以看到,WT_Runcode这个特征最重要,以此类推,,,,
同时我们来用训练好的随机森林模型来检验一下其在测试集上面的性能:

怎么样,是不是接近完美,嗯嗯确实不错。
别忘了,该部分我们的目的是要提取出重要的特征,根据上述排行榜,我们就取前7名吧:
['WT_Runcode','iTurbineOperationMode','iBPLevel','iAvailabillityToday','iYPLevel','iIL1_690V','iBlade1TempBattBox_1sec']然后保存其为csv文件,即dataSet中“ExtractionFeatures”目录下的dataSetSamplerfilterFeature.csv
为了验证,我们再用dataSetSamplerfilterFeature.csv来训练随机模型即用筛选出来的特征来训练模型,看其效果:

可以看到,性能虽有下降,但是微乎其微,看来我们筛选出来的特征很有代表性。
以上模型训练和性能检测都是在经过均衡采样后的数据上完成的,接下来我们就来看看其在原始数据上面(第二部分的dataSet)即没有经过均衡采样上面数据的真真表现,由于dataSet过大,这里仅拿出其中5%来测验:记得先shuffle即打乱:

可以看到,效果也还是不错的,类别10本来一共才用8个,没抽取到正常。
最后我们也对dataSet这个原始数据提取体征,保存为csv文件即dataSet中“ExtractionFeatures”目录下的dataSetfilterFeature.csv
目的就是在后面神经网络训练中,依次作为原始数据进行性能检测。
------------------------------------------------------------------------------------------------------------------------------------------------------------------
模型训练:
code中Model下的ModelTrain和Batch
这里选用的模型正如前言所说是LSTM,代码中都是详细注释,这里做以下几点说明:
1)以下路径分别是,训练数据集路径,模型保存路径,训练集和测试集logs路径(用于后续的可视化)

2)训练的时候我们是采用批处理的,关于为什么,相信了解深度学习的人都知道了,不懂的自行百度,这里就不展开讨论啦
所以就设计到每一次取一个批次,具体怎么取呢?网上大部分关于神经网络的训练采用的数据集都是别人做好的,有相应的API例 如Mnist数据集可以直接调用next_batch便可以得到一个批次,但是我们这里没有,所以我们需要自己干这个事情,这里简单写了个API即code中Batch中定义的一个类,具体怎么写很简单,大家直接看代码很容易就懂了,关于更多的讨论大家可以看:
python - how to implement tensorflow's next_batch for own data - Stack Overflow
导入我们定义的类,然后便可以同样使用next_batch得到一个批次:



next_batch的一个参数就是batch_size即一个批次具体大小,需要注意的是,我们这里是在加载了数据集后,先划分为训练集和测试集,然后分别在训练集和测试集上面应用了我们定义的Batch,去看该模块具体实现你会发现它默认的是batch_size小于总样本数,也就是说,假如我们划分出来训练集是20个样本,测试集是10个样本,那么我们在选用batch_size的时候可以选择10以下的,否则当我们选择比如12,那么在训练集上面选取一个批次是12的肯定没问题,但是在测试集上面选一个12大小的批次就会出错,当然啦,我们定义的Batch还不够完善,改改不就行了,是的,可以这么做,但是我们这里划分出来的测试集都是7000多个吧,所以我们一个Batch_size这里取5000,应该是够用了(一般来说,因为计算资源有限,Batch_size都是取在几十或几百的,但是由于我们这里的特征数很小,相对来说就可以将Batch_size取得更大些),至于为什么train的Batch_size和test的Batch_size要保持一致,很简单,模型输入端的数据格式要一致呀!!!
3)LSTM的输入是inputs 为 (batches,steps,inputs)(当然了batches和 steps也可以互换,具体见代码)
batches就是上面的Batch_size
关键是steps和inputs怎么取?在LSTM处理图片的过程中这里就是图片的宽和高。
这里就简单说一下其含义吧:
steps其实是一个时间序列,即多处理和顺序相关的问题,例如语音就很适合用LSTM ,而inputs的话就是特征数。笔者这里是这样设置的:

n-1在这里就是特征数
也可以反过来设置:
![]()
在本文问题上实践中证明:
第一种收敛更快,效果好一点。注意并不是所有情况都是这样,只是说该问题,不同问题有不同问题的特性,还是要随机应变。
4)这里的label标签采用了one-hot形式,这在深度学习分类问题中也很常见啦,顺便提一下:
y=tf.placeholder(tf.float32,[None],name="y")
y_one_hot = tf.one_hot(tf.cast(y,tf.int32),n_classes,on_value=1,off_value=None,axis=1)好了,别的应该没啥大问题啦,看一下结果吧:每次训练5000个样本,这里一共训练3000步,每隔10打印一次其在训练集和测试集上面的准确率:

-----------------------------------------------------------------------------------------------------------------------------------------------------------------
测试模型
code中Model下的ModelTest
这里所说的测试是指用原始数据来测试,总结一下该部分所做的事情就是:
1)加载训练好的数据集
2)测试性能
同样每次取5000个样本,一共测试40次:
INFO:tensorflow:Restoring parameters from D:/homework/pre/net/mynet
0.9916
0.9926
0.9922
0.9912
0.992
0.9918
0.9938
0.9908
0.9924
0.9914
0.991
0.9946
0.9928
0.9912
0.9906
0.9912
0.9922
0.9938
0.9918
0.9924
0.9938
0.9914
0.993
0.9922
0.9914
0.994
0.9916
0.9912
0.9918
0.9908
0.9904
0.9898
0.9918
0.9902
0.9922
0.9912
0.9926
0.9906
0.9918
0.9912------------------------------------------------------------------------------------------------------------------------------------------------------------------
可视化:
搭建的神经网络图:

训练集上的准确率和损失率变化过程:
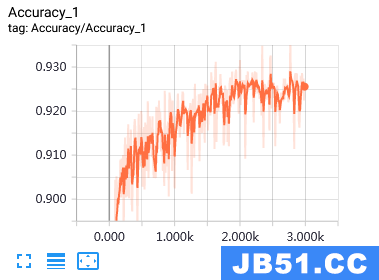
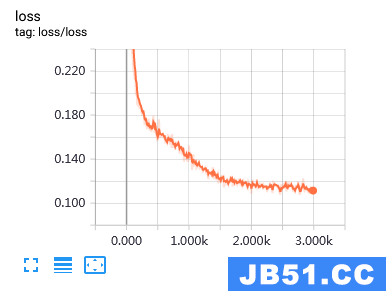
测试集上的准确率和损失率变化过程:


原始数据集上准确率和损失率变化过程:


可以看到,当模型训练好后,用原始数据集检测其性能时,准确率一直很高,损失率一直很低。
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
总结感悟:
1)上面可以看到预处理比较复杂,生产了很多csv文件,其实不必这么麻烦,很多步骤可以规划到一个函数处理,这里之所以会出现这么多中间csv是因为笔者用的是一台渣渣台式机,没有更多的算力,所以不得不拆分成多过程,分而处之。
2)通过上面可以看到,随机森林已经能够很好的解决本文问题啦,没必要用到复杂的深度学习,但是一些复杂的问题,也许传统的机器学习就束手无策啦,深度学习的使用在所难免,所以本质这个原则,我们来过一遍怎么用深度学习解决该问题,熟悉一下流程和框架。
3)就类似这样的分类问题而言,难点在于预处理的特征过程,即怎么样提取和处理原始数据的特征,这直接影响结果,其实一旦特征处理好了,就决定了一个极限值,后面不管是什么模型,包括其调优扥等过程,无非就是在不断的逼近这个值,所以预处理至关重要。
4)深度学习的优势在于可以自动筛选特征,哪一个特征不重要其最后的权值可能就小一些,而且其领域模型众多复杂,可以胜任各种问题,这一点是传统机器学习多不能媲美的,但是毕竟特征过多,如果没有足够的计算资源,不但容易导致过拟合而且效率不高,所以通常会使用传统机器学习来大概筛选一下特征,但是深度学习也有缺点,自认为其解释性不够强,尽管已经有很多解释,但大多花里花俏,而且深度学习中模型的搭建很多是靠试出来的,但不可否认其在图像等领域取得了突破性成就。个人观点,勿喷。
5)每天进步一点点,娱乐一点点,开心最重要。
看到很多小伙伴私信和关注,为了不迷路,欢迎大家关注笔者的微信公众号,会定期发一些关于NLP的干活总结和实践心得,当然别的方向也会发,一起学习:

版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 [email protected] 举报,一经查实,本站将立刻删除。